再探 同步与互斥


@[toc]
线程
先讲线程吧,目前我能接触到的应用场景还没有达到能够让进程之间出现互斥的状况。
锁种
解决互斥目前最常用的操作就是上锁了吧,来看看有多少锁。
无锁编程
不是什么时候都要靠上锁的。从根源出发,我们为什么需要上锁?因为线程在使用资源的过程中可能会出现冲突,对于这种会出现冲突的资源,还是锁住轮着用比较好。
但是有的资源其实很小,如果要在业务层面一锁一解锁也麻烦,于是就有了内核担保的原子变量进行原子操作。
#include<iostream>
#include<memory>
#include<thread>
#include<atomic> //其中包含很多原子操作
#include<vector>
using namespace std;
volatile atomic_bool isReady = false; //volatile:防止共享变量被缓存,导致线程跑来跑去
volatile atomic_int mycount = 0;
void task() {
while (!isReady) {
this_thread::yield(); //出让时间片,等待下一次调用
}
for (int i = 0; i < 100; i++) {
mycount++;
}
}
int main() {
vector<thread> tvec;
for (int i = 0; i < 10;i++) {
tvec.push_back(thread(task));
}
this_thread::sleep_for(chrono::seconds(3));
isReady = true;
for (thread& t : tvec) {
t.join();
}
cout << mycount << endl;
return 0;
}
看来下一篇要学习整理一下这些C++11新技术了,挺有意思的。
乐观锁

乐观锁是一种思想,具体实现是,表中有一个版本字段,第一次读的时候,获取到这个字段。处理完业务逻辑开始更新的时候,需要再次查看该字段的值是否和第一次的一样。如果一样更新,反之拒绝。之所以叫乐观,因为这个模式没有从数据库加锁。
==乐观锁比较适用于读多写少的情况(多读场景),悲观锁比较适用于写多读少的情况(多写场景)==。
设计一个乐观锁
class optimistic_lock(){
public:
static optimistic_lock& instance(){
static optimistic_lock op_lock;
return op_lock;
}
int get_vision(){
return vision;
}
void update_vision(){
++vision;
}
private:
int vision; //版本号
mutex mutex_;
optimistic_lock(){
vision = 0;
} //设置单例
}
外部操作时:
//获取数据,也获取vision
int vision = optimistic_lock.get_vision();
//数据回写时
bool update_data(){
if(vision == optimistic_lock.get_vision()){
mutex_.lock(); //想来想去,这里还是要上个锁
//如果不上锁,两个线程都还没写入,且都进入了这层判断,那岂不是都可以给vision加上1了
//但是如果这里上了锁,这个乐观锁还有什么乐观的意义?
//晓得了,只要不写,也没什么
if(vision == this->vision){ //双保险,参考懒汉模式的线程安全
//这里更新数据
optimistic_lock.update_vision();
mutex_.unlock();
return true;
}
else{
return false;
}
}
else{
return false;
}
};
悲观锁

悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改,所以悲观锁在持有数据的时候总会把资源 或者 数据 锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。悲观锁的实现往往依靠数据库本身的锁功能实现。
关于数据库里面的锁过两天写数据库的时候会安排上。
如何选择
在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。
1️⃣响应效率:如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败,不需要等待其他并发去释放锁。乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。
2️⃣冲突频率:如果冲突频率非常高,建议采用悲观锁,保证成功率。冲突频率大,选择乐观锁会需要多次重试才能成功,代价比较大。
3️⃣重试代价:如果重试代价大,建议采用悲观锁。悲观锁依赖数据库锁,效率低。更新失败的概率比较低。
自旋锁
自旋锁和互斥锁嘛,一直在用的,不过以前只是简单的叫它们:锁。原来人家有名字的啊。
wait() 晓得不?timewait()晓得不?
