生成对抗网络:构建您的第一个模型

目录
生成对抗网络(GAN) 是一种神经网络,可以生成类似于人类产生的材料,例如图像、音乐、语音或文本。
近年来,GAN 一直是一个活跃的研究课题。Facebook 的 AI 研究主管 Yann LeCun 称对抗性训练是机器学习领域“过去 10 年最有趣的想法”。下面,您将在实现自己的两个生成模型之前了解 GAN 的工作原理。
在本教程中,您将学习:
- 什么是生成模型以及它与判别模型的区别
- GAN 的结构和训练方式
- 如何使用PyTorch构建自己的 GAN
- 如何使用 GPU 和 PyTorch 为实际应用训练 GAN
让我们开始吧!
什么是生成对抗网络?
生成对抗网络是机器学习系统,可以学习模仿给定的数据分布。它们首先由深度学习专家 Ian Goodfellow 及其同事在 2014 年的NeurIPS 论文中提出。
GAN 由两个神经网络组成,一个训练生成数据,另一个训练区分假数据和真实数据(因此模型的“对抗性”性质)。尽管生成数据的结构的想法并不新鲜,但在图像和视频生成方面,GAN 已经提供了令人印象深刻的结果,例如:
- 使用CycleGAN进行样式转换,它可以对图像执行许多令人信服的样式转换
- 使用StyleGAN 生成人脸,如网站This Person does not Exist 所示
与更广泛研究的判别模型相比,生成数据的结构(包括 GAN)被认为是生成模型。在深入研究 GAN 之前,您将了解这两种模型之间的差异。
判别模型与生成模型
如果您研究过神经网络,那么您遇到的大多数应用程序很可能是使用判别模型实现的。另一方面,生成对抗网络是另一类称为生成模型的模型的一部分。
判别模型是用于大多数监督 分类或回归问题的模型。作为分类问题的一个例子,假设你想训练一个模型来对手写数字的图像进行 0 到 9 的分类。为此,你可以使用一个包含手写数字图像的标记数据集及其相关标签,指示每个数字是哪个数字图像代表。
在训练过程中,您将使用算法来调整模型的参数。目标是最小化损失函数,以便模型学习给定输入的输出的概率分布。在训练阶段之后,您可以使用该模型通过估计输入对应的最可能数字来对新的手写数字图像进行分类,如下图所示:

您可以将分类问题的判别模型描绘为使用训练数据来学习类之间边界的块。然后他们使用这些边界来区分输入并预测其类别。在数学方面,判别模型学习给定输入x的输出y的条件概率P ( y | x ) 。
除了神经网络,其他结构也可以用作判别模型,例如逻辑回归模型和支持向量机(SVM)。
然而,像 GAN 这样的生成模型被训练来描述数据集是如何根据概率模型生成的。通过从生成模型中采样,您可以生成新数据。虽然判别模型用于监督学习,但生成模型通常用于未标记的数据集,可以看作是无监督学习的一种形式。
使用手写数字数据集,您可以训练生成模型来生成新数字。在训练阶段,您将使用一些算法来调整模型的参数以最小化损失函数并学习训练集的概率分布。然后,通过训练好的模型,您可以生成新的样本,如下图所示:
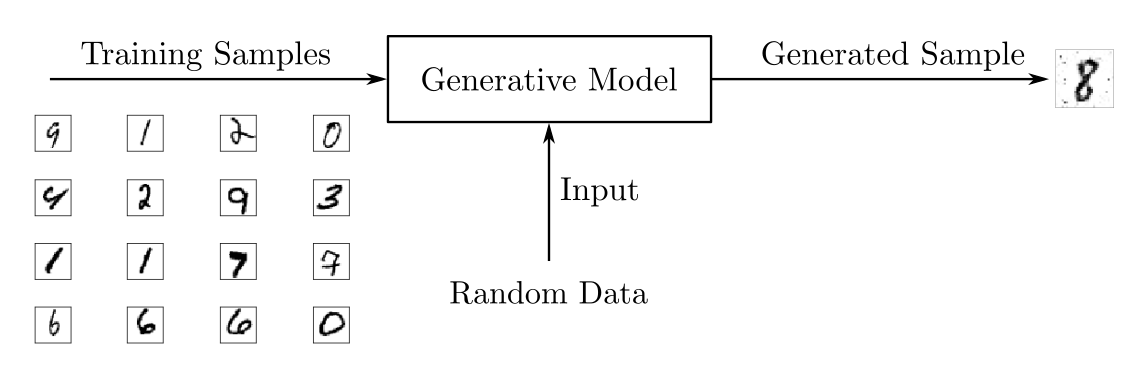
要输出的新样本,生成模型通常认为一个随机由模型产生影响的样品,或随机元素。用于驱动生成器的随机样本是从潜在空间中获得的,其中向量表示生成样本的一种压缩形式。
与判别模型不同,生成模型学习输入数据x的概率P ( x ) ,并且通过输入数据的分布,它们能够生成新的数据实例。
注意:生成模型也可以与标记数据集一起使用。当他们是时,他们被训练学习输入x的概率P ( x | y )给定输出y。它们也可用于分类任务,但一般而言,判别模型在分类方面表现更好。
您可以在文章On Discriminative vs. Generative Classifiers: A comparison of Logistic Regression 和 naive Bayes 中找到有关判别式和生成式分类器的相对优势和劣势的更多信息。
尽管近年来 GAN 受到了很多关注,但它们并不是唯一可以用作生成模型的架构。除了 GAN 之外,还有其他各种生成模型架构,例如:
然而,由于在图像和视频生成方面的令人兴奋的结果,GAN 近来吸引了大多数公众的兴趣。
现在您了解了生成模型的基础知识,您将了解 GAN 的工作原理以及如何训练它们。
生成对抗网络的架构
