性能分析之构建 Linux 操作系统分析决策树

前言
初学者对性能分析的感受是:横看成岭侧成峰,远近高低各不同。那么应该怎么学习才能建立起自己的性能分析体系,才能做到千山同一月,万户尽皆春。千江有水千江月,万里无云万里天呢?
这时候分析决策树,对性能分析人员就体现价值了,是性能分析中不可或缺的一环。它是对架构的梳理,是对系统的梳理,是对问题的梳理,是对查找证据链过程的梳理,是对分析思路的梳理。它起的是纵观全局,高屋建瓴的指导作用。性能做到了艺术的层级之后,分析决策树就是提炼出来的,可以触类旁通的方法论。而我要在这里跟你讲的,就是这样的方法论。
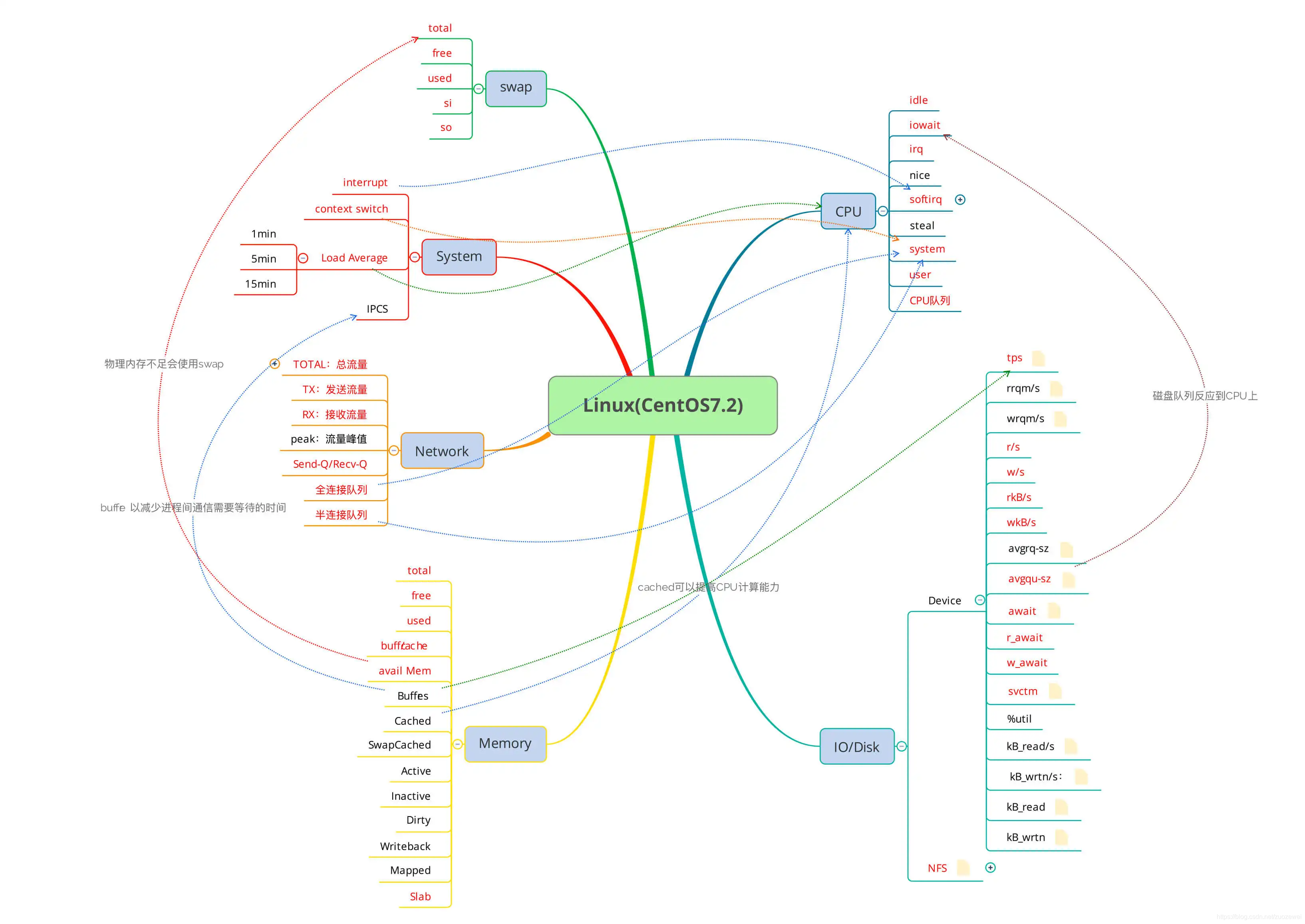
构建决策树的关键
决策树基本上就是把我们以前的分析经验总结出来,在做决策树的时候,一般会经历两个阶段:构造和剪枝。
概念简单来说:
- 构造的过程就是选择什么属性作为节点的过程构造的过程就是选择什么属性作为节点的过程;
- 剪枝就是给决策树瘦身,这一步想实现的目标就是,不需要太多的判断,同样可以得到不错的结果。之所以这么做,是为了防止“过拟合”现象的发生。
从性能分析角度来理解:
- 构造:需要根据经验是对架构的梳理,是对系统的梳理,是对问题的梳理,是对查找证据链过程的梳理,是对分析思路的梳理;
- 剪枝:需要对对不同时间序列性能数据的相关性分析,其核心就是要理解各个性能指标的关系,同时进行证据链查找,根据数据的变化来推断得出各种结论,比如故障判别、根因分析等。
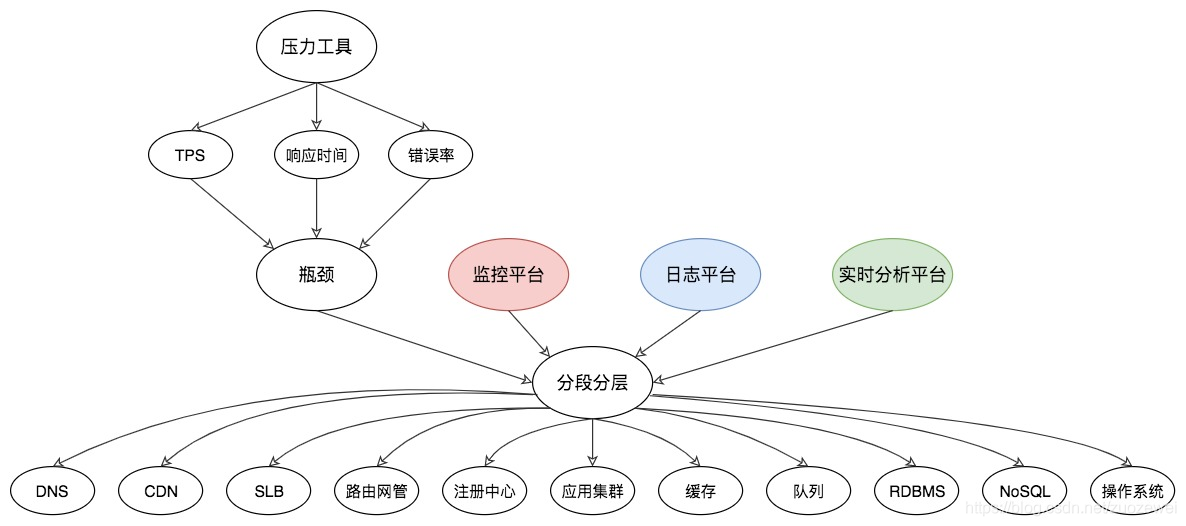
构建 CPU 分析决策树
