Python 统计基础:(二)如何描述您的数据

目录
处理二维数据
统计学家经常使用二维数据。以下是 2D 数据格式的一些示例:
NumPy 和 SciPy 提供了一种处理二维数据的综合方法。Pandas 有DataFrame专门用于处理 2D 标记数据的类。
轴
首先创建一个 2D NumPy 数组:
>>> a = np.array([[1, 1, 1],
... [2, 3, 1],
... [4, 9, 2],
... [8, 27, 4],
... [16, 1, 1]])
>>> a
array([[ 1, 1, 1],
[ 2, 3, 1],
[ 4, 9, 2],
[ 8, 27, 4],
[16, 1, 1]])
现在您有一个 2D 数据集,您将在本节中使用它。您可以像处理一维数据一样将 Python 统计函数和方法应用于它:
>>> np.mean(a)
5.4
>>> a.mean()
5.4
>>> np.median(a)
2.0
>>> a.var(ddof=1)
53.40000000000001
如您所见,您可以获得数组中所有数据的统计数据(如均值、中位数或方差)a。有时,这种行为正是您想要的,但在某些情况下,您需要为二维数组的每一行或每一列计算这些数量。
到目前为止,您使用的函数和方法都有一个名为 的可选参数axis,它对于处理 2D 数据至关重要。axis可以采用以下任何值:
axis=None表示计算数组中所有数据的统计信息。上面的例子是这样工作的。此行为通常是 NumPy 中的默认设置。axis=0表示计算所有行的统计信息,即数组的每一列。这种行为通常是 SciPy 统计函数的默认行为。axis=1表示计算所有列的统计信息,即数组的每一行。
让我们来看看axis=0在行动np.mean():
>>> np.mean(a, axis=0)
array([6.2, 8.2, 1.8])
>>> a.mean(axis=0)
array([6.2, 8.2, 1.8])
上面的两个语句返回新的 NumPy 数组,每个数组的平均值为a。在这个例子中,第一列的平均值是6.2。第二列有均值8.2,而第三列有1.8。
如果您提供axis=1给mean(),那么您将获得每一行的结果:
>>> np.mean(a, axis=1)
array([ 1., 2., 5., 13., 6.])
>>> a.mean(axis=1)
array([ 1., 2., 5., 13., 6.])
如您所见,第一行a有 mean 1.0,第二行2.0,依此类推。
注意:您可以将这些规则扩展到多维数组,但这超出了本教程的范围。随意深入研究这个主题!
该参数axis与其他 NumPy 函数和方法的工作方式相同:
>>> np.median(a, axis=0)
array([4., 3., 1.])
>>> np.median(a, axis=1)
array([1., 2., 4., 8., 1.])
>>> a.var(axis=0, ddof=1)
array([ 37.2, 121.2, 1.7])
>>> a.var(axis=1, ddof=1)
array([ 0., 1., 13., 151., 75.])