生成对抗网络由两个神经网络组成的整体结构组成,一个称为生成器,另一个称为判别器。
生成器的作用是估计真实样本的概率分布,以提供与真实数据相似的生成样本。反过来,鉴别器被训练来估计给定样本来自真实数据而不是由生成器提供的概率。
这些结构被称为生成对抗网络,因为生成器和鉴别器被训练为相互竞争:生成器试图更好地欺骗鉴别器,而鉴别器试图更好地识别生成的样本。
要了解 GAN 训练的工作原理,请考虑一个玩具示例,该示例的数据集由二维样本 ( x ₁, x ₂) 组成,x ₁ 在 0 到 2π 的区间内,x ₂ = sin( x ₁),如图所示如下图:
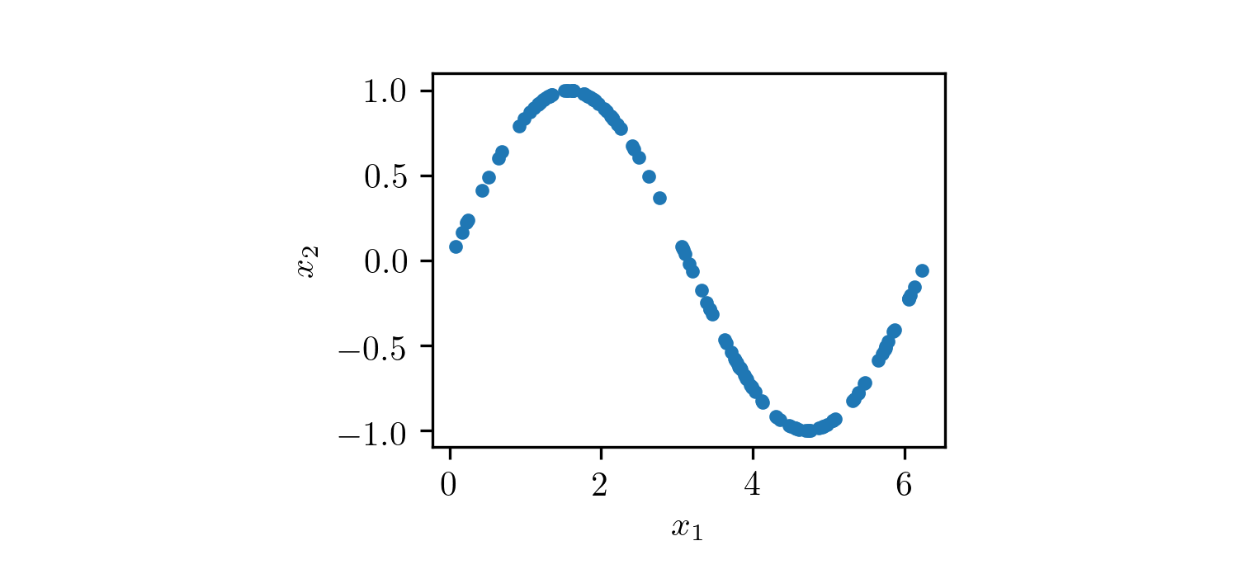
如您所见,该数据集由位于正弦曲线上的点 ( x ₁, x 2) 组成,具有非常特殊的分布。生成与数据集样本相似的对 ( x̃ ₁, x̃ ₂)的 GAN 的整体结构如下图所示:

发电机G ^馈送随机数据从一个潜在空间,其作用是产生数据类似的真实样品。在这个例子中,你有一个二维的潜在空间,所以生成器被输入随机 ( z ₁, z 2) 对,并且需要对它们进行变换,使它们类似于真实样本。
神经网络G的结构可以是任意的,允许您将神经网络用作多层感知器(MLP)、卷积神经网络(CNN) 或任何其他结构,只要输入和输出的维度与维度匹配即可潜在空间和真实数据。
鉴别器D由来自训练数据集的真实样本或由G提供的生成样本馈送。它的作用是估计输入属于真实数据集的概率。执行训练以便D在输入真实样本时输出 1,在输入生成样本时输出 0。
与G 一样,您可以为D选择任意神经网络结构,只要它考虑到必要的输入和输出维度即可。在这个例子中,输入是二维的。对于二元鉴别器,输出可能是一个范围从 0 到 1的标量。
GAN 训练过程包括一个两人极小极大博弈,其中D被调整以最小化真实样本和生成样本之间的判别误差,而G被调整以最大化D犯错的概率。
尽管包含真实数据的数据集没有标记,但D和G的训练过程是以监督方式执行的。在训练的每一步,D和G 都会更新它们的参数。事实上,在最初的 GAN 提议中,D的参数更新了k次,而G的参数每训练一步只更新一次。但是,为了使训练更简单,您可以考虑k等于 1。
为了训练D,在每次迭代中,你将从训练数据中提取的一些真实样本标记为 1,将G提供的一些生成样本标记为 0。 这样,你可以使用传统的监督训练框架来更新D的参数,以最小化一个损失函数,如下图所示:

对于包含标记的真实样本和生成样本的每批训练数据,更新D的参数以最小化损失函数。更新D的参数后,您训练G以生成更好的生成样本。G的输出连接到D,其参数保持冻结状态,如下所示:
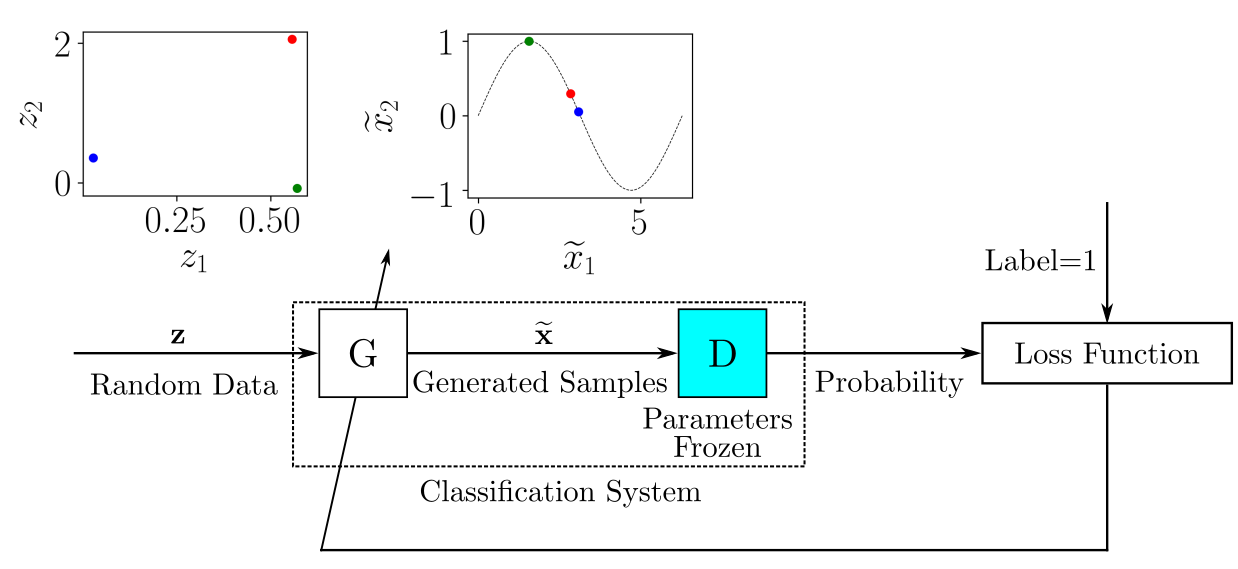
你可以把由G和D组成的系统想象成一个单一的分类系统,它接收随机样本作为输入并输出分类,在这种情况下可以解释为概率。
当G做得足够好来欺骗D 时,输出概率应该接近 1。 你也可以在这里使用传统的监督训练框架:训练由G和D组成的分类系统的数据集将由随机输入样本提供,并且与每个输入样本关联的标签将为 1。
在训练过程中,随着D和G参数的更新,预计G给出的生成样本将更接近真实数据,而D将更难以区分真实数据和生成数据。
既然您知道 GAN 的工作原理,您就可以使用PyTorch实现您自己的GAN。
你的第一个 GAN
作为生成对抗网络的第一个实验,您将实现上一节中描述的示例。
要运行该示例,您将使用PyTorch库,您可以使用Anaconda Python 发行版以及conda包和环境管理系统安装该库。要了解有关 Anaconda 和 conda 的更多信息,请查看在 Windows上设置 Python 进行机器学习的教程。
首先,创建一个 conda 环境并激活它:
$ conda create --name gan
$ conda activate gan
激活 conda 环境后,您的提示将显示其名称gan. 然后你可以在环境中安装必要的包:
$ conda install -c pytorch pytorch=1.4.0
$ conda install matplotlib jupyter
由于PyTorch是一个非常活跃的开发框架,API 可能会在新版本中发生变化。为确保示例代码能够运行,您需要安装特定版本的1.4.0.