互斥锁:阻塞等待
自旋锁:等两下就去问一声:好了不?我很急啊!好了不?你快点啊。。。哈哈哈哈哈
自旋锁的原理比较简单,如果持有锁的线程能在短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就==避免了用户进程和内核切换的消耗==。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常==适用在时间比较短的情况下==。由于这个原因,操作系统的内核经常使用自旋锁。但是,==如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度==。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。适应性自旋锁意味着自旋时间不是固定的了,而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间。
互斥锁
概念性的东西就不多说了吧,基本就是人道主义出发设计的锁,稍微学过都都能想到这种锁。
互斥变量用pthread_mutex_t数据类型表示,在使用互斥变量以前,必须首先对它进行初始化,可以把它置为常量PTHREAD_MUTEX_INITIALIZER(只对静态分配的互斥量),也可以通过调用pthread_mutex_init函数进行初始化。==如果动态地分配互斥量(例如通过调用malloc函数),那么在释放内存前需要调用pthread_mutex_destroy==。
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
返回值:若成功则返回0,否则返回错误编号
要用默认的属性初始化互斥量,只需把attr设置为NULL。
对互斥量进行加锁,需要调用pthread_mutex_lock,如果互斥量已经上锁,调用线程将阻塞直到互斥量被解锁。对互斥量解锁,需要调用pthread_mutex_unlock。
#include <pthread.h>
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
返回值:若成功则返回0,否则返回错误编号
如果线程不希望被阻塞,它可以使用pthread_mutex_trylock尝试对互斥量进行加锁。如果调用pthread_mutex_trylock时互斥量处于未锁住状态,那么pthread_mutex_trylock将锁住互斥量,不会出现阻塞并返回0,否则pthread_mutex_trylock就会失败,不能锁住互斥量,而返回EBUSY。
读写锁
读写锁,我个人认为是在乐观锁的思想上进行了升级,并实例化出来了。
读写锁可以有三种状态:读模式下加锁状态,写模式下加锁状态,不加锁状态。一次只有一个线程可以占有写模式的读写锁,但是==多个线程可以同时占有读模式的读写锁==。
当读写锁是写加锁状态时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会被阻塞。当读写锁在读加锁状态时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是如果线程希望以==写模式==对此锁进行加锁,==它必须阻塞直到所有的线程释放读锁==。虽然读写锁的实现各不相同,但当读写锁处于读模式锁住状态时,如果有另外的线程试图以写模式加锁,读写锁通常会==阻塞随后的读模式锁请求==。这样可以避免读模式锁长期占用,而等待的写模式锁请求一直得不到满足。
读写锁非常适合于对数据结构读的次数远大于写的情况。当读写锁在写模式下时,它所保护的数据结构就可以被安全地修改,因为当前只有一个线程可以在写模式下拥有这个锁。当读写锁在读模式下时,只要线程获取了读模式下的读写锁,该锁所保护的数据结构可以被多个获得读模式锁的线程读取。
设计读写锁
class RDWR_lock{
public:
static RDWR_lock& instance(){
static RDWR_lock rdwr_lock;
return rdwr_lock;
}
void WR_lock(){
while(lock_flag != WR_ONLY){} //如果被加了写锁,那就阻塞在这边等着吧
++write_count;
}
void RD_lock(){
if(lock_flag == RD_ONLY){
mutex_.lock();
//可以去开始写了,写完记得解锁
}
else if(lock_flag == WR_ONLY){ //说明它是第一个进来等的
mutex_.lock();
lock_flag = RD_WAIT;
while(write_count){} //搁这儿等着
lock_flag = RD_ONLY;
//可以开始写了
//写完状态换回去,可以解锁了
}
else{
mutex_.lock(); //等着拿锁
//回去写吧
}
}
void unlock(){
switch lock_flag{
case WR_ONLY:
--write_count;
case RD_ONLY:
lock_flag = WR_ONLY;
mutex_.unlock();
default:
LOG_FATAL("unlock RDLR_lock failed in thread %p",getpid());
}
}
private:
RDWR_lock(){
write_count = 0;