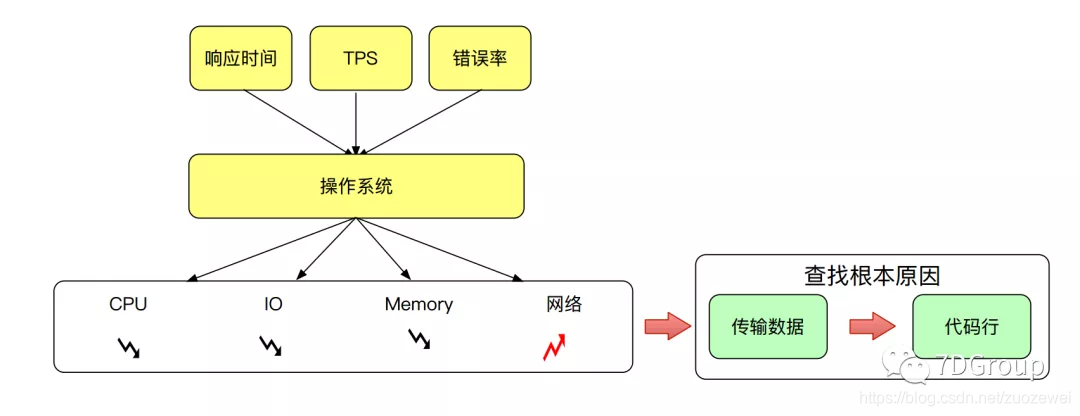
第一层是业务指标:
-
响应时间
-
TPS
-
错误率
第二层是资源指标:
-
CPU
-
IO
-
MEM
-
NET
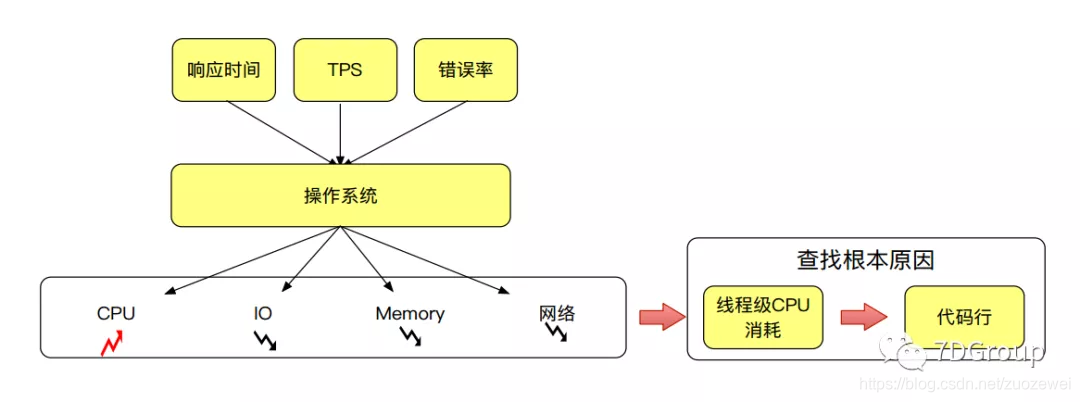
分析方法(Java应用):
-
使用 TOP 命令找到谁在消耗 CPU 比较高的进程,例如
pid=1232 -
使用
top -p 1232单独监控该进程 -
输入大写的 H 列出当前进程下的所有线程
-
查看消耗 CPU 比较高的线程,并看线程编号,例如:12399
-
使用
jstack 1232>pagainfo.dump获取当前进程下的 dump 线程信息 -
将第四步获取的线程编号 12399 转换成 16 进制 306f (
printf "%x\n" 12399) -
根据 306f 在第 5 步获取的栈信息中查找
tid=0x306的线程 -
定位代码位置(根据打印出来的堆栈信息查看代码所在位置)
以上过程简单的办法是借助一些开源的 shell 工具,如:
- 用于快速排查Java的CPU性能问题(top us值过高),自动查出运行的Java进程中消耗CPU多的线程,并打印出其线程栈,从而确定导致性能问题的方法调用。
- https://github.com/oldratlee/useful-scripts/blob/dev-2.x/docs/java.md#-show-busy-java-threads
构建 I/O 分析决策树