除了 PyTorch,您还将使用Matplotlib处理绘图,并使用Jupyter Notebook在交互式环境中运行代码。这样做不是强制性的,但它有助于机器学习项目的工作。
有关使用 Matplotlib 和 Jupyter Notebooks 的复习,请查看Python Plotting With Matplotlib (Guide)和Jupyter Notebook: An Introduction。
在打开 Jupyter Notebook 之前,您需要注册 condagan环境,以便您可以使用它作为内核来创建 Notebook。为此,在gan激活环境的情况下,运行以下命令:
$ python -m ipykernel install --user --name gan
现在您可以通过运行打开 Jupyter Notebook jupyter notebook。通过单击新建然后选择gan创建一个新的 Notebook 。
在 Notebook 中,首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
在这里,您使用torch. 您还导入nn只是为了能够以不那么冗长的方式设置神经网络。然后导入math以获取 pi 常数的值,并plt像往常一样导入 Matplotlib 绘图工具。
设置随机生成器种子是一个很好的做法,以便可以在任何机器上以相同的方式复制实验。要在 PyTorch 中执行此操作,请运行以下代码:
torch.manual_seed(111)
数字111表示用于初始化随机数生成器的随机种子,用于初始化神经网络的权重。尽管实验具有随机性,但只要使用相同的种子,它就必须提供相同的结果。
现在环境已经设置好了,可以准备训练数据了。
准备训练数据
训练数据由对 ( x ₁, x ₂)组成,因此x ₂ 由x ₁的正弦值组成,x ₁ 在 0 到 2π 的区间内。您可以按如下方式实现它:
1train_data_length = 1024
2train_data = torch.zeros((train_data_length, 2))
3train_data[:, 0] = 2 * math.pi * torch.rand(train_data_length)
4train_data[:, 1] = torch.sin(train_data[:, 0])
5train_labels = torch.zeros(train_data_length)
6train_set = [
7 (train_data[i], train_labels[i]) for i in range(train_data_length)
8]
在这里,您用1024对 ( x ₁, x ₂)组成一个训练集。在第 2 行中,您初始化train_data了一个张量,其1024行和2列的维度都包含零。甲张量是类似于多维数组NumPy的阵列。
在第 3 行中,您使用 的第一列train_data在从0到的区间中存储随机值2π。然后,在第 4 行,您将张量的第二列计算为第一列的正弦值。
接下来,您需要一个标签张量,这是 PyTorch 的数据加载器所需要的。由于 GAN 使用无监督学习技术,标签可以是任何东西。毕竟它们不会被使用。
在第 5 行中,您创建train_labels了一个填充零的张量。最后,在第 6 行到第 8 行,您创建train_set了一个元组列表,每个元组中的每一行train_data和train_labels都按照 PyTorch 的数据加载器的预期来表示。
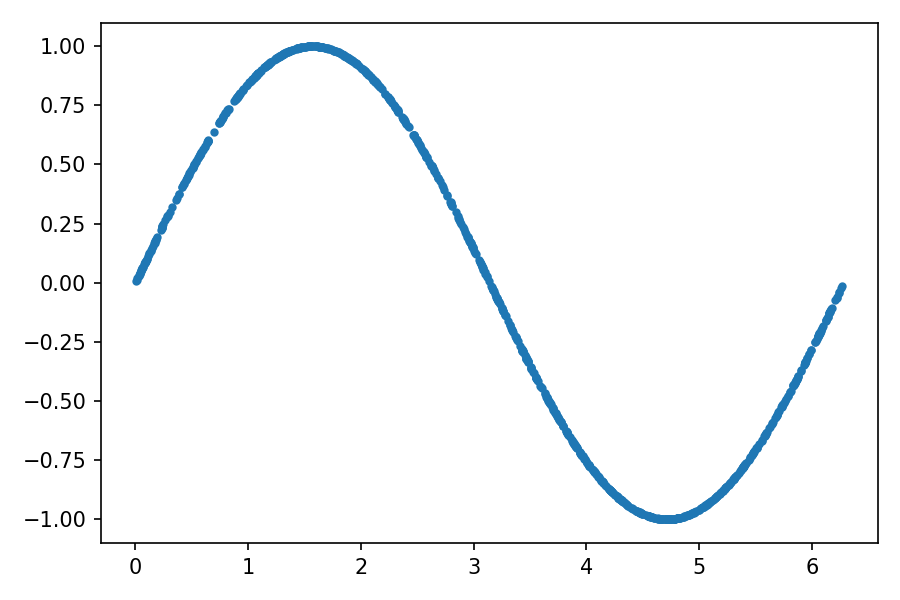
您可以通过绘制每个点 ( x ₁, x ₂)来检查训练数据:
plt.plot(train_data[:, 0], train_data[:, 1], ".")
输出应该类似于下图:
使用train_set,您可以创建 PyTorch 数据加载器:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True
)
在这里,您创建了一个名为 的数据加载器train_loader,它将对数据进行混洗train_set并返回32您将用于训练神经网络的成批样本。
设置训练数据后,您需要为构成 GAN 的鉴别器和生成器创建神经网络。在下一节中,您将实现鉴别器。
实现鉴别器
在 PyTorch 中,神经网络模型由继承自 的类表示nn.Module,因此您必须定义一个类来创建鉴别器。有关定义类的更多信息,请查看Python 3 中的面向对象编程 (OOP)。
鉴别器是一个具有二维输入和一维输出的模型。它将从真实数据或生成器接收样本,并提供样本属于真实训练数据的概率。下面的代码显示了如何创建鉴别器:
1class Discriminator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(2, 256),
6 nn.ReLU(),
7 nn.Dropout(0.3),
8 nn.Linear(256, 128),
9 nn.ReLU(),
10 nn.Dropout(0.3),
11 nn.Linear(128, 64),
12 nn.ReLU(),
13 nn.Dropout(0.3),
14 nn.Linear(64, 1),
15 nn.Sigmoid(),
16 )
17
18 def forward(self, x):
19 output = self.model(x)
20 return output
您用于.__init__()构建模型。首先,你需要调用super().__init__()运行.__init__()的nn.Module。您使用的鉴别器是一个 MLP 神经网络,使用nn.Sequential(). 它具有以下特点:
-
第 5 和 6 行:输入是二维的,第一个隐藏层由
256具有ReLU激活的神经元组成。 -
第 8、9、11 和 12 行:第二个和第三个隐藏层分别由
128和64神经元组成,并使用 ReLU 激活。 -
第 14 行和第 15 行:输出由具有sigmoidal激活的单个神经元组成,以表示概率。
最后,您使用.forward()来描述模型的输出是如何计算的。这里,x代表模型的输入,它是一个二维张量。在此实现中,输出是通过将输入提供x给您定义的模型而获得的,无需任何其他处理。
在声明鉴别器类之后,你应该实例化一个Discriminator对象:
discriminator = Discriminator()
discriminator代表您已定义并准备好接受训练的神经网络实例。但是,在实施训练循环之前,您的 GAN 还需要一个生成器。您将在下一节中实现一个。
实现生成器
在生成对抗网络中,生成器是从潜在空间中获取样本作为其输入并生成与训练集中的数据类似的数据的模型。在这种情况下,它是一个具有二维输入的模型,它将接收随机点 ( z ₁, z ₂) 和一个二维输出,该输出必须提供与训练数据中的点相似的( x̃ ₁, x̃ ₂) 点.
