Linux系列:shell编程之文档操作(1)

【摘要】 linux系列第十课
1、wc命令功能:统计文件行数、单词数等功能。
# wc常用选项。后面带了###,表示常用的。
-l:统计多少行 ###
-w:统计字数 ###
-c:统计文件字节数,一个英文字母1字节,一个汉字占2-4字节(根据编码)
-m:统计文件字符数,一个英文字母1字符,一个汉字占1个字符
-L:统计最长行的长度,也可以统计字符串长度 ###
-help:显示帮助信息
-version:显示版本信息
操作如下:
[hadoop@image1 shell]$ cat wc.txt
aaa ssss ttttt
bbbbbb;llll
ffffffffffffffff
gggggggggg
[hadoop@image1 shell]$ wc wc.txt
4 6 61 wc.txt
行数 单词数 字节数 文件名
# -l 统计文件有多少行
[hadoop@image1 shell]$ wc -l wc.txt
4 wc.txt
[hadoop@image1 shell]$ cat wc.txt | wc -l
4
# -w 统计文件单词数
[hadoop@image1 shell]$ wc -w wc.txt
6 wc.txt
[hadoop@image1 shell]$ cat wc.txt | wc -w
6
# -L 统计最长行的长度。空格也算
[hadoop@image1 shell]$ wc -L wc.txt
20 wc.txt
# -L 还可以统计字符串的长度
[hadoop@image1 shell]$ echo "abc" | wc -L
3
2、sort命令功能:排序(默认把整行作为整体,进行排序)
# 常用选项
-f:忽略字母大小写,就是将小写字母视为大写字母排序
-M:根据月份比较,比如JAN、DEC
-h:根据易读的单位大小比较,比如2K、1G
-g:按照常规数值排序
-n:根据字符串数值比较
-r:倒序(降序)排序 ###
-k:位置1,位置2根据关键字排序,在从第位置1开始,位置2结束 ###
-t:指定分隔符 ###
-u:去除重复行 ###
-o:将结果写入文件
默认把每一行看成一个整体,进行排序。
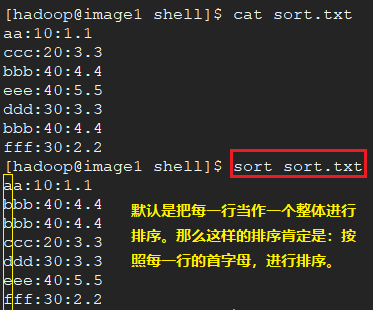
将数据按照指定分隔符分割,然后按照分割后的第二列数据,进行排序。
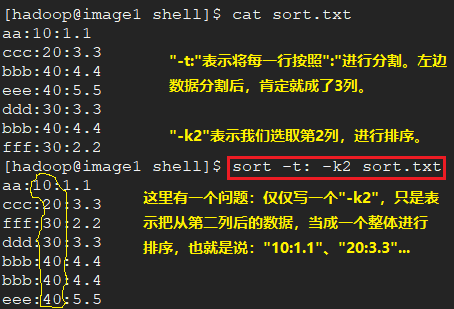
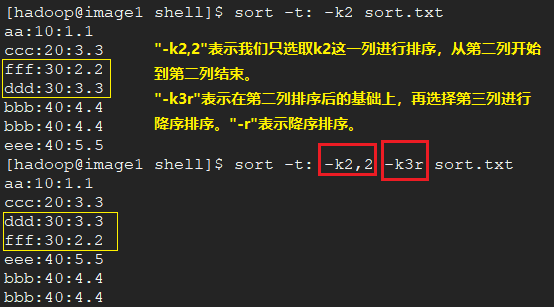
