Hadoop Streaming:用 Python 编写 Hadoop MapReduce 程序

随着数字媒体、物联网等发展的出现,每天产生的数字数据量呈指数级增长。这种情况给创建下一代工具和技术来存储和操作这些数据带来了挑战。这就是 Hadoop Streaming 的用武之地!下面给出的图表描绘了从 2013 年起全球每年产生的数据增长情况。 IDC 估计,到 2025 年,每年产生的数据量将达到 180 Zettabytes!
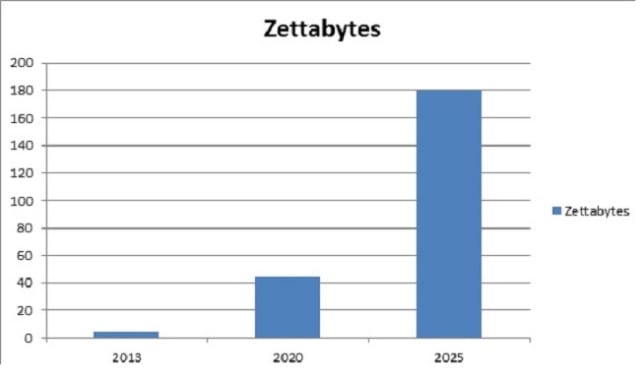
IBM 表示,每天有近 2.5 千万字节的数据被创建,其中 90% 的世界数据是在过去两年中创建的!存储如此庞大的数据量是一项具有挑战性的任务。Hadoop 可以比传统的企业数据仓库更有效地处理大量结构化和非结构化数据。它跨分布式计算机集群存储这些庞大的数据集。Hadoop Streaming 使用 MapReduce 框架,该框架可用于编写应用程序来处理海量数据。
