❤️两万字,50个pandas高频操作【图文并茂,值得收藏】❤️

重点,敲黑板了
- 首先,本文遵循,传统教学,点到为止!只介绍个人使用比较频繁的一些函数或处理方式。
- 本文的示例只是演示所用,示例一般是不修改原数据的,如果代码会修改原数据会标明(在原数据上进行修改),自己使用时一定要注意是否修改了原数据。一旦报错,首先检查自己的代码是否改变了原数据。
# 未修改原数据 df.drop('name', axis = 1) # 修改原数据 df.drop('name', axis = 1, inplace=True) # 修改原数据 df = df.drop('name', axis = 1)
- 1
- 2
- 3
- 4
- 5
- 6
pandas之所以强大是因为它拥有各种数据处理的函数,各个函数互相组合,灵活多变,并且与numpy、matplotlib、sklearn、>pyspark、sklearn等众多科学计算库交互,真正想要融会贯通实战是必经之路。- 原创不易,码字也很累。如果觉得文章不错,💗 一定记得三连哦💗 ~ 在此提前感谢各位。

文章目录
DataFrame创建
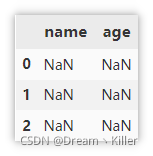
创建空的 DataFrame
创建一个空的 , 包含三行空数据。
df = pd.DataFrame(columns=['name', 'age'], index=[0, 1, 2])
- 1
常规 DataFrame 创建方式
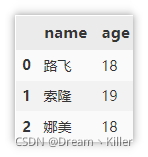
这里只介绍常见的三种,数组创建、字典创建、外部文件创建。常见文件读取的时候直接指定文件路径即可,对于 xlsx 文件可能存在多个 sheet 这时就需要指定 sheet_name 。
# 数组创建
df = pd.DataFrame(data=[['路飞', 18],
['索隆', 19],
['娜美', 18]],
columns=['name', 'age'])
# 通过字典创建
df = pd.DataFrame({'name': ['路飞','索隆', '娜美'],
'age':[18, 19, 18]})
# 通过外部文件创建,csv,xlsx,json等
df = pd.read_csv('XXX.csv')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
DataFrame存储
常见存储方式(csv, json, excel, pickle)
保存时,一般情况下是不需要保存索引的,因为读取的时候会自动生成索引。
df.to_csv('test.csv', index=False) # 忽略索引
df.to_excel('test.xlsx', index=False) # 忽略索引
df.to_json('test.json') # 保存为json
df.to_pickle('test.pkl') # 保存为二进制格式
- 1
- 2
- 3
- 4
DataFrame查看数据信息
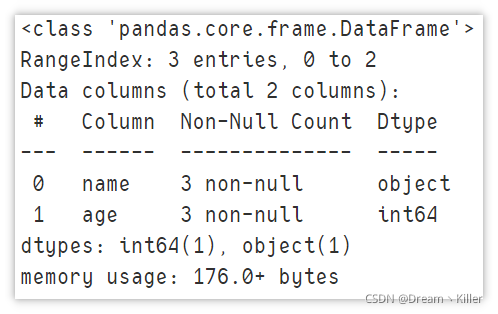
显示摘要信息
在我们使用 DataFrame 之前都会查看数据的信息,个人首选 info ,它展现了数据集的行列信息,以及每列中的非空值的数量。
df.info()
- 1
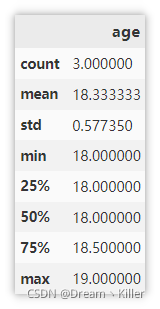
显示描述性统计信息
能够较为直观的查看数值列的基本统计信息。
df.describe()
- 1
显示 前 / 后 n行
默认显示5行,可指定显示的行数。
df.head(n) # 可指定整数,输出前面n行
df.tail(n) # 可指定整数,输出后面n行
- 1
- 2
显示索引、列信息
显示索引及列的基本信息。
df.columns # 列信息
df.index # 索引信息
- 1
- 2

显示每列的数据类型
显示列的名称及对应的数据类型。
df.dtypes
- 1

显示占用的内存大小
显示给列占用内存的大小,单位是 :字节(byte)。
df.memory_usage()
- 1

定位某行数据
重点:无论是 loc 还是 iloc 使用的要领都是先指定行,再指定列,并且行与列表达式用 , 分隔。如:df.loc[:, :] 获取所有行所有列的数据。
使用 loc() 定位
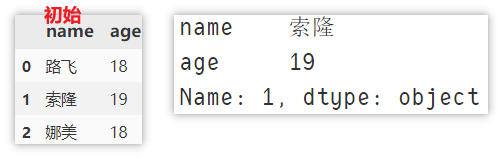
比如现在要定位 [索隆] 这行数据,有以下
df.loc[1, :] # loc[index , columns] 行索引,列名,返回 Series 对象
df.loc[df['age'] > 18] # 返回 DataFrame 对象
# 或者 df[df['age'] > 18]
# df.loc[df['name'] == '索隆']
- 1
- 2
- 3
- 4

