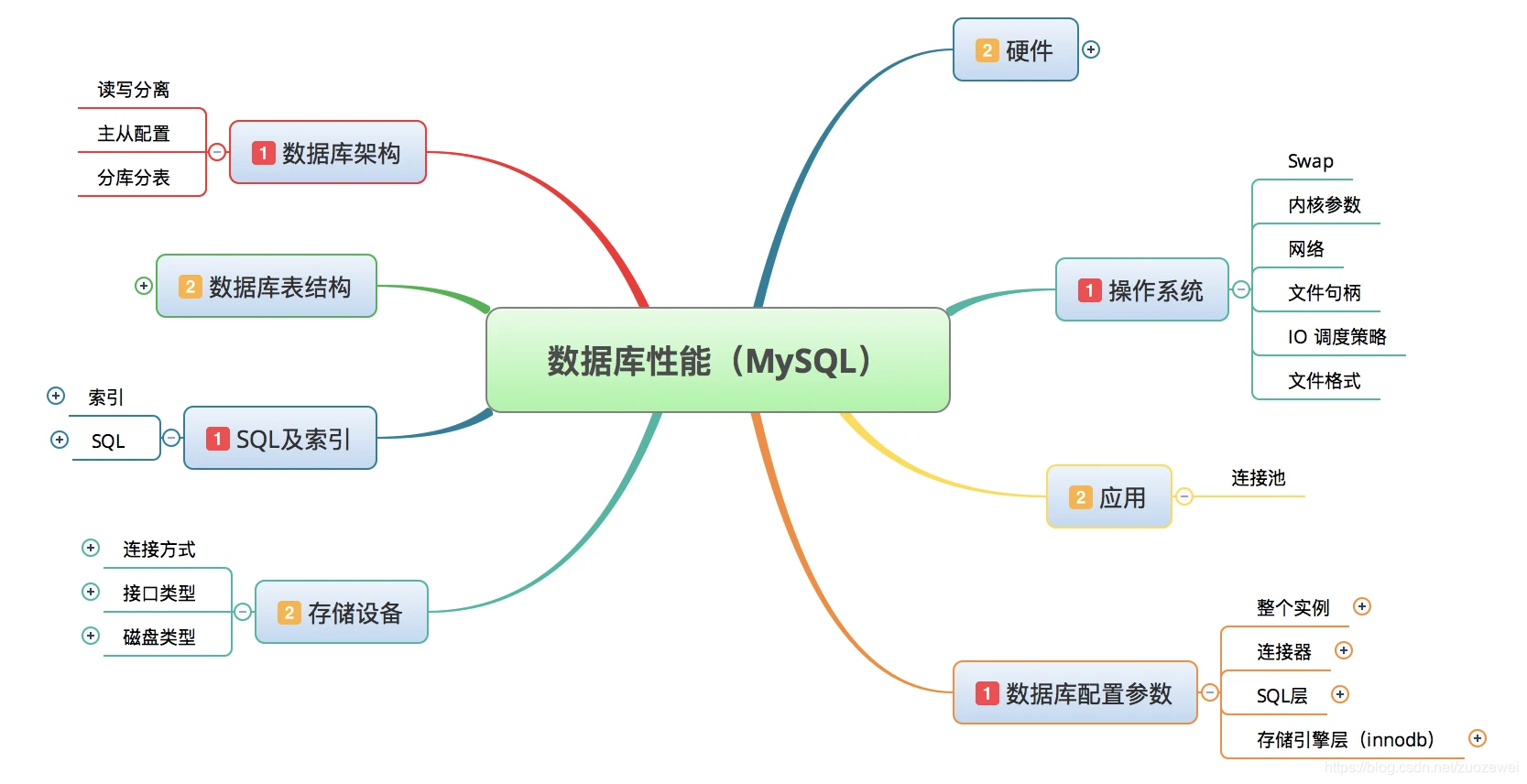
性能分析之 MySQL Report 分析(建议收藏)

声明:近期在工作时需要用到 mysqlreport 时,做的一些整理。
基本信息
MySQL 当前的版本,运行的时间,以及当前系统时间。 MySQL 服务器版本信息表明 MySQL 服务器包含和不包含哪些特点。
MySQL 服务器运行时间表明报告价值的代表性。服务器运行时间对于评估报告是很重要的,因为如果服务器不运行几个小时的话,输出报告有可能存在曲解和误导性。
有时甚至运行几个小时时间都是不够的,比如,MySQL 服务器运行了午夜的 6 个小时几乎没有业务访问过。
最理想的情况是,MySQL 服务器运行一天之后再运行 mysqlreport 来输出报告,这样报告的代表价值要比系统刚运行时要好的多。
在性能场景的运行周期前启动 MySQL ,在性能场景结束后生成 mysqlreport 会比较有用。
比如此例中,场景运行了1小时后执行了 mysqlreport。
MySQL 5.7.18-log uptime 0 1:0:51 Sat Sep 22 21:43:01 2018
索引报表
说明 mysql 当前索引缓冲区的使用率,如果过高,则需要调整 keybuffersize 的大小了。write hit 及 read hit 分别说明了写索引和读索引的效率。 keybuffersize 对 MyISAM 引擎的性能有很大的影响。 不能表明是否 MySQL 服务器索引是否良好,但是能够指示 shared key buffer(共享索引缓存)是否被充分利用。本部分仅能显示用于 MyISAM 表的共享索引缓存,其他的缓存并没有显示。
MySQL 服务器的首要问题:
索引缓存用了多少?如果它并没有被用很多,说明状况比较好,MySQL 仅仅是在需要时分配了用于索引缓存的系统 RAM。也就是说,如果索引缓存设置为 512M,那么 MySQL 不是在系统开始时就分配的 512 M内存,MySQL 仅仅会当需要时才会分配 512 M那么多!