由于 MapReduce 框架基于 Java,您可能想知道如果开发人员没有 Java 经验,他/她如何工作。好吧,开发人员可以使用他们喜欢的语言编写 mapper/Reducer 应用程序,而无需掌握太多 Java 知识,使用Hadoop Streaming而不是切换到 Pig 和 Hive 等新工具或技术。
什么是 Hadoop 流?
Hadoop Streaming 是 Hadoop 发行版附带的实用程序。它可用于执行大数据分析程序。Hadoop 流可以使用 Python、Java、PHP、Scala、Perl、UNIX 等语言执行。该实用程序允许我们使用任何可执行文件或脚本作为映射器和/或化简器来创建和运行 Map/Reduce 作业。例如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar
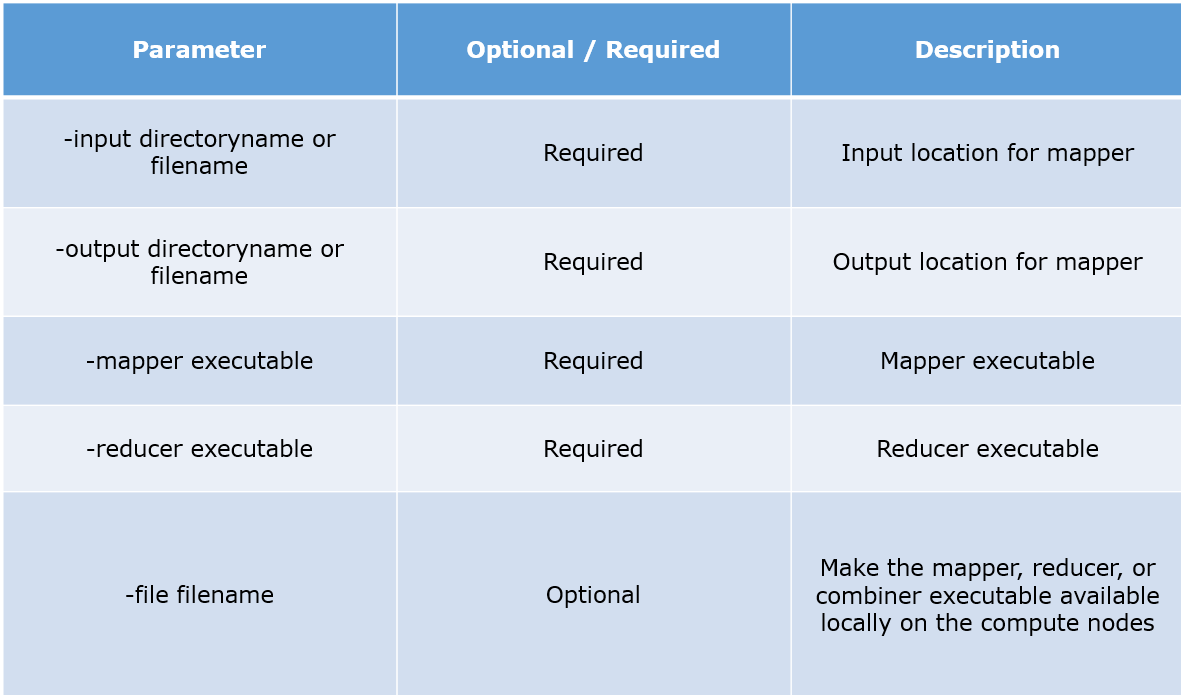
-input myInputDirs
-输出我的输出目录
-文件夹/垃圾箱/猫
-减速器/bin/wc
参数说明:
Python MapReduce 代码:
