PySpark 编程——将速度与简单相结合

Python 和 Apache Spark 是分析行业最热门的流行语。Apache Spark 是一种流行的开源框架,可确保以闪电般的速度处理数据,并支持各种语言,如 Scala、Python、Java 和 R。然后归结为您的语言偏好和工作范围。通过这篇 PySpark 编程文章,我将讨论 Spark和 Python,以演示 Python 如何利用 Apache Spark 的功能。
在我们开始 PySpark 编程之旅之前,让我列出我将在本文中涵盖的主题:
Python 和 Apache Spark 是分析行业最热门的流行语。Apache Spark 是一种流行的开源框架,可确保以闪电般的速度处理数据,并支持各种语言,如 Scala、Python、Java 和 R。然后归结为您的语言偏好和工作范围。通过这篇 PySpark 编程文章,我将讨论 Spark和 Python,以演示 Python 如何利用 Apache Spark 的功能。
在我们开始 PySpark 编程之旅之前,让我列出我将在本文中涵盖的主题:
因此,让我们从列表中的第一个主题开始,即 PySpark 编程。
PySpark 编程
PySpark 是 Apache Spark 和 Python的合作 。
Apache Spark是一个开源集群计算框架,围绕速度、易用性和流分析而构建,而Python是一种通用的高级编程语言。它提供了广泛的库,主要用于机器学习和实时流分析。
换句话说,它是一个用于 Spark的 Python API,可让您利用 Python 的简单性和 Apache Spark 的强大功能来驯服大数据。

您可能想知道,当有其他语言可用时,为什么我选择 Python 来使用 Spark。为了回答这个问题,我列出了一些您将享受 Python 的优势:
- Python 非常容易学习和实现。
- 它提供了简单而全面的 API。
- 使用 Python,代码的可读性、维护性和熟悉性要好得多。
- 它为数据可视化提供了各种选项,这在使用 Scala 或 Java 时是很困难的。
- Python 附带了广泛的库,如 numpy、pandas、scikit-learn、seaborn、matplotlib 等。
- 它得到了一个庞大而活跃的社区的支持。
现在您已经了解了 PySpark 编程的优势,让我们简单地深入了解 PySpark 的基础知识。
弹性分布式数据集 (RDD)
RDD是 任何 Spark 应用程序的构建块。RDD 代表:
- 弹性:它具有容错能力,能够在故障时重建数据。
- 分布式:数据分布在集群中的多个节点之间。
- 数据集:带有值的分区数据的集合。
它是分布式集合上的抽象数据层。它本质上是不可变的,并且遵循 惰性转换。
使用 RDD,您可以执行两种类型的操作:
数据框
PySpark中的 Dataframe 是 结构化或半结构化数据的分布式集合。 Dataframe 中的这些数据存储在命名列下的行中,类似于关系数据库表或 Excel 表。
它还与 RDD 共享一些共同属性,例如本质上不可变,遵循惰性求值并且本质上是分布式的。 它支持多种格式,如 JSON、CSV、TXT 等。此外,您可以从现有 RDD 或通过编程指定模式加载它。
PySpark SQL
PySpark SQL 是 PySpark Core 之上的更高级别的抽象模块。它主要用于处理结构化和半结构化数据集。它还提供了一个优化的 API,可以从包含不同文件格式的各种数据源中读取数据。因此,与 PySpark 您可以通过使用 SQL 和 HiveQL 来处理数据。由于这个特性,PySparkSQL 在数据库程序员和 Apache Hive 用户中逐渐流行起来。
PySpark 流
PySpark Streaming 是一个可扩展的容错系统,遵循 RDD 批处理范例。它基本上以小批量或批量间隔运行,范围从 500 毫秒到更大的间隔窗口。
在这种情况下, Spark Streaming 从Apache Flume、Kinesis、Kafka、TCP 套接字等来源接收连续的输入数据流 。然后这些流数据在内部根据批次间隔分解为多个较小的批次,并转发到 Spark 引擎。Spark Engine 使用复杂的算法处理这些数据批次,这些算法用高级函数表示,例如 map、reduce、join 和 window。一旦处理完成,处理过的批次就会被推送到数据库、文件系统和实时仪表板。

Spark Streaming 的关键抽象是离散化流 (DStream)。 DStreams 建立在 RDD 之上,便于 Spark 开发人员在 RDD 和批处理的相同上下文中工作,以解决流问题。此外, Spark Streaming 还与 MLlib、SQL、DataFrames 和 GraphX 集成,从而拓宽了您的功能范围。 作为一个高级 API,Spark Streaming为有状态操作提供了容错“恰好一次” 语义。
注意:“ exactly-once ”语义意味着事件将被流应用程序中的所有操作符“exactly once”处理,即使发生任何故障。
下图,代表了 Spark Streaming 的基本组件。