您已获得数组所有列 ( axis=0) 和行 ( axis=1)的中位数和样本变化a。
当您使用 SciPy 统计函数时,这非常相似。但请记住,在这种情况下,默认值axis是0:
>>> scipy.stats.gmean(a) # Default: axis=0
array([4. , 3.73719282, 1.51571657])
>>> scipy.stats.gmean(a, axis=0)
array([4. , 3.73719282, 1.51571657])
如果您省略axis或提供axis=0,那么您将获得所有行(即每一列)的结果。例如, 的第一列的a几何平均值为4.0,依此类推。
如果您指定axis=1,那么您将获得所有列的计算,即每一行:
>>> scipy.stats.gmean(a, axis=1)
array([1. , 1.81712059, 4.16016765, 9.52440631, 2.5198421 ])
在这个例子中,第一行的几何平均值a是1.0。对于第二行,它大约是1.82,依此类推。
如果你想要整个数据集的统计数据,那么你必须提供axis=None:
>>> scipy.stats.gmean(a, axis=None)
2.829705017016332
数组中所有项的几何平均值a约为2.83。
您可以使用scipy.stats.describe()对二维数据进行单个函数调用,从而获得 Python 统计摘要。它的工作原理类似于一维数组,但你必须小心参数axis:
>>> scipy.stats.describe(a, axis=None, ddof=1, bias=False)
DescribeResult(nobs=15, minmax=(1, 27), mean=5.4, variance=53.40000000000001, skewness=2.264965290423389, kurtosis=5.212690982795767)
>>> scipy.stats.describe(a, ddof=1, bias=False) # Default: axis=0
DescribeResult(nobs=5, minmax=(array([1, 1, 1]), array([16, 27, 4])), mean=array([6.2, 8.2, 1.8]), variance=array([ 37.2, 121.2, 1.7]), skewness=array([1.32531471, 1.79809454, 1.71439233]), kurtosis=array([1.30376344, 3.14969121, 2.66435986]))
>>> scipy.stats.describe(a, axis=1, ddof=1, bias=False)
DescribeResult(nobs=3, minmax=(array([1, 1, 2, 4, 1]), array([ 1, 3, 9, 27, 16])), mean=array([ 1., 2., 5., 13., 6.]), variance=array([ 0., 1., 13., 151., 75.]), skewness=array([0. , 0. , 1.15206964, 1.52787436, 1.73205081]), kurtosis=array([-3. , -1.5, -1.5, -1.5, -1.5]))