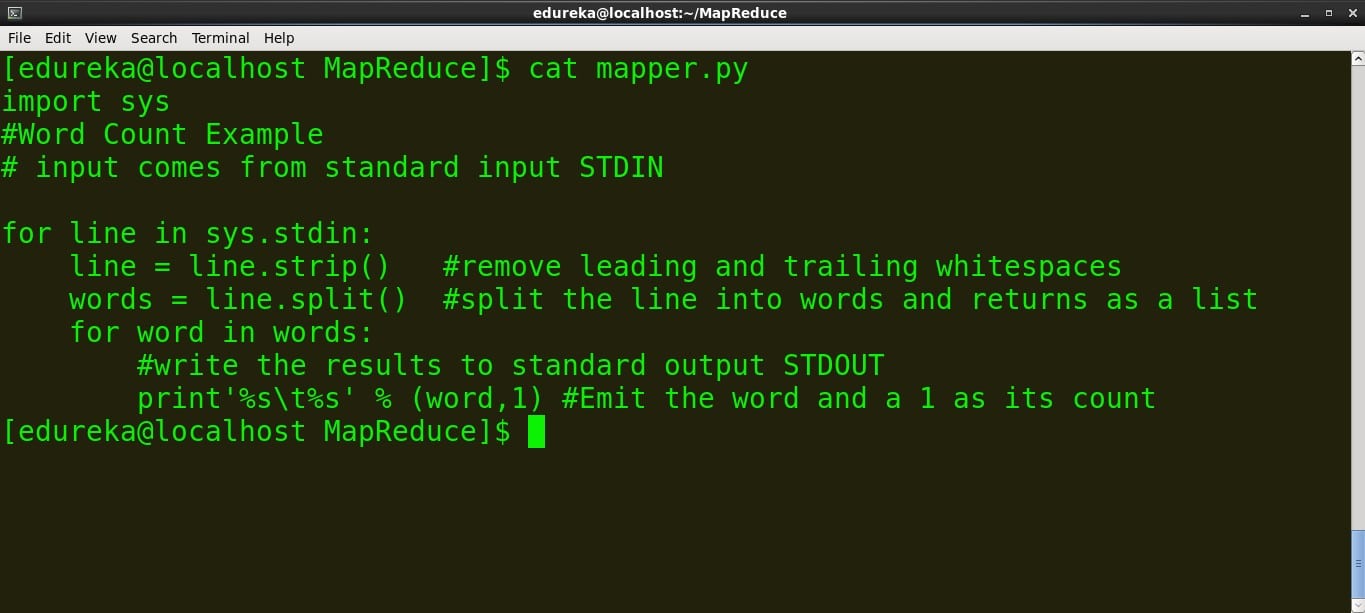
mapper.py
#!/usr/bin/python
import sys
#Word Count Example
# input comes from standard input STDIN
for line in sys.stdin:
line = line.strip() #remove leading and trailing whitespaces
words = line.split() #split the line into words and returns as a list
for word in words:
#write the results to standard output STDOUT
print'%s %s' % (word,1) #Emit the word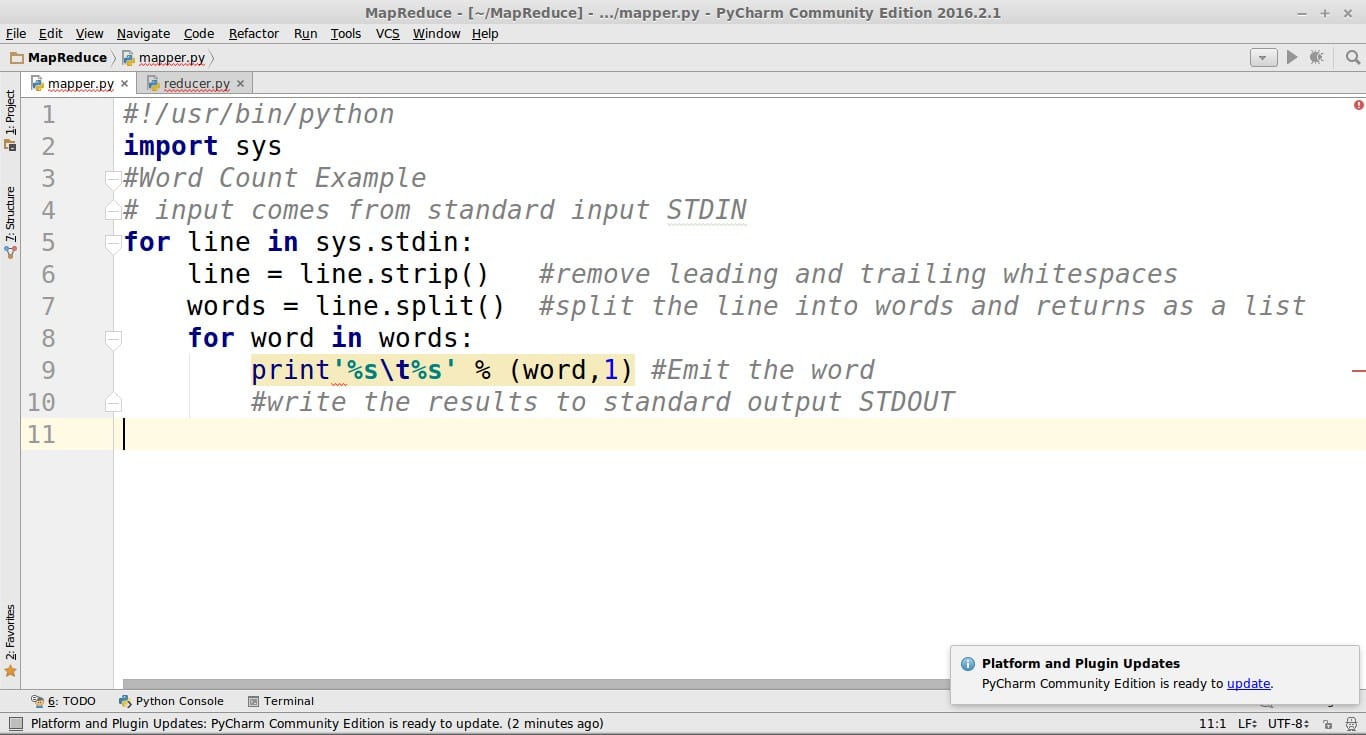
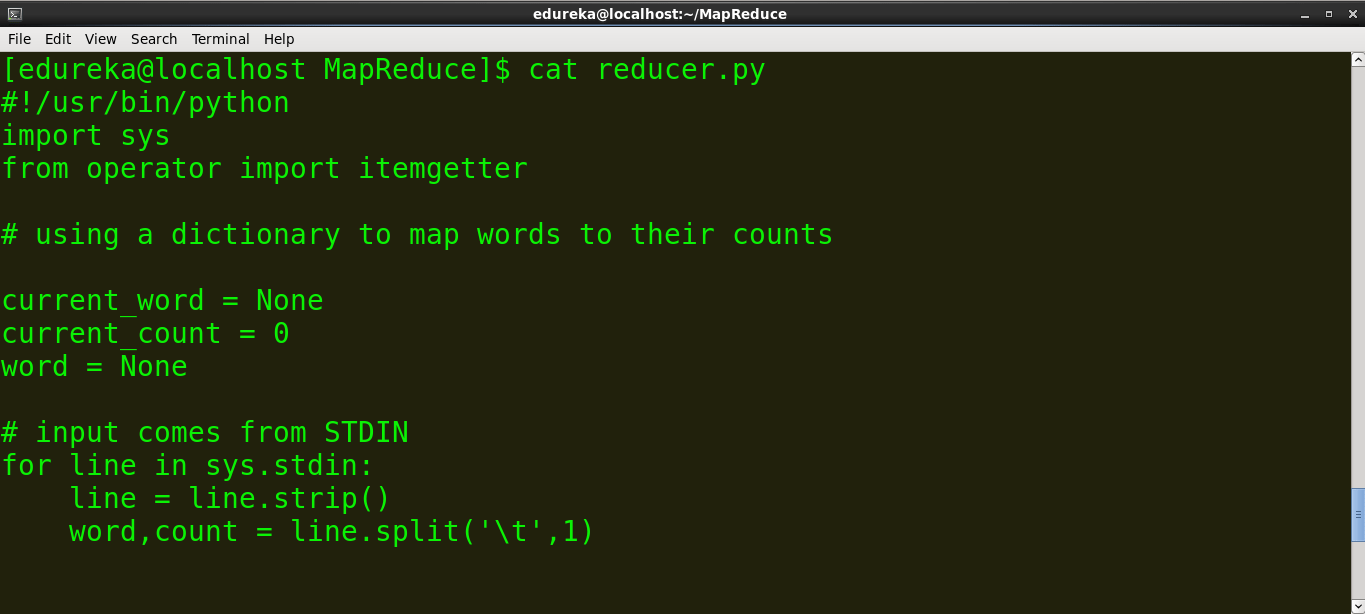
reducer.py
