⑥⭐全网首发☀️数据有道之数据库技术❤️干货大全【持续更新】❗❗❗

目录
6.1 一般数据查询功能扩展
考点1 使用TOP限制结果集
(1)适用情况
当使用SELECT语句进行查询时,有时只希望列出结果集中的前几行数据,而不是全部数据,这时就可以使用TOP谓词来限制输出的结果。
(2)语法格式
TOP n [percent] [WITH TIES]
其中,n为非负整数。
①TOP n:取查询结果的前n行数据;
②TOP n percent:取查询结果的前n%行数据;
③WITH TIES:表示包括最后一行取值并列的结果。
TOP谓词写在SELECT单词的后边(如果有DISTINCT的话,则TOP写在DISTINCT的后边)、查询列表的前边。
注意:在使用TOP谓词时,应该与ORDER BY子句一起使用,这样的前几名才有意义。当使用WITH TIES选项时,则要求必须使用ORDER BY子句。
目前MySQL并不支持top n的语法,limit n 需要的更加的频繁
考点2 使用CASE函数
(1)适用情况
可以在查询语句中使用CASE函数,以达到分情况显示不同类型的数据的目的。CASE函数是一种多分支表达式,它计算条件列表并返回多个可能的结果表达式中的一个。
(2)类型
简单CASE函数和搜索CASE函数。
(3)简单CASE函数
①语法格式
-
CASE测试表达式
-
-
WHEN简单表达式1 THEN结果表达式1
-
-
WHEN简单表达式2 THEN结果表达式2
-
-
…
-
-
WHEN简单表达式n THEN结果表达式n
-
-
[EISE结果表达式n+1]
-
-
END
②执行过程
a.计算测试表达式,然后按从上到下的顺序对每个WHEN子句的简单表达式进行计算。
b.如果某个简单表达式的值与测试表达式的值相匹配,则返回与第一个取值为True的WHEN对应的结果表达式的值。
c.如果所有的简单表达式的值都不与测试表达式的值相匹配,则当指定了ELSE子句时,将返回ELSE子句中指定的结果表达式的值;若没有指定ELSE子句,则返回NULL值。
(4)搜索CASE函数
①语法格式
搜索CASE函数的各个WHEN子句的布尔表达式可以使用比较运算符,也可以使用逻辑运算符。
②执行过程
搜索CASE函数的执行过程同简单CASE函数。
③例题
【例1】查询每种商品的销售次数,如果销售次数超过10次,则显示“热门商品”,如果销售次数在5~10次之间,则显示“一般商品”,如果销售次数低于5次,则显示“难销商品”,如果商品没有被销售过,则显示“滞销商品”。
分析:由于要查询的是全部商品的销售情况,包括有销售记录的和没有销售记录的,因此,应该用外连接实现。另外,在统计每种商品的销售次数时,应该使用COUNT(列名)函数,不能使用COUNT(*)函数,而且应该对外连接后的销售记录表中的商品编号列进行统计。
【真题演练】
设SC表中记录成绩的列为:Grade,类型为int。若在查询成绩时,希望将成绩按“优”、“良”、“中”、“及格”和“不及格”形式显示,正确的Case函数是( )。
A.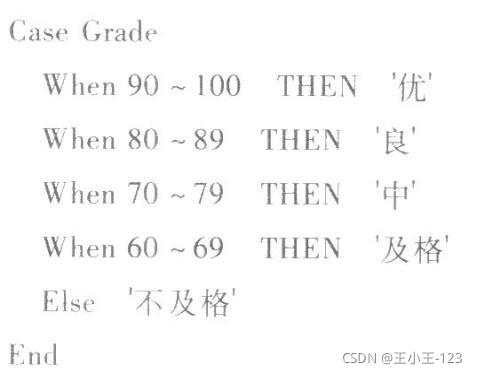
B.
C.
D.
