Java-Java I/O流解读之基于字符的I / O和字符流

概述
Java内部将字符(字符类型)存储在16位UCS-2字符集中。 但外部数据源/接收器可以将字符存储在其他字符集(例如US-ASCII,ISO-8859-x,UTF-8,UTF-16等等)中,固定长度为8位或16位, 位或以1到4字节的可变长度。 [读取“字符集和编码方案”]。
因此,Java必须区分用于处理8位原始字节的基于字节的I / O和用于处理文本的基于字符的I / O。
字符流需要在外部I / O设备使用的字符集和Java内部UCS-2格式之间进行转换。 例如,字符“您”在UCS-2(Java内部)存储为 “60 A8”,在UTF8中为“E6 82 A8”,GBK / GB2312中为“C4 FA”, BIG5中为“B1 7A”。 如果将这个字符写入文件使用UTF-8,则字符流需要将“60 A8”转换为“E6 82 A8”。 转换发生在读取操作中。
字节/字符流是指Java程序中的操作单元,不需要与从外部I / O设备传送的数据量相对应。 这是因为一些字符集使用固定长度的8位(例如,US-ASCII,ISO-8859-1)或16位(例如,UCS-16),而某些使用可变长度为1-4字节 例如,UTF-8,UTF-16,UTF-16-BE,UTF-16-LE,GBK,BIG5)。
当使用字符流读取8位ASCII文件时,将从文件读取8位数据,并将其放入Java程序的16位字符位置。
Abstract superclass Reader and Writer
除了操作和字符集转换(这非常复杂)之外,基于字符的I / O几乎与基于字节的I / O相同。 而不是InputStream和OutputStream,我们使用Reader和Writer来进行基于字符的I / O。
抽象超类Reader操作char,它声明一个抽象方法read()从输入源读取一个字符。
read()将字符返回为0到65535之间的一个int(Java中的一个char可以被视为一个无符号的16位整数);
如果检测到end-of-stream,则为-1。
read()还有两个变量可以将一个字符块读入char数组。
public abstract int read() throws IOException
public int read(char[] chars, int offset, int length) throws IOException
public int read(char[] chars) throws IOException
- 1
- 2
- 3
File I/O Character-Streams - FileReader & FileWriter
FileReader和FileWriter是抽象超类Reader和Writer的具体实现,用于从磁盘文件支持I / O。 FileReader / FileWriter假定磁盘文件使用默认字符编码(charset)。
默认的字符集保存在JVM的系统属性“file.encoding”中。 您可以通过静态方法java.nio.charset.Charset.defaultCharset()或System.getProperty(“file.encoding”)获取默认字符集。
如果默认字符集与ASCII兼容(例如US-ASCII,ISO-8859-x,UTF-8和许多其他,但不是UTF-16,UTF),则使用FileReader / FileWriter可以安全地使用ASCII文本 -16BE,UTF-16LE等等)。
当无法控制文件编码字符集,不建议使用FileReader / FileWriter。
Buffered I/O Character-Streams - BufferedReader & BufferedWriter
BufferedReader和BufferedWriter可以堆叠在FileReader / FileWriter或其他字符流的顶部,以执行缓冲I / O,而不是逐个字符的读取。
BufferedReader提供了一个新的方法readLine(),它读取一行并返回一个String(没有行分隔符)。
分隔线可以由“\ n”(Unix),“\ r \ n”(Windows)或“\ r”(Mac)分隔。
示例:
package com.xgj.master.java.io.fileDemo.characterStreams;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.nio.charset.Charset;
import org.junit.Test;
/**
*
*
* @ClassName: BufferedFileReaderWriterJDK7
*
* @Description: Demo of BufferedFileReader and BufferedWriter in JDK7.
*
* Write a text message to an output file, then read it back.
*
* NOTE: FileReader/FileWriter uses the default charset for file
* encoding in this demo.