使用 iloc 定位
使用 iloc 取第二行(索引从0开始),所有列的数据。
df.iloc[1, :] # iloc[index1, index2] 行索引, 列索引
- 1
添加一行数据
使用 loc 定位并添加
使用 loc 定位到 index = 3 的行,再进行赋值(在原数据上进行修改)
df.loc[len(df)] = ['乔巴', 3]
- 1

使用 append 添加
append 添加数据时需要指定列名,列值,如果某列未指定的话,则默认填充 NaN。
df.append({'name': '山治', 'age': 19}, ignore_index=True)
- 1

删除数据
根据列名删除列
使用 drop 来删除某列,指定要删除的轴,与对应 列/行 的 名称/索引。
df.drop('name', axis = 1) # 删除单列
df.drop(['name', 'age'], axis = 1) # 删除多列
- 1
- 2

根据索引删除行
与上面删除列的方式相似,不过这里指定的是索引。
df.drop(0, axis=0) # 删除单行
df.drop([0, 1], axis=0) # 删除多行
- 1
- 2

使用 loc 定位数据并删除
先使用 loc 定位某条件的数据,再获取索引 index ,然后使用 drop 删除。
df.drop(df.loc[df['name'] == '娜美'].index, axis=0) # 删除定位到的行
- 1

使用 del 删除列
del 是在原数据上进行修改,使用是要注意。
del df['age']
- 1
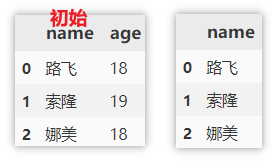
同时删除行、列
drop 也可以同时指定行列进行删除,这里删除第一、二行并删除 age 列。
df.drop(columns=['age'], index=[0, 1])
- 1
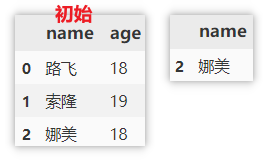
删除重复值
- 指定
subset,则根据指定的列作为参考进行去重,即如果某两行a值相同,则会删除第二次的出现的那一行,只保留第一次 - 不指定
subset,则根据所有列作为参考进行去重,只有两行数据 完全相同 才会进行去重。
df.drop_duplicates(subset=['a'], keep='first')
df.drop_duplicates(keep='first')
- 1
- 2

筛查重复值
示例数据
df = pd.DataFrame({'name':['Python',
'Python',
'Java',
'Java',
'C'],
'count': [2, 2, 6, 8, 10]})
- 1
- 2
- 3
- 4
- 5
- 6

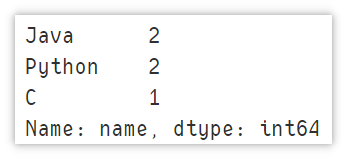
判断某列是否有重复值
使用 values_counts() 对列中各值出现次数进行统计。结果默认按照降序进行排列,只需要判断第一行值的出现次数是否为1即可判断是否存在重复值。
df['a'].value_counts()
- 1
使用 drop_duplicates() 对重复值进行删除,只保留第一次出现的值,判断处理后的值是否与原 df 相等,如果 False 就表示有重复值。
df.equals(df.drop_duplicates(subset=['a'], keep='first'))
False
- 1
- 2
- 3
判断 DataFrame 是否有重复行
同样是使用 drop_duplicates() 对重复值进行删除,只保留第一次出现的值,此时不使用 subset 参数设置列,默认为全部列,判断处理后的值是否与原 df 相等,如果 False 就表示有重复值。
df.equals(df.drop_duplicates(keep='first'))
False
- 1
- 2
- 3
统计重复行的数量
注意这里的统计是参照所有列来的,只有两行完全相同才会判断为重复行,所以统计的结果是 1 。
len(df) - len(df.drop_duplicates(keep="first"))
1
- 1
- 2
- 3
显示重复的数据行
先删除重复的行,只保留第一次出现的,得到一个 行唯一 的数据集,再使用 drop_duplicates() 删除掉 df 中存在重复的所有数据,这次不保留第一次出现的重复值,将上述两个结果集进行合并,使用 drop_duplicates() 对新生成的数据集进行去重,即可得到重复行的数据。
df.drop_duplicates(keep="first")\
.append(df.drop_duplicates(keep=False))\
.drop_duplicates(keep=False)
- 1
- 2
- 3