#!/usr/bin/python
import sys
from operator import itemgetter
# using a dictionary to map words to their counts
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
line = line.strip()
word,count = line.split(' ',1)
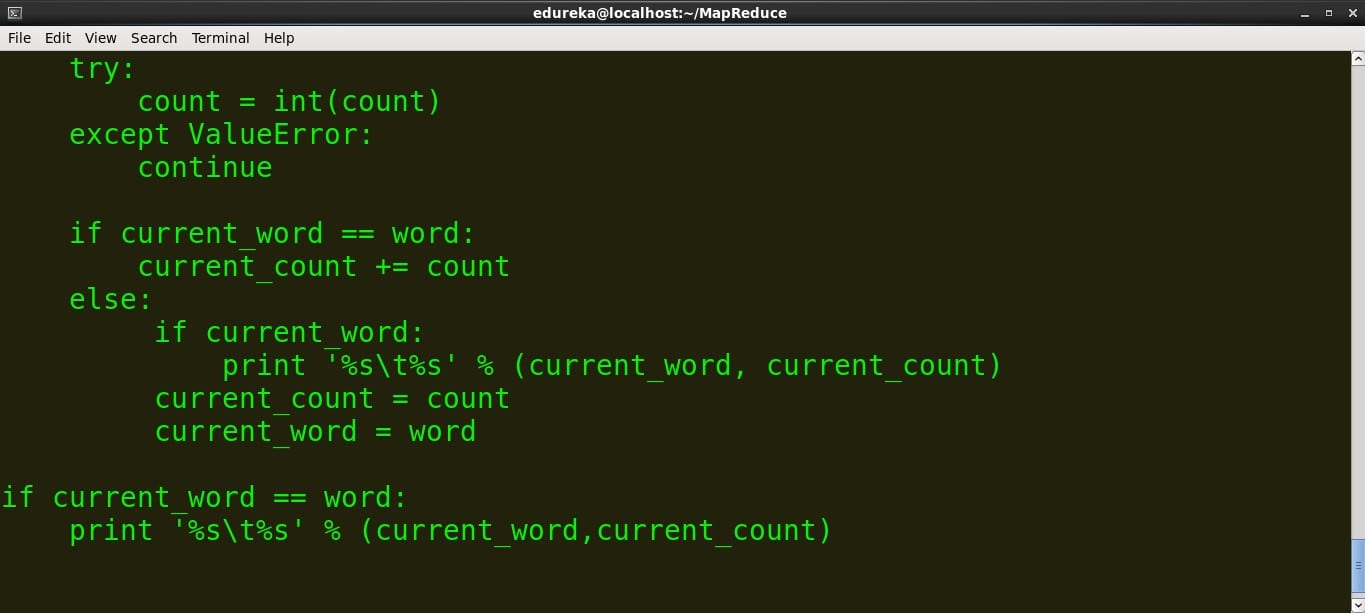
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print '%s %s' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print '%s %s' % (current_word,current_count)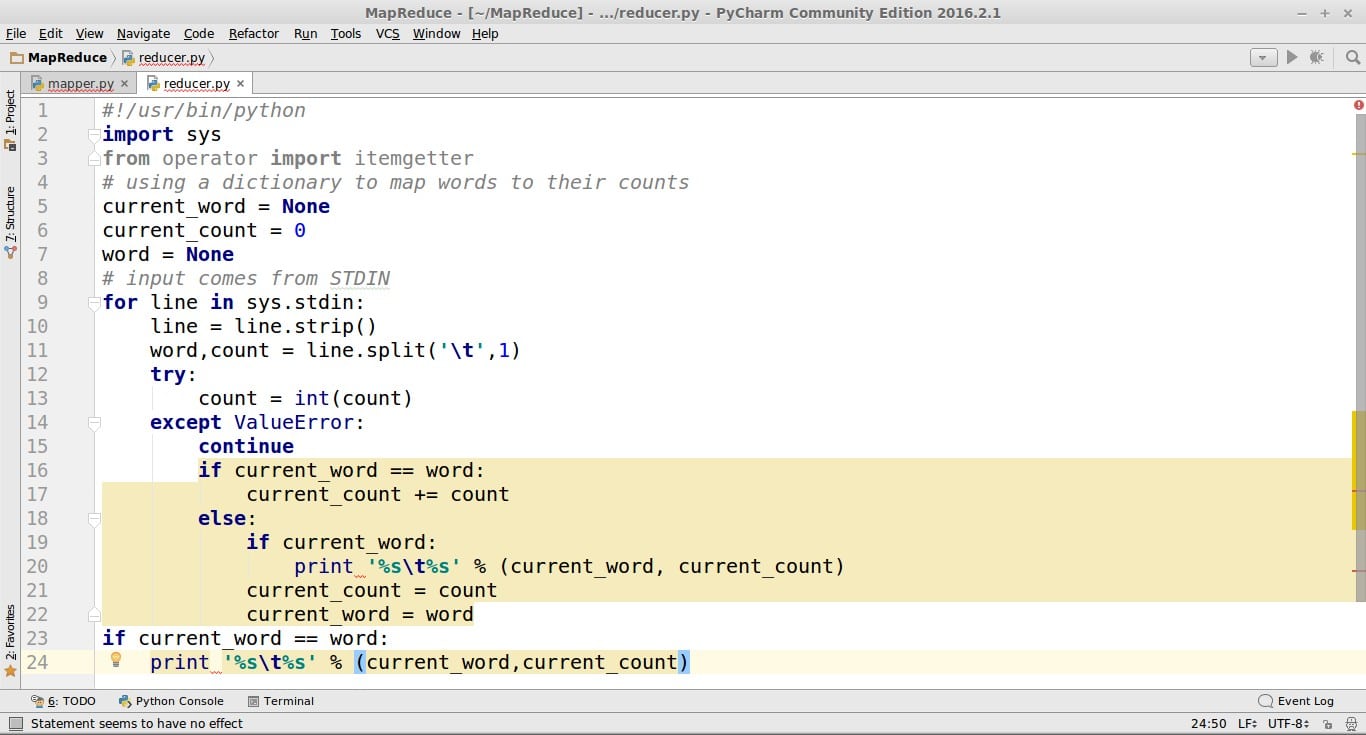
跑:
- 创建一个包含以下内容的文件并将其命名为 word.txt。
猫鼠狮鹿虎狮象狮鹿
- 将 mapper.py 和 reducer.py 脚本复制到上述文件所在的同一文件夹中。
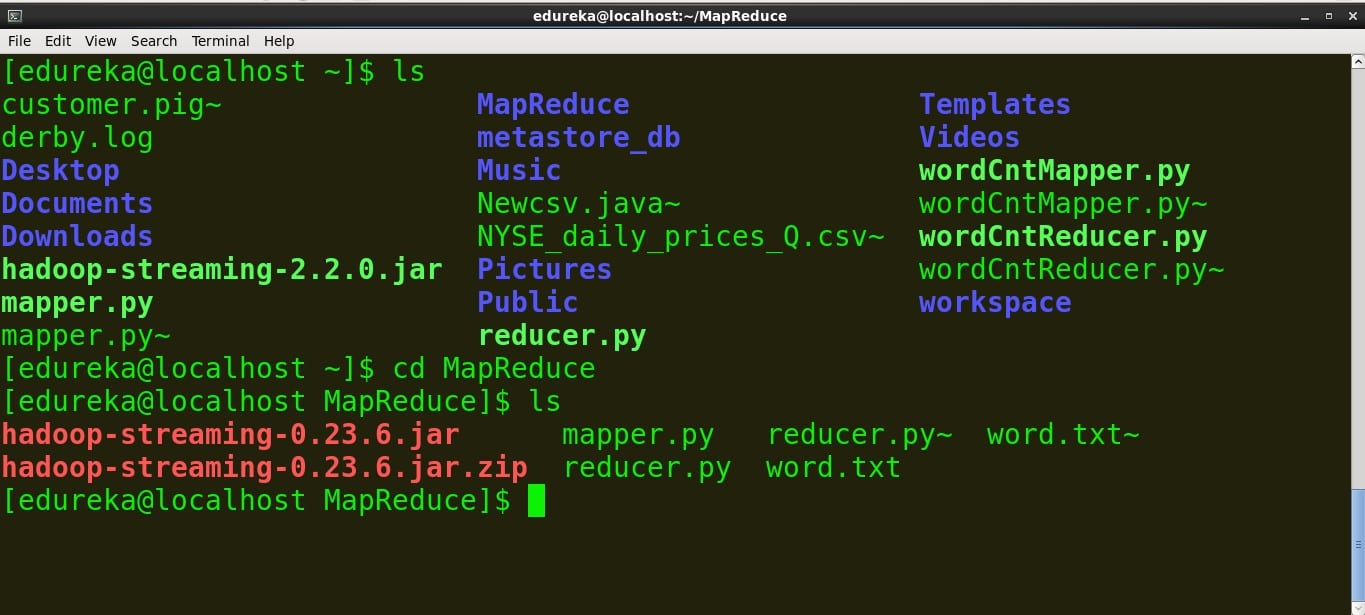
- 打开终端并找到文件所在的目录。 命令:ls:列出目录中的所有文件cd:更改目录/文件夹
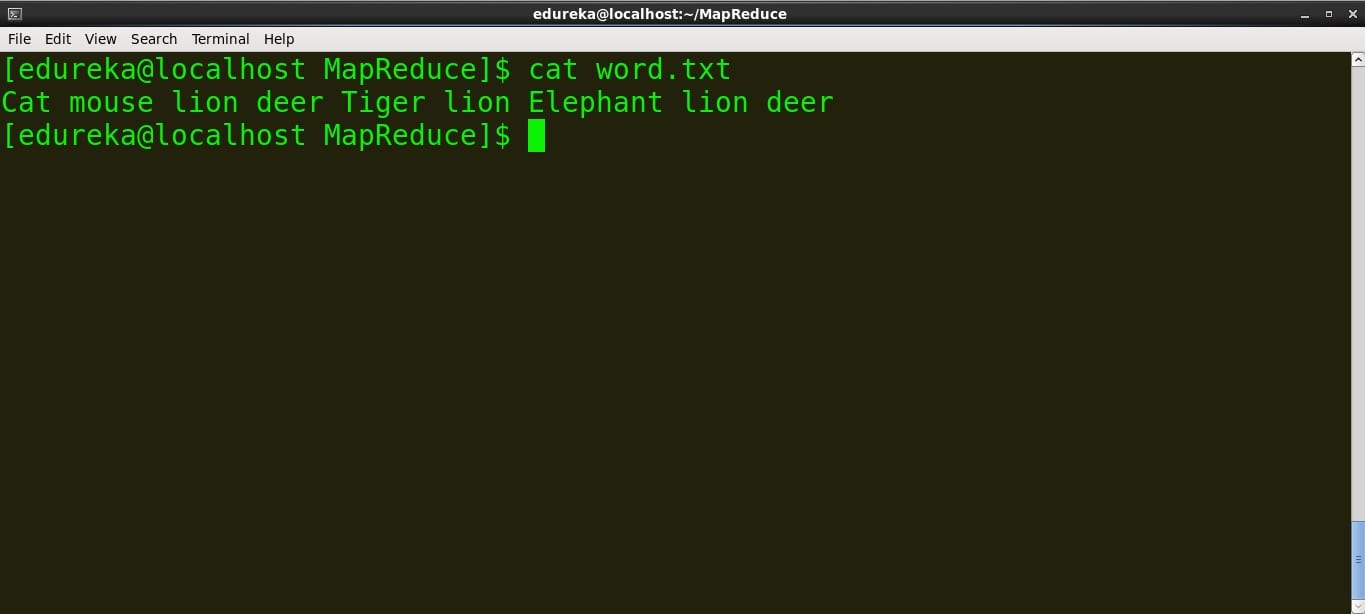
- 查看文件的内容。
命令:cat file_name
> mapper.py 的内容
命令:cat mapper.py
>reducer.py 的内容
命令:cat reducer.py
我们可以在本地文件(例如:word.txt)上运行 mapper 和 reducer。为了在 Hadoop 分布式文件系统 (HDFS) 上运行 Map 和 Reduce,我们需要Hadoop Streaming jar。所以在我们在 HDFS 上运行脚本之前,让我们在本地运行它们以确保它们工作正常。
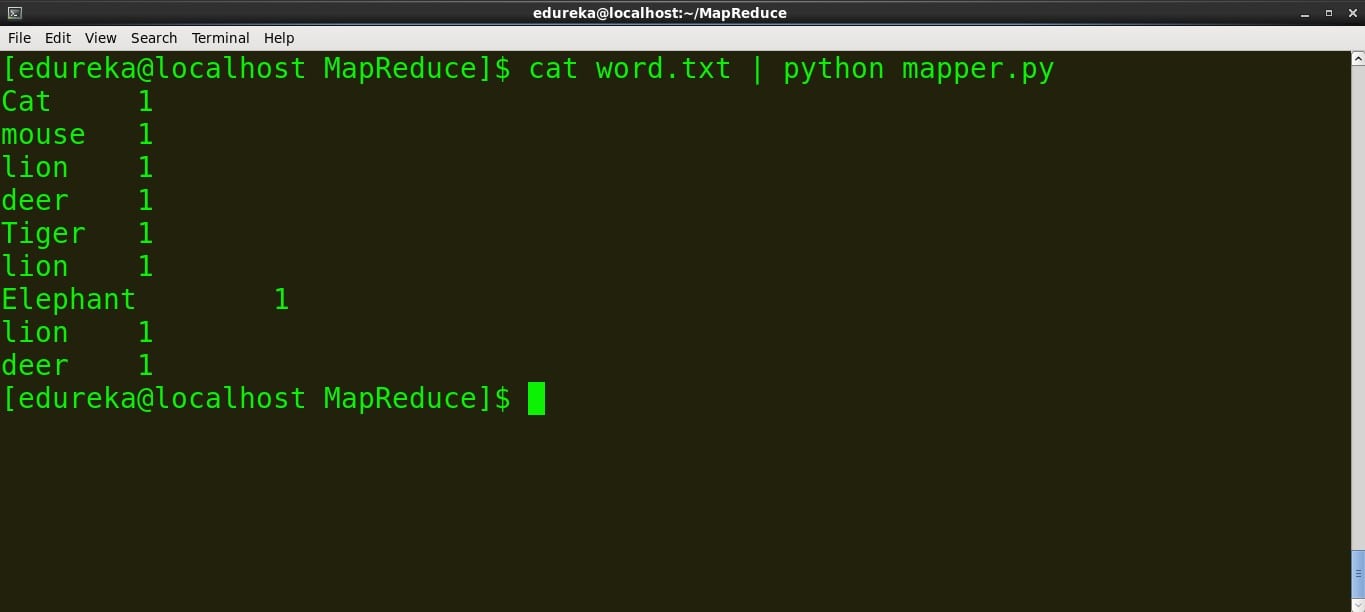