*
* @author: Mr.Yang
*
* @date: 2017年9月7日 上午11:36:56
*/
public class BufferedFileReaderWriterJDK7 {
@Test
public void test() {
String fileName = "D:\\xgj.txt";
// 2 lines of texts
String message = "Character Streams!\nCharacter Stream Operation!\n";
// Print the default charset
System.out.println(Charset.defaultCharset());
System.out.println(System.getProperty("file.encoding"));
// JDK7中的写法
// write content to file
try (BufferedWriter bw = new BufferedWriter(new FileWriter(new File(fileName)))) {
bw.write(message);
bw.flush();// flush
} catch (IOException e) {
e.printStackTrace();
}
// read content from file
try (BufferedReader br = new BufferedReader(new FileReader(new File(fileName)))) {
String inLine;
// BufferedReader provides a new method readLine(), which reads a
// line and returns a String , if null means end of charcterStreams
while ((inLine = br.readLine()) != null) {
System.out.println(inLine);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
Character Set (or Charset) - Package java.nio.charset (JDK 1.4) 字符集 - java.nio.charset(JDK 1.4)包
JDK 1.4提供了一个新的包java.nio.charset作为NIO(New IO)的一部分,以支持Java程序内部使用的Unicode(UCS-2) 和以任何其他格式编码的外部设备之间的字符进行转换(例如, US-ASCII,ISO-8859-x,UTF-8,UTF-16,UTF-16BE,UTF-16LE等)
主类java.nio.charset.Charset提供了用于测试是否支持特定字符集的静态方法,通过名称查找字符集实例,并列出所有可用的字符集和默认字符集。
public static SortedMap<String,Charset> availableCharsets() // lists all the available charsets
public static Charset defaultCharset() // Returns the default charset
public static Charset forName(String charsetName) // Returns a Charset instance for the given charset name (in String)
public static boolean isSupported(String charsetName) // Tests if this charset name is supported
- 1
- 2
- 3
- 4
示例:
package com.xgj.master.java.io.fileDemo.characterStreams;
import java.nio.charset.Charset;
import org.junit.Test;
public class TestCharset {
@Test
public void test() {
// print the default charst
System.out.println("The default charset is " + Charset.defaultCharset());
System.out.println("The default charset is " + System.getProperty("file.encoding"));
// Print the list of available Charsets in name=Charset
System.out.println("The available charsets are:");
System.out.println(Charset.availableCharsets());
// Check if the given charset name is supported
System.out.println(Charset.isSupported("UTF-8")); // true
System.out.println(Charset.isSupported("UTF8")); // true
System.out.println(Charset.isSupported("UTF_8")); // false
// Get an instance of a Charset
Charset charset = Charset.forName("UTF8");
// Print this Charset name
System.out.println(charset.name()); // "UTF-8"
// Print all the other aliases
System.out.println(charset.aliases()); // [UTF8, unicolor-1-1-utf-8]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
输出:
The default charset is UTF-8
The default charset is UTF-8
The available charsets are:
{Big5=Big5, Big5-HKSCS=Big5-HKSCS, EUC-JP=EUC-JP, EUC-KR=EUC-KR, GB18030=GB18030, GB2312=GB2312, GBK=GBK, IBM-Thai=IBM-Thai, IBM00858=IBM00858, IBM01140=IBM01140, IBM01141=IBM01141, IBM01142=IBM01142, IBM01143=IBM01143, IBM01144=IBM01144, IBM01145=IBM01145, IBM01146=IBM01146, IBM01147=IBM01147, IBM01148=IBM01148, IBM01149=IBM01149, IBM037=IBM037, IBM1026=IBM1026, IBM1047=IBM1047, IBM273=IBM273, IBM277=IBM277, IBM278=IBM278, IBM280=IBM280, IBM284=IBM284, IBM285=IBM285, IBM290=IBM290, IBM297=IBM297, IBM420=IBM420, IBM424=IBM424, IBM437=IBM437, IBM500=IBM500, IBM775=IBM775, IBM850=IBM850, IBM852=IBM852, IBM855=IBM855, IBM857=IBM857, IBM860=IBM860, IBM861=IBM861, IBM862=IBM862, IBM863=IBM863, IBM864=IBM864, IBM865=IBM865, IBM866=IBM866, IBM868=IBM868, IBM869=IBM869, IBM870=IBM870, IBM871=IBM871, IBM918=IBM918, ISO-2022-CN=ISO-2022-CN, ISO-2022-JP=ISO-2022-JP, ISO-2022-JP-2=ISO-2022-JP-2, ISO-2022-KR=ISO-2022-KR, ISO-8859-1=ISO-8859-1, ISO-8859-13=ISO-8859-13, ISO-8859-15=ISO-8859-15, ISO-8859-2=ISO-8859-2, ISO-8859-3=ISO-8859-3, ISO-8859-4=ISO-8859-4, ISO-8859-5=ISO-8859-5, ISO-8859-6=ISO-8859-6, ISO-8859-7=ISO-8859-7, ISO-8859-8=ISO-8859-8, ISO-8859-9=ISO-8859-9, JIS_X0201=JIS_X0201, JIS_X0212-1990=JIS_X0212-1990, KOI8-R=KOI8-R, KOI8-U=KOI8-U, Shift_JIS=Shift_JIS, TIS-620=TIS-620, US-ASCII=US-ASCII, UTF-16=UTF-16, UTF-16BE=UTF-16BE, UTF-16LE=UTF-16LE, UTF-32=UTF-32, UTF-32BE=UTF-32BE, UTF-32LE=UTF-32LE, UTF-8=UTF-8, windows-1250=windows-1250, windows-1251=windows-1251, windows-1252=windows-1252, windows-1253=windows-1253, windows-1254=windows-1254, windows-1255=windows-1255, windows-1256=windows-1256, windows-1257=windows-1257, windows-1258=windows-1258, windows-31j=windows-31j, x-Big5-HKSCS-2001=x-Big5-HKSCS-2001, x-Big5-Solaris=x-Big5-Solaris, x-euc-jp-linux=x-euc-jp-linux, x-EUC-TW=x-EUC-TW, x-eucJP-Open=x-eucJP-Open, x-IBM1006=x-IBM1006, x-IBM1025=x-IBM1025, x-IBM1046=x-IBM1046, x-IBM1097=x-IBM1097, x-IBM1098=x-IBM1098, x-IBM1112=x-IBM1112, x-IBM1122=x-IBM1122, x-IBM1123=x-IBM1123, x-IBM1124=x-IBM1124, x-IBM1364=x-IBM1364, x-IBM1381=x-IBM1381, x-IBM1383=x-IBM1383, x-IBM300=x-IBM300, x-IBM33722=x-IBM33722, x-IBM737=x-IBM737, x-IBM833=x-IBM833, x-IBM834=x-IBM834, x-IBM856=x-IBM856, x-IBM874=x-IBM874, x-IBM875=x-IBM875, x-IBM921=x-IBM921, x-IBM922=x-IBM922, x-IBM930=x-IBM930, x-IBM933=x-IBM933, x-IBM935=x-IBM935, x-IBM937=x-IBM937, x-IBM939=x-IBM939, x-IBM942=x-IBM942, x-IBM942C=x-IBM942C, x-IBM943=x-IBM943, x-IBM943C=x-IBM943C, x-IBM948=x-IBM948, x-IBM949=x-IBM949, x-IBM949C=x-IBM949C, x-IBM950=x-IBM950, x-IBM964=x-IBM964, x-IBM970=x-IBM970, x-ISCII91=x-ISCII91, x-ISO-2022-CN-CNS=x-ISO-2022-CN-CNS, x-ISO-2022-CN-GB=x-ISO-2022-CN-GB, x-iso-8859-11=x-iso-8859-11, x-JIS0208=x-JIS0208, x-JISAutoDetect=x-JISAutoDetect, x-Johab=x-Johab, x-MacArabic=x-MacArabic, x-MacCentralEurope=x-MacCentralEurope, x-MacCroatian=x-MacCroatian, x-MacCyrillic=x-MacCyrillic, x-MacDingbat=x-MacDingbat