HBase 架构:HBase 数据模型 & HBase 读/写机制

HBase 架构
在我之前关于HBase 教程的博客中,我解释了什么是 HBase 及其特性。我还提到了 Facebook Messenger 的案例研究,以帮助您更好地联系。现在继续,我将解释 HBase 和 HBase 架构的数据模型。在继续之前,您还应该知道 HBase 是一个重要的概念,它构成了大数据 Hadoop 认证课程的一个组成部分。
我将在此 HBase 架构博客中向您介绍的重要主题是:
我们先来了解一下HBase的数据模型。它有助于 HBase 更快地读/写和搜索。
HBase 架构:HBase 数据模型
众所周知,HBase 是一个面向列的 NoSQL 数据库。虽然它看起来类似于包含行和列的关系数据库,但它不是关系数据库。关系数据库是面向行的,而 HBase 是面向列的。那么,让我们首先了解面向列和面向行的数据库之间的区别:
面向行与面向列的数据库:
- 面向行的数据库以行的顺序存储表记录。而面向列的数据库 将表记录存储在一系列列中,即列中的条目存储在磁盘上的连续位置。
为了更好地理解它,让我们举个例子并考虑下表。
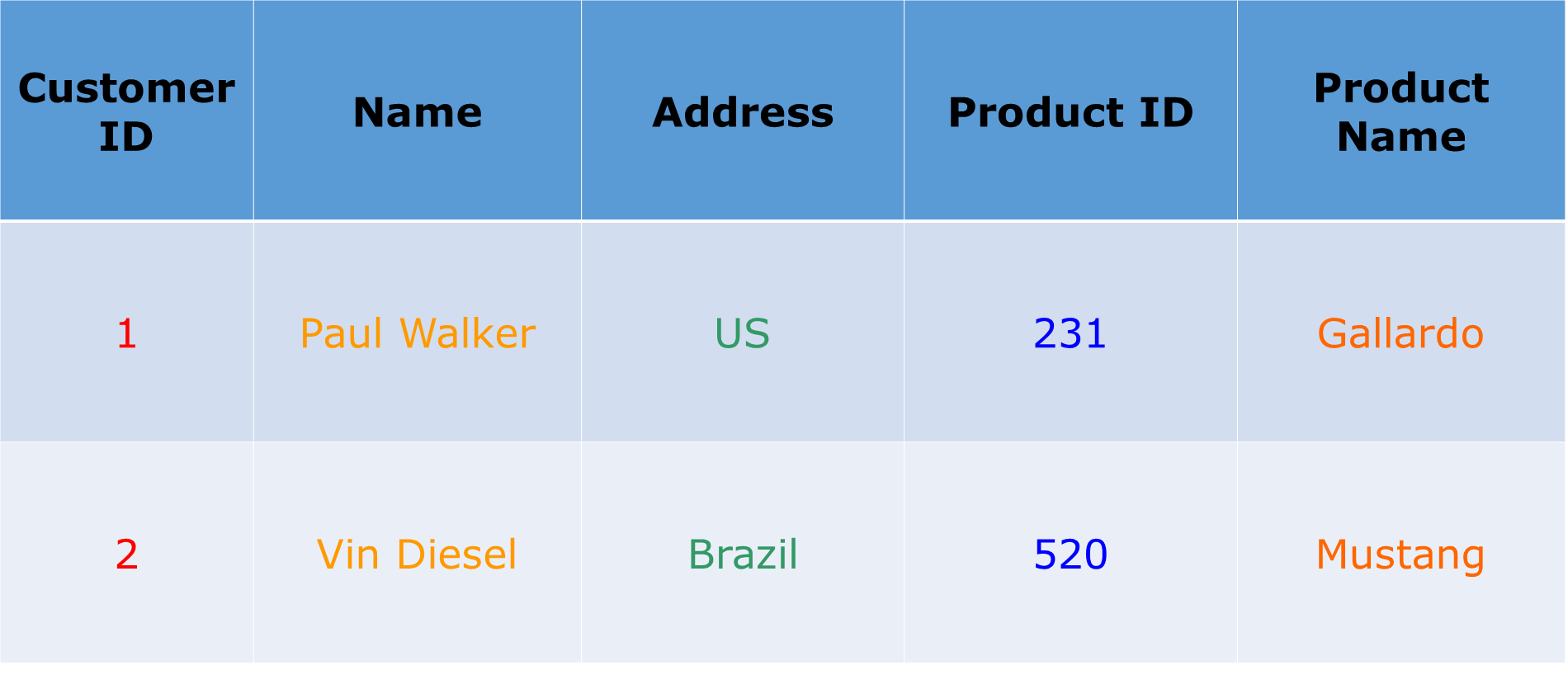
如果此表存储在面向行的数据库中。它将存储如下所示的记录:
1 ,保罗沃克,美国, 231 ,加拉多,
2, Vin Diesel ,巴西, 520 , Mustang
如上所示,在面向行的数据库中,数据是基于行或元组存储的。
虽然面向列的数据库将此数据存储为:
1 , 2 , Paul Walker , Vin Diesel , 美国,巴西, 231 , 520 , Gallardo , Mustang
在面向列的数据库中,所有列值都存储在一起,就像第一列值将存储在一起,然后第二列值将一起存储,其他列中的数据以类似方式存储。
- 当数据量非常大时,比如 PB 级或 EB 级,我们使用面向列的方法,因为单列的数据存储在一起,可以更快地访问。
- 虽然面向行的方法相对有效地处理较少数量的行和列,但面向行的数据库存储数据是一种结构化格式。
- 当我们需要处理和分析大量半结构化或非结构化数据时,我们使用面向列的方法。例如处理在线分析处理的应用程序,如数据挖掘、数据仓库、包括分析在内的应用程序等。
