【NLP】⚠️学不会打我! 半小时学会基本操作 2⚠️词向量模型简介

概述
我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量.
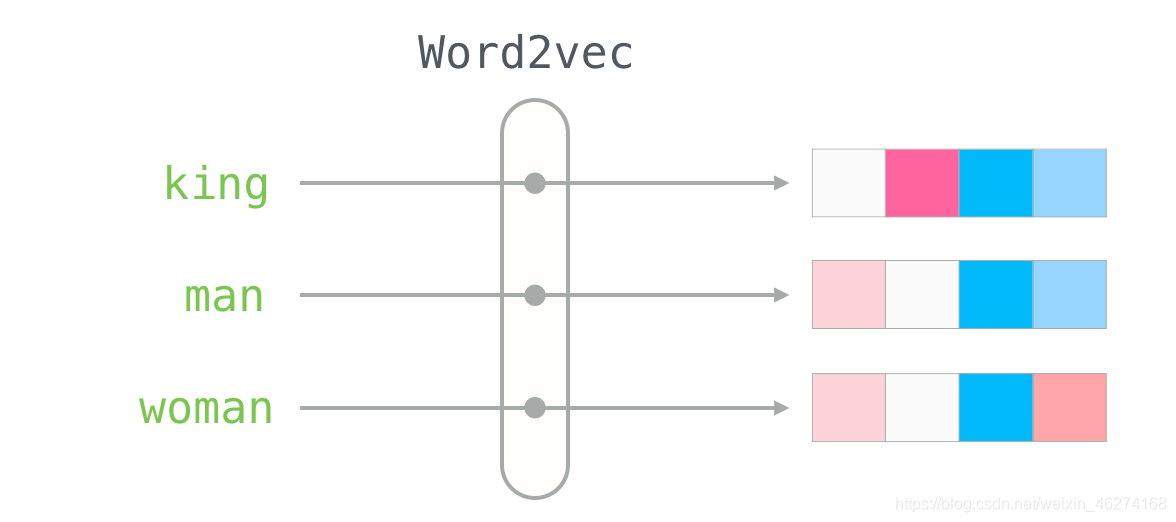
当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量我们就可以使用不同方法来计算相似度.

那我们如何来描述语言的特征呢? 我们把语言分割成一个个词, 然后在词的层面上构建特征.
词向量维度
词向量的维度越高, 其所能提供的信息也就越多, 计算结果的可靠性就更值得信赖.
50 维的词向量:

用热度图表示一下:

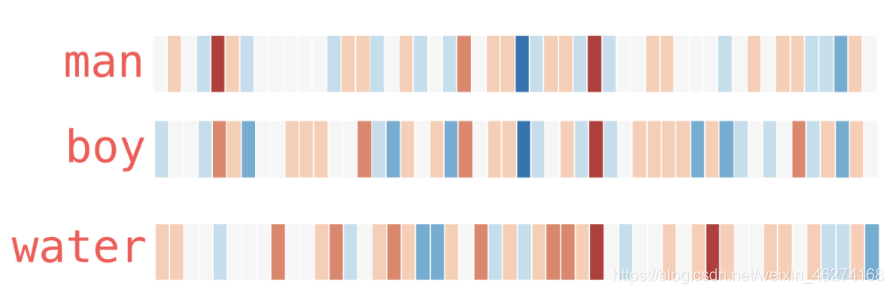
从上图我们可以看出, 相似的词在特征表达中比较相似. 由此也可以证明词的特征是有意义的.
Word2Vec
Word2Vec 是一个经过预训练的 2 层神经网络, 可以帮助我们将单词转换为向量. Word2Vec 分为两种学习的方法: CBOW 和 Skip-Gram.
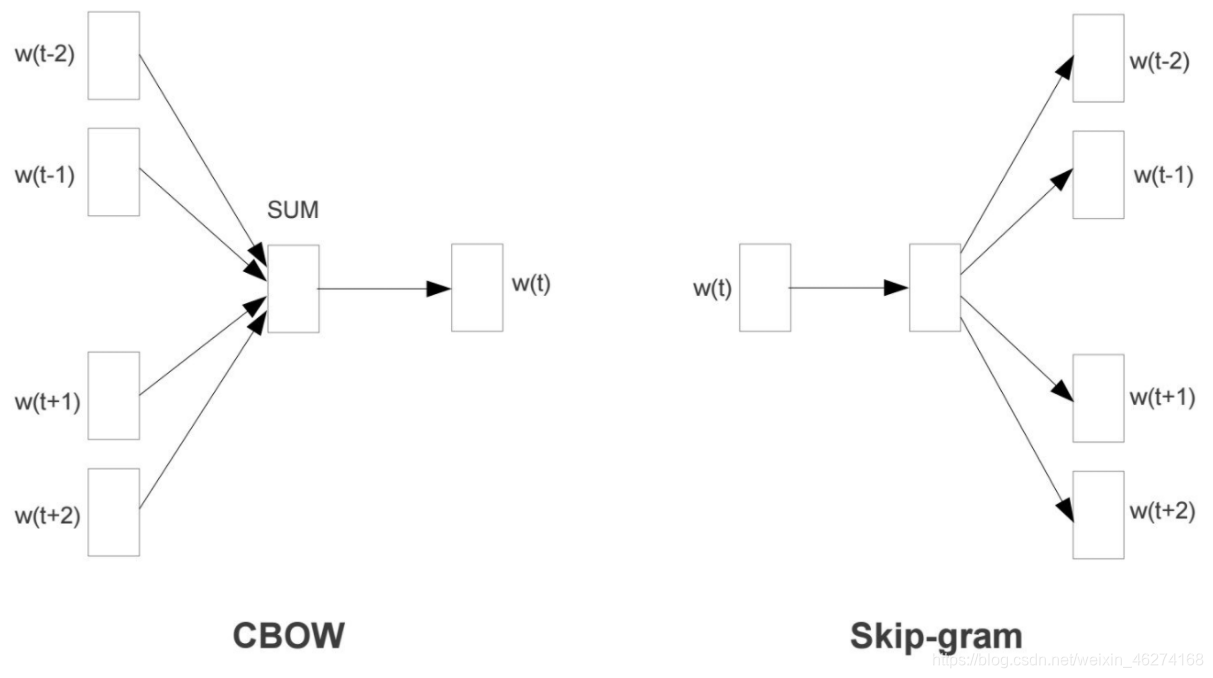
CBOW 模型
CBOW (Continuous Bag-of-Words) 是根据单词周围的上下文来预测中间的词. 如图:
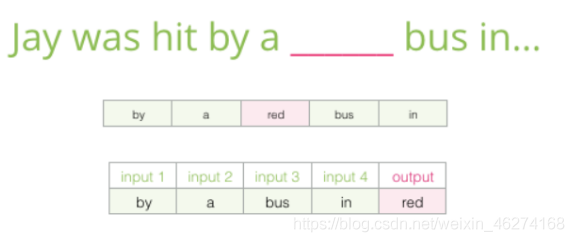
Skip-Gram 模型
Skip-Gram 用于预测同一句子中当前单词前后的特定范围内的单词.

Skip-Gram 所需的训练数据集:


负采样模型
如果一个语料库稍微大一些, 可能的结果简直太多了. 词向量模型的最后一层相当于 softmax (转换为概率), 计算起来会非常耗时.
我们可以将输入改成两个单词, 判断这两个词是否为前后对应的输入和输出, 即一个二分类任务.
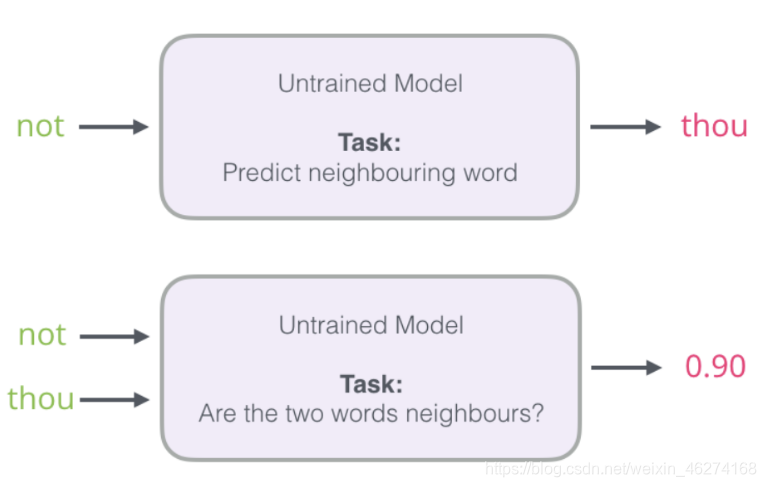
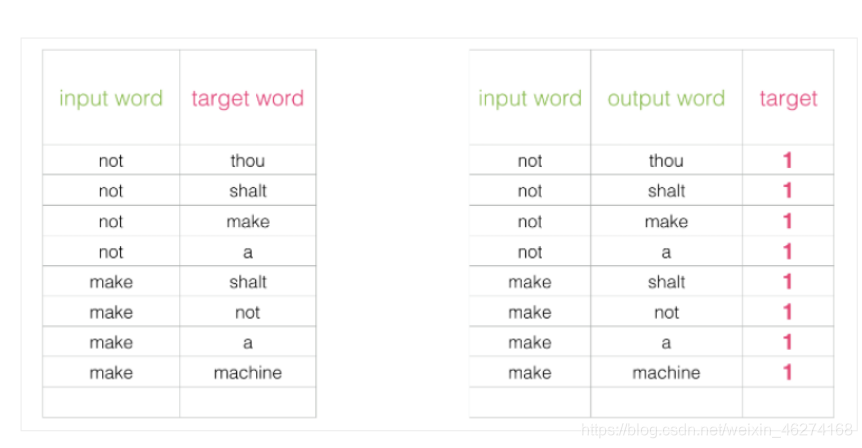
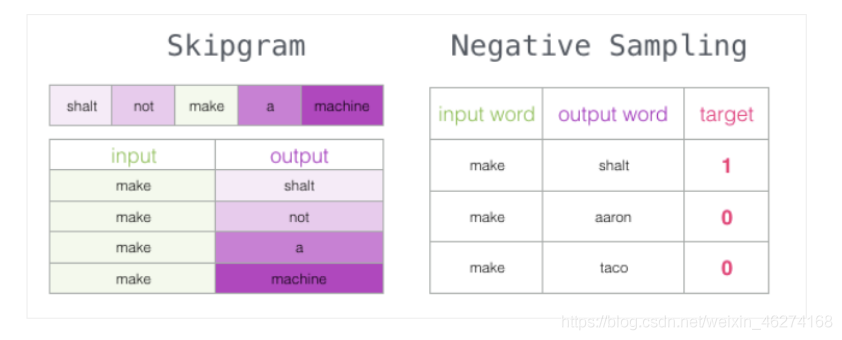
但是我们会发现一个问题, 此时的训练集构建出来的标签全为 1, 无法进行较好的训练. 这时候负采样模型就派上用场了. (默认为 5 个)