Buffer used,显示的就是 MySQL 曾经一次分配的最大的数量。实际上,MySQL 实际的使用量会少,也有可能多于这个数。MySQL 称之为“高水位(high water mark)”。
这一指标通常说明 MySQL 的配置指标中 keybuffersize 是否足够大。 如果报告的此行指示,MySQL 已经占用了索引缓存的 80 %到 90 %,那么 keybuffersize 的参数就应该增大。
注意,这一行的指标是不可能超过 95 %的。考虑到 mysqlreport 无法计算一些内部数据结构对索引缓存的占用情况,所以,95%通常也就是表示为 100%。 在本例子中,MySQL 利用了 8M 缓存的 3k 空间,所以索引缓存是基本都没有用到。
在本例中,keybuffersize=8388608,即 8M。
__ Key _________________________________________________________________
Buffer used 3.00k of 8.00M %Used: 0.04
请注意,这里所指的 Key Buffer 是指 MyISAM Storage Engine 所使用的 Shared Key Buffer,InnoDB 所使用的 Key Buffer 并不包含在内。 MySQL Server 的 Buffer 大略可分为二种:
-
Global Buffer:由所有 Client 所共享的 Buffer、keybuffer、innodbbufferpool、innodblogbuffer、innodbadditionalmempool net_buffer …等等
-
Thread Buffer:个别的 Connection 所需占用的 Buffer 例如: sortbuffer、myisamsortbuffer、readbuffer、joinbuffer readrnd_buffer …等等。
计算 Server 至少需使用的总内存数量的方式为:
关于 MySQL 的 Cache 机制有一点需要特别注意,MyISAM Storage Engine 将每个 table 分成三个档案储存在硬盘之中,例如若有一个数据表的名称为 example,那么就会在硬盘上发现 example.FRM, example.MYD,example.MYI 等三个档案。
这三个档案所储存的数据如下:
- FRM: 储存这个数据表的结构
- MYD: Row Data,也就是你存在 example 数据表里的数据
- MYI: 此数据表的索引
接下来是重点: 当 MySQL 要 Cache 某个资料表时,MySQL 只会 Cache 索引,也就是 MYI 档案,而 Row Data( MYD )则是交由操作系统来负责 Cache。
到底 Key Buffer 要设定多少才够呢?如前所述,MySQL 只会 Cache 索引(MYI),因此只要将数据库中所有的 MYI 档案加总起来,你就会知道大概要设为多少。
这一行指示 MySQL 在生成报告时占用索引缓存的情况(4.1.2和以后的版本有效,因为 Keyblocksunused 是在 4.1.2 以后才增加的。)。如果前一行表示是一个高水位指示,那么这一行的占用量应该是小于或等于上一行的高水位。有时也会高于高水位指示,这是不是 MySQL 的 Bug 目前还不得而知。不管怎样,这一行和前一行的结果能够很好地指示 keybuffersize 的参数设置的是不是足够大。
在本例子中,MySQL服务器状态就不太好,占用了8M,是索引缓存的 100 %,已经是全部的空间了。
Current 8.00M %Usage: 100.00
从以上两个数据就可以看到的是,mysql 每一次分配的 key buffer都不大,最大的也只有 3 K,但整个 key buffer 占用却已经达到100 %了,所以还是要增加 key buffer size 才行。
索引(keys)是使用固有 RAM 分区的。这一行,Write hit,显示了索引写入的效率(这是个百分比比率值,分子是索引写入硬盘的量,分母是索引写入缓存的量)。索引写入命中率没有一个标准值。索引写入命中率依赖于 MySQL 服务器基本执行的是哪种语句。
如果MySQL主要执行的是 updates 或者 inserts,那么索引写入命中率可能接近 0%是可接受的;
如果MySQL主要执行的是selects,那么索引写入命中率可能 90%或更多是可接受的。
一个负数百分比表示 MySQL 写入索引到硬盘多于写入缓存,这样通常会很慢、不合理的、不可接受的。 最好描述索引写入命中率的方法,就是需要你知道 MySQL 服务器主要执行哪些语句,DMS报告(Lines 17-22)能够帮助解决这一问题。结合 Questions 部分的 DMS 里 insert 的数据量,可知,在这个场景执行的过程中,主要是 insert 语句,所以这里的索引写入命中率接近0%的。
Write hit 0.00%