>运行映射器
命令:cat word.txt | python mapper.py
>运行reducer.py
命令: cat word.txt | python mapper.py | sort -k1,1 | python reducer.py
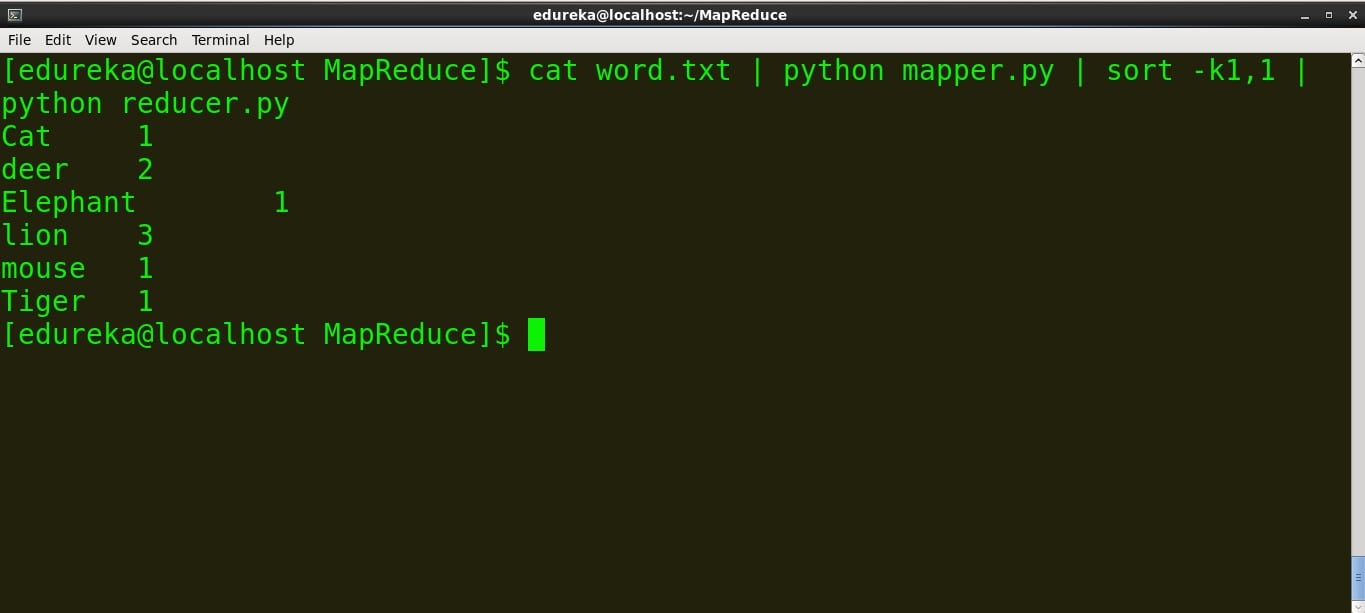
我们可以看到映射器和减速器按预期工作,因此我们不会面临任何进一步的问题。
在 Hadoop 上运行Python 代码
在我们在 Hadoop 上运行 MapReduce 任务之前,将本地数据(word.txt)复制到 HDFS
> 示例:hdfs dfs -put source_directory hadoop_destination_directory
命令:hdfs dfs -put /home/edureka/MapReduce/word.txt /user/edureka
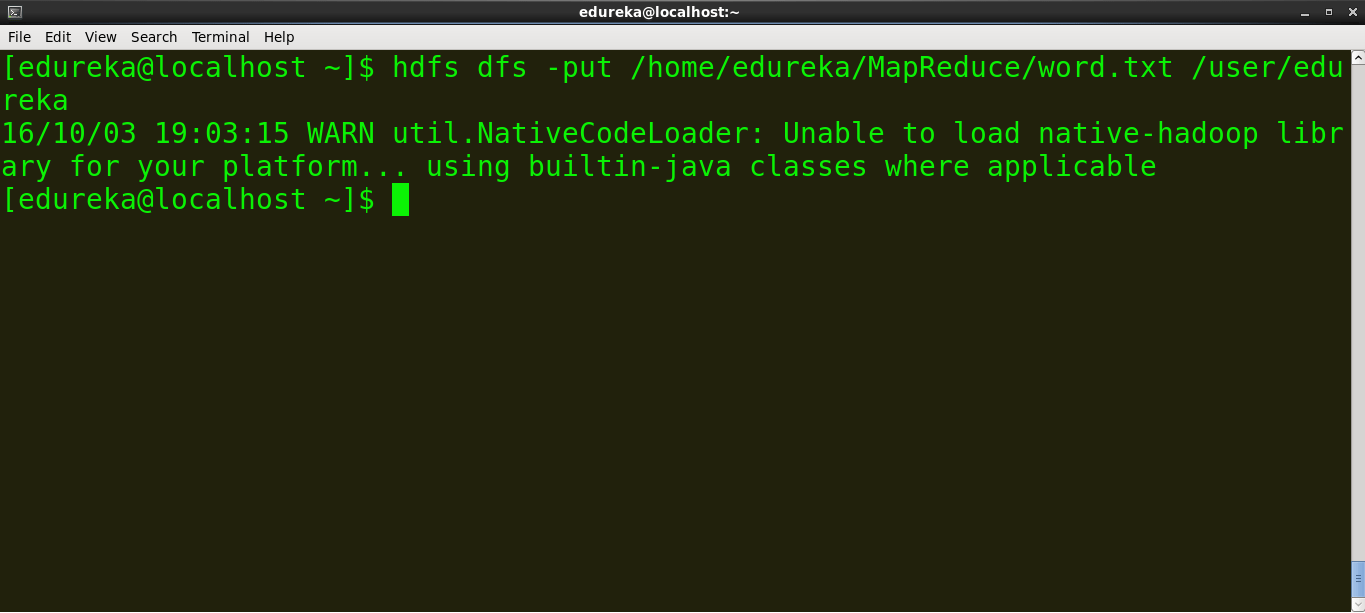
复制jar文件的路径
