性能分析之单条SQL查询案例分析(mysql)

引言
本文将以一个案例详细展开介绍如何针对单条SQL进行性能分析。
背景
在定位到需要优化的单条查询SQL后,我们可以针对此查询“钻取”更多信息,分析为什么会花费怎么长的时间执行,以及如何去优化的大致方向。
准备工作
环境准备
- 操作系统:window/linux
- 数据库: MySQL 5.7
数据准备
创建一个数据库表
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '编号',
ename VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名字',
job VARCHAR(9) NOT NULL DEFAULT "" COMMENT '工作',
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '上级编号',
hiredate DATE NOT NULL COMMENT '入职时间',
sal DECIMAL(7,2) NOT NULL COMMENT '薪水',
comm DECIMAL(7,2) NOT NULL COMMENT '红利',
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '部门编号'
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
构建一个存储函数,这个存储函数会返回一个长度为参数 n 的随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
接下来我们再创建一个存储函数,该存储函数会返回一个随机 int 值
delimiter $$
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
然后我们利用刚刚创建的两个存储函数创建一个存储过程,该存储过程包含一个参数,该参数表示插入数据表 emp 的数据条数
elimiter $$
create procedure insert_emp(in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values (i ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
我们调用创建的存储过程,对 emp 表插入 1000w 条数据
call insert_emp(10000000);
最后,统计表数据
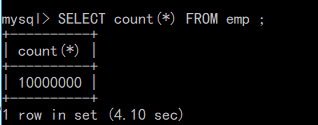
案例分析
查询SQL
现在我们运行一个查询时间超过 1s 的查询语句

Explain 执行计划
MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发/测试人员针对性优化
EXPLAIN 命令的使用十分简单,只需要"EXPLAIN + SQL 语句"即可,如下命令就是对我们刚刚的慢查询语句使用 EXPLAIN 之后的结果

可以看到,EXPLAIN 命令的结果一共有以下几列:
- id: SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符.
- select_type: SELECT 查询的类型
- PRIMARY(子查询中最外层查询)
- SUBQUERY(子查询内层第一个 SELECT)
- UNION( UNION 语句中第二个 SELECT 开始后面所有 SELECT)
- SIMPLE(除了子查询或者 UNION 之外的其他查询)
- table: 查询的是哪个表
- partitions: 匹配的分区
- type: join 类型,性能关系:ALL < index < range ~ index_merge < ref < eq_ref < const < system
- all(全表扫描)
- index(全索引扫描)
- rang(索引范围扫描)
- ref(join语句中被驱动表索引引用查询)
- eq_ref(通过主键或唯一索引访问,最多只会有一条结果)
- const(读常量,只需读一次)
- system(系统表,表中只有一条数据)
- null(速度最快)
- possible_keys: 此次查询中可能选用的索引
- key: 此次查询中确切使用到的索引
- key_len:使用索引的最大长度;
- ref: 哪个字段或常数与 key 一起被使用
- rows: 显示此查询一共扫描了多少行. 这个是一个估计值.
- filtered: 表示此查询条件所过滤的数据的百分比
- extra: 额外的信息
- distinct
- using filesort(order by 操作)
- using index(所查数据只需要在 index 中即可获取)
- using temporary(使用临时表)
- using where(如果包含 where,且不是仅通过索引即可获取内容,就会包含此信息)
这样,通过执行计划我们就可以清楚的看到,这条查询语句是一个全表扫描语句,查询时没有用到任何索引,所以它的查询时间肯定会很慢。
Show Profiling
Show Profiling 命令是在 MySQL5.1 以后引入的,来源于开源社区中的 Jeremy Cole 的贡献。在 MySQL 数据库中默认是禁用的,可以通过服务器变量在会话(连接)级别动态地修改。然后,在服务器上执行的所有语句,都会测量其耗费的时间和其它一些查询执行状态变更相关数据。

接下来我们执行一条查询命令

在开启了Query Profiler 功能之后,MySQL 就会自动记录所有执行的 Query 的 Profiling 信息。 然后我们通过以下命令获取系统中保存的所有 Query 的 profile 概要信息
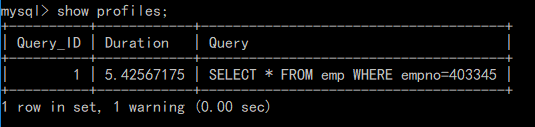
然后我们可以通过以下命令查看具体的某一次查询的 Profiling 信息