该实现类似于您为鉴别器所做的。首先,你必须创建一个Generator继承自的类nn.Module,定义神经网络架构,然后你需要实例化一个Generator对象:
1class Generator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(2, 16),
6 nn.ReLU(),
7 nn.Linear(16, 32),
8 nn.ReLU(),
9 nn.Linear(32, 2),
10 )
11
12 def forward(self, x):
13 output = self.model(x)
14 return output
15
16generator = Generator()
这里,generator代表生成器神经网络。它由两个带有16和32神经元的隐藏层组成,两者都带有 ReLU 激活,以及一个带有2输出神经元的线性激活层。这样,输出将包含一个包含两个元素的向量,这些元素可以是从负无穷大到无穷大的任何值,这将表示 ( x̃ ₁, x̃ ₂)。
现在您已经为鉴别器和生成器定义了模型,您可以开始执行训练了!
训练模型
在训练模型之前,您需要设置一些在训练期间使用的参数:
1lr = 0.001
2num_epochs = 300
3loss_function = nn.BCELoss()
在此设置以下参数:
-
第 1 行设置学习率 (
lr),您将使用它来调整网络权重。 -
第 2 行设置了 epochs (
num_epochs)的数量,它定义了使用整个训练集进行的训练重复次数。 -
3个线分配变量
loss_function的二进制交叉熵的功能BCELoss(),这是损失函数,你会用它来训练模型。
二元交叉熵函数是训练鉴别器的合适损失函数,因为它考虑了二元分类任务。它也适用于训练生成器,因为它将其输出提供给鉴别器,鉴别器提供二进制可观察输出。
PyTorch 在torch.optim. 您将使用Adam 算法来训练鉴别器和生成器模型。要使用创建优化器torch.optim,请运行以下几行:
1optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
2optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
最后,您需要实现一个训练循环,在该循环中将训练样本馈送到模型,并更新它们的权重以最小化损失函数:
1for epoch in range(num_epochs):
2 for n, (real_samples, _) in enumerate(train_loader):
3 # Data for training the discriminator
4 real_samples_labels = torch.ones((batch_size, 1))
5 latent_space_samples = torch.randn((batch_size, 2))
6 generated_samples = generator(latent_space_samples)
7 generated_samples_labels = torch.zeros((batch_size, 1))
8 all_samples = torch.cat((real_samples, generated_samples))
9 all_samples_labels = torch.cat(
10 (real_samples_labels, generated_samples_labels)
11 )
12
13 # Training the discriminator
14 discriminator.zero_grad()
15 output_discriminator = discriminator(all_samples)
16 loss_discriminator = loss_function(
17 output_discriminator, all_samples_labels)
18 loss_discriminator.backward()
19 optimizer_discriminator.step()
20
21 # Data for training the generator
22 latent_space_samples = torch.randn((batch_size, 2))
23
24 # Training the generator
25 generator.zero_grad()
26 generated_samples = generator(latent_space_samples)
27 output_discriminator_generated = discriminator(generated_samples)
28 loss_generator = loss_function(
29 output_discriminator_generated, real_samples_labels
30 )
31 loss_generator.backward()
32 optimizer_generator.step()
33
34 # Show loss
35 if epoch % 10 == 0 and n == batch_size - 1:
36 print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
37 print(f"Epoch: {epoch} Loss G.: {loss_generator}")
对于 GAN,您在每次训练迭代时更新鉴别器和生成器的参数。正如所有神经网络通常所做的那样,训练过程由两个循环组成,一个用于训练时期,另一个用于每个时期的批次。在内部循环中,您开始准备数据以训练鉴别器:
-
第 2 行:您从数据加载器获取当前批次的真实样本并将它们分配给
real_samples。请注意,张量的第一个维度的元素数等于batch_size。这是在 PyTorch 中组织数据的标准方式,张量的每一行代表批次中的一个样本。 -
第 4 行:您使用真实样本
torch.ones()的值创建标签1,然后将标签分配给real_samples_labels。 -
第 5 行和第 6 行:您通过在 中存储随机数据来创建生成的样本
latent_space_samples,然后将其提供给生成器以获取generated_samples。 -
第 7 行:您用于为生成的样本的标签
torch.zeros()分配值0,然后将标签存储在generated_samples_labels. -
第 8 行到第 11 行:您将真实样本和生成的样本和标签连接起来,并将它们存储在
all_samples和 中all_samples_labels,您将使用它们来训练鉴别器。
接下来,在第 14 到 19 行,您训练鉴别器:
-
第 14 行:在 PyTorch 中,需要在每个训练步骤清除梯度以避免累积它们。您可以使用
.zero_grad(). -
第 15 行:您使用 中的训练数据计算鉴别器的输出
all_samples。 -
第 16 和 17 行:您使用 中模型的输出
output_discriminator和 中的标签计算损失函数all_samples_labels。 -
第 18 行:您计算梯度以使用 更新权重
loss_discriminator.backward()。 -
第 19 行:您通过调用 来更新鉴别器权重
optimizer_discriminator.step()。
接下来,在第 22 行,您准备数据以训练生成器。您将随机数据存储在 中latent_space_samples,行数等于batch_size。您使用两列,因为您提供二维数据作为生成器的输入。
您在第 25 到 32 行训练生成器:
-
第 25 行:您使用 清除渐变
.zero_grad()。 -
第 26 行:您为生成器提供数据
latent_space_samples并将其输出存储在generated_samples. -
第 27 行:您将生成器的输出提供给鉴别器并将其输出存储在 中
output_discriminator_generated,您将使用它作为整个模型的输出。 -
第 28 至 30 行:您使用存储在 中的分类系统的输出
output_discriminator_generated和 中的标签计算损失函数real_samples_labels,它们都等于1。 -
第 31 和 32 行:计算梯度并更新生成器权重。请记住,当您训练生成器时,您将鉴别器的权重保持在冻结状态,因为您创建
optimizer_generator的第一个参数等于generator.parameters()。
最后,在第 35 到 37 行,您显示了每十个时期结束时鉴别器和生成器损失函数的值。
由于本示例中使用的模型参数很少,因此训练将在几分钟内完成。在下一节中,您将使用经过训练的 GAN 生成一些样本。
检查 GAN 生成的样本
生成对抗网络旨在生成数据。所以,在训练过程结束后,你可以从潜在空间中获取一些随机样本,并将它们馈送到生成器以获得一些生成的样本:
latent_space_samples = torch.randn(100, 2)
generated_samples = generator(latent_space_samples)
然后您可以绘制生成的样本并检查它们是否与训练数据相似。在绘制generated_samples数据之前,您需要使用.detach()从 PyTorch 计算图中返回一个张量,然后您将使用它来计算梯度:
generated_samples = generated_samples.detach()
plt.plot(generated_samples[:, 0], generated_samples[:, 1], ".")