缺失值处理
查找缺失值
缺失值为 True ,非缺失值为 False 。
df.isnull()
- 1
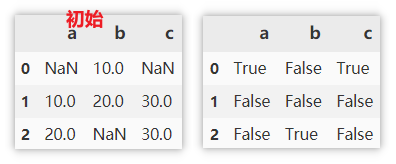
查找非缺失值
非缺失值为 True ,缺失值为 False 。
df.notnull()
- 1
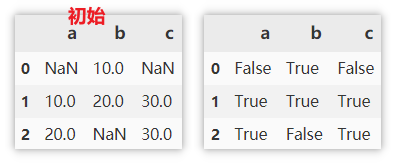
显示有缺失值的行
.isnull:查找缺失值,主要为了将缺失值的位置标 True。
.T:行列转置,为下一步 any 做准备。
.any:一个序列中满足一个 True,则返回 True。
df[df.isnull().T.any()]
- 1

删除缺失值
这里的参数需要注意的比较多,这里着重讲一下。
- axis:0 行,1 列
- how:
- any:如果有 NaN,删除该行或列。
- all:如果所有值都是 NaN,删除该行或列。
- thresh:指定 NaN 的数量,当 NaN 数量达到才删除。
- subset:要考虑的数据范围,如:删除缺失行,就用subset指定参考的列,默认是所有列。
- inplace:是否修改原数据。
# 某行如果有缺失值,则删除这一行
df.dropna(axis=0, how='any')
# 某列如果有缺失值,则删除这一列
df.dropna(axis=1, how='any')
- 1
- 2
- 3
- 4

填充缺失值
数字或字符串填充
直接指定要填充的数字或字符串。
df.fillna(0)
- 1

用缺失值 前/后 的值填充
- 用缺失值的前一个值(该列上面一个值)填充,如果缺失值在第一行则不填充
- 用缺失值的后一个值(该列下面一个值)填充,如果缺失值在最后一行则不填充
df.fillna(method='pad')
df.fillna(method='bfill')
- 1
- 2

用缺失值所在列的 均值/中位数 等填充
可以用该列的统计信息来进行填充。如使用 mean、median、max、min、sum 填充等。
df.fillna(df.mean())
- 1

列操作
修改列名
df.columns 是直接指定新的列名来替换所有的列名。 (在原数据上进行修改)
rename() 需要指定原名与新名来进行替换。
df.columns = ['new_name', 'new_age']
df.rename(columns=({'name':'new_name','age':'new_age'}))
- 1
- 2
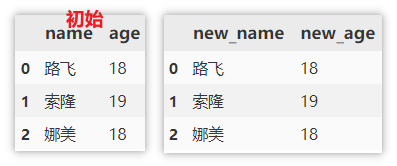
修改列类型
使用 astype 来修改列类型。
df['age'].astype(str)
- 1
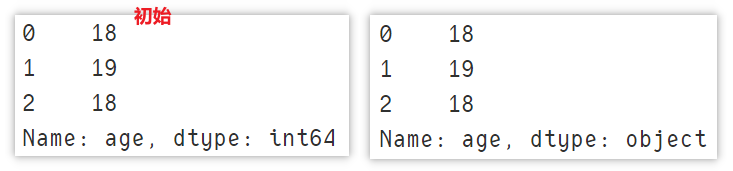
将列进行拆分得到多列
split 只能对字符串列进行拆分。
df[['name1', 'name2']] = df['name'].str.split(',', expand=True)
- 1

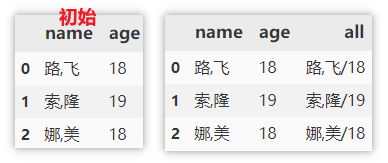
将多列合并成新列
同样合并也是字符串类型的列才能进行合并。
df['all'] = df['name'] + '/' + df['age'].astype(str)
- 1
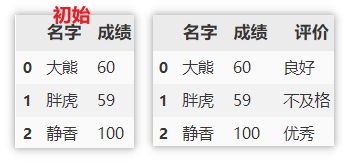
对数值列分区
对于数值列,实际使用的时候可能需要根据指定的范围,将这些数值变为标签值,如衡量产品的指标及格、不及格,成绩是否优秀等。使用是需要指定数值列、各个标签的临界值,临界值的开闭情况(示例中:默认 left=True ,指定 right=False ,即左闭右开),最后指定标签的名称即可。
df['评价'] = pd.cut(df['成绩'], [0, 60, 80, np.inf],
right=False, labels=['不及格', '良好', '优秀'])
- 1
- 2
排序
索引排序
对行索引降序排序
df.sort_index(axis=0, ascending=False)
- 1
对列索引降序排序
df.sort_index(axis=1, ascending=False)
- 1

