Linux系列:shell编程之文档操作(2)

【摘要】 linux系列第十课
1、grep命令
注:一种强大的文本搜索工具,【可以搜索流和文件行】,支持使用正则表达式搜索文本,并把匹配的行统计出来。
常用参数:
-c:统计符合条件的字符串出现的总行数。
-E:支持扩展正则表达式。
-i:忽略字符大小写。
-n:在显示匹配到的字符串前面加上行号。
-v:显示没有”搜索字符串”内容的那一行。
-l:列出文件内容中有搜索字符串的文件名称。
-o:只输出文件中匹配到的部分。
-color=auto:将匹配到的字符串高亮出来。
1)基本使用 // 这个不太好总结出来,自己慢慢体会就好啦!
# 有两种写法
# 第一种写法
# 注:这个只能是搜索文件中的指定字符。如果是文件夹则会报错
grep 字符 文件:从文件中搜索并打印找到行。
# 第二种写法:常用是这种
文件/文件夹 | grep 字符:从流中获取并输出找到的行。
第二种写法,举例如下:
# 最好是配合"-i"使用,忽略大小写。
[hadoop@image1 shell]$ ls
a.sh b.txt compare.sh file.sh if-elif-else.sh list1.sh services.sh test.sh uni.sh while.sh
a.txt cacul.sh c.txt func1.sh if-else.sh list.sh sort.txt three.sh until.sh
bool.sh case.sh cut.txt func2.sh if.sh read.sh str.sh uniq.txt wc.txt
# 查找某一个指定文件
[hadoop@image1 shell]$ ll | grep a.txt
-rw-rw-r--. 1 hadoop hadoop 10 Oct 25 12:41 a.txt
# 查看某一个指定进程
[hadoop@image1 shell]$ ps aux | grep sshd
root 2225 0.0 0.0 66260 1208 ? Ss 09:32 0:00 /usr/sbin/sshd
root 2464 0.0 0.2 102104 4048 ? Ss 09:32 0:00 sshd: hadoop [priv]
hadoop 2468 0.0 0.0 102104 1896 ? R 09:32 0:01 sshd: hadoop@pts/0
hadoop 3495 0.0 0.0 103336 848 pts/0 S+ 13:39 0:00 grep sshd
# 查看是否安装了某一个指定的软件
[hadoop@image1 shell]$ rpm -qa | grep -i jdk
2)正则表达式的使用
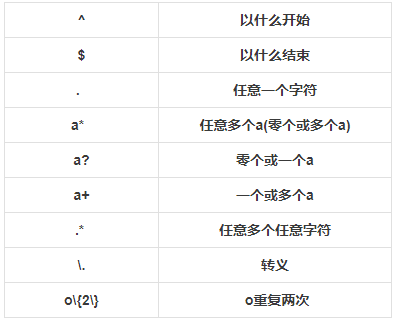
注:这里不好举例,自己下去慢慢看,不是太难。
2、find命令功能:搜索文件目录层次结构
常用可选项:
-name 根据文件名查找,支持('* ' , '? ')
-type 根据文件类型查找(f-普通文件,c-字符设备文件,b-块设备文件,l-链接文件,d-目录)
-perm 根据文件的权限查找,比如 755
-user 根据文件拥有者查找
-group 根据文件所属组寻找文件
-size 根据文件小大寻找文件
-o 表达式 或
-a 表达式 与
-not 表达式 非
操作如下:
## 准备的测试文件
[hadoop@image1 txt]$ ll
total 248
-rw-rw-r--. 1 hadoop hadoop 235373 Apr 18 00:10 hw.txt
-rw-rw-r--. 1 hadoop hadoop 0 Apr 22 05:43 HADOOP.pdf
-rw-rw-r--. 1 hadoop hadoop 3 Apr 22 05:50 liujialing.jpg
-rw-rw-r--. 1 hadoop hadoop 0 Apr 22 05:43 mingxing.pdf
-rw-rw-r--. 1 hadoop hadoop 57 Apr 22 04:40 mingxing.txt
-rw-rw-r--. 1 hadoop hadoop 66 Apr 22 05:15 sort.txt
-rw-rw-r--. 1 hadoop hadoop 214 Apr 18 10:08 test.txt
-rw-rw-r--. 1 hadoop hadoop 24 Apr 22 05:27 uniq.txt
## 1、查找文件名txt结尾的文件
find /home/hadoop/txt/ -name "*.txt"
/home/hadoop/txt/uniq.txt
/home/hadoop/txt/mingxing.txt
/home/hadoop/txt/test.txt
/home/hadoop/txt/hw.txt
/home/hadoop/txt/sort.txt