计算公式:Write hit = MySQL 将索引写入硬盘的次数 / MySQL 将索引写入 RAM 的次数
比索引写入命中率更重要的是索引读取命中率(key read hit)。这一行描述了索引读取的效率(这是个百分比比率值,分子是索引读取硬盘的量,分母是索引读取缓存的量)。索引读取命中率应该低于99%。 过低的百分比表明这会是一个问题。一个低索引命中百分比通常可能是索引空间太小了。索引空间是为了避免MySQL装载过多的索引到内存中,当这种情况发生时,MySQL会恢复从硬盘读取索引,这就会使得硬盘相当慢而且会使索引无效。 通常来讲,开始运行MySQL的前1-2个小时,这一行的值会低于99%,经过 1-2 个小时以后,取值就会接近99%。
Read hit 0.00%
操作报表
操作报表的第一行表示了 MySQL 回应了所有问题的总数和更新时间内的平均回应率。
从下面的数据可以看到,每秒 mysql 的操作是 3.2 k次(QPS),但是有多少完成了,就要看下面的几行数据了。 (这里需要说明的是,“Questions(操作)”是被响应的,而“(Queries查询)”是被执行的。mysqlreport 可以分辨出“操作”和查询,特别是在“操作数报告”中。“操作”是每个和各种对MySQL服务器的请求,这包含了SQL查询和MySQL特定的命令和协议通信,查询是仅包含SQL查询:SELECT, UPDATE 等)
__ Questions ___________________________________________________________
Total 32.20k 3.2k/s
所有的“操作”可分为5类:
- 数据操作语句(DMS)
- 询缓存命中率(QC Hits)
- COMQUIT
- 其他通信命令
- 未知。
这 5 个分类是动态显示的。mysqlreport 按照他们的总次数降序排列。这个子报告能够明显的表示出 MySQL 在忙着干什么。
理想情况下,MySQL 应该忙于 DMS 或者 QC Hits,因为这些行为时真正完成某些事情的。COMQUIT,Com 和 Unknown 类别是必要的,但是处于次要地位。 在进一步解释每一类之前,需要说明的是这部分子报告第三列表明该列值占总“操作”请求数的百分比,“操作”部分的其他子报告也是如此。
在例子中,DMS 数占总操作数的 82.84 %是正常示数。 Data manipulation statements(DMS)包括SELECT,INSERT,REPLACE,UPDATE和DELETE。基本上,DMS 是 MySQL 数据库干的最有用的,因此,DMS 应该是 MySQL 做的最多的。DMS 子报告会详细显示。 QC Hits(Query Cache Hits) 是MySQL查询执行过程中,通过查询缓存补偿,而不是实际执行的操作数。具有一个较高的QC Hits数是令人期待的,因为QC的返回是非常快的。但是,完成有效地QC缓存是非常困难的。这在后面的Query Cache Report中的Insrt:Prune和Hit:Insert部分将深入解释。
在例子中,QC Hits 是没有显示的,说明在这个 report 期间没有 select 语句。
COMQUIT 是个可以忽略的无关紧要的参数,它包含到报告中为了保证完整性。
Com_ 表示 MySQL 处理的各种命令,通常都是协议相关的。理想情况下,在这个指标应当比较低,因为当比较高时,说明 MySQL 忙而无用。该分类参数过高,则表示一些怪异的问题,后面在 Com_ 将详细讨论。
Unknown 是一个推测的目录。理想情况下,前四部分的总和应该是等于全部“操作”数量,但通常不相等。这是因为存在一些MySQL的操作,增加了操作计数器,但是并没有表现在单独的指标上。 这一行会动态显示为 “+Unknown” 或者 “-Unknown”。"+Unknown"表示存在更多的操作数,比 mysqlreport 计算的多;"-Unknown" 表示 mysqlreport 计算的数比所有的统计数少。
DMS 32.20k 3.2k/s %Total: 99.99
COM_QUIT 3 0.3/s 0.01
-Unknown 2 0.2/s 0.01
Com_ 1 0.1/s 0.00
指示了 MySQL 执行的慢查询数目有多少。影响“Slow”指标的系统参数longquerytime,这一参数默认值为10s。很多人认为10s是在数据库时间中时一个恒定值,longquerytime最好设置为1或者毫秒级单位(毫秒设置在MySQL的新版本中支持) longquerytime,这一参数值只有慢查询之后才会显现出来。在mysqlreport v3.5以后,该参数支持:秒、毫秒、微妙。在某些情况下,该参数由于显示宽度8个字母的限制。