当您提供 时axis=None,您将获得所有数据的摘要。大多数结果是标量。如果设置axis=0或省略它,则返回值是每列的摘要。因此,大多数结果是项目数与列数相同的数组。如果设置axis=1,则describe()返回所有行的摘要。
您可以使用点符号从摘要中获取特定值:
>>> result = scipy.stats.describe(a, axis=1, ddof=1, bias=False)
>>> result.mean
array([ 1., 2., 5., 13., 6.])
这就是您可以通过单个函数调用查看二维数组的统计摘要的方式。
数据帧
该类DataFrame是 Pandas 的基本数据类型之一。使用起来非常舒服,因为它有行和列的标签。使用数组a并创建一个DataFrame:
>>> row_names = ['first', 'second', 'third', 'fourth', 'fifth']
>>> col_names = ['A', 'B', 'C']
>>> df = pd.DataFrame(a, index=row_names, columns=col_names)
>>> df
A B C
first 1 1 1
second 2 3 1
third 4 9 2
fourth 8 27 4
fifth 16 1 1
在实践中,列的名称很重要并且应该是描述性的。行的名称有时会自动指定为0、1等。您可以使用参数 明确指定它们index,但index如果您愿意,也可以随意省略。
DataFrame方法与方法非常相似Series,但行为不同。如果不带参数调用 Python 统计方法,DataFrame则将返回每一列的结果:
>>> df.mean()
A 6.2
B 8.2
C 1.8
dtype: float64
>>> df.var()
A 37.2
B 121.2
C 1.7
dtype: float64
你得到的是一个新Series的结果。在这种情况下,Series保存每列的均值和方差。如果你想要每一行的结果,那么只需指定参数axis=1:
>>> df.mean(axis=1)
first 1.0
second 2.0
third 5.0
fourth 13.0
fifth 6.0
dtype: float64
>>> df.var(axis=1)
first 0.0
second 1.0
third 13.0
fourth 151.0
fifth 75.0
dtype: float64
结果是Series每行所需的数量。标签'first'、'second'等指的是不同的行。
您可以DataFrame像这样隔离 a 的每一列:
>>> df['A']
first 1
second 2
third 4
fourth 8
fifth 16
Name: A, dtype: int64
现在,您拥有对象'A'形式的列Series,您可以应用适当的方法:
>>> df['A'].mean()
6.2
>>> df['A'].var()