## 2、忽略大小写,查找文件名包含hadoop
find /home/hadoop/txt -iname "*hadoop*"
/home/hadoop/txt/HADOOP.pdf
## 3、查找文件名结尾是.txt或者.jpg的文件
find /home/hadoop/txt/ \( -name "*.txt" -o -name "*.jpg" \)
/home/hadoop/txt/liujialing.jpg
/home/hadoop/txt/uniq.txt
/home/hadoop/txt/mingxing.txt
/home/hadoop/txt/test.txt
/home/hadoop/txt/hw.txt
/home/hadoop/txt/sort.txt
另一种写法:
find /home/hadoop/txt/ -name "*.txt" -o -name "*.jpg"
## 4、使用正则表达式的方式,去查找上面条件的文件
find /home/hadoop/txt/ -regex ".*\(\.txt\|\.jpg\)$"
/home/hadoop/txt/liujialing.jpg
/home/hadoop/txt/uniq.txt
/home/hadoop/txt/mingxing.txt
/home/hadoop/txt/test.txt
/home/hadoop/txt/hw.txt
/home/hadoop/txt/sort.txt
## 5、查找.jpg结尾的文件,然后删掉
find /home/hadoop/txt -type f -name "*.jpg" -delete
[hadoop@hadoop txt]$ ll
total 248
-rw-rw-r--. 1 hadoop hadoop 235373 Apr 18 00:10 hw.txt
-rw-rw-r--. 1 hadoop hadoop 0 Apr 22 05:43 HADOOP.pdf
-rw-rw-r--. 1 hadoop hadoop 0 Apr 22 05:43 mingxing.pdf
-rw-rw-r--. 1 hadoop hadoop 57 Apr 22 04:40 mingxing.txt
-rw-rw-r--. 1 hadoop hadoop 66 Apr 22 05:15 sort.txt
-rw-rw-r--. 1 hadoop hadoop 214 Apr 18 10:08 test.txt
-rw-rw-r--. 1 hadoop hadoop 24 Apr 22 05:27 uniq.txt
3、shell操作字符串
1)字符串截取
Linux中操作字符串,也是一项必备的技能。其中尤以截取字符串更加频繁
下面为大家介绍几种常用方式,截取字符串。
预先定义一个变量:website=“http://hadoop//centos/huangbo.html”
[hadoop@image1 ~]$ website="http://hadoop//centos/huangbo.html"
#截取,删除左边字符串(包括制定的分隔符),保留右边字符串
[hadoop@image1 ~]# echo ${website#*//}
结果:hadoop//centos/huangbo.html
##截取,删除左边字符串(包括指定的分隔符),保留右边字符串,和上边一个#不同的是,它一直从左找到最后,而不是像一个#那样找到一个就满足条件退出了。
[hadoop@image1 ~]# echo ${website##*//}
结果:centos/huangbo.html
%截取,删除右边字符串(包括制定的分隔符),保留左边字符串
[hadoop@image1 ~]# echo ${website%//*}
结果:http://hadoop
%%截取,删除右边字符串(包括指定的分隔符),保留左边字符串,和上边一个%不同的是,它一直从右找到最前,而不是像一个%那样找到一个就满足条件退出了。
[hadoop@image1 ~]# echo ${website%%//*}
结果:http:
总结以上四种方式:
# 去掉左边,最短匹配模式, ##最长匹配模式。
% 去掉右边,最短匹配模式, %%最长匹配模式。
注意:他们两个的写法还有点不同。
去掉左边,使用的是#,同时*在字符左边;
去掉右边,使用的是%,同时*在字符右边;
预先定义一个变量:website=“http://hadoop//centos/huangbo.html”
[hadoop@image1 ~]$ website="http://hadoop//centos/huangbo.html"
从左边第几个字符开始,以及截取的字符的个数。
[hadoop@image1 ~]# echo ${website:2:2}
tp
从左边第几个字符开始,一直到结束。
[hadoop@image1 ~]# echo ${website:2}
tp://hadoop//centos//huangbo.html