例如,longquerytime的参数值’999.999 ms’ 截断成’999.999 ',‘10.000100 s’ 截断成 '10.0001 '。 理想情况下,慢查询的统计应该为0,但是通常也会有一些慢查询的存在。一般来说,慢查询的比率(第三列)占整个操作数的0.05或更低。当有很多慢查询(第一列),这是的比率值就会显示出问题。这一行还增加了一列:DMS 操作数百分比。对于慢查询,0 是最好的,这一列在DMS子报告中更加有用。 最后一列,Log,表示慢查询日志功能开启还是关闭(通过设置logslowqueries参数)。慢查询日志通常是打开的。
Slow 10 s 0 0/s 0.00 %DMS: 0.00 Log: ON
DMS 子报告,和 DTQ 子报告一样,第一列是按照降序排列的,第二列是按每秒计算的结果,第三列表明该列值占总数的百分比。表示了前文所提到数据操作数(SELECT、INSERT等)。 第一行显示的和DTQ报告中的显示一样的。 这一子报告显示MySQL数据库是哪一种类的数据库:是查询负荷高、还是插入负荷高、还是其他的。MySQL 服务器都是倾向于查询负荷高(SELECT heavy)。了解是哪种类型的 MySQL 数据库有利于理解其他的报告值。
例如,一个插入负荷高的服务器,其写入率会接近为1.0,这种类型的数据库锁表报告值也会偏高,这类数据库适合采用 InnoDB 类型表;一个查询负荷高的数据库,就会表现出读取率为1和一个较低的表锁值,这种类型的数据库需要采用查询缓存,适合于采用 MyISAM 表。 在这个例子中,服务器是一个插入高的数据库。很明显,这个数据库面向插入事务。知道数据库类型就有利于数据库参数的优化。
DMS 32.20k 3.2k/s 99.99
INSERT 16.10k 1.6k/s 50.00 50.00
SELECT 16.10k 1.6k/s 50.00 50.00
REPLACE 0 0/s 0.00 0.00
DELETE 0 0/s 0.00 0.00
UPDATE 0 0/s 0.00 0.00
Com 子报告和其他子报告一样分类排序。这部分子报告的内容不同于服务器到服务器命令,因为每一行指示的Com指标都是表现的 MySQL 协议的命令,你可以参考 MySQL 的帮助文档理解这部分概念。 大部分的条目名称都是很直观的,比如Comchangedb。 这部分指标当 DTQ 子报告中的 Com 最高时才起作用,此时表明 MySQL 正忙于“程序事务”而不是 SQL 查询事务。举个例子,一台服务器的 Comrollback 指标很高。
rollback 发生在事务处理失败的时候。服务器的每一次事务处理都失败,很显然,服务器是有问题的。在没有 mysqlreport 的情况下,很明显是不可能分辨出服务器的这些问题的。 大部分服务器,Com_子报告显示没有异常,但是时常地检查该部分报告是很有必要的。
Com_ 1 0.1/s 0.00
show_status 1 0.1/s 0.00
查询和排序报表
Scan 指的是有多少 SELECT statements 造成 MySQL 需要进行 Full Table Scan。
Full Join 的意思与 Scan 差不多,但它是适用在多个 Tables 相互Join 在一起的情况。这二种情况的执行效能都非常的差,因此原则上你会希望这两个数值越低越好。但这也不是绝对的,仍然要考虑实际的情况,例如虽然Server 有很高比例的 Scan,但若这些 Scan 都是针对一些只有几十笔数据的 table,那么相对而言它依然是十分有效率的;但反之,若这些 Scan 是针对具有上百万笔数据的 table,那么就会严重影响系统效能。
__ SELECT and Sort _____________________________________________________
Scan 2 0.2/s %SELECT: 0.01
Range 0 0/s 0.00
Full join 0 0/s 0.00
Range check 0 0/s 0.00
Full rng join 0 0/s 0.00
Sort scan 0 0/s
Sort range 0 0/s
Sort mrg pass 0 0/s
查询缓存报表
查询缓存的目的很简单,将 select 查询的结果缓存在内存中,以供下次直接获取。在这个场景中缓存查询是没有开启的。
query_cache_size = 1048576
query_cache_type = OFF
query_cache_limit = 1048576
在查询为主的数据库的由要开启缓存查询,并且要配置合理的查询缓存大小。
但是,查询缓存有一个需要注意的问题,那就是缓存过期策略,MySQL 采用的机制是,当一个数据表有更新操作(比如 update或者 insert )后,那么涉及这个表的所有查询缓存都会失效。这的确令人比较沮丧,但是 MySQL 这样做是不希望引入新的开销而自找麻烦,所以“宁可错杀一千,不可放过一个”。这样一来,对于 select 和 update 混合的应用来说,查询缓存反而可能会添乱
比如说如下 mysqlreport 中查询缓存的报告:
__ Query Cache ______________________________________________________
Memory usage 38.05M of 256.00M %Used: 14.86