, x-MacGreek=x-MacGreek, x-MacHebrew=x-MacHebrew, x-MacIceland=x-MacIceland, x-MacRoman=x-MacRoman, x-MacRomania=x-MacRomania, x-MacSymbol=x-MacSymbol, x-MacThai=x-MacThai, x-MacTurkish=x-MacTurkish, x-MacUkraine=x-MacUkraine, x-MS932_0213=x-MS932_0213, x-MS950-HKSCS=x-MS950-HKSCS, x-MS950-HKSCS-XP=x-MS950-HKSCS-XP, x-mswin-936=x-mswin-936, x-PCK=x-PCK, x-SJIS_0213=x-SJIS_0213, x-UTF-16LE-BOM=x-UTF-16LE-BOM, X-UTF-32BE-BOM=X-UTF-32BE-BOM, X-UTF-32LE-BOM=X-UTF-32LE-BOM, x-windows-50220=x-windows-50220, x-windows-50221=x-windows-50221, x-windows-874=x-windows-874, x-windows-949=x-windows-949, x-windows-950=x-windows-950, x-windows-iso2022jp=x-windows-iso2022jp}
true
true
false
UTF-8
[unicode-1-1-utf-8, UTF8]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
文件编码的默认字符集保存在系统属性“file.encoding”中。
要更改JVM的文件编码默认字符集,可以使用命令行VM选项“-Dfile.encoding”。
例如,以下命令运行具有UTF-8的默认字符集的程序。
> java -Dfile.encoding=UTF-8 TestCharset
- 1
最重要的是,Charset类提供了在Java程序中使用的UCS-2和外部设备(如UTF-8)中使用的特定字符集对字符进行编码/解码的方法。
public final ByteBuffer encode(String s)
public final ByteBuffer encode(CharBuffer cb)
// Encodes Unicode UCS-2 characters in the CharBuffer/String
// into a "byte sequence" using this charset, and returns a ByteBuffer.
public final CharBuffer decode(ByteBuffer bb)
// Decode the byte sequence encoded using this charset in the ByteBuffer
// to Unicode UCS-2, and return a charBuffer.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
示例:
以下示例在各种编码方案中对一些Unicode文本进行编码,并显示编码字节序列的十六进制代码。
package com.xgj.master.java.io.fileDemo.characterStreams;
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
import org.junit.Test;
public class TestCharsetEncodeDecode {
@Test
public void test() {
// Try these charsets for encoding
String[] charsetNames = { "US-ASCII", "ISO-8859-1", "UTF-8", "UTF-16", "UTF-16BE", "UTF-16LE", "GBK", "BIG5" };
String message = "Hi,您好!"; // Unicode message to be encoded
// Print UCS-2 in hex codes
System.out.printf("%10s: ", "UCS-2");
for (int i = 0; i < message.length(); ++i) {
System.out.printf("%04X ", (int) message.charAt(i));
}
System.out.println();
for (String charsetName : charsetNames) {
// Get a Charset instance given the charset name string
Charset charset = Charset.forName(charsetName);
System.out.printf("%10s: ", charset.name());
// Encode the Unicode UCS-2 characters into a byte sequence in this
// charset.
ByteBuffer bb = charset.encode(message);
while (bb.hasRemaining()) {
System.out.printf("%02X ", bb.get()); // Print hex code
}
System.out.println();
bb.rewind();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
输出结果解读:
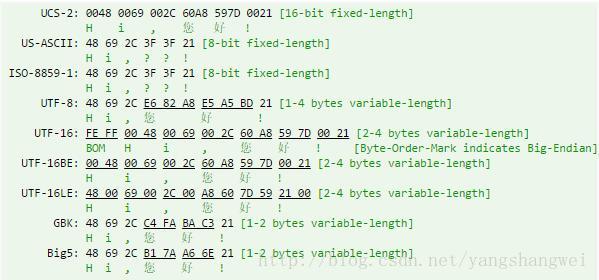
示例二:
以下示例尝试使用CharBuffer和ByteBuffer进行编码/解码
package com.xgj.master.java.io.fileDemo.characterStreams;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.Charset;
import org.junit.Test;
public class TestCharsetEncodeByteBuffer {
@Test
public void test() {
// "Hi,您好!"