【答案】C
考点3 将查询结果保存到新表中
(1)适用情况
当使用SELECT语句查询数据时,产生的结果是保存在内存中的。如果希望将查询结果永久保存下来,比如保存在一个表中,则可以通过在SELECT语句中使用INTO子句实现。
(2)INTO子句的语法格式
SELECT查询列表序列 INTO<新表名>
FROM数据源
… - -其他行过滤、分组等子句
其中“新表名”是要存放查询结果的表名。这个语句将查询的结果保存在“新表名”所指定的表中。实际上这个语句包含如下三个功能:
①根据查询语句列出的列以及其类型创建一个新表;
②执行查询语句;
③将查询的结果插入到新表中。
(3)INTO语句创建新表的分类
用INTO子句创建的新表可以是永久表(在执行这个语句时所使用的数据库中被物理的创建,并且是存储在磁盘上的表),也可以是临时表(在tempdb数据库中创建此表,其生存期是有限的)。临时表又根据其使用范围分为局部临时表和全局临时表两种。
①局部临时表
局部临时表通过在表名前加一个“#”来标识,比如:#T1,表示“#T1”是一个局部临时表。局部临时表的生存期与创建此局部临时表的用户的连接生存期相同,它只能在创建此局部临时表的当前连接中使用。
②全局临时表
全局临时表通过在表名前加两个“#”来标识,比如:##T1,表示“##T1”是一个全局临时表。全局临时表的生存期与创建全局临时表的用户的连接生存期相同,并且在生存期内可以被所有的连接使用。
可以对局部临时表和全局临时表中的数据进行查询,其方法同永久表一样。
6.2 查询结果的并、交、差运算
考点1 并运算
(1)概述
并运算可将两个或多个查询语句的结果集合并为一个结果集,这个运算可以使用UNION运算符实现。UNION是一个特殊的运算符,通过它可以实现让两个或更多的查询产生单一的结果集。
(2)UNION与JOIN的区别
UNION操作与JOIN连接操作不同,UNION更像是将一个查询结果追加到另一个查询结果中(虽然各数据库管理系统对UNION操作略有不同,但基本思想是一样的)。JOIN操作是水平地合并数据(添加更多的列),而UNION是垂直地合并数据(添加更多的行)。
(3)语法格式
SELECT语句1
UNION[ALL]
SELECT语句2
UNION[ALL]
…
SELECT语句n
其中:ALL表示在结果集中包含所有查询语句产生的全部记录,包括重复的记录。如果没有指定ALL,则系统默认是删除合并后结果集中的重复记录。
(4)注意事项
①所有要进行UNION操作的查询,其SELECT列表中列的个数必须相同,而且对应列的语义应该相同。
②各查询语句中每个列的数据类型必须与其他查询中对应列的数据类型是隐式兼容的,即只要它们能进行隐式转换即可。例如,如果第一个查询中第二个列的数据类型是char(20),而第二个查询中第二个列的数据类型是varchar(40)是可以的。
③合并后的结果采用第一个SELECT语句的列标题。
④如果要对查询的结果进行排序,则ORDER BY子句应该写在最后一个查询语句之后,且排序的依据列应该是第一个查询语句中出现的列名。
【真题演练】
下述语句的功能是将两个查询结果合并为一个结果,其中正确的是( )。[2014年3月真题]
A.
B.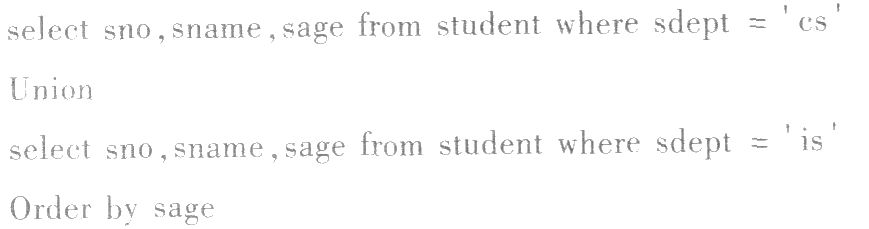
C.
D.