Profiling 剖析报告给出了执行查询的每个步骤及其花费的时间,看结果可以快速的确定是那个步骤花费的时间最多。
以上各字段含义:
- starting:开始
- checking permissions:鉴权
- Opening tables :打开表
- init:初始化
- System lock:系统锁
- optimizing:优化
- statistics:统计
- preparing:准备
- executing:执行
- Sending data:发送数据
- end:结束
- query end:查询结果
- closing tables:关闭表
- freeing items:释放items
- cleaning up:清理
type 参数可以指定以显示特定的其他类型的信息:
- ALL:显示所有信息
- BLOCK IO: 显示块输入和输出操作的计数
- CONTEXT SWITCHES: 显示自愿和非自愿上下文切换的计数
- CPU: 显示用户和系统 CPU 使用时间
- IPC: 显示发送和接收的消息的计数
- MEMORY: 目前尚未实施
- PAGE FAULTS: 显示主要和次要页面错误的计数
- SOURCE: 显示源代码中的函数名称,以及函数发生的文件的名称和行号
- SWAPS: 显示交换计数
通过这个结果可以很容易看到,由于这是一次全表扫描,这里耗时最大是在 sending data(发送数据)上。
除了这种情况,以下几种情况也可能耗费大量时间:
- converting HEAP to MyISAM (查询结果太大时,把结果放在磁盘)
- create tmp table (创建临时表,如 group 时储存中间结果)
- Copying to tmp table on disk (把内存临时表复制到磁盘)
- locked (被其他查询锁住)
- logging slow query (记录慢查询)
HOW STATUS
SHOW STATUS 命令返回一些计数器,既有服务器级别的全局计时器,也有基于某个连接的会话级别的计数器。例如其中的 Queries 在会话开始时为0,每提交一次查询增加1。如果执行 SHOW GLOBAL STATUS,则可以查看服务器级别(从服务器启动时开始计算的查询次数统计)。不同的计数器可见范围不一样,全局计数器也会出现在SHOW STATUS 的结果中,这样容易被误认为会话级,所以一定不能搞迷糊了。
SHOW STATUS是一个很有用的工具,但并不是一款剖析工具。虽然无法提供基于时间的统计,但是执行查询完后观察某些计数器的值还是很有帮助的。

从结果可以看出该查询有很多的没有用到索引的 Handler_read_rnd_next(读操作)以及Key_blocks_unused(未使用的缓存簇(blocks)数)。假设我们不知道这条 SQL 具体的定义仅从结果来推测,这个查询有可能是全表扫描,没有合适的索引。
我们可能注意到通过 Explain 执行计划也可以获得大部分相同的信息,但是 Explain 是通过估计得到的结果,而通过计数器则是实际的测量结果。
各参数详解参考官方资料:
https://dev.mysql.com/doc/refman/5.6/en/server-status-variables.html
慢查询日志
我们可以用以下命令查看慢查询次数
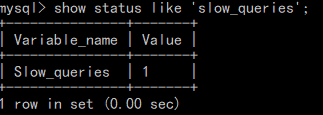
使用该命令只能查看慢查询次数,但是我们没有办法知道是哪些查询产生了慢查询,如果想要知道是哪些查询导致的慢查询,那么我们必须修改 mysql 的配置文件。打开 mysql 的配置文件(windows系统是my.ini,linux系统是my.cnf),在 [mysqld] 下面加上以下代码
# General and Slow logging.
log-output=FILE
general-log=0
general_log_file="DESKTOP-MLD0KTS.log"
slow-query-log=1
slow_query_log_file="DESKTOP-MLD0KTS-slow.log"
long_query_time=1
此时我们在 mysql 中运行以下命令,可以看到 slow_query_log 是 ON 状态,log_file 也是我们指定的文件

运行以下命令我们可以看到我们设定的慢查询时间也生效了,此时只要查询时间大于 1s,查询语句都将存入日志文件
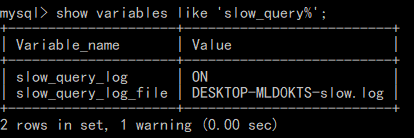
现在我们运行一个查询时间超过 1s 的查询语句,然后查看 mysql 安装目录下的 data 目录,该目录会产生一个慢查询日志文件:mysql_slow.log,该文件内容如下

在该日志文件中,我们可以知道慢查询产生的时间,最终产生了几行结果,测试了几行结果,以及运行语句是什么。在这里我们可以看到,这条语句产生一个结果,但是检测了 1000w 行记录,是一个全表扫描语句。
参考资料:
[1]Vadim Tkacbenko著.高性能MySQL.北京:电子工业出版社,2013.

- 点赞
- 收藏
- 关注作者
评论(0)