- 而在线事务处理(例如处理结构化数据并需要事务属性(ACID 属性)的银行和金融领域)使用面向行的方法。
HBase 表具有以下组件,如下图所示:
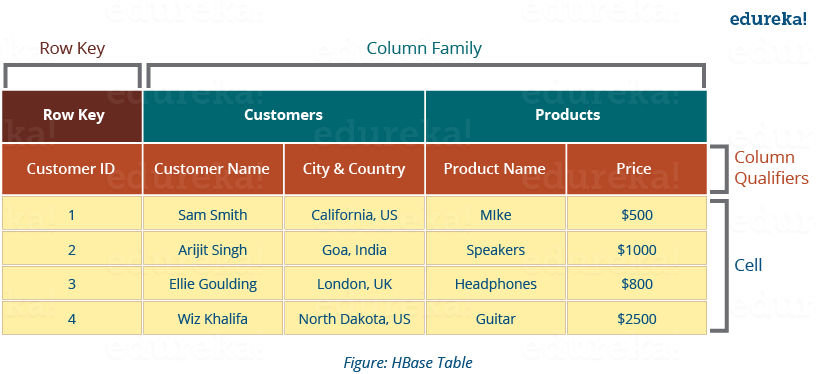
- 表格:数据以表格格式存储在 HBase 中。但这里的表格是面向列的格式。
- 行 键:行键用于搜索记录,使搜索速度更快。你会很想知道怎么做吗?我将在本博客的架构部分进行解释。
- 列 族:各种列组合在一个列族中。这些列族存储在一起,这使得搜索过程更快,因为可以在一次查找中一起访问属于同一列族的数据。
- 列 限定符:每列的名称称为其列限定符。
- 单元格:数据存储在单元格中。数据被转储到由行键和列限定符专门标识的单元格中。
- 时间戳:时间戳是日期和时间的组合。无论何时存储数据,它都会与其时间戳一起存储。这使得搜索特定版本的数据变得容易。
用更简单易懂的方式,我们可以说 HBase 包括:
- 一组表
- 每个表都有列族和行
- 行键在 HBase 中充当主键。
- 对 HBase 表的任何访问都使用此主键
- HBase 中存在的每个列限定符表示与驻留在单元格中的对象相对应的属性。
现在您了解了 HBase 数据模型,让我们看看这个数据模型如何符合 HBase 架构并使其适用于大存储和更快的处理。
HBase 架构:HBase 架构的组件
HBase 具有三个主要组件,即HMaster Server、HBase Region Server、Regions和Zookeeper。
下图解释了 HBase 架构的层次结构。我们将单独讨论它们中的每一个。
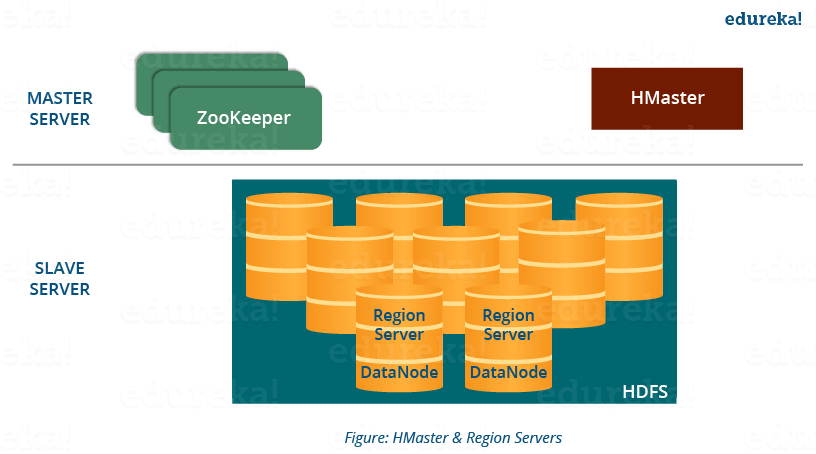
现在在进入 HMaster 之前,我们将了解 Region,因为所有这些 Server(HMaster、Region Server、Zookeeper)都是用来协调和管理 Region 并在 Region 内部执行各种操作的。因此,您很想知道什么是区域以及它们为何如此重要?
HBase 架构:区域
一个区域包含分配给该区域的开始键和结束键之间的所有行。HBase 表可以划分为多个区域,将一个列族的所有列存储在一个区域中。每个区域都包含按排序顺序的行。