重置索引
将索引重新排序,原来的索引不保留。
df.reset_index(drop=True)
- 1
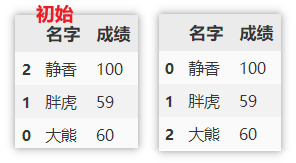
值排序
先按照名字降序排序,再对相同名字下的成绩进行降序排序。
df.sort_values(by=['名字', '成绩'], axis=0, ascending=False)
- 1

创建排名列
使用 rank 来进行排名,主要参数 method 的取值含义如下:
method |
含义 |
|---|---|
average |
默认值,在名次一样的分组中,为各个值分配平均排名(平均数),排名之间存在跳跃 |
min |
使用分组中的最小排名,排名之间存在跳跃 |
max |
使用分组中的最大排名,排名之间存在跳跃 |
first |
按值在原始数据中的出现顺序进行排名,排名之间存在跳跃 |
dense |
同一个分组的排名相同,排名之间不存在跳跃 |
现在按照 成绩 列对每行数据进行排名,并新建排名列,几种排名方式下面都已给出。
df['排名'] = df['成绩'].rank(method='average', ascending=False)
- 1

分组
对行分组统计
现在对各人的成绩进行分组计算,分别计算总和、均值、最大值。
df.groupby(['名字']).sum()
df.groupby(['名字']).mean()
df.groupby(['名字']).max()
- 1
- 2
- 3

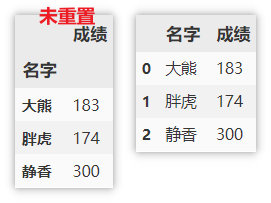
注意:此时的索引为 名字,如果想要重置索引,可以使用如下方式。
df.groupby(['名字']).sum().reset_index()
- 1
对不同列使用不同的统计函数
agg() 是指定函数使用在某个数列上,然后返回标量值。
apply() 是先将数据拆分 >>> 再应用 >>> 最后汇总的过程(只能应用单个函数)。返回多维的数据。
df.groupby(['名字']).agg({'成绩':['sum','mean','max']})
df.groupby(['名字']).apply(max)
- 1
- 2

DataFrame合并
pandas中的合并函数主要是:merge()、concat()、append(),一般用来连接两个及以上 DataFrame 。其中,concat(), append() 用来纵向连接 DataFrame 对象, merge() 用来横向连接 DataFrame 对象。
三者对比:
concat()
- 连接多个DataFrame
- 设置特定的键(key)
append()
- 连接多个DataFrame
merge()
- 指定列来连接DataFrame
merge()
on 若指定则该列必须同时出现在这两个 DataFrame 中,默认值为两个 DataFrame 列中的交集,在本例中即使不指定 on ,实际默认值也会按照 name 列来进行合并。
how 参数详解:
- inner:根据
on指定的列取交集。 - outer:根据
on指定的列取并集。 - left:根据
on指定的列并以左连接的方式合并。 - right:根据
on指定的列并以右连接的方式合并。
pd.merge(df1, df2, on='name', how = "inner")
pd.merge(df1, df2, on='name', how = "outer")
pd.merge(df1, df2, on='name', how = "left")
pd.merge(df1, df2, on='name', how = "right")
- 1
- 2
- 3
- 4

concat()
concat() 可以多个 DataFrame 进行合并,根据实际情况可以选择纵向合并还是横向合并。具体看下面的示例。
# 多个DataFrame纵向合并取交集
pd.concat([df1, df2], ignore_index=True, join='inner',axis=0)
# 多个DataFrame纵向合并取并集
pd.concat([df1, df2], ignore_index=True, join='outer',axis=0)
# 多个DataFrame横向合并取交集
pd.concat([df1, df2], ignore_index=False, join='inner',axis=1)
# 多个DataFrame横向合并取并集
pd.concat([df1, df2], ignore_index=False, join='outer',axis=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

另外还可以指定 key ,在索引的位置添加原数据的名称。
pd.concat([df1, df2], ignore_index=False, join='outer', keys=['df1', 'df2'])
- 1

append()
append() 常用于纵向合并,也可以多个 DataFrame 进行合并。
df1.append(df2, ignore_index=True)
df1.append([df1, df2], ignore_index=True)
- 1
- 2

DataFrame时间处理
示例数据

将字符串列转化成时间序列
有时从 csv 或 xlsx 文件中读取的时间,是字符串(Object)类型,这时就需要将其转化成 datetime 类型,方便后续对时间的处理。
pd.to_datetime(df['datetime'])
- 1
将时间列作为索引
对于大部分时间序列数据,我们都可以将该列作为索引,来最大的利用时间。这里 drop=False 选择不删除 datetime 列。
df.set_index('datetime', drop=False)
- 1