37.20000000000001
这就是您如何获取单个列的统计信息。
有时,您可能希望将 aDataFrame用作 NumPy 数组并对其应用一些函数。可以从DataFramewith.values或获取所有数据.to_numpy():
>>> df.values
array([[ 1, 1, 1],
[ 2, 3, 1],
[ 4, 9, 2],
[ 8, 27, 4],
[16, 1, 1]])
>>> df.to_numpy()
array([[ 1, 1, 1],
[ 2, 3, 1],
[ 4, 9, 2],
[ 8, 27, 4],
[16, 1, 1]])
df.values并df.to_numpy()为您提供一个 NumPy 数组,其中包含DataFrame没有行和列标签的所有项目。请注意,这df.to_numpy()更灵活,因为您可以指定项目的数据类型以及是要使用现有数据还是复制它。
像Series,DataFrame对象具有.describe()返回另一个DataFrame包含所有列的统计信息摘要的方法:
>>> df.describe()
A B C
count 5.00000 5.000000 5.00000
mean 6.20000 8.200000 1.80000
std 6.09918 11.009087 1.30384
min 1.00000 1.000000 1.00000
25% 2.00000 1.000000 1.00000
50% 4.00000 3.000000 1.00000
75% 8.00000 9.000000 2.00000
max 16.00000 27.000000 4.00000
摘要包含以下结果:
count:每列中的项目数mean:每列的平均值std:标准差minandmax:最小值和最大值25%,50%, 和75%:百分位数
如果您希望结果DataFrame对象包含其他百分位数,则应指定可选参数的值percentiles。
您可以像这样访问摘要的每个项目:
>>> df.describe().at['mean', 'A']
6.2
>>> df.describe().at['50%', 'B']
3.0
这就是您可以通过Series单个 Pandas 方法调用在一个对象中获得描述性 Python 统计信息的方法。
可视化数据
除了计算平均值、中位数或方差等数值量外,您还可以使用视觉方法来呈现、描述和汇总数据。在本节中,您将学习如何使用以下图表直观地呈现您的数据:
- 箱线图
- 直方图
- 饼状图
- 条形图
- XY 图
- 热图
matplotlib.pyplot是一个非常方便且广泛使用的库,尽管它不是唯一可用于此目的的 Python 库。您可以像这样导入它:
>>> import matplotlib.pyplot as plt
>>> plt.style.use('ggplot')
现在,您已matplotlib.pyplot导入并可以使用。第二个语句通过选择颜色、线宽和其他样式元素来设置绘图的样式。如果您对默认样式设置感到满意,您可以随意省略这些设置。
注意:本节侧重于表示数据并将样式设置保持在最低限度。您将在 中看到指向所用例程的官方文档的链接matplotlib.pyplot,因此您可以探索在此处看不到的选项。