【答案】B
考点2 交运算
(1)概述
交运算将返回同时在两个集合中出现的记录,即返回两个查询结果集中各个列的值均相同的记录,并用这些记录构成交运算的结果。实现交运算的运算符为INTERSECT。
(2)语法格式
SELECT语句1
INTERSECT
SELECT语句2
INTERSECT
…
SELECT语句n
INTERSECT运算对各查询语句的要求同UNION运算。
考点3 差运算
(1)概述
差运算将返回在第一个集合中有但第二个集合中没有的数据。实现差运算的SQL运算符为EXCEPT。
(2)语法格式
SELECT语句1
EXCEPT
SELECT语句2
EXCEPT
…
SELECT语句n
EXCEPT运算对各查询语句的要求同UNION运算。
6.3 相关子查询
考点1 概 述
(1)定义
在SQL语言中,一个SELECT-FROM-WHERE语句称为一个查询块。如果一个SELECT语句是嵌套在一个SELECT、INSERT、UPDATE或DELETE语句中,则称为子查询或内层查询,包含子查询的语句称为主查询或外层查询。
(2)子查询与外层查询的关系
一个子查询也可以嵌套在另外一个子查询中。为了与外层查询有所区别,总是把子查询写在圆括号中。与外层查询类似,子查询语句中也必须包含SELECT子句和FROM子句,并可以根据需要选择WHERE子句、GROUP BY子句和HAVING子句。
考点2 语法格式
·WHERE表达式 [NOT] IN(子查询)
·WHERE表达式 比较运算符(子查询)
·WHERE [NOT] EXISTS(子查询)
通常,子查询一般用在外层查询的WHERE子句或HAVING子句中,与比较运算符或逻辑运算符一起构成查询条件。对于返回结果为单值的子查询语句,可以出现在任何允许使用表达式的地方。
考点3 用 途
(1)使用子查询进行基于集合的测试
①使用子查询进行基于集合的测试时,通过运算符IN和NOT IN,将一个表达式的值与子查询返回的结果集进行比较。
②形式为:
WHERE表达式 [NOT] IN(子查询)
这种形式的子查询的语句是分步骤实现的,即先执行子查询,然后在子查询的结果基础上再执行外层查询。子查询返回的结果实际上就是一个集合,外层查询就是在这个集合上使用IN运算符进行比较。
(2)使用子查询进行比较测试
①使用子查询进行比较测试时,通过比较运算符(=、<>、<、>、<=、>=),将一个表达式的值与子查询返回的单值进行比较。如果比较运算的结果为True,则比较测试返回True;如果比较运算的结果为False,则比较测试返回False。
②形式为:
WHERE表达式 比较运算符(子查询)
使用子查询进行的比较测试要求子查询语句必须是返回单值的查询语句。
③注意:由于聚合函数不能出现在WHERE子句中,因此,当一个列的值与一个聚合函数的结果进行比较时,必须用子查询先得到聚合函数的结果,然后在此结果基础之上再执行外层查询的比较。
子查询的查询条件不依赖于外层查询,称这样的子查询为不相关子查询或嵌套子查询。
(3)使用子查询进行存在性测试
使用子查询进行存在性测试时,通常使用EXISTS谓词,其形式为:
WHERE [NOT] EXISTS(子查询)
带EXISTS谓词的子查询不返回查询的结果,只产生逻辑真值和逻辑假值。
①EXISTS的含义是:当子查询中有满足条件的数据时,EXISTS返回真值,否则返回假值。
②NOT EXISTS的含义是:当子查询中有满足条件的数据时,NOT EXISTS返回假值,当子查询中不存在满足条件的数据时,NOT EXISTS返回真值。
6.4 其他形式的子查询
考点1 替代表达式的子查询
替代表达式的子查询是指在SELECT语句的选择列表中嵌入一个只返回一个标量值的 SELECT语句,这个查询语句通常都是通过一个聚合函数来返回一个单值。
考点2 派生表
(1)概述
派生表(有时也称为内联视图)是将子查询作为一个表来处理,这个由子查询产生的新表就被称为“派生表”,可在查询语句中用派生表来建立与其他表的连接关系,在生成派生表后,在查询语句中对派生表的操作与普通表一样。
(2)优点
使用派生表可以简化查询,从而避免使用临时表,而且相比手动生成临时表的方法性能更优越。
(3)出现
派生表与其他表一样出现在查询语句的FROM子句中。例如:
这里的temp就是派生表。
6.5 其他一些查询功能
考点1 开窗函数
(1)概述
