Oracle-分析函数之排序值rank()和dense_rank()

概述
ORACLE函数系列:
Oracle-分析函数之连续求和sum(…) over(…)
Oracle-分析函数之排序值rank()和dense_rank()
Oracle-分析函数之排序后顺序号row_number()
Oracle-分析函数之取上下行数据lag()和lead()
聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
在9i版本之前,只有分析功能(analytic ),即从一个查询结果中计算每一行的排序值,是基于order_by_clause子句中的value_exprs指定字段的。
其语法为:
RANK ( ) OVER ( [query_partition_clause] order_by_clause )
- 1
在9i版本新增加了合计功能(aggregate),即对给定的参数值在设定的排序查询中计算出其排序值。这些参数必须是常数或常值表达式,且必须和ORDER BY子句中的字段个数、位置、类型完全一致。
其语法为:
RANK ( expr [, expr]... ) WITHIN GROUP
( ORDER BY
expr [ DESC | ASC ] [NULLS { FIRST | LAST }]
[, expr [ DESC | ASC ] [NULLS { FIRST | LAST }]]...
- 1
- 2
- 3
- 4
参考栗子三。
语法
【语法】
rank() over( [query_partition_clause] order_by_clause )
- 1
dense_rank() over( [query_partition_clause] order_by_clause )
- 1
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过.
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
rank()
栗子1
表xgj:
--建表
create table XGJ
(
col1 NUMBER,
col2 NUMBER
)
- 1
- 2
- 3
- 4
- 5
- 6
--插入数据
insert into xgj (COL1, COL2)
values (1, 1);
insert into xgj (COL1, COL2)
values (2, 1);
insert into xgj (COL1, COL2)
values (3, 2);
insert into xgj (COL1, COL2)
values (3, 1);
insert into xgj (COL1, COL2)
values (4, 1);
insert into xgj (COL1, COL2)
values (4, 2);
insert into xgj (COL1, COL2)
values (5, 2);
insert into xgj (COL1, COL2)
values (5, 2);
insert into xgj (COL1, COL2)
values (6, 2);
--提交数据
commit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
数据规格如下:
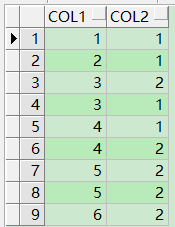
分析功能:列出Col2分组后根据Col1排序,并生成数字列.
比较实用于在成绩表中查出各科前几名的信息。
SELECT a.*,RANK() OVER(PARTITION BY col2 ORDER BY col1) "Rank" FROM xgj a;
- 1
- 2
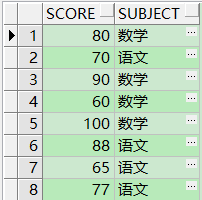
栗子2
TABLE:xgj_2 (分数 ,科目)
create table xgj_2
(
score NUMBER,
subject VARCHAR2(20)
)
- 1
- 2
- 3
- 4
- 5
insert into xgj_2(SCORE, SUBJECT)
values (80, '数学');
insert into xgj_2(SCORE, SUBJECT)
values (70, '语文');
insert into xgj_2(SCORE, SUBJECT)
values (90, '数学');
insert into xgj_2(SCORE, SUBJECT)
values (60, '数学');
insert into xgj_2(SCORE, SUBJECT)
values (100, '数学');
insert into xgj_2(SCORE, SUBJECT)
values (88, '语文');
insert into xgj_2(SCORE, SUBJECT)
values (65, '语文');
insert into xgj_2(SCORE, SUBJECT)
values (77, '语文');
commit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
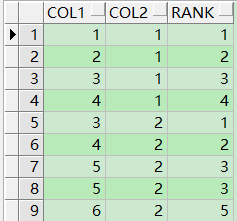
数据规格如下:
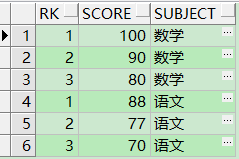
现在我想要的结果是:(即想要每门科目的前3名的分数)
数学,100
数学,90
数学,80
语文,88
语文,77
语文,70
- 1
- 2
- 3
- 4
- 5
- 6
- 7
SQL:
select *
from (select rank() over(partition by a.subject order by a.score desc) rk,
a.*
from xgj_2 a) t
where t.rk <= 3;
- 1
- 2
- 3
- 4
- 5
栗子3
拿第二个栗子的表 作为数据源。
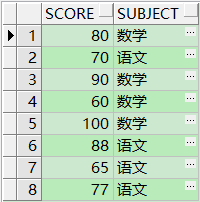
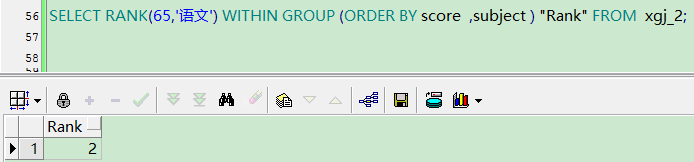
合计功能:计算出数值(65,’语文’)在Orade By score ,subject排序下的排序值,也就是score=65,subject=语文在排序以后的位置
SELECT RANK(65,'语文') WITHIN GROUP (ORDER BY score ,subject ) "Rank" FROM xgj_2;
- 1
- 2
结果如下:
dense_rank()
dense_rank与rank()用法相当,但是有一个区别:dence_rank在并列关系是,相关等级不会跳过。rank则跳过.
栗子1
表xgj_3 数据规格:
A B C
a liu wang
a jin shu
a cai kai
b yang du
b lin ying
b yao cai
b yang 99
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
例如:当rank时为:
select m.a,m.b,m.c,rank() over(partition by a order by b) RK from xgj_3 m
A B C RK
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
而如果用dense_rank时为:
select m.a,m.b,m.c,dense_rank() over(partition by a order by b) RK from xgj_3 m
A B C RK
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
文章来源: artisan.blog.csdn.net,作者:小小工匠,版权归原作者所有,如需转载,请联系作者。
原文链接:artisan.blog.csdn.net/article/details/53038325

- 点赞
- 收藏
- 关注作者
评论(0)