您将使用伪随机数来获取要处理的数据。您不需要有关随机数的知识就可以理解本节。您只需要一些任意数字,而伪随机生成器是获取它们的便捷工具。该模块np.random生成伪随机数数组:
- 正态分布的数字是用 生成的
np.random.randn()。 - 均匀分布的整数是用 生成的
np.random.randint()。
NumPy 1.17 引入了另一个用于生成伪随机数的模块。要了解更多信息,请查看官方文档。
箱线图
的箱形图是在视觉上表示给定的数据集的描述性统计的优秀工具。它可以显示极差、四分位距、中位数、众数、异常值和所有四分位数。首先,创建一些数据以用箱线图表示:
>>> np.random.seed(seed=0)
>>> x = np.random.randn(1000)
>>> y = np.random.randn(100)
>>> z = np.random.randn(10)
第一条语句使用 设置 NumPy 随机数生成器的种子seed(),因此每次运行代码时都可以获得相同的结果。您不必设置种子,但如果您不指定此值,那么每次都会得到不同的结果。
其他语句生成三个具有正态分布伪随机数的 NumPy 数组。x指具有 1000 个项目的数组,y有 100 个,z包含 10 个项目。现在您有了要处理的数据,您可以申请.boxplot()获取箱线图:
fig, ax = plt.subplots()
ax.boxplot((x, y, z), vert=False, showmeans=True, meanline=True,
labels=('x', 'y', 'z'), patch_artist=True,
medianprops={'linewidth': 2, 'color': 'purple'},
meanprops={'linewidth': 2, 'color': 'red'})
plt.show()
参数.boxplot()定义如下:
x是你的数据。vert时将绘图方向设置为水平False。默认方向为垂直。showmeans显示当 时数据的平均值True。meanline当 时将平均值表示为一条线True。默认表示是一个点。labels:你的数据标签。patch_artist决定如何绘制图形。medianprops表示代表中位数的线的属性。meanprops表示代表平均值的线或点的属性。
还有其他参数,但它们的分析超出了本教程的范围。
上面的代码产生这样的图像:
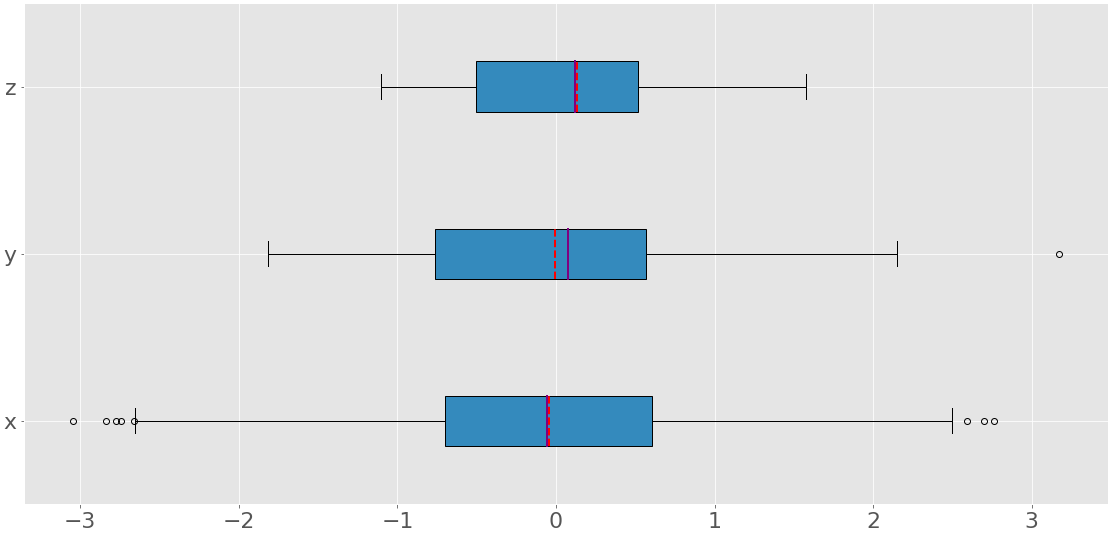
您可以看到三个箱线图。它们中的每对应于单个的数据集(x,y,或z),并显示如下:
- 平均值是红色虚线。
- 中位数是紫色线。
- 第一个四分位数是蓝色矩形的左边缘。
- 第三个四分位数是蓝色矩形的右边缘。
- 四分位距是蓝色矩形的长度。
- 该范围包含从左到右的所有内容。
- 异常值是左侧和右侧的点。
箱线图可以在一个图中显示如此多的信息!
直方图
当数据集中存在大量唯一值时,直方图特别有用。直方图将排序数据集中的值划分为多个区间,也称为bins。通常,所有 bin 的宽度都相等,但并非必须如此。bin 的下限和上限的值称为bin 边缘。