基于jar版本的Hadoop Streaming jar路径为:
/usr/lib/hadoop-2.2.X/share/hadoop/tools/lib/hadoop-streaming-2.2.X.jar
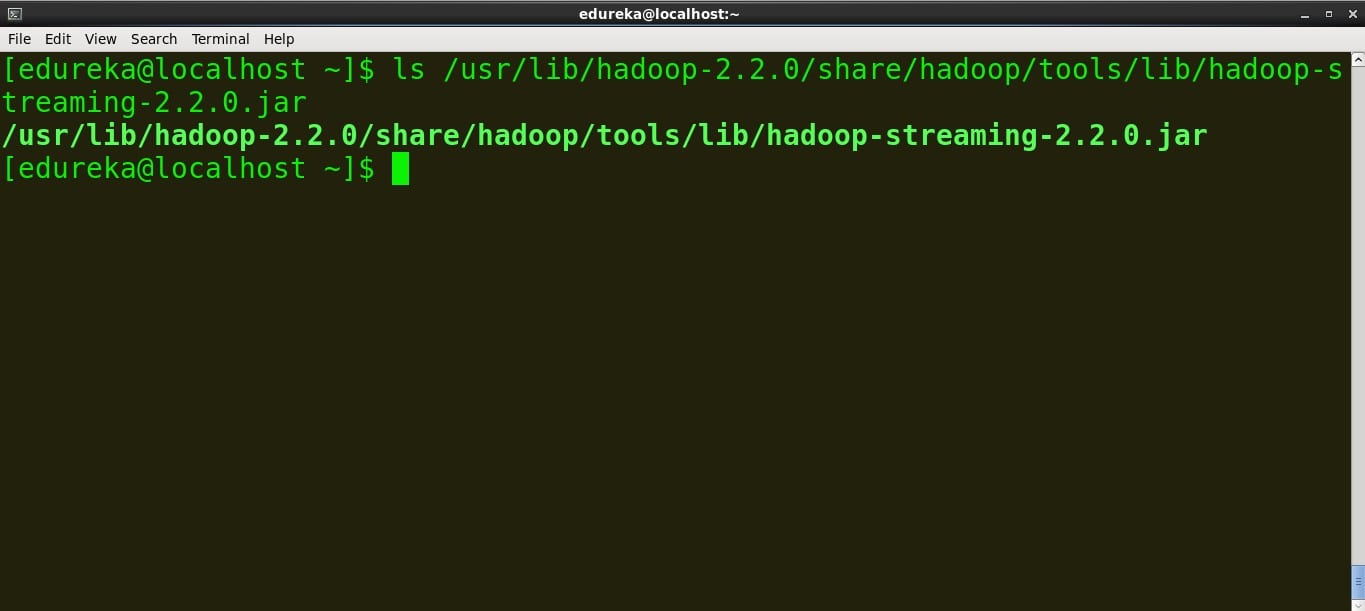
因此,在您的终端上找到 Hadoop Streaming jar 并复制路径。
命令:
ls /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar
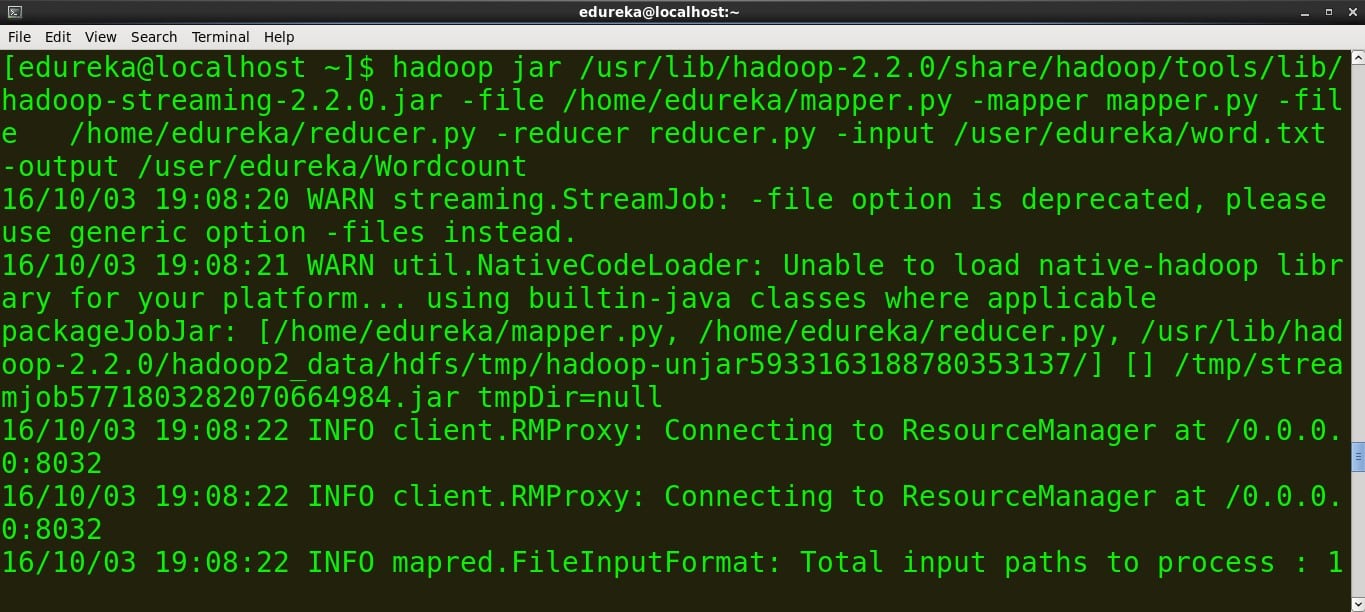
运行 MapReduce 作业
命令:
hadoop jar /usr/lib/hadoop-2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar -file /home/edureka/mapper.py -mapper mapper.py -file /home/ edureka/reducer.py -reducer reducer.py -input /user/edureka/word -output /user/edureka/Wordcount