Block Fragmnt 4.29%
Hits 12.74k 33.3/s
Inserts 58.21k 152.4/s
Insrt:Prune 58.21k:1 152.4/s
Hit:Insert 0.22:1
如果你的应用中对于密集 select 的数据表很少更新,很适合于使用查询缓存。 Block Fragmnt这个数值越高表示 Query Cache的碎片状况越严重,通常它会界于 10%~20% 之间。在此范例中 Block Fragmnt为 100%,这是不可接受的情况。可以调整 querycacheminresunit 的值来降低 Block Fragmnt。
__ Query Cache _________________________________________________________
Memory usage 16.35k of 1.00M %Used: 1.60
Block Fragmnt 100.00%
Hits 0 0/s
Inserts 1 0.1/s
Insrt:Prune 1:1 0/s
Hit:Insert 0.00:1
再来分析另一个例子中的 QC 情况:
__ Query Cache_________________________________________________________
Memory usage 17.81M of 32.00M %Used: 55.66
Block Fragmnt 13.05%
Hits 16.58k 8.02/s
Inserts 48.50k 23.48/s
Prunes 33.46k 16.20/s
Insrt:Prune 1.45:1 7.28/s
Hit:Insert 0.34:1
- Hits 是这三个数值中最重要的一项,因为它指出有多少
SELECT statements是可直接从Query Cache里面取得所需的信息,此数值 越高就越好。 - Inserts 和 Prunes 最好是从比值来观察比较容易理解。虽然 Prunes 的值偏高可能代表着Query Cache 设得不够大,但并不一定是如此。在上例中只有 55% 的 Query Cache 被使用,有着相对而言算低的fragmentation 值。但 Prunes 值偏高,Prunes 的值(16/s)是 QC Hits 的两倍。可以想象这台 Server 的
Query Cache是一颗苹果树,它的树枝被剪去的速度比你采收苹果的速度还快。 Insert 与 Prune 的比值可显示Query Cache的挥发性。在一个高度稳定的Query Cache中,Insrt 的值应该要高于 Prune 的值;反之,在一个挥发性较高(较不稳定)的 Query Cache 中,这个比值将会是 1:1 或是偏重在 Prune 那方,这表示 Query Cache 中的数据有可能在使用到之前就已经被清了。我们会希望拥有一个稳定的Query Cache,因为稳定的Query Cache表示那些被 Cache 在Query Cache中的资料会常被用到。高挥发性(较不稳定)的Query Cache 代表两件事情:- 第一,
Query Cache设得太小,需要加大。 - 第二,MySQL 正试图要 cache 所有的东西,甚至是那些其实并不需要 cache 的数据。
- 若是第一种状况,只要单纯的加大
Query Cache即可。 - 若是第二种情况,可能是 MySQL 试图要去 cache 所有可以 cache 的数据,你可以使用 SQLNOCACHE 来明确的告诉 MySQL 什么资料是你不想要 cache 的。
- 第一,
- Hit 与 Insert 的比值代表着
Query Cache的有效性,理想的情况是我们新增了一些 Qeury 到Query Cache中,然后希望得到许多 Hits。因此若是这个 Query Cache 是有效率的,那么该比值应该要偏重在左方。若比值是偏重在 Insert 那方,那么这个 Query Cache 的挥发性就太高了。考虑以下这个比值,若 Hit:Insert 为 1:1,那就表示Query Cache 中的数据只使用了一次就被清除掉了,换句话说,我们放进去的数据比我们从里面拿出来的数据还多,这样一来就失去了使用 Query Cache 的意义。 - 回想我们前面所提过的,虽然在本范例中 QC Hit 在全部的 Questions 中占了很高的比例,但实际上我们可以发现 QC 的有效性其实是很低的(Hit:Insert 的比值偏重在 Insert 那方)。若造成这个现象的原因是 MySQL 正试图cache 所有的东西,那么将 Cache 模式改为 DEMAND 或许可以解决此问题。
表锁报表
Waited 表示有多少次查询需要等待表锁定;Immediate 表示有多少次查询可以立即获得表锁定,同时后面还有一个比例,表示等待表锁定的查询次数占所有查询次数的百分比,这里是0.00%,非常好,但为什么这么低呢?