通过索引获取 1月 的数据,这里显示前五行。
df.loc['2021-1'].head()
- 1

通过索引获取 1~3月 的数据。
df.loc['2021-1':'2021-3'].info()
- 1

获取时间的各个属性
这里给出一般需求中可能会用到的属性,同时给出各个方法的实例。
| 常见属性 | 描述 |
|---|---|
date |
获取日期 |
time |
获取时间 |
year |
获取年份 |
month |
获取月份 |
day |
获取天 |
hour |
获取小时 |
minute |
获取分钟 |
second |
获取秒 |
dayofyear |
数据处于一年中的第几天 |
weekofyear |
数据处于一年中的第几周(新版使用 isocalendar().week) |
weekday |
数据处于一周中的第几天(数字 周一为0) |
day_name() |
数据处于一周中的第几天(英文 Monday) |
quarter |
数据处于一年中的第几季度 |
is_leap_year |
是否为闰年 |
这里随便选第 100 行的日期做示例,各个属性的结果均以注释的形式展示。
df['datetime'].dt.date[100]
# datetime.date(2021, 4, 11)
df['datetime'].dt.time[100]
# datetime.time(11, 50, 58, 995000)
df['datetime'].dt.year[100]
# 2021
df['datetime'].dt.month[100]
# 4
df['datetime'].dt.day[100]
# 11
df['datetime'].dt.hour[100]
# 11
df['datetime'].dt.minute[100]
# 50
df['datetime'].dt.second[100]
# 58
df['datetime'].dt.dayofyear[100]
# 101
df['datetime'].dt.isocalendar().week[100]
# 14
df['datetime'].dt.weekday[100]
# 6
df['datetime'].dt.day_name()[100]
# 'Sunday'
df['datetime'].dt.quarter[100]
# 2
df['datetime'].dt.is_leap_year[100]
# False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
重采样 resample()
重采样分为 降采样 和 升采样 两种。
降采样指的是采样的时间频率低于原时间序列的时间频率,同时来讲就是一个聚合操作。看示例,下面获取各季度的 count 列平均值。Q 代表 quarter 表示按季度采样。
df.resample('Q',on='datetime')["count"].mean()
- 1
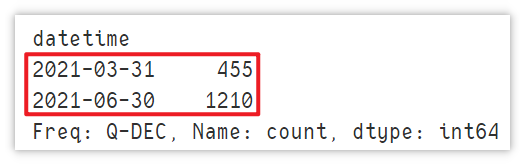
注意:此时的输出的最大时间为06-30, 并不是实际数据中的 05-31。 但是并不影响计算。
升采样与降采样相反,指的是采样的时间频率高于原时间序列的时间频率,相当于获取更细纬度的时间数据,但这样往往会造成数据中存在大量空值,实际用的不多,这里就不展开讲解了。
DataFrame遍历方式
iterrows() - 遍历行(索引,列值序列)
按行进行遍历,获取行的索引与列值序列,速度较慢,直接看例子。
for index, row in df.iterrows():
print(index)
print(row)
print(row['name'])
print(row['age'])
break # 演示所用,只显示一行
- 1
- 2
- 3
- 4
- 5
- 6

iteritems() - 遍历(列名,值)
按列进行遍历,获取列名与该列的值。
for column, value in df.iteritems():
print(column)
print(value)
break # 演示所用,只显示一行
- 1
- 2
- 3
- 4
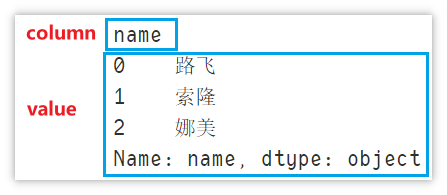
itertuples() - 遍历行 (索引,列值A,列值B…)
按行进行遍历,获取行的索引与列值,与 iterrows 的不同之处是索引与列值包含在一起,用 info[0] 获取索引
for info in df.itertuples():
print(info[0])
print(info[1])
print(info[2])
break # 演示所用,只显示一行
- 1
- 2
- 3
- 4
- 5

这就是本文所有的内容了,如果感觉还不错的话。❤ 记得三连支持哦!!!❤
后续会继续分享各种干货,如果感兴趣的话可以点个关注不迷路哦~。

文章来源: blog.csdn.net,作者:Dream丶Killer,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_43965708/article/details/120381927

- 点赞
- 收藏
- 关注作者
评论(0)