的频率是对应于每个区间的单个值。它是数据集的元素数,其值位于 bin 的边缘之间。按照惯例,除了最右边的一个之外,所有垃圾箱都是半开的。它们包括等于下限的值,但不包括等于上限的值。最右边的 bin 是关闭的,因为它包括两个边界。如果用 bin 边 0、5、10 和 15 划分数据集,则有三个 bin:
- 第一个和最左边的 bin包含大于或等于 0 且小于 5 的值。
- 第二个 bin包含大于或等于 5 且小于 10 的值。
- 第三个也是最右边的 bin包含大于或等于 10 且小于或等于 15 的值。
该函数np.histogram()是获取直方图数据的便捷方法:
>>> hist, bin_edges = np.histogram(x, bins=10)
>>> hist
array([ 9, 20, 70, 146, 217, 239, 160, 86, 38, 15])
>>> bin_edges
array([-3.04614305, -2.46559324, -1.88504342, -1.3044936 , -0.72394379,
-0.14339397, 0.43715585, 1.01770566, 1.59825548, 2.1788053 ,
2.75935511])
它接受包含您的数据的数组和 bin 的数量(或边缘)并返回两个 NumPy 数组:
hist包含对应于每个 bin 的项目的频率或数量。bin_edges包含 bin 的边缘或边界。
什么histogram()计算,.hist()可以显示图形:
fig, ax = plt.subplots()
ax.hist(x, bin_edges, cumulative=False)
ax.set_xlabel('x')
ax.set_ylabel('Frequency')
plt.show()
的第一个参数.hist()是数据的序列。第二个参数定义 bin 的边缘。第三个禁用使用累积值创建直方图的选项。上面的代码产生了这样的图:
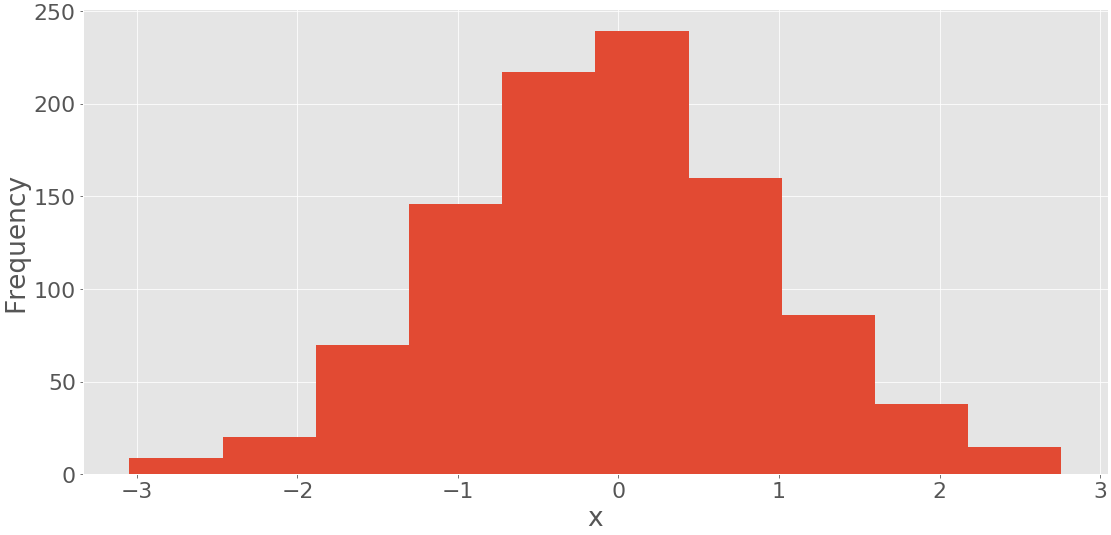
您可以在水平轴上看到 bin 边缘,在垂直轴上看到频率。
这是可能获得与您提供的参数的数据项的累积数量的直方图cumulative=True来.hist():
fig, ax = plt.subplots()
ax.hist(x, bin_edges, cumulative=True)
ax.set_xlabel('x')
ax.set_ylabel('Frequency')
plt.show()
此代码产生下图:
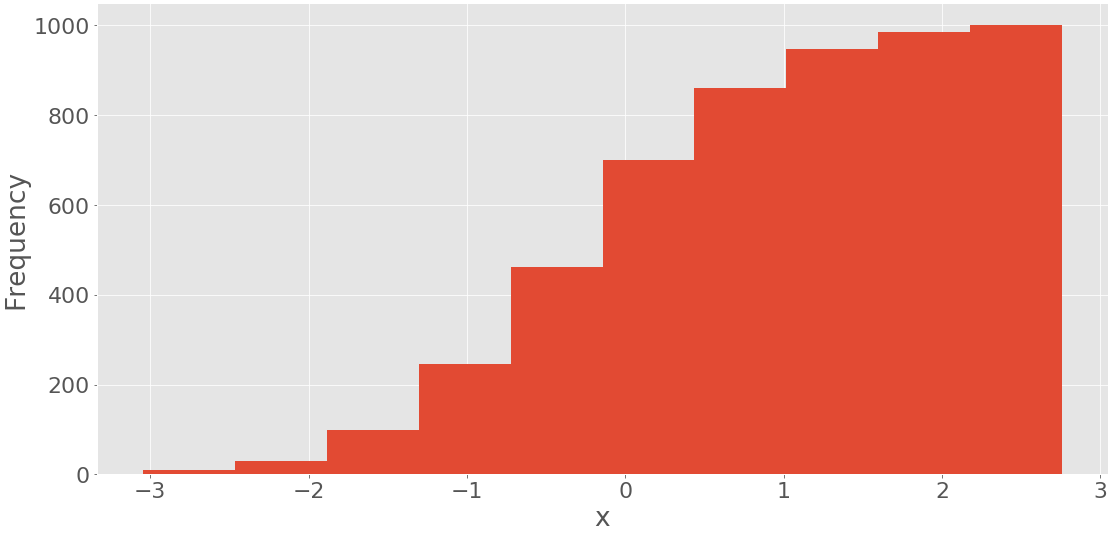
它显示带有累积值的直方图。第一个和最左边的 bin 的频率是这个 bin 中的项目数。第二个 bin 的频率是第一个和第二个 bin 中项目数的总和。其他 bin 遵循相同的模式。最后,最后一个和最右边的 bin 的频率是数据集中的项目总数(在本例中为 1000)。您也可以在后台pd.Series.hist()使用 using直接绘制直方图matplotlib。
饼状图
