性能分析之系统资源饱和度

前言
在做性能分析的时候,我们不可避免地判断资源到底够不够用?哪里不够?为什么不够?证据是什么?
能回复得了这些问题并不容易。
今天就来聊聊一下操作系统资源饱和度应该如何衡量?
现在 k8s 盛行,所以这里来借用 k8s 中部署的 Prometheus+Grafana 来直观的看图。
CPU 资源
先看一个图:
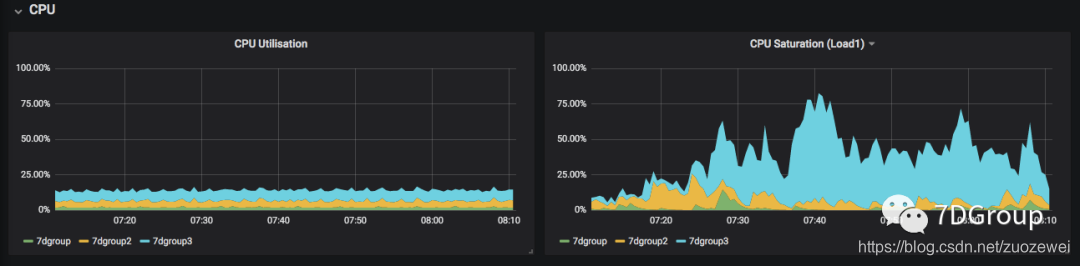
一边是 CPU 使用率,一边是 CPU 饱和度。
饱和度如何来算的呢?
看它的 Query 是什么样的:
node:node_cpu_saturation_load1:{cluster="$cluster"} / scalar(sum(min(kube_pod_info{cluster="$cluster"}) by (node)))
即是 node_cpu_saturation_load1 来计算的,那这个 node_cpu_saturation_load1 的基础数据是什么?再来它的来源:
sum by (node) (
node_load1{job="node-exporter"}
* on (namespace, pod) group_left(node)
node_namespace_pod:kube_pod_info:
)
/
node:node_num_cpu:sum
record: 'node:node_cpu_saturation_load1:'
load average 1min 内的数据,node_exporter 同时也实现了 node_load5/node_load15。分别来对应我们常见的 Linux 中的 load average 的 1 分钟、5 分钟、15 分钟。
而这个 load average 从哪里来,在之前的文章中有过描述,同时也说了这个值用来判断系统负载的局限性。这里就不展开了。
知道了这个 CPU 饱和度的来源之后,我们再来看上面的图。即是说,我们在判断 CPU 是否够用的时候,不仅是要看 CPU 使用率,还要看 CPU 饱和度才可以。
内存资源
如下图:
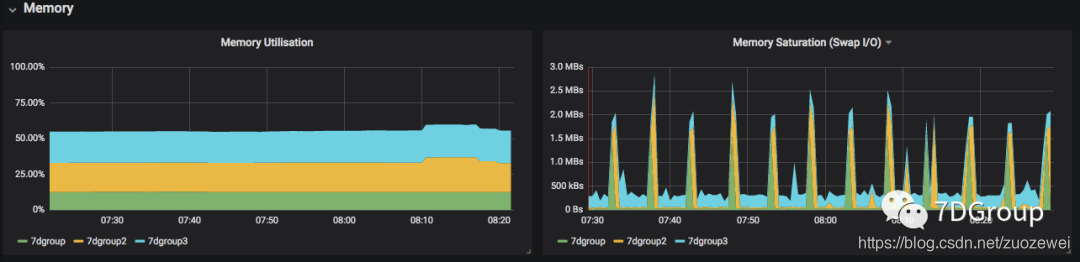
这里的内存饱和度后面加了一个 Swap IO。其实了解内存的人会知道,swap 这个词实在是有特定的含义,交换分区,但是在我们在配置 k8s 的时候会知道 swap 是关了的。但是这里 swap 是什么呢?
再来看它的 Query 语句。
node:node_memory_swap_io_bytes:sum_rate{cluster="$cluster"}
取了 node_memory_swap_io_bytes 这个值,这个值在 prometheus 里是什么呢?