这需要了解 MyISAM 的表锁定机制。 MyISAM 的表锁定可以允许多个线程同时读取数据,比如 select 查询,它们之间是不需要锁等待的。但是对于更新操作(如 update 操作),它会排斥对当前表的所有其他查询,包括 select 查询。除此之外,更新操作有着默认的高优先级,这意味着当表锁释放后,更新操作将先获得锁定,然后才轮到读取操作。也就是说,如果有很多 update 操作排着长队,那么对当前表的 select 查询必须等到所有的更新都完成之后才能开始。
举例如下:
__ Table Locks______________________________________________________
Waited 1.01k 0.49/s %Total: 1.24
Immediate 80.04k 38.74/s
这个部份包含了两项信息:
- 第一项是 Waited,代表 MySQL 需要等待以取得 table lock 的次数。
- 第二项是 Immediate,表示MySQL 不需要等待即可立刻取得 table lock 的次数。
对数据库来说『等待』几乎可以肯定是一件很不好的事情,因此 Waited 的值应该要越小越好。最具有代表性的是第三个字段 (Waited 占所有 table lock 的百分比),这个数值应该要小于 10%,大于这个值就表示table/query 的索引设计不良或是有过多的 Slow Query。
从下面的数据来看,在场景执行期间就没有发生过锁表的情况。
__ Table Locks _________________________________________________________
Waited 0 0/s %Total: 0.00
Immediate 1 0.1/s
表信息报表
第一是 Open,显示目前正开启的 table 数量、总共可开启的最大数量,以及 Table Cache 的使用状况。
第二是 Opend,表示截至目前为止 MySQL 总共开启过的 Table 数量,以及除上 Uptime 后的比值。
这里有两件事值得注意:
- 首先是 Table Cache 的使用状况,100% 的 Table Cache 使用率并不是一件坏事但你可以试着调大
Table Cache以增进效能 - 第二是 MySQL 开启 Table 的平均速率,若这个值很高则表示的
table_cache设得太小了,需要调大一些。
一般来说, MySQL 开启 Table 的平均速率最好是小于 1/s。但大于这个数值也不一定就是坏事,有些调校良好且运作的十分有效率的 MySQL Server 其值为 7/s 并使用了 100% 的 Table Cache。
__ Tables ______________________________________________________________
Open 816 of 2000 %Cache: 40.80
Opened 1 0.1/s
连接报表
Connections Report 所代表的意义与 Tables Report 相似,请各位以此类推。
比较需要注意的是:若你发现 Connections 的使用率接近 100%,也许你会想调大 maxconnections 的值以允许MySQL 的 Client 建立更多连接。然而,这通常是一种错误。常常可以发现很多网络上的数据会教我们要调大 maxconnections,但却从来没有给一个明确的理由。事实上,maxconnections 的默认值(100),就算是对于负载十分沉重但有良好调校过的 Server 都已十分足够。
MySQL 对于单一连接的数据处理通常只需要零点几秒的时间即可完成,就算是最大只能使用 100 个连接也够让你用上很长一段时间。若是的 Server 有着非常高的最大连接数(max connections)或是单一连接需要很长时间才可完成,那么问题八成不是 maxconnections 的值不够大而是在别的地方,例如 slow queries、索引设计不良、甚至是过于缓慢的 DNS 解析。
在将 max_connections 的值调到 100 以上之前,应该要先确定真的是因为Server 过于忙碌而需要调高此数值,而不是其它地方出了问题。每秒平均连接数有可能会很高,事实上,若这个值很高而且 Server 的运作十分顺畅,那么这通常会是一个好现象,无需担心。大部份 Server 的每秒平均连接数应该都会低于 5/s。
__ Connections _________________________________________________________
Max used 604 of 2000 %Max: 30.20
Total 5 0.5/s
临时表报表
或许看到一些 explain 查询在分析时出现 Using temporary 的状态,这意味着查询过程中需要创建临时表来存储中间数据,我们需要通过合理的索引来避免它。