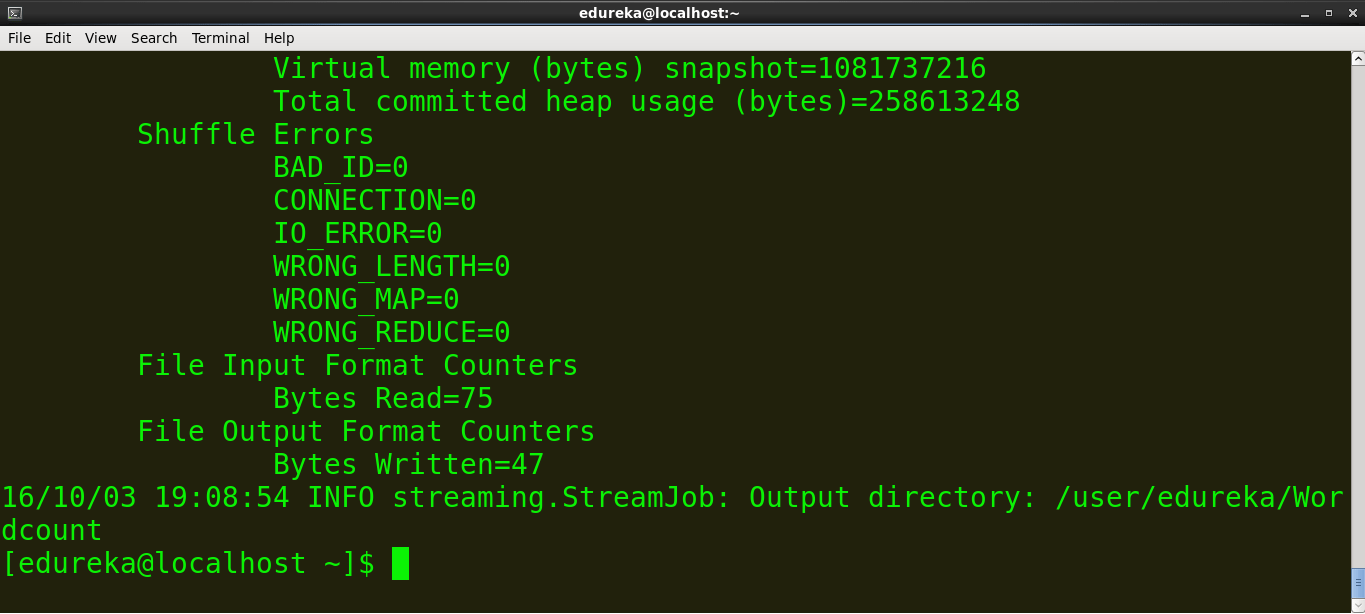
Hadoop 为统计和信息提供了一个基本的 Web 界面。当 Hadoop 集群运行时,在浏览器中打开 http://localhost:50070。这是 Hadoop Web 界面的屏幕截图。
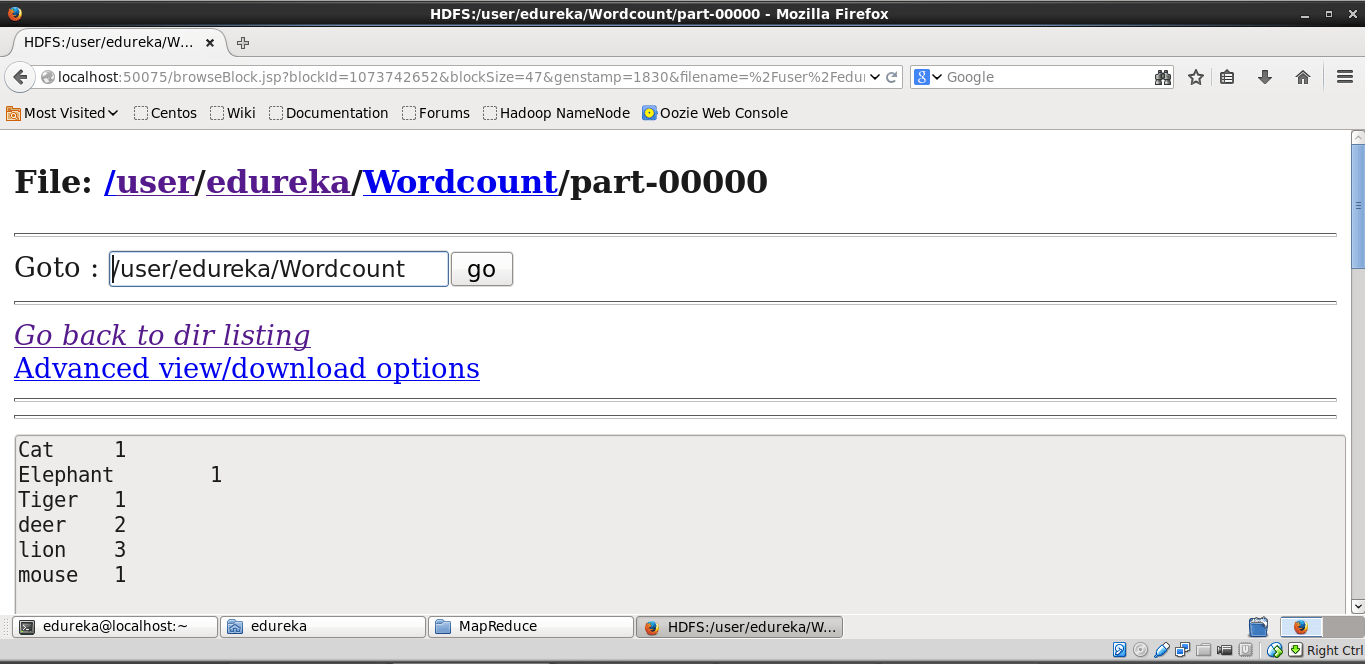
现在浏览文件系统并找到生成的 wordcount 文件以查看输出。下面是截图。
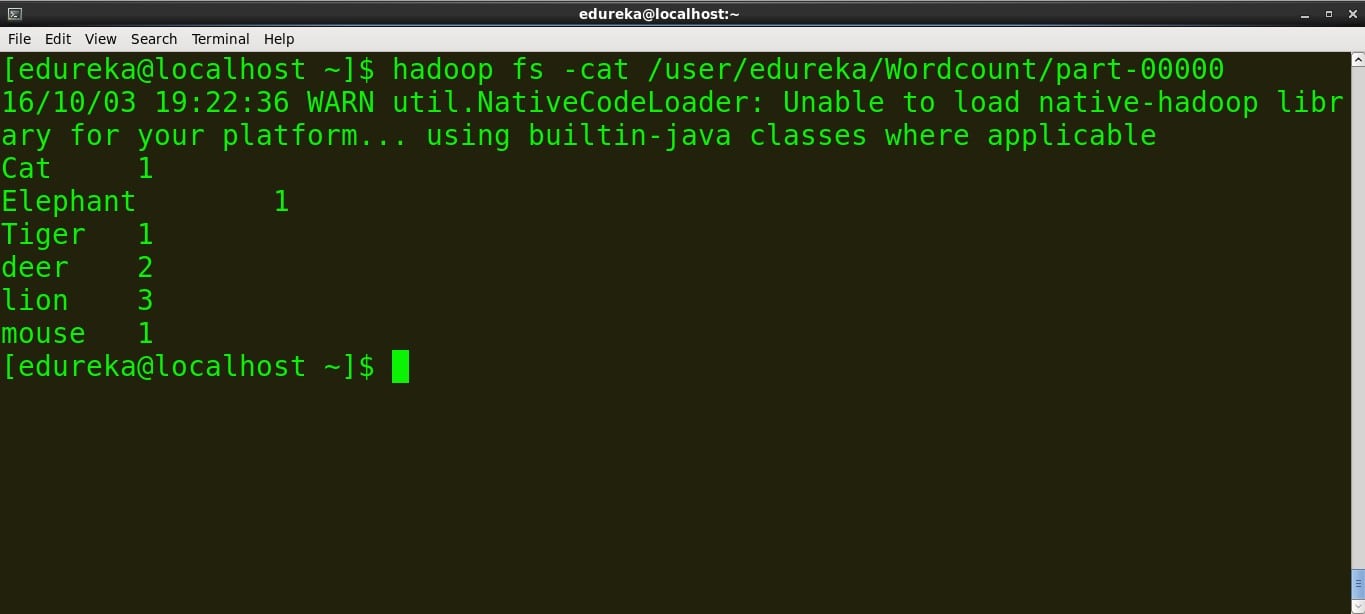
我们可以使用这个命令在终端上看到输出
命令:hadoop fs -cat /user/edureka/Wordcount/part-00000
您现在已经学会了如何使用 Hadoop Streaming 执行用 Python 编写的 MapReduce 程序!

- 点赞
- 收藏
- 关注作者
评论(0)