lock_flag = WR_ONLY;
}
int write_count; //加读锁数量
enum flag = {
WR_ONLY = 1, //只读
RD_WAIT, //等待写锁
RD_ONLY //只写
}
int lock_flag;
mutex mutex_;
};
使用读写锁
与互斥量一样,读写锁在使用之前必须初始化,在释放它们底层的内存前必须销毁。
#include <pthread.h>
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t *restrict attr);
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
两者的返回值都是:若成功则返回0,否则返回错误编号
在释放读写锁占用的内存之前,需要调用pthread_rwlock_destroy做清理工作。如果pthread_rwlock_init为读写锁分配了资源,pthread_rwlock_destroy将释放这些资源。如果在调用pthread_rwlock_destroy之前就释放了读写锁占用的内存空间,那么分配给这个锁的资源就丢失了。
要在读模式下锁定读写锁,需要调用pthread_rwlock_rdlock;要在写模式下锁定读写锁,需要调用pthread_rwlock_wrlock。不管以何种方式锁住读写锁,都可以调用pthread_rwlock_unlock进行解锁。
#include <pthread.h>
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
所有的返回值都是:若成功则返回0,否则返回错误编号
在实现读写锁的时候可能会对共享模式下可获取的锁的数量进行限制,所以需要检查pthread_rwlock_rdlock的返回值。即使pthread_rwlock_wrlock和pthread_rwlock_unlock有错误的返回值,如果锁设计合理的话,也不需要检查其返回值。错误返回值的定义只是针对不正确地使用读写锁的情况,例如未经初始化的锁,或者试图获取已拥有的锁从而可能产生死锁这样的错误返回等。
提一嘴,读写锁也有那个时间机制的。
死锁
pthread_mutex_timedlock
在讲死锁之前先了解一个新的函数:
pthread_mutex_timedlock函数(第三版新增)
当请求一个已经加锁的互斥量时,如果我们想要限定线程阻塞的时间(时间到了就不再阻塞等待),这时需要使用pthread_mutex_timedlock函数。pthread_mutex_timedlock函数类似于pthread_mutex_lock,只不过一旦设置的超时值到达,pthread_mutex_timedlock函数会返回错误代码ETIMEDOUT,线程不再阻塞等待。
#include <pthread.h>
#include <time.h>
int pthread_mutex_timedlock( pthread_mutex_t *restrict mutex,
const struct timespec *restrict tsptr );
返回值:若成功则返回0,失败则返回错误代码
超时值指定了我们要等待的时间,它使用绝对时间(而不是相对时间:我们指定线程将一直阻塞等待直到时刻X,而不是说我们将要阻塞X秒钟。)。该时间值用timespec结构表示:秒和纳秒。
不然我还真不知道要怎么手动破开一个死锁状态。
死锁产生
就有时候吧,不是咱想死锁的。
在多道程序系统中,若对资源的管理、分配和使用不当,也会产生一种危险,即在一定条件下会导致系统发生一种随机性错误——死锁。
多个进程所共享的资源不足,引起它们对资源的竞争而产生死锁
-竞争可剥夺和非剥夺性资源
-竞争非剥夺性资源
进程运行过程中,请求和释放资源的顺序不当,而导致进程死锁
-进程推进顺序合法
-进程推进顺序非法
再有就是我们自己忘记释放锁了,这个是我们可以操控的。
死锁的避免与解决的基本方法
-
预防死锁
通过设置某些限制条件,以破坏产生死锁的四个必要条件中的一个或几个,来防止发生死锁。 -
避免死锁
在资源的动态分配过程中,使用某种方法去防止系统进入不安全状态,从而避免了死锁的发生。 -
检测死锁
检测死锁方法允许系统运行过程中发生死锁。但通过系统所设置的检测机构,可以及时检测出死锁的发生,并精确地确定与死锁有关的进程和资源,然后采取适当措施,从系统中消除所发生的死锁 -
解除死锁
解除死锁是与检测死锁相配套的一种设施,用于将进程从死锁状态下解脱出来
lock_guard && unique_lock
属于C++11新特性,这里先提一嘴,回头专门写一篇C++11新特性的。
lock_guard
lock_guard是一个互斥量包装程序,它提供了一种方便的RAII(Resource acquisition is initialization )风格的机制来在作用域块的持续时间内拥有一个互斥量。
创建lock_guard对象时,它将尝试获取提供给它的互斥锁的所有权。当控制流离开lock_guard对象的作用域时,lock_guard析构并释放互斥量。
它的特点如下:
创建即加锁,作用域结束自动析构并解锁,无需手工解锁
不能中途解锁,必须等作用域结束才解锁
不能复制
#include <thread>
#include <mutex>
#include <iostream>
int g_i = 0;