词向量的训练过程
1. 初始化词向量矩阵
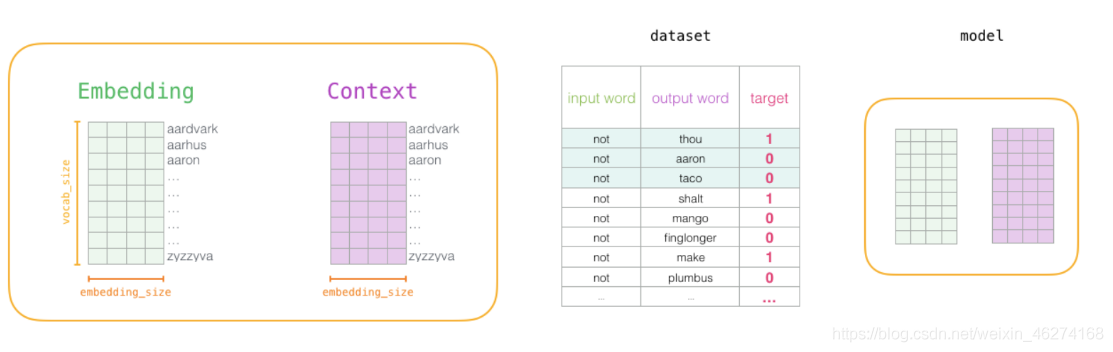
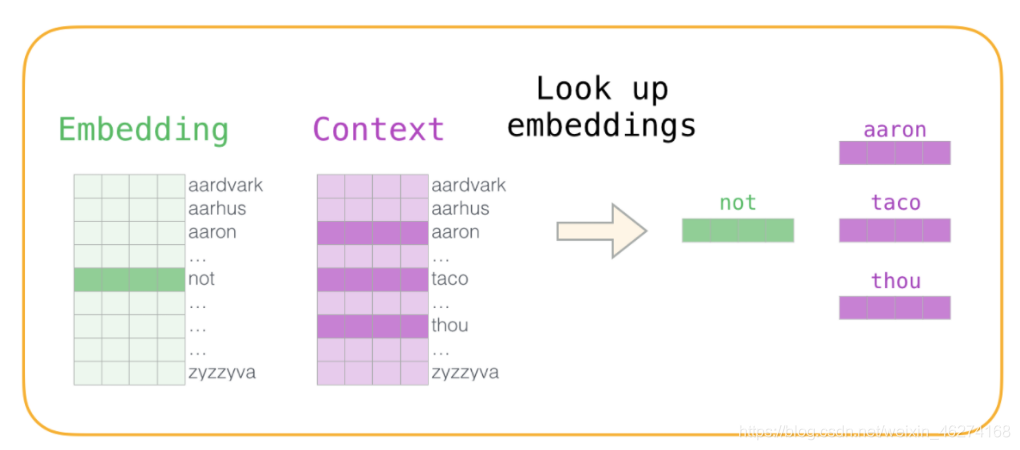
2. 神经网络反向传播
通过神经网络反向传播来计算更新. 此时不光更新权重参数矩阵 W, 也会更新输入数据.
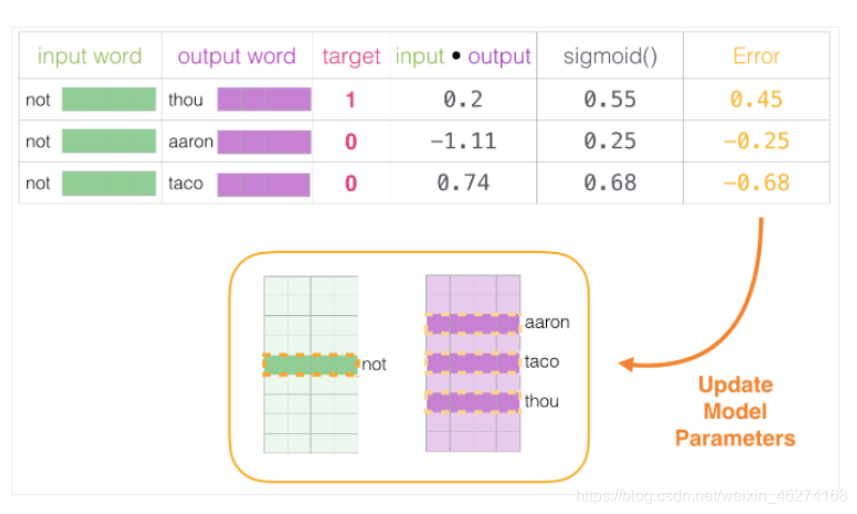
文章来源: iamarookie.blog.csdn.net,作者:我是小白呀,版权归原作者所有,如需转载,请联系作者。
原文链接:iamarookie.blog.csdn.net/article/details/114465682

- 点赞
- 收藏
- 关注作者
评论(0)