将数据按照指定分隔符分割,然后按照分割后的第二列数据,进行排序。若分裂后的第二列数据相同,就按照第三列降序。
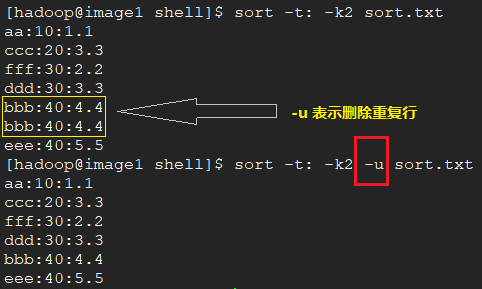
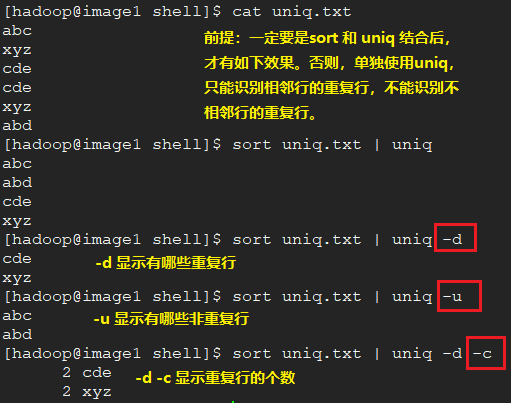
删除重复行。既可以去除相邻行的重复,也可以去重不相邻行的重复。与下面的uniq进行对比学习。
3、uniq命令功能:去重。只能去除相邻行。
# 常用选项
-c:打印出现的次数
-d:只打印重复行。
-u:只打印不重复行。
-D:只打印重复行,并且把所有重复行打印出来
-f N:比较时跳过前N列
-i:忽略大小写 ###
-s N:比较时跳过前N个字符
-w N:对每行第N个字符以后内容不做比较
操作如下:
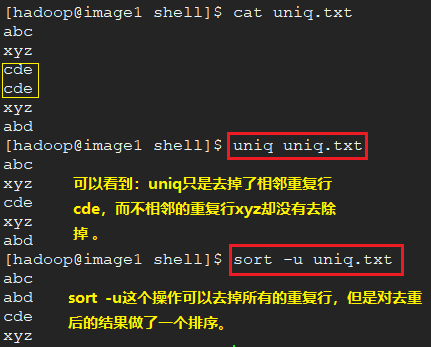
uniq命令结合sort命令的几种用法。
4、一个简单案例:求两个文件的并集。
原始文件如下:
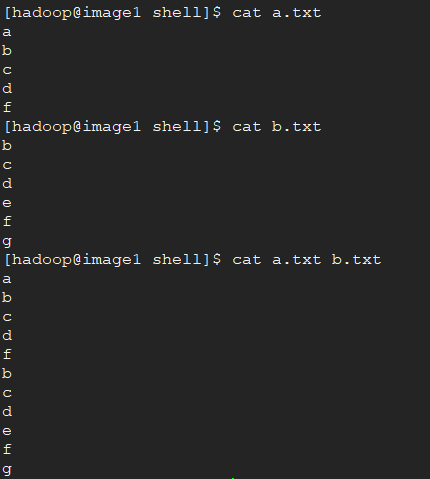
操作如下:
[hadoop@image1 shell]$ cat a.txt b.txt | sort -r | uniq > c.txt
[hadoop@image1 shell]$ cat c.txt
g
f
e
d
c
b
a
解释如下:
我们对所查看内容,先试用“sort -r”做一个降序排序,然后使用“uniq”进行去重,
最后使用“>”重定向到c.txt中。
一个“>”代表覆盖原有内容。两个“>>”代表追加在原文件之后。
注意:交集,差集使用uniq中参数一样可以写出来。自己可以下去练练手。
5、cut命令功能:从一个文本文件或者文本流中提取文本列。
常用选项
-d:后面接分隔字符。与 -f 一起使用
-f:依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思
-c:按照字符截取
-b:按照字节截取
操作如下:
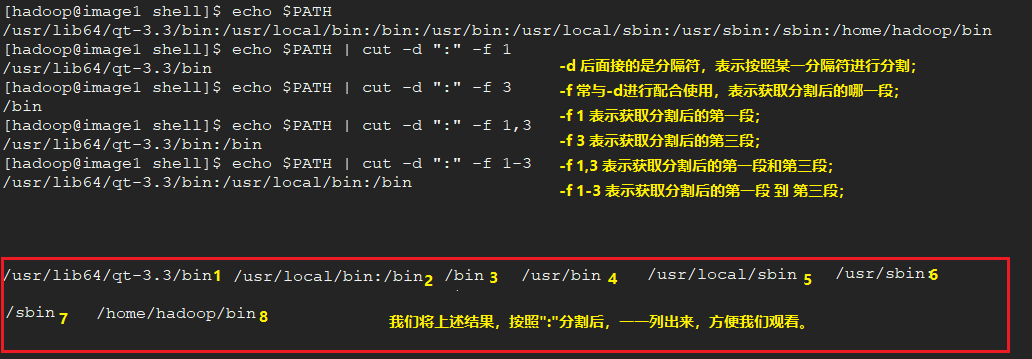
再举一个例子加深印象:
[hadoop@image1 shell]$ cat cut.txt
黄渤 huangbo 18 jiangxi
徐峥 xuzheng 22 hunan
王宝强 wangbaoqiang 44 liujiayao
[hadoop@image1 shell]$ cut -d " " -f 1,3 cut.txt
黄渤 18
徐峥 22
王宝强 44

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)