输出应类似于下图:

您可以看到生成的数据的分布类似于真实数据中的分布。通过在训练过程中使用固定的潜在空间样本张量并在每个 epoch 结束时将其馈送到生成器,您可以可视化训练的演变:
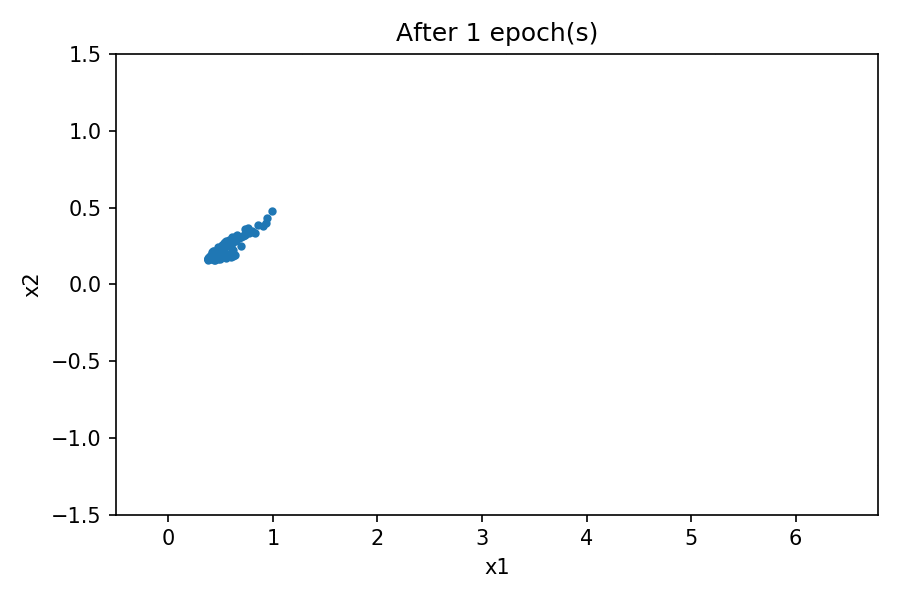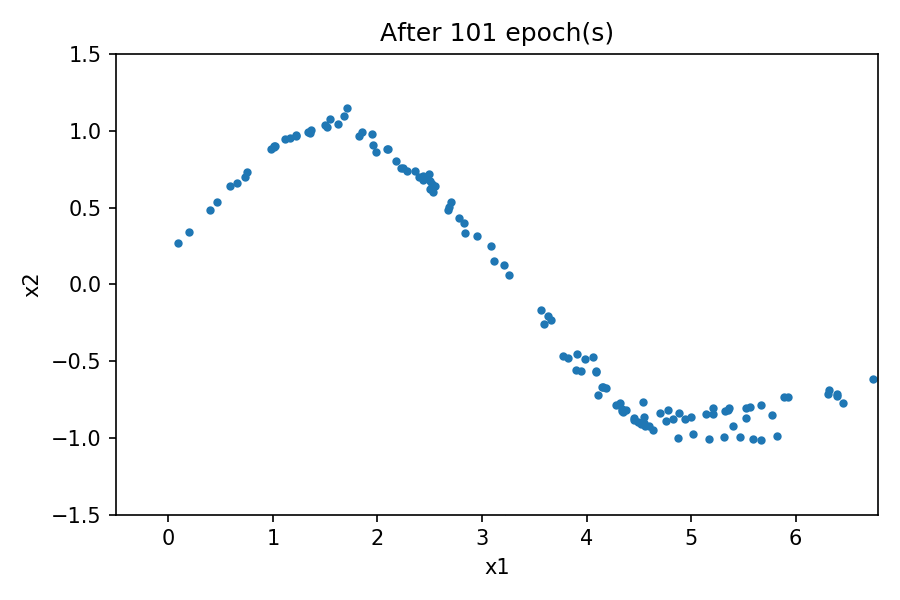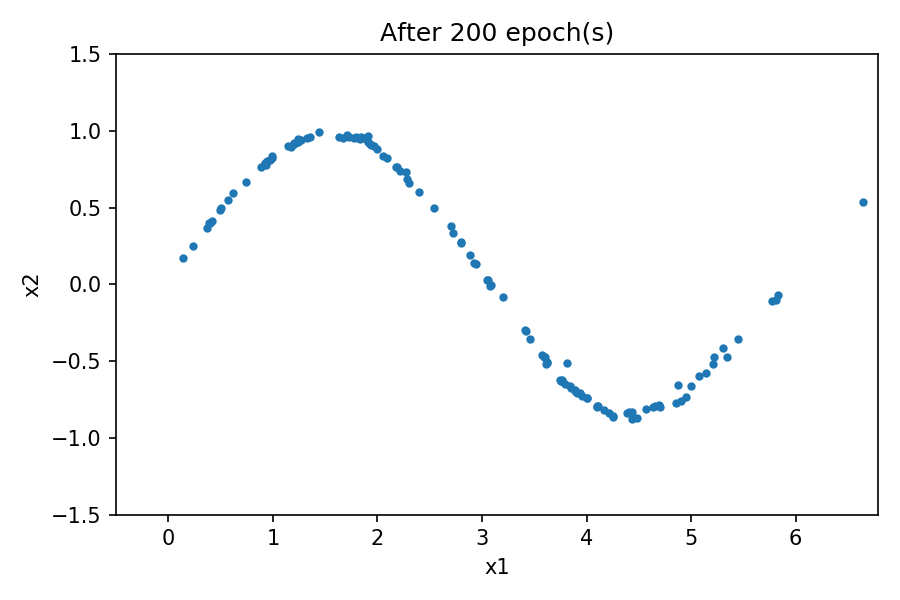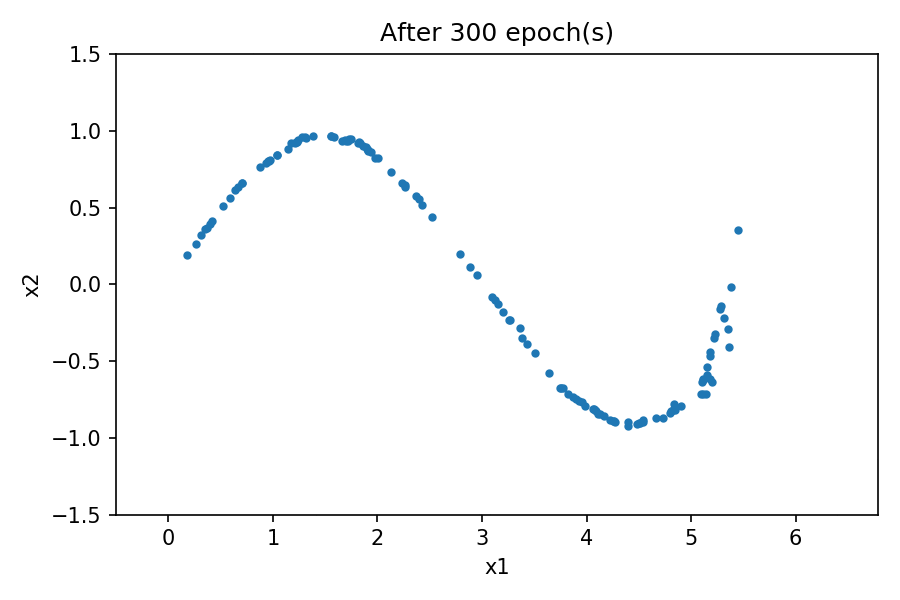
请注意,在训练过程开始时,生成的数据分布与真实数据有很大不同。然而,随着训练的进行,生成器学习真实的数据分布。
现在您已经完成了生成对抗网络的第一个实现,您将使用图像进行更实际的应用。
带有 GAN 的手写数字生成器
生成对抗网络还可以生成高维样本,例如图像。在此示例中,您将使用 GAN 生成手写数字的图像。为此,您将使用包中包含的手写数字MNIST 数据集训练模型torchvision。
首先,您需要torchvision在激活的ganconda 环境中安装:
$ conda install -c pytorch torchvision=0.5.0
同样,您使用 的特定版本torchvision来确保示例代码将运行,就像您使用pytorch. 环境设置好后,您可以开始在 Jupyter Notebook 中实现模型。打开它并通过单击New然后选择gan创建一个新的 Notebook 。
与前面的示例一样,首先导入必要的库:
import torch
from torch import nn
import math
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
除此之外,您还之前已经导入库,你将需要torchvision并transforms取得训练数据和进行图像转换。
同样,设置随机生成器种子以能够复制实验:
torch.manual_seed(111)
由于此示例使用训练集中的图像,因此模型需要更复杂,具有更多参数。这会使训练过程变慢,在CPU 上运行时每个 epoch 大约需要两分钟。您需要大约 50 个 epoch 才能获得相关结果,因此使用 CPU 时的总训练时间约为 100 分钟。
为了减少训练时间,如果有可用的GPU,您可以使用GPU来训练模型。但是,您需要手动将张量和模型移动到 GPU,以便在训练过程中使用它们。
您可以通过创建一个device指向 CPU 或(如果有)指向 GPU的对象来确保您的代码在任一设置上运行:
device = ""
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
稍后,您将使用它device来设置应在何处创建张量和模型,使用 GPU(如果可用)。
现在基本环境设置好了,就可以准备训练数据了。
准备训练数据
MNIST 数据集由 0 到 9 的手写数字的 28 × 28 像素灰度图像组成。要将它们与 PyTorch 一起使用,您需要执行一些转换。为此,您定义transform了一个在加载数据时使用的函数:
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
该函数有两部分:
transforms.ToTensor()将数据转换为 PyTorch 张量。transforms.Normalize()转换张量系数的范围。
原始系数由transforms.ToTensor()0 到 1的范围给出,并且由于图像背景为黑色,因此当使用此范围表示时,大多数系数等于 0。
transforms.Normalize()通过0.5从原始系数中减去并将结果除以,将系数的范围更改为 -1 到 1 0.5。通过这种转换,输入样本中等于 0 的元素数量显着减少,这有助于训练模型。
的参数transforms.Normalize()是两个元组,(M₁, ..., Mₙ)和(S₁, ..., Sₙ),n代表图像的通道数。诸如 MNIST 数据集中的灰度图像只有一个通道,因此元组只有一个值。然后,对于i图像的每个通道,从系数中transforms.Normalize()减去Mᵢ并将结果除以Sᵢ。
现在,您可以使用以下方法加载训练数据torchvision.datasets.MNIST并使用transform以下方法执行转换:
train_set = torchvision.datasets.MNIST(
root=".", train=True, download=True, transform=transform
)
该参数download=True确保第一次运行上述代码时,MNIST 数据集将被下载并存储在当前目录中,如参数 所示root。
现在您已经创建了train_set,您可以像以前一样创建数据加载器:
batch_size = 32
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=batch_size, shuffle=True
)
您可以使用 Matplotlib 绘制训练数据的一些样本。为了改进可视化,您可以使用cmap=gray_r反转颜色图并在白色背景上以黑色绘制数字:
real_samples, mnist_labels = next(iter(train_loader))
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(real_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
输出应类似于以下内容:

如您所见,有不同手写风格的数字。随着 GAN 学习数据的分布,它还会生成具有不同手写风格的数字。
现在您已经准备好训练数据,您可以实现鉴别器和生成器模型。
实现鉴别器和生成器
在这种情况下,鉴别器是一个 MLP 神经网络,它接收一个 28 × 28 像素的图像,并提供该图像属于真实训练数据的概率。
您可以使用以下代码定义模型:
1class Discriminator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(784, 1024),
6 nn.ReLU(),
7 nn.Dropout(0.3),
8 nn.Linear(1024, 512),
9 nn.ReLU(),
10 nn.Dropout(0.3),
11 nn.Linear(512, 256),
12 nn.ReLU(),
13 nn.Dropout(0.3),
14 nn.Linear(256, 1),
15 nn.Sigmoid(),
16 )
17
18 def forward(self, x):
19 x = x.view(x.size(0), 784)
20 output = self.model(x)
21 return output
要将图像系数输入到 MLP 神经网络中,您需要对它们进行向量化,以便神经网络接收带有784系数的向量。
向量化发生在 的第一行.forward(),因为调用x.view()转换输入张量的形状。在这种情况下,输入的原始形状x为 32 × 1 × 28 × 28,其中 32 是您设置的批大小。转换后的形状x变为 32 × 784,每条线代表训练集图像的系数。
要使用 GPU 运行鉴别器模型,您必须实例化它并使用.to(). 要在有可用 GPU 时使用 GPU,您可以将模型发送到device您之前创建的对象:
discriminator = Discriminator().to(device=device)
由于生成器将生成更复杂的数据,因此有必要增加来自潜在空间的输入的维度。在这种情况下,生成器将接受 100 维输入,并将提供具有 784 个系数的输出,这些系数将组织在表示图像的 28 × 28 张量中。
这是完整的生成器模型代码:
1class Generator(nn.Module):
2 def __init__(self):
3 super().__init__()
4 self.model = nn.Sequential(
5 nn.Linear(100, 256),
6 nn.ReLU(),
7 nn.Linear(256, 512),
8 nn.ReLU(),
9 nn.Linear(512, 1024),
10 nn.ReLU(),
11 nn.Linear(1024, 784),
12 nn.Tanh(),
13 )
14
15 def forward(self, x):
16 output = self.model(x)
17 output = output.view(x.size(0), 1, 28, 28)
18 return output
19