如您所见,数据从各种来源(例如 Kafka、Flume、Twitter、ZeroMQ、Kinesis 或 TCP 套接字等)被摄取到 Spark Stream 中。此外,这些数据是使用复杂的算法处理的,这些算法用高级函数表示,如 map、reduce、join 和 window。最后,这些处理过的数据被推送到各种文件系统、数据库和实时仪表板以供进一步利用。
我希望这能让您清楚地了解 PySpark Streaming 的工作原理。现在让我们转到这篇 PySpark 编程文章的最后一个也是最吸引人的主题,即机器学习。
机器学习
如您所知,Python 是一种成熟的语言,自古以来就被大量用于数据科学和机器学习。在 PySpark 中,机器学习由一个名为MLlib(机器学习库)的 Python 库促进。它只不过是 PySpark Core 的包装器,它使用机器学习算法(如分类、聚类、线性回归等)执行数据分析。
使用 PySpark 进行机器学习的诱人特性之一是它适用于分布式系统并且具有高度可扩展性。
MLlib 使用 PySpark 公开了三个核心机器学习功能:
- 数据准备:它 提供了各种功能,如提取、转换、选择、散列等。
- 机器学习算法:它 利用一些流行和先进的回归、分类和聚类算法进行机器学习。
- 实用工具:具有卡方检验、描述性统计、线性代数和模型评价方法等统计方法。
让我向您展示如何 通过逻辑回归使用分类来实现机器学习 。
在这里,我将对食品检验数据进行简单的预测分析。
##Importing the required libraries
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
from pyspark.sql import Row
from pyspark.sql.functions import UserDefinedFunction
from pyspark.sql.types import *
##creating a RDD by importing and parsing the input data
def csvParse(s):
import csv
from StringIO import StringIO
sio = StringIO(s)
value = csv.reader(sio).next()
sio.close()
return value
food_inspections = sc.textFile('file:////home/edureka/Downloads/Food_Inspections_Chicago_data.csv')
.map(csvParse)
##Display data format
food_inspections.take(1)
#Structuring the data
schema = StructType([
StructField("id", IntegerType(), False),
StructField("name", StringType(), False),
StructField("results", StringType(), False),
StructField("violations", StringType(), True)])
#creating a dataframe and a temporary table (Results) required for the predictive analysis.
##sqlContext is used to perform transformations on structured data
ins_df = spark.createDataFrame(food_inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema)
ins_df.registerTempTable('Count_Results')
ins_df.show()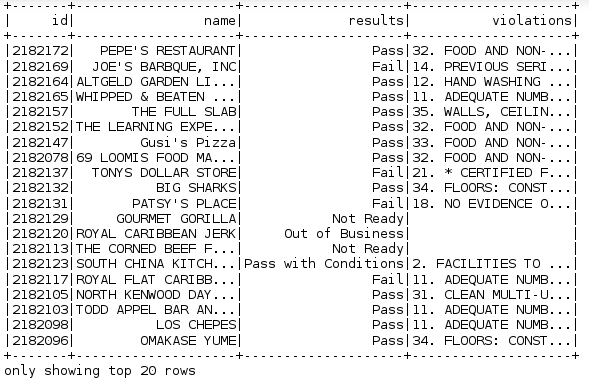
##Let's now understand our dataset
#show the distinct values in the results column
result_data = ins_df.select('results').distinct().show()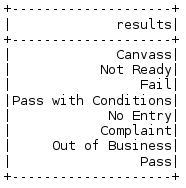
##converting the existing dataframe into a new dataframe
###each inspection is represented as a label-violations pair.
####Here 0.0 represents a failure, 1.0 represents a success, and -1.0 represents some results besides those two
def label_Results(s):
if s == 'Fail':
return 0.0
elif s == 'Pass with Conditions' or s == 'Pass':
return 1.0
else:
return -1.0
ins_label = UserDefinedFunction(label_Results, DoubleType())
labeled_Data = ins_df.select(ins_label(ins_df.results).alias('label'), ins_df.violations).where('label >= 0')
labeled_Data.take(1)
##Creating a logistic regression model from the input dataframe
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeled_Data)
## Evaluating with Test Data
test_Data = sc.textFile('file:////home/edureka/Downloads/Food_Inspections_test.csv')
.map(csvParse)
.map(lambda l: (int(l[0]), l[1], l[12], l[13]))
test_df = spark.createDataFrame(test_Data, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass with Conditions'")
predict_Df = model.transform(test_df)
predict_Df.registerTempTable('Predictions')
predict_Df.columns
## Printing 1st row
predict_Df.take(1)
## Predicting the final result
numOfSuccess = predict_Df.where("""(prediction = 0 AND results = 'Fail') OR
(prediction = 1 AND (results = 'Pass' OR
results = 'Pass with Conditions'))""").count()
numOfInspections = predict_Df.count()
print "There were", numOfInspections, "inspections and there were", numOfSuccess, "successful predictions"
print "This is a", str((float(numOfSuccess) / float(numOfInspections)) * 100) + "%", "success rate"
有了这个,我们结束了这个关于 PySpark 编程的博客。希望它有助于为您的知识增加一些价值。

- 点赞
- 收藏
- 关注作者
评论(0)