许多区域被分配给一个Region Server,它负责处理、管理、执行对该组区域的读取和写入操作。
所以,以更简单的方式结束:
- 一个表可以分为多个区域。区域是存储在开始键和结束键之间的数据的有序行范围。
- 一个 Region 的默认大小为 256MB,可以根据需要进行配置。
- 区域服务器为客户端提供一组区域。
- 一个区域服务器可以为客户端提供大约 1000 个区域。
现在从层次结构的顶部开始,我首先想向您解释 HMaster Server,它的作用类似于HDFS 中的 NameNode 。然后,在层次结构中向下移动,我将带您了解 ZooKeeper 和 Region Server。
HBase 架构:HMaster
如下图所示,您可以看到 HMaster 处理驻留在 DataNode 上的 Region Server 集合。让我们了解 HMaster 是如何做到这一点的。
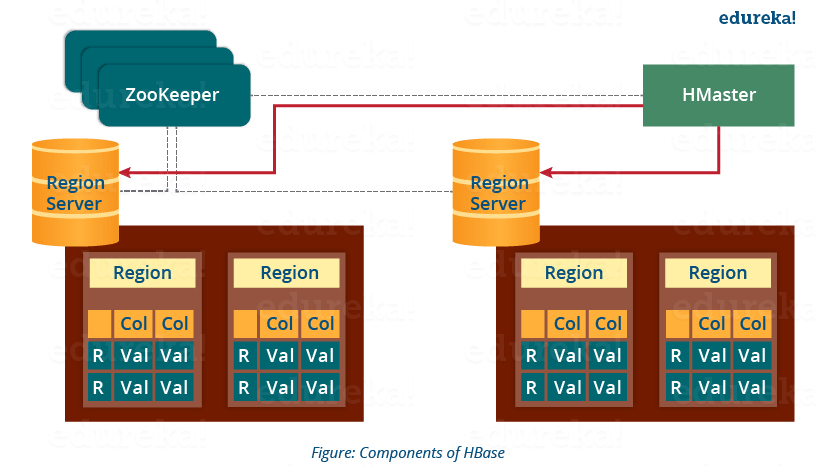
- HBase HMaster 执行 DDL 操作(创建和删除表)并将区域分配给区域服务器,如上图所示。
- 它协调和管理 Region Server(类似于 NameNode 在 HDFS 中管理 DataNode)。
- 它在启动时将区域分配给区域服务器,并在恢复和负载平衡期间将区域重新分配给区域服务器。
- 它监视集群中所有 Region Server 的实例(在 Zookeeper 的帮助下),并在任何 Region Server 关闭时执行恢复活动。
- 它提供了一个用于创建、删除和更新表的接口。
HBase 有一个庞大的分布式环境,仅靠 HMaster 不足以管理所有内容。那么,你会想知道是什么帮助 HMaster 管理这个巨大的环境?这就是 ZooKeeper 出现的地方。在了解了 HMaster 如何管理 HBase 环境后,我们将了解 Zookeeper 如何帮助 HMaster 管理环境。
HBase 架构:ZooKeeper – 协调器
下图解释了 ZooKeeper 的协调机制。
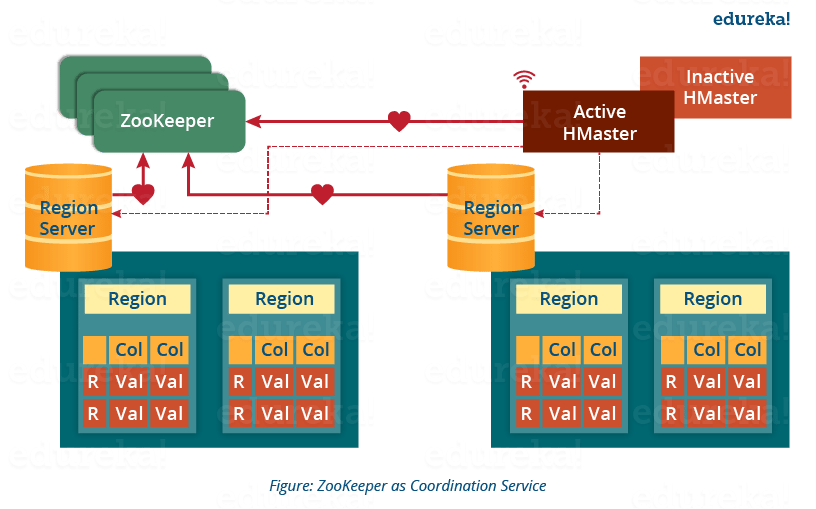
- Zookeeper 就像 HBase 分布式环境中的协调器。它有助于通过会话进行通信来维护集群内的服务器状态。