std::mutex g_i_mutex; // protects g_i
void safe_increment()
{
const std::lock_guard<std::mutex> lock(g_i_mutex);
++g_i;
std::cout << std::this_thread::get_id() << ": " << g_i << '\n';
// g_i_mutex is automatically released when lock
// goes out of scope
}
int main()
{
std::cout << "main: " << g_i << '\n';
std::thread t1(safe_increment);
std::thread t2(safe_increment);
t1.join();
t2.join();
std::cout << "main: " << g_i << '\n';
}
unique_lock
要玩的转这个,那真的要了解C++11新特性了,因为这里面涉及了智能指针和绑定器。
unique_lock是一个通用的互斥量锁定包装器,它允许延迟锁定,限时深度锁定,递归锁定,锁定所有权的转移以及与条件变量一起使用。
简单地讲,unique_lock 是 lock_guard 的升级加强版,它具有 lock_guard 的所有功能,同时又具有其他很多方法,使用起来更强灵活方便,能够应对更复杂的锁定需要。
特点如下:
创建时可以不锁定(通过指定第二个参数为std::defer_lock),而在需要时再锁定
可以随时加锁解锁
作用域规则同 lock_grard,析构时自动释放锁
不可复制,可移动
条件变量需要该类型的锁作为参数(此时必须使用unique_lock)
#include <mutex>
#include <thread>
#include <chrono>
struct Box {
explicit Box(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void transfer(Box &from, Box &to, int num)
{
// don't actually take the locks yet
std::unique_lock<std::mutex> lock1(from.m, std::defer_lock);
std::unique_lock<std::mutex> lock2(to.m, std::defer_lock);
// lock both unique_locks without deadlock
std::lock(lock1, lock2);
from.num_things -= num;
to.num_things += num;
// 'from.m' and 'to.m' mutexes unlocked in 'unique_lock' dtors
}
int main()
{
Box acc1(100);
Box acc2(50);
std::thread t1(transfer, std::ref(acc1), std::ref(acc2), 10);
std::thread t2(transfer, std::ref(acc2), std::ref(acc1), 5);
t1.join();
t2.join();
}
条件变量
- 条件变量提供了另一种同步的方式。互斥量通过控制对数据的访问实现了同步,而条件变量允许根据实际的数据值来实现同步。
- 没有条件变量,程序员就必须使用线程去轮询(可能在临界区),查看条件是否满足。这样比较消耗资源,因为线程连续繁忙工作。条件变量是一种可以实现这种轮询的方式。
- 条件变量往往和互斥一起使用
使用条件变量的代表性顺序如下:

条件变量原语
//初始化条件变量:
//本人还是喜欢静态初始化,省事儿
pthread_cont_t cont = PTHREAD_COND_INITIALIZER;
//好,再看看动态初始化
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);
//参数释义:cond:用于接收初始化成功管道条件变量
//attr:通常为NULL,且被忽略
//有初始化那肯定得有销毁
int pthread_cond_destroy(pthread_cond_t *cond);
//既然说条件变量是用来等待的,那就更要看看这等待的特殊之处了
int pthread_cond_wait(pthread_cond_t *cond,pthread_mutex_t *mutex); //无条件等待
int pthread_cond_timedwait(pthread_cond_t *cond,pthread_mutex_t mytex,const struct timespec *abstime); //计时等待
//好,加入等待唤醒大军了,那得看看怎么去唤醒了
int pthread_cond_signal(pthread_cond_t *cptr); //唤醒一个等待该条件的线程。存在多个线程是按照其队列入队顺序唤醒其中一个
int pthread_cond_broadcast(pthread_cond_t * cptr); //广播,唤醒所哟与等待线程
条件变量与互斥锁