从右边第几个字符开始,以及字符的个数。
[hadoop@image1 ~]# echo ${website:0-4:2}
ht
从右边第几个字符开始,一直到结束。
[hadoop@image1 ~]# echo ${website:0-4}
html
预先定义一个变量:website=“http://hadoop//centos/huangbo.html”
[hadoop@image1 ~]$ website="http://hadoop//centos/huangbo.html"
利用awk进行字符串截取。
[hadoop@image1 ~]# echo $website | awk '{print substr($1,2,6)}'
ttp://
利用cut进行字符串截取。
[hadoop@image1 ~]# echo $website | cut -b 1-4
http
[hadoop@image1 ~]# echo $website | cut -c 1-4
http
[hadoop@image1 ~]# echo $website | cut -b 1,4
hp
[hadoop@image1 ~]# echo $website | cut -c 1,4
hp
获取最后几个字符。
[hadoop@image1 ~]# echo ${website:(-3)}
tml
截取从倒数第3个字符后的2个字符。
[hadoop@image1 ~]# echo ${website:(-3):2}
tm
2)字符串替换
# 使用格式
${parameter/pattern/string}
操作如下:
# 定义变量VAR:
[hadoop@image1 ~]# var="hello tom, hello kitty, hello xiaoming"
# 替换第一个hello
[hadoop@image1 ~]# echo ${var/hello/hi}
hi tom, hello kitty, hello xiaoming
# 替换所有hello
[hadoop@image1 ~]# echo ${var//hello/hi}
hi tom, hi kitty, hi xiaoming
3)获取字符串长度
在此为大家提供五种方式获取某字符串的长度。
预先定义一个变量:website=“http://hadoop//centos/huangbo.html”
[hadoop@image1 ~]$ website="http://hadoop//centos/huangbo.html"
Ⅰ 通过#的方式获取字符串(最简单,最常用)
[hadoop@image1 ~]$ echo ${#website}
35
Ⅱ 使用wc -L命令
[hadoop@image1 ~]$ echo ${website} | wc -L
35
Ⅲ 使用expr的方式去计算
[hadoop@image1 ~]$ expr length ${website}
35
Ⅳ 通过awk + length的方式获取字符串长度
[hadoop@image1 ~]$ echo ${website} | awk '{print length($0)}'
35
Ⅴ 通过awk的方式计算以""分隔的字段个数
[hadoop@image1 ~]$ echo ${website} | awk -F "" '{print NF}'
35
4、sed命令功能
5、awk命令功能
# 语法格式如下:$1表示获取第一列,依次往后。
# 注意:下面一定是单引号,不能是双引号。
查找的结果 | awk -F分隔符 'print $1'
操作如下:
[hadoop@image1 ~]# cat /etc/passwd | awk -F ':' '{print $1}'
root
bin
daemon
adm
lp
[hadoop@image1 ~]# cat /etc/passwd | awk -F ':' '{print $1"\t"$7}'
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
[hadoop@image1 ~]# cat /etc/passwd | awk -F ':' '{print $1","$7}'
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
[hadoop@image1 ~]# cat /etc/passwd | awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}'
name,shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
blue,/bin/nosh
注:sed和awk用法,自己下去看看,不太好写笔记。

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)