- 每个 Region Server 和 HMaster Server 都会定期向 Zookeeper 发送连续的心跳,并检查哪个服务器是活动的和可用的,如上图所示。它还提供服务器故障通知,以便可以执行恢复措施。
- 从上图可以看出,有一个不活动的服务器,它作为活动服务器的备份。如果活动服务器出现故障,它就会派上用场。
- 活动的 HMaster 向 Zookeeper 发送心跳,而非活动的 HMaster 侦听活动 HMaster 发送的通知。如果活动 HMaster 未能发送心跳,则会话将被删除,非活动 HMaster 变为活动状态。
- 而如果 Region Server 无法发送心跳,则会话将过期并通知所有侦听器。然后 HMaster 执行适当的恢复操作,我们将在本博客稍后讨论。
- Zookeeper 还维护 .META Server 的路径,这有助于任何客户端搜索任何区域。Client首先必须与.META Server核对某个区域所属的Region Server,并获取该Region Server的路径。
说到.META Server,我先给大家解释一下什么是.META Server?因此,您可以轻松地将 ZooKeeper 和 .META Server 的工作联系在一起。稍后,当我在此博客中向您解释 HBase 搜索机制时,我将解释这两者如何协同工作。
HBase 架构: 元表
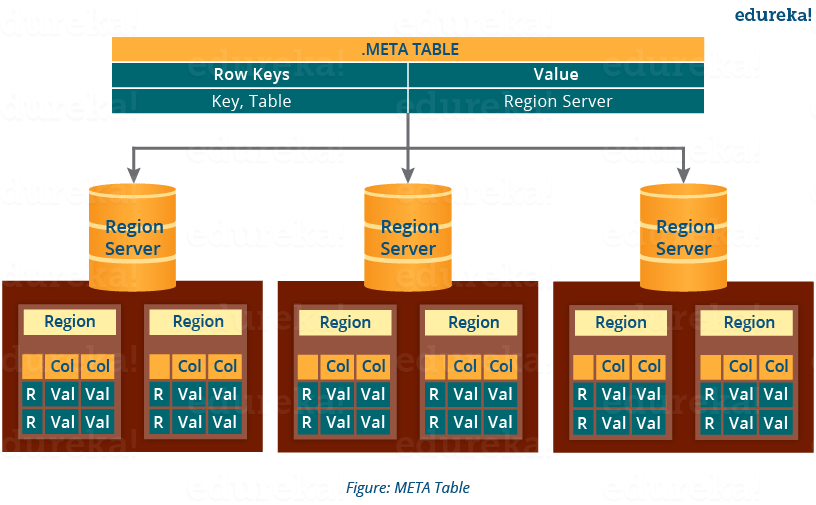
- META 表是一个特殊的 HBase 目录表。它维护了 HBase 存储系统中所有区域服务器的列表,如上图所示。
- 从图中可以看到,.META文件以键和值的形式维护表。Key 代表区域的起始键和它的 id,而值包含区域服务器的路径。
正如我在向您解释 Region 时已经讨论过的 Region Server 及其功能,因此现在我们正在向下移动层次结构,我将专注于 Region Server 的组件及其功能。稍后我将讨论搜索、阅读、写作的机制,并了解所有这些组件如何协同工作。
HBase 架构: Region Server 的组件
下图显示了区域服务器的组件。现在,我将分别讨论它们。
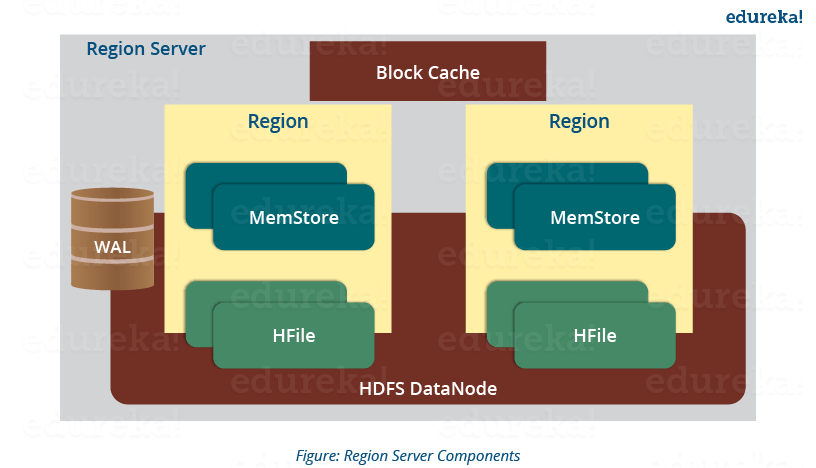
区域服务器维护在HDFS顶部运行的各种区域。区域服务器的组件是:
- WAL: 从上图中可以得出结论,Write Ahead Log (WAL) 是附加到分布式环境中每个 Region Server 的文件。WAL 存储尚未持久化或提交到永久存储的新数据。它用于恢复数据集失败的情况。
- Block Cache:从上图可以清楚的看到Block Cache位于Region Server的顶部。它将经常读取的数据存储在内存中。如果 BlockCache 中的数据最近最少使用,则该数据将从 BlockCache 中删除。
- MemStore:是写缓存。在将所有传入数据提交到磁盘或永久内存之前,它会存储所有传入数据。一个区域中的每个列族都有一个 MemStore。正如您在图像中看到的,一个区域有多个 MemStore,因为每个区域包含多个列族。数据在提交到磁盘之前按字典顺序排序。
- HFile:从上图可以看出HFile是存储在HDFS上的。因此,它将实际单元存储在磁盘上。当 MemStore 的大小超过时,MemStore 将数据提交到 HFile。
现在我们知道了 HBase 架构的主要和次要组件,我将在此解释机制和他们的协作努力。不管是读还是写,首先我们要搜索从哪里读或者从哪里写一个文件。所以,让我们了解这个搜索过程,因为这是使 HBase 非常流行的机制之一。
HBase 架构: 搜索如何在 HBase 中初始化?
如您所知,Zookeeper 存储 META 表位置。每当客户端向 HBase 发出读取或写入请求时,就会发生以下操作:
- 客户端从 ZooKeeper 检索 META 表的位置。
- 客户端然后从 META 表中请求相应行键的 Region Server 的位置来访问它。客户端将此信息与 META 表的位置一起缓存。
- 然后它将通过从相应的 Region Server 请求来获取行位置。
对于将来的引用,客户端使用其缓存来检索 META 表的位置和先前读取的行键的区域服务器。然后客户端将不会引用 META 表,直到并且除非由于区域移动或移动而导致未命中。然后它将再次请求 META 服务器并更新缓存。
与每次一样,客户端不会浪费时间从 META 服务器检索 Region Server 的位置,因此,这节省了时间并使搜索过程更快。现在,让我告诉您如何在 HBase 中进行写入。其中涉及哪些组件以及它们如何参与?