在服务器编程中常用的线程池,多个线程会操作同一个任务队列,一旦发现任务队列中有新的任务,子线程将取出任务;这里因为是多线程操作,必然会涉及到用互斥锁保护任务队列的情况(否则其中一个线程操作了任务队列,取出线程到一半时,线程切换又取出相同任务)。但是互斥锁一个明显的缺点是它只有两种状态:锁定和非锁定。设想,每个线程为了获取新的任务不断得进行这样的操作:锁定任务队列,检查任务队列是否有新的任务,取得新的任务(有新的任务)或不做任何操作(无新的任务),释放锁,这将是很消耗资源的。
而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起配合使用。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。一般说来,条件变量被用来进行线程间的同步。对应于线程池的场景,我们可以让线程处于等待状态,当主线程将新的任务放入工作队列时,发出通知(其中一个或多个),得到通知的线程重新获得锁,取得任务,执行相关操作。
注意事项
(1)必须在互斥锁的保护下唤醒,否则唤醒可能发生在锁定条件变量之前,照成死锁。
(2)唤醒阻塞在条件变量上的所有线程的顺序由调度策略决定
(3)如果没有线程被阻塞在调度队列上,那么唤醒将没有作用。
(4)以前不懂事儿,就喜欢广播。由于pthread_cond_broadcast函数唤醒所有阻塞在某个条件变量上的线程,这些线程被唤醒后将再次竞争相应的互斥锁,所以必须小心使用pthread_cond_broadcast函数。
虚假唤醒与唤醒丢失
⑴虚假唤醒
在多核处理器下,pthread_cond_signal可能会激活多于一个线程(阻塞在条件变量上的线程)。结果是,当一个线程调用pthread_cond_signal()后,多个调用pthread_cond_wait()或pthread_cond_timedwait()的线程返回。这种效应成为”虚假唤醒”(spurious wakeup)
Linux帮助里面有
为什么不去修正,性价比不高嘛。
所以通常的标准解决办法是这样的(妙!):
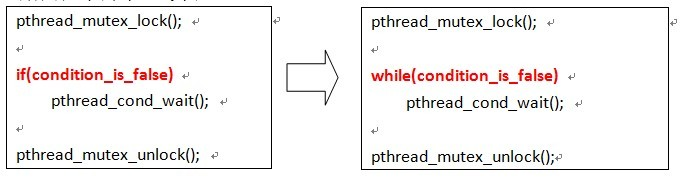
⑵唤醒丢失
无论哪种等待方式,都必须和一个互斥量配合,以防止多个线程来打扰。
互斥锁必须是普通锁或适应锁,并且在进入pthread_cond_wait之前必须由本线程加锁。
在更新等待队列前,mutex必须保持锁定状态. 在线程进入挂起,进入等待前,解锁。(好绕啊,我已经尽力断句了)
在条件满足并离开pthread_cond_wait前,上锁。以恢复它进入cont_wait之前的状态。
为什么等待会被上锁?
以免出现唤醒丢失问题。
这里有个大神解释要不要看:https://stackoverflow.com/questions/4544234/calling-pthread-cond-signal-without-locking-mutex
做事做全套,源码也给放这儿了:https://code.woboq.org/userspace/glibc/nptl/pthread_cond_wait.c.html
在放些咱能看懂的中文解释:将线程加入唤醒队列后方可解锁。保证了线程在陷入wait后至被加入唤醒队列这段时间内是原子的。
但这种原子性依赖一个前提条件:唤醒者在调用pthread_cond_broadcast或pthread_cond_signal唤醒等待者之前也必须对相同的mutex加锁。
满足上述条件后,如果一个等待事件A发生在唤醒事件B之前,那么A也同样在B之前获得了mutex,那A在被加入唤醒队列之前B都无法进入唤醒调用,因此保证了B一定能够唤醒A;试想,如果A、B之间没有mutex来同步,虽然B在A之后发生,但是可能B唤醒时A尚未被加入到唤醒队列,这便是所谓的唤醒丢失。
在线程未获得相应的互斥锁时调用pthread_cond_signal或pthread_cond_broadcast函数可能会引起唤醒丢失问题。
唤醒丢失往往会在下面的情况下发生:
一个线程调用pthread_cond_signal或pthread_cond_broadcast函数;
另一个线程正处在测试条件变量和调用pthread_cond_wait函数之间;
没有线程正在处在阻塞等待的状态下。
使用条件变量
//例子演示了使用Pthreads条件变量的几个函数。主程序创建了三个线程,两个线程工作,根系“count”变量。第三个线程等待count变量值达到指定的值。
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 3
#define TCOUNT 10
#define COUNT_LIMIT 12
int count = 0;
int thread_ids[3] = {0,1,2};
pthread_mutex_t count_mutex;
pthread_cond_t count_threshold_cv;
void *inc_count(void *idp)
{
int j,i;
double result=0.0;
int *my_id = idp;
for(i=0; i<TCOUNT; i++) {
pthread_mutex_lock(&count_mutex);
count++;
/*
Check the value of count and signal waiting thread when condition is
reached. Note that this occurs while mutex is locked.