20generator = Generator().to(device=device)
在第 12 行,您使用双曲正切函数 Tanh()作为输出层的激活函数,因为输出系数应该在 -1 到 1 的区间内。在第 20 行,您实例化生成器并将其发送device到使用 GPU(如果有)可用。
现在您已经定义了模型,您将使用训练数据训练它们。
训练模型
要训练模型,您需要像在前面的示例中一样定义训练参数和优化器:
lr = 0.0001
num_epochs = 50
loss_function = nn.BCELoss()
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
为了获得更好的结果,您可以降低前一个示例的学习率。您还将时期数设置为50以减少训练时间。
训练循环与您在前一个示例中使用的循环非常相似。在突出显示的行中,您将训练数据发送device到使用 GPU(如果可用):
1for epoch in range(num_epochs):
2 for n, (real_samples, mnist_labels) in enumerate(train_loader):
3 # Data for training the discriminator
4 real_samples = real_samples.to(device=device)
5 real_samples_labels = torch.ones((batch_size, 1)).to(
6 device=device
7 )
8 latent_space_samples = torch.randn((batch_size, 100)).to(
9 device=device
10 )
11 generated_samples = generator(latent_space_samples)
12 generated_samples_labels = torch.zeros((batch_size, 1)).to(
13 device=device
14 )
15 all_samples = torch.cat((real_samples, generated_samples))
16 all_samples_labels = torch.cat(
17 (real_samples_labels, generated_samples_labels)
18 )
19
20 # Training the discriminator
21 discriminator.zero_grad()
22 output_discriminator = discriminator(all_samples)
23 loss_discriminator = loss_function(
24 output_discriminator, all_samples_labels
25 )
26 loss_discriminator.backward()
27 optimizer_discriminator.step()
28
29 # Data for training the generator
30 latent_space_samples = torch.randn((batch_size, 100)).to(
31 device=device
32 )
33
34 # Training the generator
35 generator.zero_grad()
36 generated_samples = generator(latent_space_samples)
37 output_discriminator_generated = discriminator(generated_samples)
38 loss_generator = loss_function(
39 output_discriminator_generated, real_samples_labels
40 )
41 loss_generator.backward()
42 optimizer_generator.step()
43
44 # Show loss
45 if n == batch_size - 1:
46 print(f"Epoch: {epoch} Loss D.: {loss_discriminator}")