byte[] bytes = { 0x00, 0x48, 0x00, 0x69, 0x00, 0x2C, 0x60, (byte) 0xA8, 0x59, 0x7D, 0x00, 0x21 };
// Print UCS-2 in hex codes
System.out.printf("%10s: ", "UCS-2");
for (int i = 0; i < bytes.length; ++i) {
System.out.printf("%02X ", bytes[i]);
}
System.out.println();
Charset charset = Charset.forName("UTF-8");
// Encode from UCS-2 to UTF-8
// Create a ByteBuffer by wrapping a byte array
ByteBuffer bb = ByteBuffer.wrap(bytes);
// Create a CharBuffer from a view of this ByteBuffer
CharBuffer cb = bb.asCharBuffer();
ByteBuffer bbOut = charset.encode(cb);
// Print hex code
System.out.printf("%10s: ", charset.name());
while (bbOut.hasRemaining()) {
System.out.printf("%02X ", bbOut.get());
}
System.out.println();
// Decode from UTF-8 to UCS-2
bbOut.rewind();
CharBuffer cbOut = charset.decode(bbOut);
System.out.printf("%10s: ", "UCS-2");
while (cbOut.hasRemaining()) {
char aChar = cbOut.get();
// Print char & hex code
System.out.printf("'%c'[%04X] ", aChar, (int) aChar);
}
System.out.println();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
运行结果:
UCS-2: 00 48 00 69 00 2C 60 A8 59 7D 00 21
UTF-8: 48 69 2C E6 82 A8 E5 A5 BD 21
UCS-2: 'H'[0048] 'i'[0069] ','[002C] '您'[60A8] '好'[597D] '!'[0021]
- 1
- 2
- 3
Text File I/O - InputStreamReader and OutputStreamWriter
如前所述,Java内部存储16位UCS-2字符集中的字符(字符类型)。 但外部数据源/接收器可以将字符存储在其他字符集(例如US-ASCII,ISO-8859-x,UTF-8,UTF-16等等)中,固定长度为8位或16位, 位或以1到4字节的可变长度。
前面介绍的FileReader / FileWriter使用默认字符集进行解码/编码,导致非便携式程序。
要选择字符集,我们需要使用InputStreamReader和OutputStreamWriter。 InputStreamReader和OutputStreamWriter被认为是字节到字符的桥梁。
我们以在InputStreamReader的构造函数中选择字符集:
public InputStreamReader(InputStream in) // Use default charset
public InputStreamReader(InputStream in, String charsetName) throws UnsupportedEncodingException
public InputStreamReader(InputStream in, Charset cs)
- 1
- 2
- 3
我们可以通过静态方法java.nio.charset.Charset.availableCharsets()列出可用的字符集。 Java支持的常用字符串名称如下:
- “US-ASCII”: 7-bit ASCII (aka ISO646-US)
- “ISO-8859-1”: Latin-1
- “UTF-8”: Most commonly-used encoding scheme for Unicode
- “UTF-16BE”: Big-endian (big byte first) (big-endian is usually the
default) - “UTF-16LE”: Little-endian (little byte first)
- “UTF-16”: with a 2-byte BOM (Byte-Order-Mark) to specify the byte
order. FE FF indicates big-endian, FF FE indicates little-endian.
由于InputStreamReader / OutputStreamWriter通常需要以多个字节读/写,最好用BufferedReader / BufferedWriter包装它。
示例:
以下程序使用各种字符集将Unicode文本写入磁盘文件进行文件编码。 然后,它逐个字节(通过基于字节的输入流)读取文件,以检查各种字符集中的编码字符。 最后,它使用基于字符的reader读取文件。
package com.xgj.master.java.io.fileDemo.characterStreams;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import org.junit.Test;
/**
*
*
* @ClassName: TextFileEncodingJDK7
*
* @Description: Write texts to file using OutputStreamWriter specifying its
* charset encoding.
*
* Read byte-by-byte using FileInputStream.
*
* Read char-by-char using InputStreamReader specifying its
* charset encoding.
