白话Elasticsearch23-深度探秘搜索技术之通过ngram分词机制实现index-time搜索推荐


概述
继续跟中华石杉老师学习ES,第23篇
课程地址: https://www.roncoo.com/view/55
官网
NGram Tokenizer:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-ngram-tokenizer.html

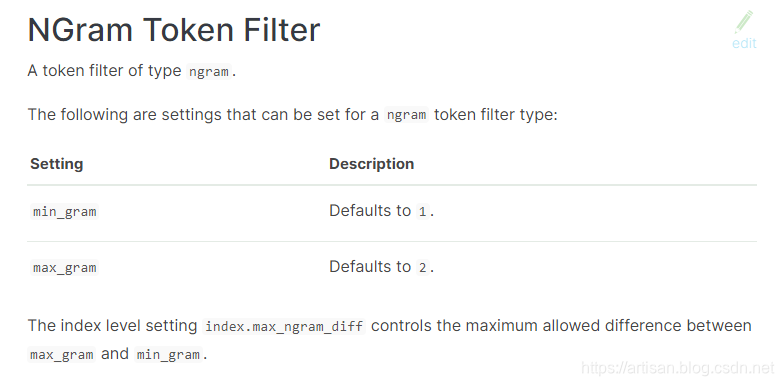
NGram Token Filter:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-ngram-tokenfilter.html
Edge NGram Tokenizer:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-edgengram-tokenizer.html

Edge NGram Token Filter:
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-edgengram-tokenfilter.html

什么是ngram
什么是ngram
假设有个单词quick,5种长度下的ngram
ngram length=1,会被拆成 q u i c k
ngram length=2,会被拆成 qu ui ic ck
ngram length=3,会被拆成 qui uic ick
ngram length=4,会被拆成 quic uick
ngram length=5,会被拆成 quick
- 1
- 2
- 3
- 4
- 5
其中任意一个被拆分的部分 就被称为ngram 。
什么是edge ngram
quick,anchor首字母后进行ngram
q
qu
qui
quic
quick
- 1
- 2
- 3
- 4
- 5
上述拆分方式就被称为edge ngram
使用edge ngram将每个单词都进行进一步的分词切分,用切分后的ngram来实现前缀搜索推荐功能
举个例子 两个doc
doc1 hello world
doc2 hello we
使用edge ngram拆分
h
he
hel
hell
hello -------> 可以匹配 doc1,doc2
w -------> 可以匹配 doc1,doc2
wo
wor
worl
world
e ---------> 可以匹配 doc2
使用hello w去搜索
hello --> hello,doc1
w --> w,doc1
doc1中hello和w,而且position也匹配,所以,ok,doc1返回,hello world
ngram和index-time搜索推荐原理
搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了,而是简单的拿前缀去倒排索引中匹配即可,如果匹配上了,那么就好了,就和match query全文检索一样
例子
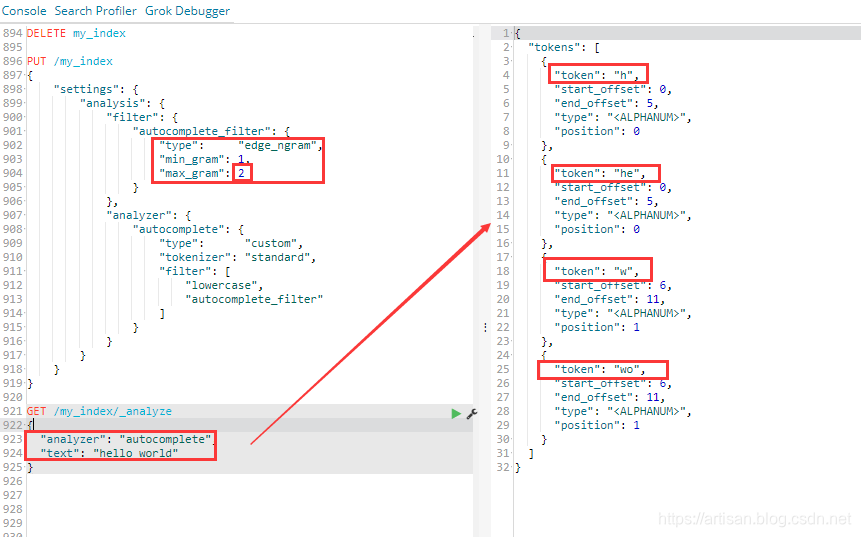
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
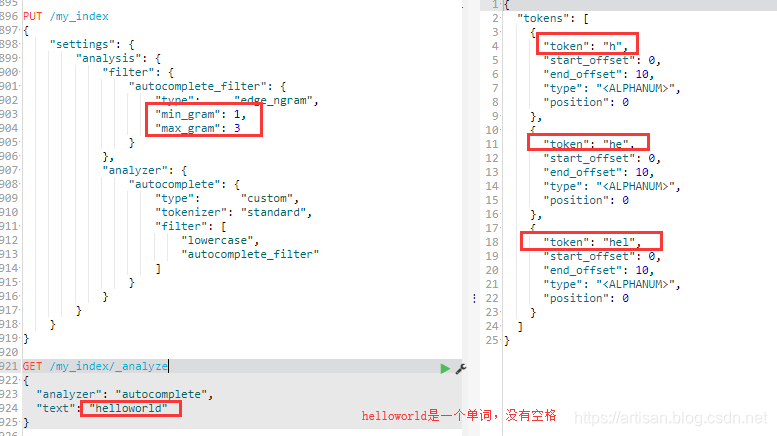
helloworld
设置
min ngram = 1
max ngram = 3
- 1
- 2
使用edge_ngram ,则会被拆分为一下 ,
h
he
hel
- 1
- 2
- 3
知识点: autocomplete
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-analyzer.html

GET /my_index/_analyze
{
"analyzer": "autocomplete",
"text": "helll world"
}
- 1
- 2
- 3
- 4
- 5
设置mapping , 查询的时候还是使用standard
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
造数据
PUT /my_index/my_type/1
{
"content":"hello Jack"
}
PUT /my_index/my_type/2
{
"content":"hello John"
}
PUT /my_index/my_type/3
{
"content":"hello Jose"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查询
GET /my_index/my_type/_search
{
"query": {
"match": {
"content": "hello J"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
返回:
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.2876821,
"hits": [
{
"_index": "my_index",
"_type": "my_type",
"_id": "2",
"_score": 0.2876821,
"_source": {
"content": "hello John"
}
},
{
"_index": "my_index",
"_type": "my_type",
"_id": "1",
"_score": 0.2876821,
"_source": {
"content": "hello Jack"
}
},
{
"_index": "my_index",
"_type": "my_type",
"_id": "3",
"_score": 0.2876821,
"_source": {
"content": "hello Jose"
}
}
]
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 如果用match,只有hello的也会出来,全文检索,只是分数比较低
- 推荐使用match_phrase,要求每个term都有,而且position刚好靠着1位,符合我们的期望的
文章来源: artisan.blog.csdn.net,作者:小小工匠,版权归原作者所有,如需转载,请联系作者。
原文链接:artisan.blog.csdn.net/article/details/98124341

- 点赞
- 收藏
- 关注作者
评论(0)