另一方面,当临时表在所难免时,我们也要尽量减少临时表本身的开销,通过 mysqlreport 报告中的 Created Temp 部分,我们可以看到:
_ Created Temp _____________________________________________________
Disk table 864.89k 2.0/s
Table 7.06M 16.1/s Size: 32.0M
File 9.22k 0.0/s
MySQL 可以将临时表创建在磁盘(Disk table)、内存(Table)以及临时文件(File)中,显然,在磁盘上创建临时表的开销最大,所以我们希望 MySQL 尽量不要在磁盘上创建临时表。
在 MySQL 的配置中,我们可以通过 tmptablesize 选项来设置用于存储临时表的内存空间大小,一旦这个空间不够用,MySQL 将会启用磁盘来保存临时表,你可以根据 mysqlreport 的统计尽量给临时表设置较大的内存空间。
在本示例中,临时表的情况如下,只用到了一个临时表。
__ Created Temp ________________________________________________________
Disk table 0 0/s
Table 1 0.1/s Size: 16.0M
File 0 0/s
线程报表
MySQL 采用多线程来处理并发的连接,通过 mysqlreport 中的 Threads 部分,可以看到线程创建的统计结果:
Threads _____________________________________________________
Running 2 of 5
Cached 0 of 0 %Hit: 0
Created 6.15M 43.6/s
Slow 0 0/s
也许你会觉得创建线程的消耗不值一提,但是所谓优化都是在你系统繁忙下的救命稻草。 一个比较好的办法是在应用中尽量使用持久连接,这将在一定程度上减少线程的重复创建。
另一方面,从上面的 Cached=0 可以看出,这些线程并没有被复用。 在本例中,threadcachesize = 64,只用到了 5 个线程,并且没有复用(Cached)的。
__ Threads _____________________________________________________________
Running 5 of 64
Cached 0 of 64 %Hit: 100
Created 0 0/s
Slow 0 0/s
__ Aborted _____________________________________________________________
Clients 0 0/s
Connects 4 0.4/s
__ Bytes _______________________________________________________________
Sent 27.43M 2.7M/s
Received 18.84M 1.9M/s
上面的 %HIT 需要关注下,每一个连接到 MySQL 的联机都是由不同的 Thread 来处理,当 MySQL 启动时会预先建立一些 Threads 并保留在 Thread Cache 中,如此一来 MySQL 就不用一直忙着建立与删除 Threads。
但当每秒最大联机数大于 MySQL 的 Thread Cache 时,MySQL 就会进入 Thread Thrash 的状态:它不断地建立新的 Threads 以满足不断增加的联机的需求。当 Thread Thrash 发生时,%Hit 的数值就会降低。在本范例中 %Hit 的值为 100%,这是非常好的,因为它表示几乎每一个新进来的联机都不会造成 MySQL 建立新的Thread。
而在本例中,threadcachesize 是 64,当前 Running 的 threads 也很少,可见并没有太大的压力。
InnoDB缓存池报表
nnodbbufferpoolsize 定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区大小。和 MyISAM 存储引擎不同, MyISAM 的 keybuffersize只能缓存索引键,而 innodbbufferpoolsize 却可以缓存数据块和索引键。适当的增加这个参数的大小,可以有效的减少 InnoDB 类型的表的磁盘 I/O。
如果你在 MySQ L中大量使用 Innodb 类型表,则可以将缓冲池大小设置为物理内存的 60%-80%(最好配置成自增长的缓冲池),并持续关注它的使用率。 如下 Usage 表示, 总的缓存 16 G中, 当前已占用 2.27G, 使用率 14.20 %,这种情况下完全不用考虑增加 innodb 缓存池。 Read hit 表示缓存命中率 100%, 这个数值是比较理想的, 一般情况下, 都应该大于 99.98%.