饼图表示带有少量标签和给定相对频率的数据。即使使用无法排序的标签(如标称数据),它们也能很好地工作。饼图是一个分成多个切片的圆。每个切片对应于数据集中的单个不同标签,并且其面积与与该标签相关联的相对频率成正比。
让我们定义与三个标签关联的数据:
>>> x, y, z = 128, 256, 1024
现在,创建一个饼图.pie():
fig, ax = plt.subplots()
ax.pie((x, y, z), labels=('x', 'y', 'z'), autopct='%1.1f%%')
plt.show()
的第一个参数.pie()是您的数据,第二个参数是相应标签的序列。autopct定义图中显示的相对频率的格式。你会得到一个看起来像这样的图:
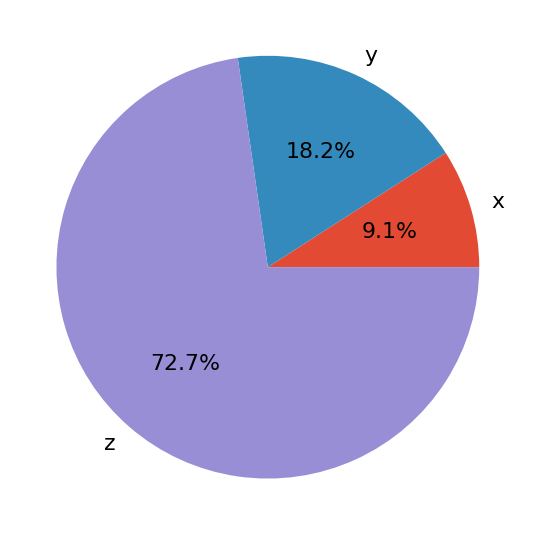
饼图显示x为圆圈的最小部分,第二大部分y,然后z是最大部分。百分比表示每个值与其总和相比的相对大小。
条形图
条形图还说明与给定标签或离散数值对应的数据。他们可以显示来自两个数据集的数据对。一组的项目是标签,而另一组的相应项目是它们的频率。或者,他们也可以显示与频率相关的错误。
条形图显示称为条形的平行矩形。每个条形对应一个标签,其高度与其标签的频率或相对频率成正比。让我们生成三个数据集,每个数据集有 21 个项目:
>>> x = np.arange(21)
>>> y = np.random.randint(21, size=21)
>>> err = np.random.randn(21)
您可以使用np.arange()来获得x,或连续整数从阵列0到20。您将使用它来表示标签。y是均匀分布的随机整数数组,也在0和之间20。这个数组将代表频率。err包含正态分布的浮点数,这是错误。这些值是可选的。
.bar()如果您想要垂直条或.barh()如果您想要水平条,您可以创建一个条形图:
fig, ax = plt.subplots())
ax.bar(x, y, yerr=err)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
此代码应生成下图:
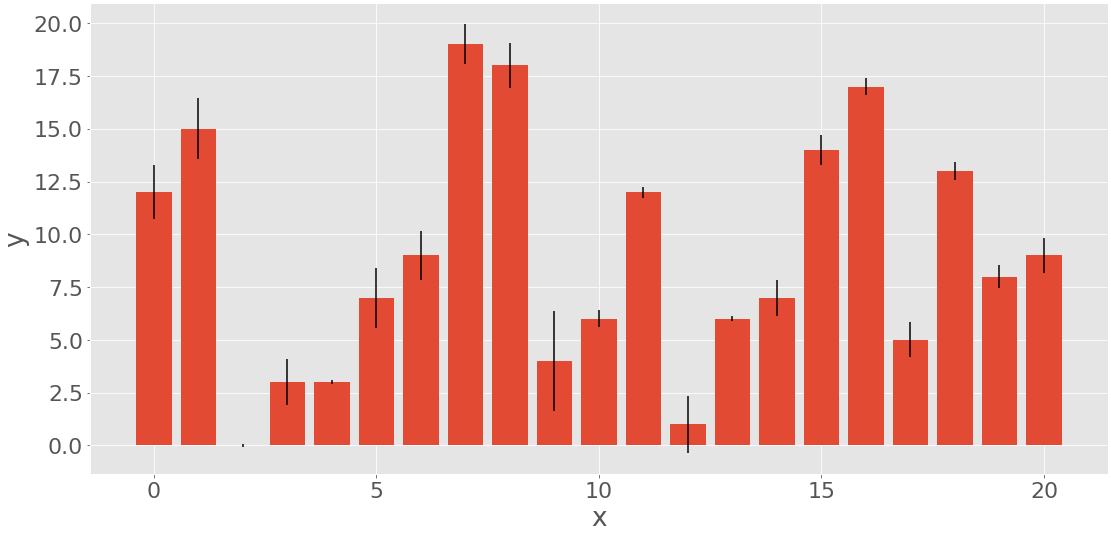
红条的高度对应于频率y,而黑线的长度表示误差err。如果你不希望包括错误,则省略该参数yerr的.bar()。
XY 图
的XY坐标图或散点图表示数据来自两个数据集的对。水平 x 轴显示集合中的值x,而垂直 y 轴显示集合中的相应值y。您可以选择包含回归线和相关系数。让我们生成两个数据集并执行线性回归scipy.stats.linregress():
>>> x = np.arange(21)
>>> y = 5 + 2 * x + 2 * np.random.randn(21)
>>> slope, intercept, r, *__ = scipy.stats.linregress(x, y)
>>> line = f'Regression line: y={intercept:.2f}+{slope:.2f}x, r={r:.2f}'
数据集x再次是具有从 0 到 20 的整数的数组。y计算为x带有一些随机噪声的失真的线性函数。