- expr: |
1e3 * sum(
(rate(node_vmstat_pgpgin{job="node-exporter"}[1m])
+ rate(node_vmstat_pgpgout{job="node-exporter"}[1m]))
)
record: :node_memory_swap_io_bytes:sum_rate
取了 vmstat 的 page in/out。这就理解了,swap 并不是特指交换分区。而是页交换,没有交换分区不打紧,页交换还是要做的。
而有页交换并不一定就是内存用完了,指内存中找不到要使用的页也是要有 page in 的。而在代码中定义了某个变量或对象的内存大小之后,当不够用时,也照样会 page out。
所以判断内存是否够用,不仅要看内存是否用完,还要看 page in/out 是否产生。
磁盘资源
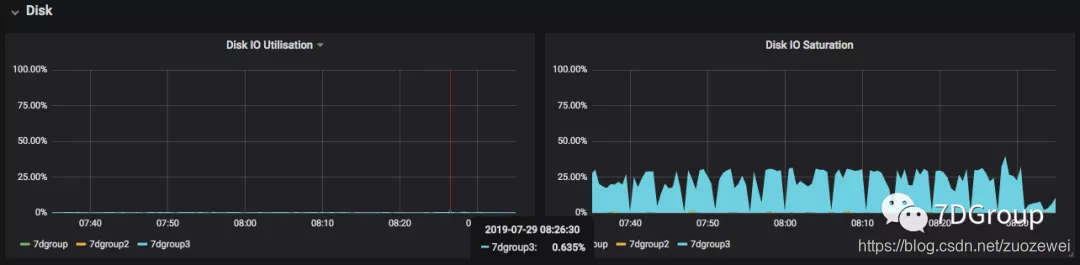
磁盘的 IO 饱和度是比较容易判断的,我们来看看它是如何判断,同样来看看它的 Query:
node:node_disk_saturation:avg_irate{cluster="$cluster"} / scalar(:kube_pod_info_node_count:{cluster="$cluster"})
取了 node_disk_staturation,同时计算了 avg_irate。我们来看一下这个值的来源。
- expr: |
avg by (node) (
irate(node_disk_io_time_weighted_seconds_total{job="node-exporter",device=~"nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+"}[1m])
* on (namespace, pod) group_left(node)
node_namespace_pod:kube_pod_info:
)
record: node:node_disk_saturation:avg_irate
它取了 node_disk_io_time_weighted_seconds_total 的值,这是一个加权累积值。而这个值是来源于 iostat 中的avgqu-sz,这个值是 IO 队列长度。
这样就知道这个饱和度的来源了
网络资源
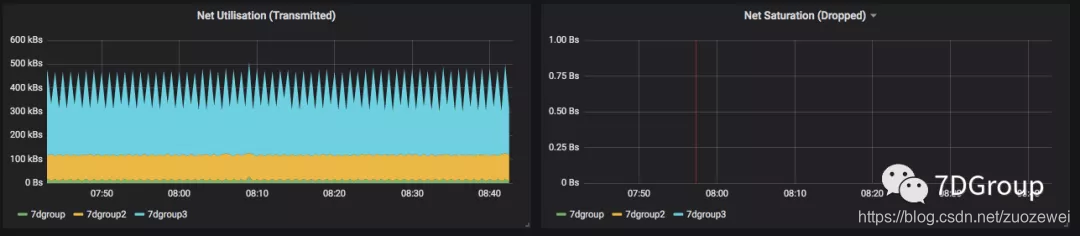
在网络资源的判断上,这里用了一个非常直接的词 dropped。直观理解就是丢包,来看它的 Query 语句。
node:node_net_saturation:sum_irate{cluster="$cluster"}
这里调用了 node_net_saturation 的值,而这个值不够直观的知道是什么内容。
再来看看它的来源:
- expr: |
sum by (node) (
(irate(node_network_receive_drop_total{job="node-exporter",device!~"veth.+"}[1m]) +
irate(node_network_transmit_drop_total{job="node-exporter",device!~"veth.+"}[1m]))
* on (namespace, pod) group_left(node)
node_namespace_pod:kube_pod_info:
)
record: node:node_net_saturation:sum_irate
从这段代码就很清楚地知道了,这是从接收的 drop 来的。好直观的名字。
其实判断网络瓶颈,不止是丢不丢包,也要看队列。如果已经出现丢包了的话,那网络质量就必定差了。
总结
其实不管我们用什么工具来看性能数据,都是需要知道它的来源和值的含义,这样才能判断精确。
在很多场合,不管是项目还是做一些分享,我都强调过性能分析中要先理解每个数据的含义再来看所选择的工具中如何展现。
而有些人觉得上一个监控平台或 APM 之类的就可以知道瓶颈点在哪里了,这个理念绝对是有问题的。
打好基础,仍然是学习的重点。

- 点赞
- 收藏
- 关注作者
评论(0)