*/
if (count == COUNT_LIMIT) {
pthread_cond_signal(&count_threshold_cv);
printf("inc_count(): thread %d, count = %d Threshold reached./n",*my_id, count);
}
printf("inc_count(): thread %d, count = %d, unlocking mutex/n",*my_id, count);
pthread_mutex_unlock(&count_mutex);
/* Do some work so threads can alternate on mutex lock */
for (j=0; j<1000; j++)
result = result + (double)random();
}
pthread_exit(NULL);
}
void *watch_count(void *idp)
{
int *my_id = idp;
printf("Starting watch_count(): thread %d/n", *my_id);
/*
Lock mutex and wait for signal. Note that the pthread_cond_wait
routine will automatically and atomically unlock mutex while it waits.
Also, note that if COUNT_LIMIT is reached before this routine is run by
the waiting thread, the loop will be skipped to prevent pthread_cond_wait \
from never returning.
*/
pthread_mutex_lock(&count_mutex);
if (count<COUNT_LIMIT) {
pthread_cond_wait(&count_threshold_cv, &count_mutex);
printf("watch_count(): thread %d Condition signal received./n", *my_id);
}
pthread_mutex_unlock(&count_mutex);
pthread_exit(NULL);
}
int main(int argc, char *argv[])
{
int i, rc;
pthread_t threads[3];
pthread_attr_t attr;
/* Initialize mutex and condition variable objects */
pthread_mutex_init(&count_mutex, NULL);
pthread_cond_init (&count_threshold_cv, NULL);
/* For portability, explicitly create threads in a joinable state */
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
pthread_create(&threads[0], &attr, inc_count, (void *)&thread_ids[0]);
pthread_create(&threads[1], &attr, inc_count, (void *)&thread_ids[1]);
pthread_create(&threads[2], &attr, watch_count, (void *)&thread_ids[2]);
/* Wait for all threads to complete */
for (i=0; i<NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
printf ("Main(): Waited on %d threads. Done./n", NUM_THREADS);
/* Clean up and exit */
pthread_attr_destroy(&attr);
pthread_mutex_destroy(&count_mutex);
pthread_cond_destroy(&count_threshold_cv);
pthread_exit(NULL);
}
信号量
咳咳,先来几个大神的意见:
我的建议是不要使用 semaphore。https://www.zhihu.com/question/47411729 陈硕
陈硕大佬的话一般都这么简短,下面有一位大神体谅我们比较菜,给出了释义:
最近你的回答都要简略啦!我来帮你补充一下。1)虽然,从逻辑上可以基于信号量来实现任何锁,但信号量并不是一个“好用”的东西。2)计算机实现的最小粒度的同步机制并不是信号量,而是spinlock(自旋锁)一类的东西,因此,与其说spinlock可以基于信号量来实现,不如说,信号量本身就是靠spinlock实现的。3)信号量有很多种实现,但都绕不开操作系统层面的支持,这样一来,信号量的开销就远高于spinlock这样的cpu原生实现的锁。4)在多核环境下,用信号量来实现数据同步可能会造成一些问题,需要编程者掌握较高的并发编程知识才能避免。(涉及到CPU乱序执行、内存乱序读取等问题)5)以Java举例,Java的sync实质上是锁+内存屏障(用来避免乱序执行和乱序读取),因此,不理解CPU内存模型的初学者容易认为sync仅仅只是一个锁,用信号量就能模拟。6)综上所述,信号量只能模拟锁,但不能模拟同步机制,同步机制需要锁+内存屏障,现成的锁往往自带内存屏障,所以内存屏障对于编程者而言是透明的,而许多编程者不知道这一点,试图用信号量模拟锁,这样一来程序就会fail。
一个信号量 S 是个整型变量,它除了初始化外只能通过两个标准原子操作:wait () 和 signal() 来访问:
操作 wait() 最初称为 P(荷兰语proberen,测试);
操作 signal() 最初称为 V(荷兰语verhogen,增加)
对信号量有4种操作(#include<semaphore.h>):
1. 初始化(initialize),也叫做建立(create) int sem_init(sem_t *sem, int pshared, unsigned int value);
2. 等信号(wait),也可叫做挂起(suspend)int sem_wait(sem_t *sem);
3. 给信号(signal)或发信号(post) int sem_post(sem_t *sem);
4.清理(destroy) int sem_destory(sem_t *sem);

- 点赞
- 收藏
- 关注作者
评论(0)