Python 第四节 第六课

[toc]
根据键查找 "键值对" 的底层过程
我们明白了, 一个键值对是如何存储到数组中的, 根据键对象取到值对象, 理解起来就简单了.
>>> a.get("name")
>>> "我是小白"
当我们调用 a.get( "name" ), 就是根据键 "name" 查找到 "键值对", 而从找到值对象 "我是小白".
第一步, 我们仍然要计算 "name" 对象的散列值:
>>>bin(hash("name"))
0b100000111110100101100111000111101100110100111111000000110100101
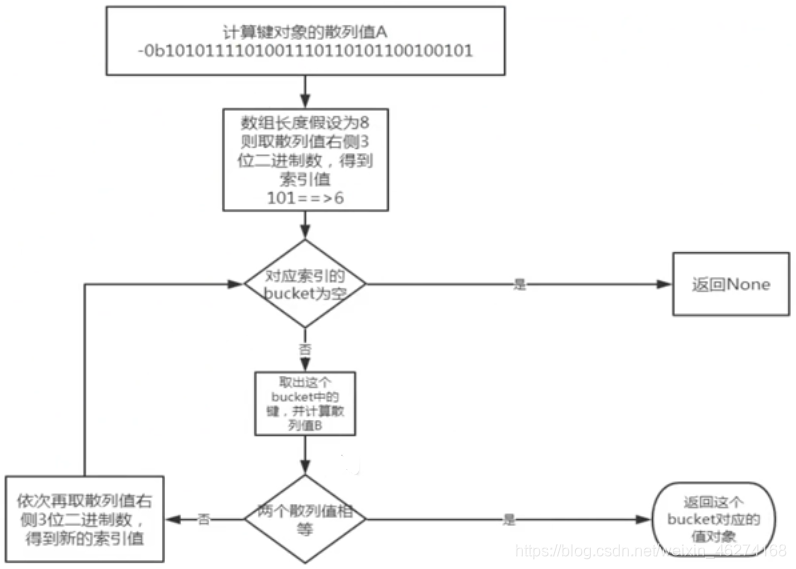
和存储的底层流程算法一致, 也是依次取散列值的不同位置的数字. 假设数组长度为 8 , 我们可以拿计算出的散列值的最右边 3 位数作为偏移量, 即 "101", 十进制是数字 5. 我们查看偏移量 5, 对应的 bucket 是否为空. 如果为空, 则返回 None. 如果不为空, 则将这个 bucket 的键值对象计算对应的散列值, 和我们的散列值进行比较, 如果相等. 则对应 "值对象" 返回. 如果不相等, 则再依次取其他几位数字, 重新计算偏移量. 依次取完后, 任然没有找到. 则返回 None. 流程如下:
用法总结:
1. 键必须可散列
(1) 数字, 字符串, 元组, 都是可以散列的.
(2) 自定义对象需要支持下面三点:
-
支持 hash() 函数
-
支持通过__eq__() 方法检测相等性
-
若 a == b 为真, 则 hash(a) == hash(b) 也为真
2. 字典在内存中开销巨大, 典型的空间换时间.
3. 键查询速度很快
4. 往字典里面添加新建可能导致扩容, 导致散列表在键次序变换. 因此, 不要在遍历字典的同时进行字典的修改.
文章来源: iamarookie.blog.csdn.net,作者:我是小白呀,版权归原作者所有,如需转载,请联系作者。
原文链接:iamarookie.blog.csdn.net/article/details/108841478

- 点赞
- 收藏
- 关注作者
评论(0)