HBase 架构: HBase 写机制
下图解释了 HBase 中的写入机制。
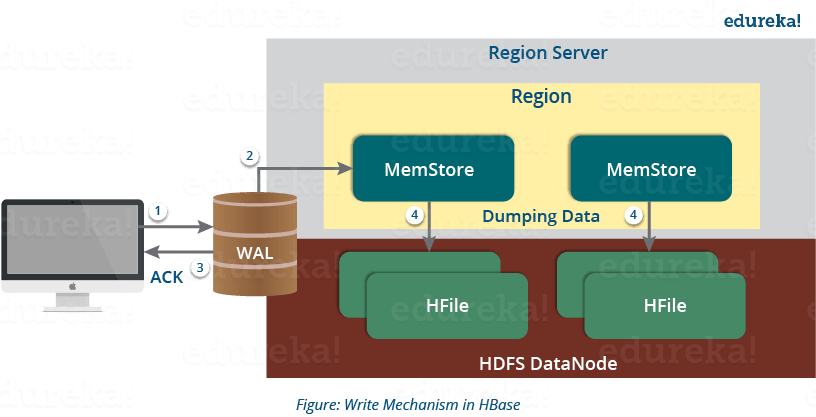
写入机制依次经过以下过程(参考上图):
步骤1:每当客户端有写请求时,客户端将数据写入WAL(Write Ahead Log)。
- 然后将编辑附加到 WAL 文件的末尾。
- 该 WAL 文件保存在每个 Region Server 中,Region Server 使用它来恢复未提交到磁盘的数据。
第 2 步:将数据写入 WAL 后,将其复制到 MemStore。
第 3 步:一旦数据放入 MemStore,客户端就会收到确认。
第 4 步:当 MemStore 达到阈值时,它将数据转储或提交到 HFile。
现在让我们深入了解一下 MemStore 在写作过程中的贡献以及它的功能是什么?
HBase 写机制- MemStore
- MemStore 总是按照字典顺序(按字典方式)将存储在其中的数据更新为已排序的 KeyValue。每个列族有一个 MemStore,因此每个列族的更新以排序的方式存储。
- 当 MemStore 达到阈值时,它会以排序的方式将所有数据转储到一个新的 HFile 中。此 HFile 存储在 HDFS 中。HBase 为每个列族包含多个 HFile。
- 随着时间的推移,HFile 的数量随着 MemStore 转储数据而增长。
- MemStore 还保存了最后写入的序列号,因此 Master Server 和 MemStore 都知道到目前为止提交了什么以及从哪里开始。当区域启动时,读取最后一个序列号,并从该编号开始新的编辑。
正如我多次讨论过的,HFile 是 HBase 架构中的主要持久存储。最后,所有的数据都提交到 HFile 中,HFile 是 HBase 的永久存储。因此,让我们看看 HFile 的属性,它可以在读写时更快地进行搜索。
HBase 架构: HBase 写入机制- HFile
- 写入按顺序放置在磁盘上。因此,磁盘读写头的运动非常少。这使得写入和搜索机制非常快。
- 每当打开 HFile 时,HFile 索引就会加载到内存中。这有助于在单次查找中查找记录。
- 预告片是一个指向 HFile 的元块的指针。它写在提交文件的末尾。它包含有关时间戳和布隆过滤器的信息。
- 布隆过滤器有助于搜索键值对,它会跳过不包含所需行键的文件。时间戳还有助于搜索文件的版本,它有助于跳过数据。
在了解写入机制和各种组件在使写入和搜索更快方面的作用之后。我将向您解释读取机制在 HBase 架构中是如何工作的?然后我们将转向提高 HBase 性能的机制,如压缩、区域拆分和恢复。
HBase 架构: 读取机制
正如我们在搜索机制中所讨论的,如果客户端的缓存中没有它,客户端首先从 .META 服务器中检索区域服务器的位置。然后它按顺序执行以下步骤:
- 为了读取数据,扫描器首先在块缓存中查找行单元。这里存储了所有最近读取的键值对。
- 如果 Scanner 未能找到所需的结果,它会移动到 MemStore,因为我们知道这是写缓存内存。在那里,它搜索最近写入的文件,这些文件尚未转储到 HFile 中。
- 最后,它将使用布隆过滤器和块缓存从 HFile 加载数据。