__ InnoDB Buffer Pool __________________________________________________
Usage 2.27G of 16.00G %Used: 14.20
Read hit 100.00%
这部分数据和 innodbflushlogattrx_commit 参数关系非常大。
-
innodbflushlogattrx_commit = 1表示事务提交时立即将事务日志写入磁盘,同时数据和索引也立即更新。这符合事务的持久性原则。 -
innodbflushlogattrx_commit = 0表示事务提交时不立即将事务日志写入磁盘,而是每隔 1 秒写入磁盘文件一次,并且刷新到磁盘,同时更新数据和索引。这样一来,如果 mysqld 崩溃,那么在内存中事务日志缓冲区最近 1 秒的数据将会丢失,这些更新将永远无法恢复。 -
innodbflushlogattrx_commit = 2表示事务提交时立即写入磁盘文件,但是不立即刷新到磁盘,而是每隔 1 秒刷新到磁盘一次,同时更新数据和索引。在这种情况下,即使 mysqld 崩溃后,位于内核缓冲区的事务日志仍然不会丢失,只有当操作系统崩溃的时候才会丢失最后 1 秒的数据。
显然,将 innodbflushlogattrx_commit 设置为 0 可以获得最佳性能,同时它的数据丢失可能性也最大。
- Free: 空闲页,是使用率(%Used)的对立方。
- Data: 数据页,列 %Dirty,展示已经被修改过,但还没有被刷新到磁盘存储的数据页的比率。
- Misc:用于管理分配行锁和自适应哈希索引导致的开销使用的页。
- Latched: 目前正在读写、或者因为其他原因无法被刷新的页。
Pages
Free 899.55k %Total: 85.80
Data 148.89k 14.20 %Drty: 0.34
Misc 6 0.00
Latched 0.00
Reads 从内存读取的数量, 这个数值可以用来衡量 innodb 缓冲池的吞吐量,因为几乎所有 inondb 需要的东西都是在缓冲池里,所以缓冲池的读性能是越快越好。 哪怕超过每秒 200000 次也不是不可能的 。
- From file: 从磁盘读的数量,越小越好。
- Ahead Rnd: 随机读,innodb 启动的随机读取数。只有对表的大部分内容进行随机扫描的时候才会出现。
- Ahead Sql: 顺序读,只有全表扫描才会出现。
- Writes:本行显示写的数量以及读写的比率。如果服务器主要操作是update和insert的话,这个值也会比较高。
- Flushes: 缓冲池的页刷新请求数。
- Wait Free:一般情况下,innodb 缓冲池的写操作是后台运行的。不过,如果出现必须要读写一个页可偏偏没有可用的新页时,(innodb)就只能先等待页的刷新了。这个变量就是这些等待的总数。只要缓冲池的大小设置得当,等待数应该会很小。
Reads 191.27k 19.1k/s
From file 0 0/s 0.00
Ahead Rnd 0 0/s
Ahead Sql 0/s
Writes 122.74k 12.3k/s
Flushes 1.05k 105.5/s
Wait Free 0 0/s
innodb 锁报表
- Waits:等待某行解锁的累积次数,最好为0。
- Current:当前正在等待解锁的行个数,最好为0。
- Time acquiring:显示了毫秒(ms)级行锁等待数据。分别是总值、平均值和最大值。同样最好是 0 次。
__ InnoDB Lock _________________________________________________________
Waits 0 0/s
Current 0
Time acquiring
Total 0 ms
Average 0 ms
Max 0 ms
InnoDB 数据、页、行报表
这部分报告,一般广泛的用于衡量 innodb 引擎的吞吐量指标。
- Reads/Writes: 指的是整个innodb引擎完成所有的数据读/写次数。
注意:
不是整个数据读取字节数或者类型,而是 innodb 完成的数据读/写次数。
- fsync: 刷新,innodb从内存写入磁盘的次数。这个值应该会比前两个小。
- Pending: 等待,又被分成了三行(108-110),分别是读、写、刷新的等待次数。
__ InnoDB Data, Pages, Rows ____________________________________________
Data
Reads 0 0/s
Writes 13.12k 1.3k/s
fsync 125 12.5/s
Pending
Reads 0
Writes 0
fsync 0
包括三种自描述类型:创建、读取、写入,分别用来表示缓冲池中页的创建、读取 和写入的数量和速率(即每秒操作数)。
Pages
Created 753 75.3/s
Read 0 0/s
Written 1.05k 105.5/s
Rows
Deleted 0 0/s
Inserted 16.10k 1.6k/s
Read 0 0/s
Updated 0 0/s

- 点赞
- 收藏
- 关注作者
评论(0)