47 print(f"Epoch: {epoch} Loss G.: {loss_generator}")
某些张量不需要使用device. 这是与案件generated_samples中第11行,这将已经因为发送到一个可用的GPUlatent_space_samples和generator先前发送到GPU。
由于此示例具有更复杂的模型,因此训练可能需要更多时间。完成后,您可以通过生成一些手写数字样本来检查结果。
检查 GAN 生成的样本
要生成手写数字,您必须从潜在空间中随机抽取一些样本并将它们提供给生成器:
latent_space_samples = torch.randn(batch_size, 100).to(device=device)
generated_samples = generator(latent_space_samples)
要绘图generated_samples,您需要将数据移回 CPU,以防它在 GPU 上运行。为此,您只需调用.cpu(). 正如您之前所做的那样,您还需要.detach()在使用 Matplotlib 绘制数据之前调用:
generated_samples = generated_samples.cpu().detach()
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
plt.imshow(generated_samples[i].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
输出应该是类似于训练数据的数字,如下图所示:

经过 50 个 epoch 的训练,生成了几个与真实数字相似的数字。您可以通过考虑更多的训练时期来改善结果。与前面的示例一样,通过使用固定的潜在空间样本张量,并在训练过程中的每个 epoch 结束时将其馈送到生成器,您可以可视化训练的演变:
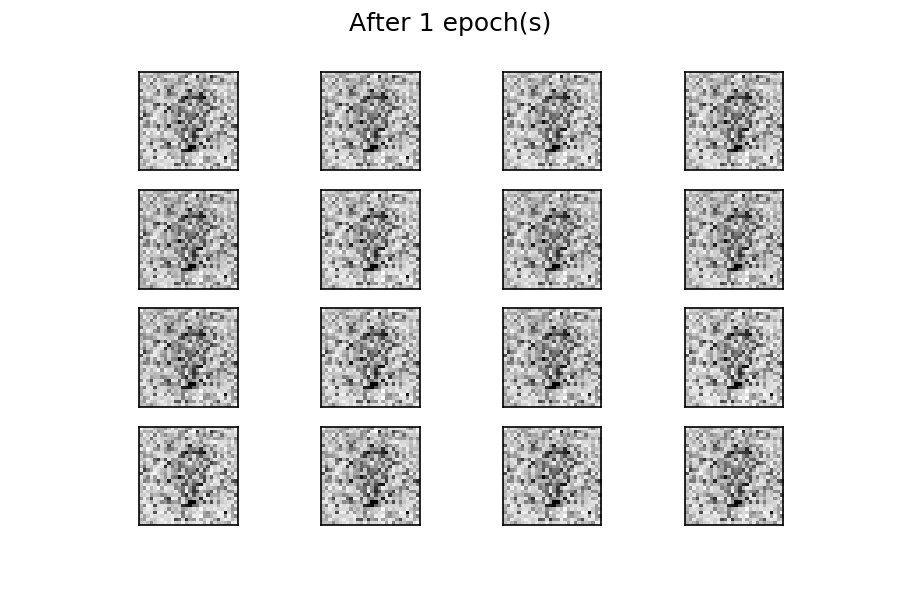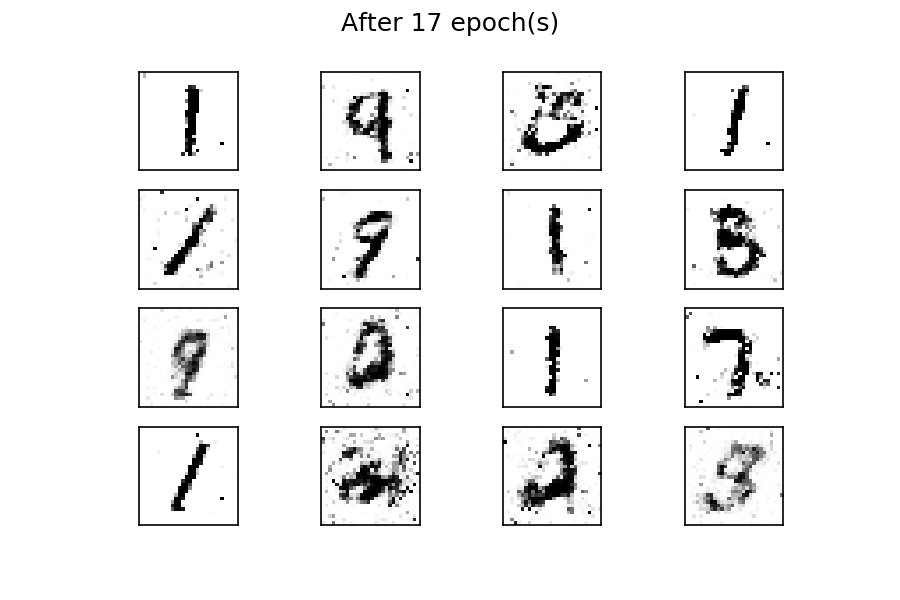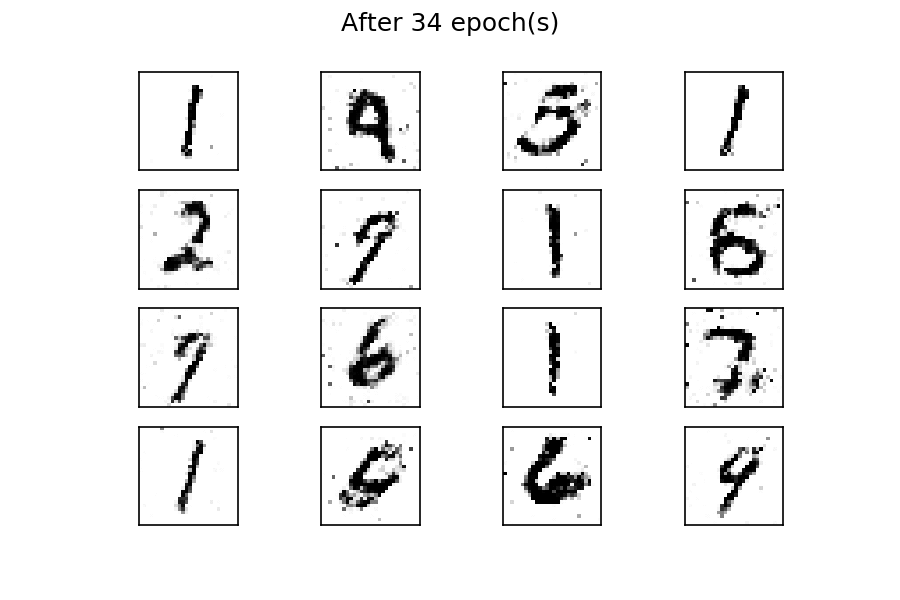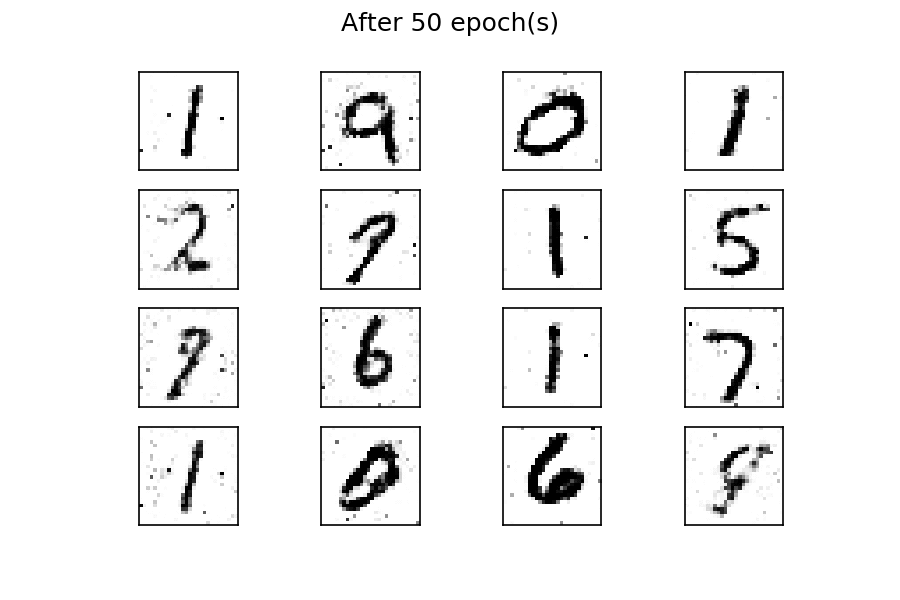
可以看到,在训练过程开始时,生成的图像是完全随机的。随着训练的进行,生成器学习真实数据的分布,并且在大约 20 个 epoch 时,一些生成的数字已经类似于真实数据。
结论
恭喜!您已经学习了如何实现自己的生成对抗网络。在深入研究生成手写数字图像的实际应用之前,您首先通过一个玩具示例了解 GAN 结构。
您已经看到,尽管 GAN 很复杂,但像 PyTorch 这样的机器学习框架通过提供自动微分和简单的 GPU 设置使实现更加简单。
在本教程中,您学习了:
- 判别模型和生成模型之间的区别是什么
- 如何构建和训练生成对抗网络
- 如何使用PyTorch和GPU等工具来实现和训练 GAN 模型
GAN 是一个非常活跃的研究课题,近年来提出了几个令人兴奋的应用。如果您对该主题感兴趣,请密切关注技术和科学文献以检查新的应用想法。
进一步阅读
现在您了解了使用生成对抗网络的基础知识,您可以开始研究更复杂的应用程序。以下书籍是加深知识的好方法:
- GANs in Action: Deep Learning with Generative Adversarial Networks由 Jakub Langr 和 Vladimir Bok撰写,涵盖了更详细的主题,包括最近的应用程序,例如用于执行风格迁移的CycleGAN。
- 生成性深度学习:教学机器绘画、写作、作曲和游戏,作者 David Foster,调查了生成对抗网络和其他生成模型的实际应用。
值得一提的是,机器学习是一个广泛的学科,除了生成对抗网络之外,还有很多不同的模型结构。有关机器学习的更多信息,请查看以下资源:
- 在 Windows 上为机器学习设置 Python
- 使用 Python 和 Keras 进行实用的文本分类
- 使用 Python 进行传统人脸检测
- 在 OpenCV + Python 中使用颜色空间进行图像分割
- 使用 Python 进行语音识别的终极指南
- 使用协同过滤构建推荐引擎
在机器学习的世界里有很多东西要学。继续学习,随时在下面留下任何问题或评论!

- 点赞
- 收藏
- 关注作者
评论(0)