linregress返回几个值。您将需要回归线的slope和intercept以及相关系数r。然后你可以申请.plot()得到xy图:
fig, ax = plt.subplots()
ax.plot(x, y, linewidth=0, marker='s', label='Data points')
ax.plot(x, intercept + slope * x, label=line)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend(facecolor='white')
plt.show()
上面代码的结果是这个图:
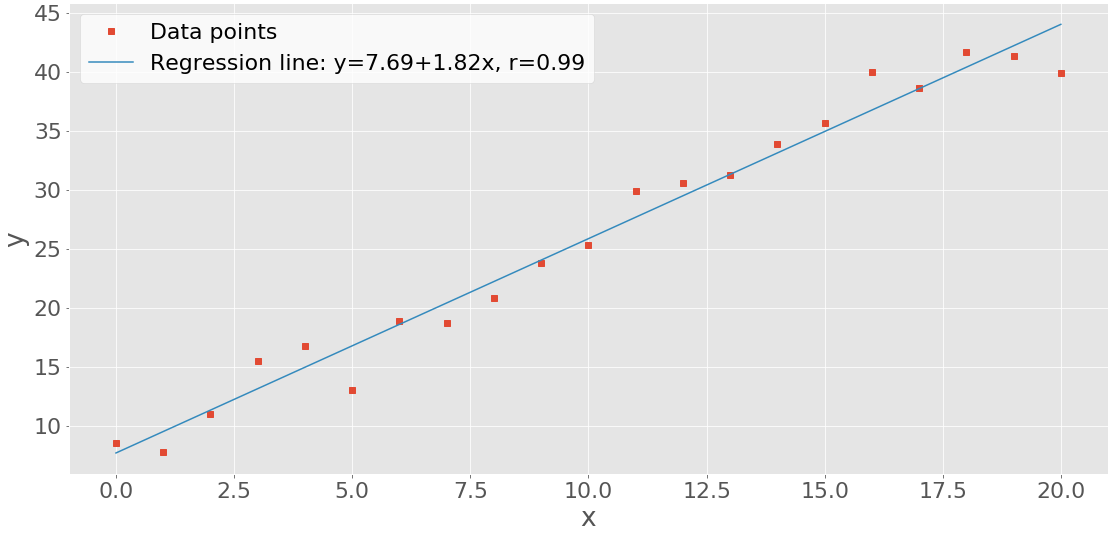
您可以看到数据点(xy 对)为红色方块,以及蓝色回归线。
热图
甲热图可用于直观显示的矩阵。颜色代表矩阵的数字或元素。热图对于说明协方差和相关矩阵特别有用。您可以为协方差矩阵创建热图.imshow():
matrix = np.cov(x, y).round(decimals=2)
fig, ax = plt.subplots()
ax.imshow(matrix)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, matrix[i, j], ha='center', va='center', color='w')
plt.show()
在这里,热图包含了标签'x',并'y'从协方差矩阵以及数字。你会得到这样的图:
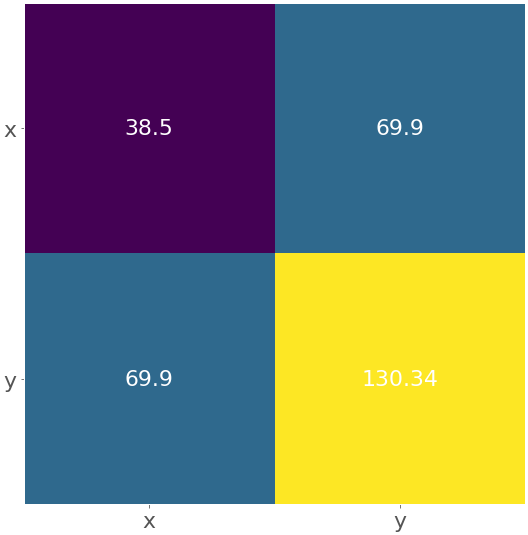
黄色字段代表矩阵中最大的元素130.34,而紫色字段对应于最小的元素38.5。中间的蓝色方块与值相关联69.9。
您可以按照相同的逻辑获取相关系数矩阵的热图:
matrix = np.corrcoef(x, y).round(decimals=2)
fig, ax = plt.subplots()
ax.imshow(matrix)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, matrix[i, j], ha='center', va='center', color='w')
plt.show()
结果如下图:
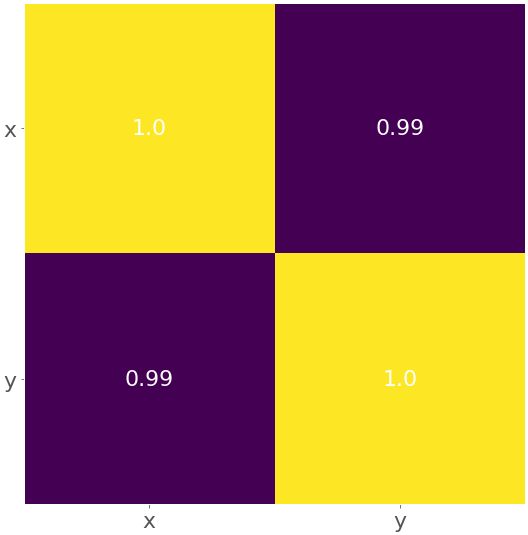
黄色表示值1.0,紫色表示0.99。
结论
您现在知道描述和汇总数据集的数量以及如何在 Python 中计算它们。使用纯 Python 代码可以获得描述性统计数据,但这很少是必要的。通常,您会使用一些专门为此目的创建的库:
- 将 Python
statistics用于最重要的 Python 统计函数。 - 使用 NumPy高效处理数组。
- 将 SciPy用于 NumPy 数组的其他 Python 统计例程。
- 使用 Pandas处理标记数据集。
- 使用 Matplotlib通过绘图、图表和直方图可视化数据。
在大数据和人工智能时代,您必须知道如何计算描述性统计量度。现在您已准备好深入了解数据科学和机器学习的世界!如果您有任何问题或意见,请将它们放在下面的评论部分。

- 点赞
- 收藏
- 关注作者
评论(0)