在SQL Server中,一组行被称为一个窗口,开窗函数是指可以用于“分区”或“分组”计算的函数。这些函数结合OVER子句对组内的数据进行编号,并进行求和、计算平均值等统计。从这个角度来说,SUM、AVG以及ROW_NUMBER(对数据进行编号的函数)等都可以称为开窗函数。
开窗函数可以分别应用于每个分区,把每个分区看成是一个窗口,并为每个分区进行计算。开窗函数必须放在OVER子句前边。
(2)分类
排名开窗函数和聚合开窗函数。
(3)将OVER子句与聚合函数结合使用
①使用方法与语法格式
OVER子句用于确定在应用关联的开窗函数之前对行集的分区和排序。
将OVER子句与聚合函数结合使用的语法格式为:
②参数说明
a.PARTITION BY:将结果集划分为多个分区。开窗函数分别应用于每个分区,并为每个分区计算函数值。
b.value_expression:指定对行集进行分区所依据的列,该列必须是在FROM子句中生成的列,而且不能引用选择列表中的表达式或别名。value_expression可以是列表达式、替代表达式的子查询、标量函数或用户定义的变量。
注意:可以在单个查询中使用多个开窗函数,每个函数的OVER子句在分区和排序上可以不同。
(4)将OVER子句与排名函数一起使用
排名函数为分区中的每一行返回一个排名值。根据所用函数的不同,某些行可能与其他行具有相同的排名值。排名函数具有不确定性。
SQL Server提供了四个排名函数:RANK、DENSE_RANK、NTILE和ROW_NUMBER。下面分别介绍这些排名函数。
①RANK()函数
a.语法格式
b.参数含义
<partition_by_clause>:将FROM子句生成的结果集划分成排名函数适用的分区。
<order_by_clause>:指定应用于分区中的行时所基于的排序依据列。
RANK()函数返回结果集中每行数据在每个分区内的排名。每个分区内行的排名从1开始。
注意:如果排序时有值相同的行,则这些值相同的行具有相同的排名。例如,如果两位销售人员有相同的年销售量,则他们将并列第一,并且下一个销售人员的排名是第三。因此,RANK()函数并不一定返回连续整数。
【例2】查询订单号、产品号、订购数量以及每个产品在每个订单中的订购数量排名。
分析:该查询需要用订单号进行分区,用订购数量作为排名依据列。
②DENSE_RANK()函数
DENSE_RANK()函数与RANK()函数的作用基本一样,使用方法也一样,唯一的区别是DENSE_RANK()函数的排名中间没有任何间断,即该函数返回的是一个连续的整数值。
【例3】将【例2】的查询改为用DENSE_RANK()函数实现。
③NTILE()
a.作用
将有序分区中的行划分到指定数目的组中,每个组有一个编号,编号从1开始。对于每一行,NTILE()函数将返回此行所属的组的编号。
b.语法格式
各参数含义同RANK()函数。
考点2 公用表表达式
(1)定义
将查询语句产生的结果集指定一个临时命名的名字,这些命名的结果集就称为公用表表达式(CTE)。命名后的公用表表达式后可以在SELECT、INSERT、UPDATE、DELETE等语句中被多次引用。公用表表达式还可以包括对自身的引用,这种表达式称为递归公用表表达式。
(2)优点
①可以定义递归公用表表达式。
②使数据操作代码更加清晰简洁。
③GROUP BY子句可以直接作用在子查询所得的标量列上。
④可以在一个语句中多次引用公用表表达式。
(3)语法格式
(4)参数说明
①expression_name:公用表表达式的标识符。expression_name必须与在同一WITH< common_table_expression>子句中定义的任何其他公用表表达式的名称不同,但该名可以与基本表或视图名相同。在查询中对expression_name的任何引用都会使用公用表表达式。
②column_nanle:在公用表表达式中指定列名。在一个CTE定义中不允许出现重名的列名,
③SELECT语句:指定一个用其结果集填充到公用表表达式的SELECT语句。
每文一语
闲下来,才能惰性的灵魂
文章来源: wxw-123.blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:wxw-123.blog.csdn.net/article/details/120105725

- 点赞
- 收藏
- 关注作者
评论(0)