到目前为止,我已经讨论了 HBase 的搜索、读写机制。现在我们来看看 HBase 机制,它使 HBase 中的搜索、读取和写入变得快速。首先,我们将了解Compaction,这是其中一种机制。
HBase 架构: 压缩
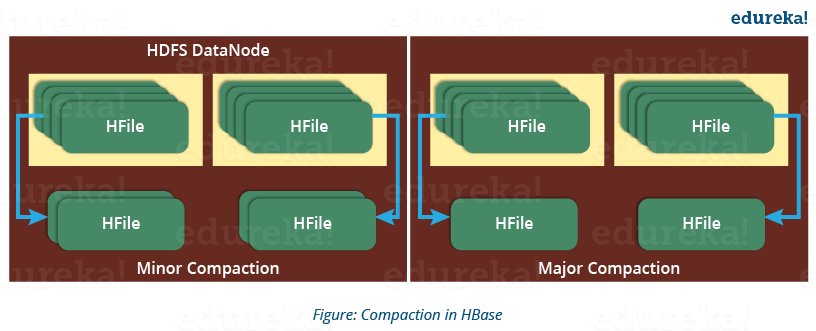
HBase 结合 HFiles 以减少存储并减少读取所需的磁盘寻道次数。这个过程称为压缩。Compaction 从一个区域中选择一些 HFile 并将它们组合起来。如上图所示,有两种类型的压缩。
- 次要压缩:HBase 自动选择较小的 HFile 并将它们重新提交到较大的 HFile,如上图所示。这称为轻微压实。它执行合并排序以将较小的 HFile 提交到较大的 HFile。这有助于优化存储空间。
- Major Compaction: 如上图所示,在Major compaction中,HBase将一个区域的较小的HFiles合并并重新提交到一个新的HFile。在这个过程中,相同的列族被放置在新的 HFile 中。它会在此过程中删除已删除和过期的单元格。它提高了读取性能。
但在此过程中,输入输出磁盘和网络流量可能会变得拥挤。这称为写放大。因此,它通常安排在低峰值负载时间。
现在我将讨论的另一个性能优化过程是 Region Split。这对于负载平衡非常重要。
HBase 架构: 区域拆分
下图说明了 Region Split 机制。

每当一个区域变大时,它就会被分成两个子区域,如上图所示。每个区域正好代表父区域的一半。然后将此拆分报告给 HMaster。这由同一个 Region Server 处理,直到 HMaster 将它们分配给新的 Region Server 以进行负载平衡。
接下来,最后但并非最不重要的一点是,我将向您解释 HBase 如何在发生故障后恢复数据。我们知道故障恢复是 HBase 的一个非常重要的特性,因此让我们了解 HBase 如何在故障后恢复数据。
HBase 架构:HBase 崩溃和数据恢复
- 每当 Region Server 出现故障时,ZooKeeper 都会通知 HMaster 故障。
- 然后 HMaster 将崩溃的 Region Server 的区域分发并分配给许多活动的 Region Server。为了恢复出现故障的 Region Server 的 MemStore 的数据,HMaster 将 WAL 分发给所有 Region Server。
- 每个 Region Server 重新执行 WAL 来为那个失败的 region 的列族构建 MemStore。
- 数据按时间顺序(按时间顺序)写入 WAL。因此,重新执行该 WAL 意味着进行所有在 MemStore 文件中所做和存储的更改。
- 所以,在所有的 Region Servers 执行完 WAL 之后,所有列族的 MemStore 数据都被恢复了。
我希望这篇博客能帮助您了解 HBase 数据模型和 HBase 架构。希望你喜欢它。现在,您可以将 HBase 的特性(我在之前的HBase 教程博客中解释过)与 HBase 架构联系起来,并了解它的内部工作原理。现在您已经了解了 HBase 的理论部分,您应该转向实践部分。记住这一点,我们的下一篇Hadoop 教程系列博客将解释一个示例HBase POC。

- 点赞
- 收藏
- 关注作者
评论(0)