*
* @author: Mr.Yang
*
* @date: 2017年9月7日 下午1:35:15
*/
public class TextFileEncodingJDK7 {
@Test
public void test() {
String message = "Hi,您好!"; // with non-ASCII chars
// Java internally stores char in UCS-2/UTF-16
// Print the characters stored with Hex codes
for (int i = 0; i < message.length(); ++i) {
char aChar = message.charAt(i);
System.out.printf("[%d]'%c'(%04X) ", (i + 1), aChar, (int) aChar);
}
System.out.println();
// Try these charsets for encoding text file
String[] csStrs = { "UTF-8", "UTF-16BE", "UTF-16LE", "UTF-16", "GB2312", "GBK", "BIG5" };
String outFileExt = "-out.txt"; // Output filenames are
// "charset-out.txt"
// Write text file in the specified file encoding charset
for (int i = 0; i < csStrs.length; ++i) {
// Buffered for efficiency
try (OutputStreamWriter out = new OutputStreamWriter(new FileOutputStream(csStrs[i] + outFileExt),
csStrs[i]); BufferedWriter bufOut = new BufferedWriter(out)) {
// Print file encoding charset efficiency
System.out.println(out.getEncoding());
bufOut.write(message);
bufOut.flush();
} catch (IOException ex) {
ex.printStackTrace();
}
}
// Read raw bytes from various encoded files
// to check how the characters were encoded.
for (int i = 0; i < csStrs.length; ++i) {
// Buffered for efficiency
try (BufferedInputStream in = new BufferedInputStream(new FileInputStream(csStrs[i] + outFileExt))) {
// Print file encoding charset
System.out.printf("%10s", csStrs[i]);
int inByte;
while ((inByte = in.read()) != -1) {
// Print Hex codes
System.out.printf("%02X ", inByte);
}
System.out.println();
} catch (IOException ex) {
ex.printStackTrace();
}
}
// Read text file with character-stream specifying its encoding.
// The char will be translated from its file encoding charset to
// Java internal UCS-2.
for (int i = 0; i < csStrs.length; ++i) {
// Buffered for efficiency
try (InputStreamReader in = new InputStreamReader(new FileInputStream(csStrs[i] + outFileExt), csStrs[i]);
BufferedReader bufIn = new BufferedReader(in)) {
// print file encoding charset
System.out.println(in.getEncoding());
int inChar;
int count = 0;
while ((inChar = in.read()) != -1) {
++count;
System.out.printf("[%d]'%c'(%04X) ", count, (char) inChar, inChar);
}
System.out.println();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
输出分析:
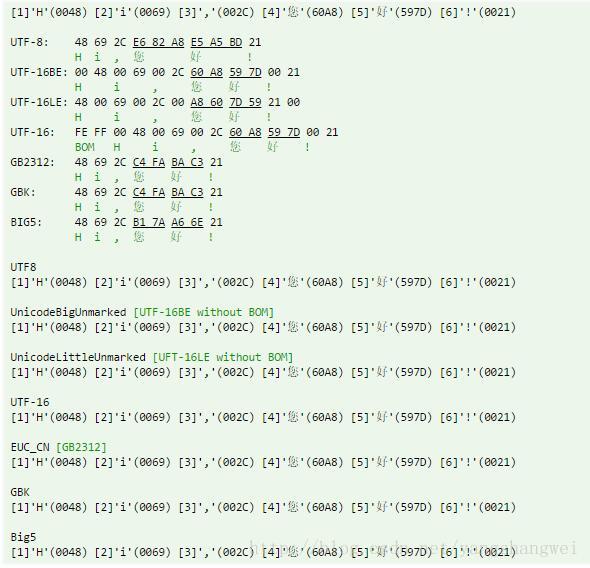
从输出中可以看出,“您好”的字符在不同的字符集中被不同地编码。
尽管如此,InputStreamReader能够将字符转换为与Java程序中使用的相同的UCS-2
代码
代码已托管到Github—> https://github.com/yangshangwei/JavaMaster
文章来源: artisan.blog.csdn.net,作者:小小工匠,版权归原作者所有,如需转载,请联系作者。
原文链接:artisan.blog.csdn.net/article/details/77880801

- 点赞
- 收藏
- 关注作者
评论(0)