【NLP】⚠️学不会打我! 半小时学会基本操作 1⚠️ 分词

【摘要】 无
概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

分词器 jieba
jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viterbi 算法.

安装
pip install jieba
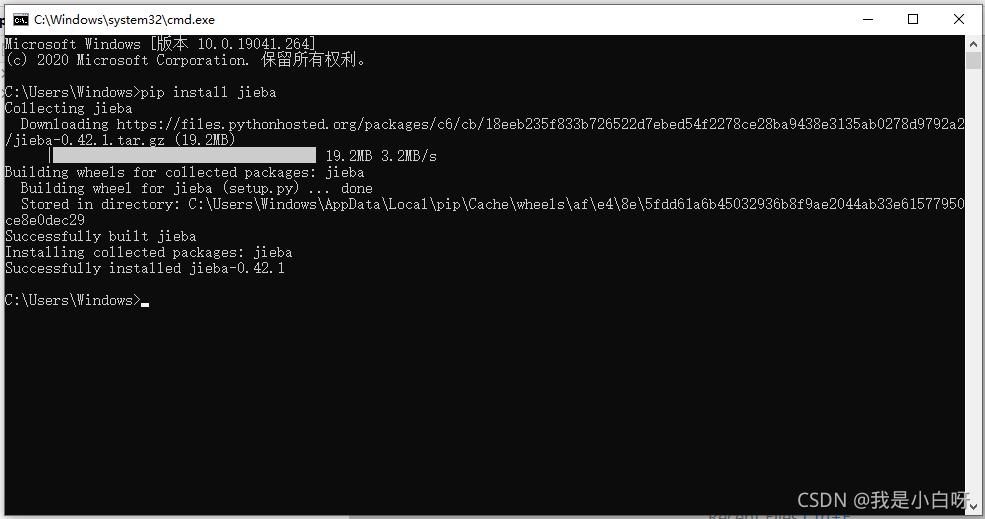
查看是否安装成功:
import jieba
print(jieba.__version__)
输出结果:
0.42.1
精确分词
精确分词: 精确模式试图将句子最精确地切开, 精确分词也是默认分词.

格式:
jieba.cut(content, cut_all=False)
参数:
- content: 需要分词的内容
- cut_all: 如果为 True 则为全模式, False 为精确模式
例子:
import jieba
# 定义文本
content = "自然语言处理是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。"
# 精确分词
seg = jieba.cut(content, cut_all=False)
# 调试输出
print([word for word in seg])
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
Loading model cost 0.984 seconds.
Prefix dict has been built successfully.
['自然语言', '处理', '是', '人工智能', '和', '语言学', '领域', '的', '分支', '学科', '。', '此', '领域', '探讨', '如何', '处理', '及', '运用', '自然语言', ';', '自然语言', '处理', '包括', '多方面', '和', '步骤', ',', '基本', '有', '认知', '、', '理解', '、', '生成', '等', '部分', '。']
全模式
全模式分词: 全模式会把句子中所有可能是词语的都扫出来. 速度非常快, 但不能解决歧义问题.
例子:
C:\Users\Windows\Anaconda3\pythonw.exe "C:/Users/Windows/Desktop/project/NLP 基础/结巴.py"
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
['自然', '自然语言', '语言', '处理', '是', '人工', '人工智能', '智能', '和', '语言', '语言学', '领域', '的', '分支', '学科', '。', '此', '领域', '探讨', '如何', '何处', '处理', '及', '运用', '自然', '自然语言', '语言', ';', '自然', '自然语言', '语言', '处理', '包括', '多方', '多方面', '方面', '和', '步骤', ',', '基本', '有', '认知', '、', '理解', '、', '生成', '等', '部分', '。']
Loading model cost 0.999 seconds.
Prefix dict has been built successfully.
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
['自然', '自然语言', '语言', '处理', '是', '人工', '人工智能', '智能', '和', '语言', '语言学', '领域', '的', '分支', '学科', '。', '此', '领域', '探讨', '如何', '何处', '处理', '及', '运用', '自然', '自然语言', '语言', ';', '自然', '自然语言', '语言', '处理', '包括', '多方', '多方面', '方面', '和', '步骤', ',', '基本', '有', '认知', '、', '理解', '、', '生成', '等', '部分', '。']
Loading model cost 0.999 seconds.
Prefix dict has been built successfully.
搜索引擎模式
搜索引擎模式: 在精确模式的基础上, 对长词再次切分. 提高召回率, 适合用于搜索引擎分词.

例子:
import jieba
# 定义文本
content = "自然语言处理是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。"
# 搜索引擎模式
seg = jieba.cut_for_search(content)
# 调试输出
print([word for word in seg])
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
['自然', '语言', '自然语言', '处理', '是', '人工', '智能', '人工智能', '和', '语言', '语言学', '领域', '的', '分支', '学科', '。', '此', '领域', '探讨', '如何', '处理', '及', '运用', '自然', '语言', '自然语言', ';', '自然', '语言', '自然语言', '处理', '包括', '多方', '方面', '多方面', '和', '步骤', ',', '基本', '有', '认知', '、', '理解', '、', '生成', '等', '部分', '。']
Loading model cost 0.859 seconds.
Prefix dict has been built successfully.
获取词性
通过 jieba.posseg 模式实现词性标注.
import jieba.posseg as psg
# 定义文本
content = "自然语言处理是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。"
# 分词
seg = psg.lcut(content)
# 获取词性
part_of_speech = [(x.word, x.flag) for x in seg]
# 调试输出
print(part_of_speech)
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
[('自然语言', 'l'), ('处理', 'v'), ('是', 'v'), ('人工智能', 'n'), ('和', 'c'), ('语言学', 'n'), ('领域', 'n'), ('的', 'uj'), ('分支', 'n'), ('学科', 'n'), ('。', 'x'), ('此', 'zg'), ('领域', 'n'), ('探讨', 'v'), ('如何', 'r'), ('处理', 'v'), ('及', 'c'), ('运用', 'vn'), ('自然语言', 'l'), (';', 'x'), ('自然语言', 'l'), ('处理', 'v'), ('包括', 'v'), ('多方面', 'm'), ('和', 'c'), ('步骤', 'n'), (',', 'x'), ('基本', 'n'), ('有', 'v'), ('认知', 'v'), ('、', 'x'), ('理解', 'v'), ('、', 'x'), ('生成', 'v'), ('等', 'u'), ('部分', 'n'), ('。', 'x')]
Loading model cost 1.500 seconds.
Prefix dict has been built successfully.


【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)