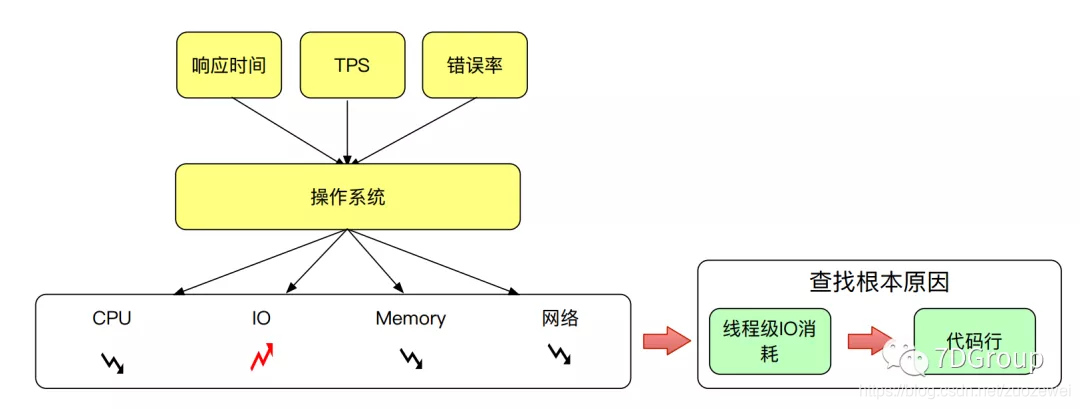
先聊下磁盘系统结构:
- 如果是IDE驱动器,磁盘命名为:hda、hdb、hdc等;
- 如果是SCSI驱动器,磁盘命名为:sda、sdb、sdc等
- 磁盘通常被分成多个分区,分区设备的名称是通过将分区号添加到基本设备名称的末尾来创建的,每个单独的分区通常包含一个文件系统或一个交换分区,按照/etc/fstab中的指定,这些分区被装载到 Linux 根文件系统中。这些挂载的文件系统包含应用程序读写的文件。
- 当应用程序执行读或写操作时,Linux 内核可能会将文件的副本存储在其缓存或缓冲区中,并在不访问磁盘的情况下返回所请求的信息。但是,如果 Linux 内核没有存储在内存中的数据副本,它会向磁盘的 I/O 队列添加一个请求。如果 Linux 内核注意到多个请求请求磁盘上的连续位置,它会将它们合并为一个大请求。这种合并消除了第二个请求的寻道时间,从而提高了总体磁盘性能。当请求被放入磁盘队列时,如果磁盘当前不忙,它将开始为 I/O 请求提供服务。如果磁盘正忙,请求将在队列中等待,直到驱动器可用,然后对其进行服务。
在这一层咱们主要关注 I/O ,既然是关注 I/O ,如果 I/O 高应该怎么去分析?怎么定位?
vmstat [-D] [-d] [-p 分区]
参数说明:
- d:显示磁盘相关统计信息。
- D: 显示 Linux I/O 子系统的总统计信息,统计数据是自系统启动以来的总数
- p: 统计数据是自系统启动以来的总数,而不仅仅是此示例和上一个示例之间发生的总数。
使用 vmstat 中关于磁盘也就是 bo/bi/wa
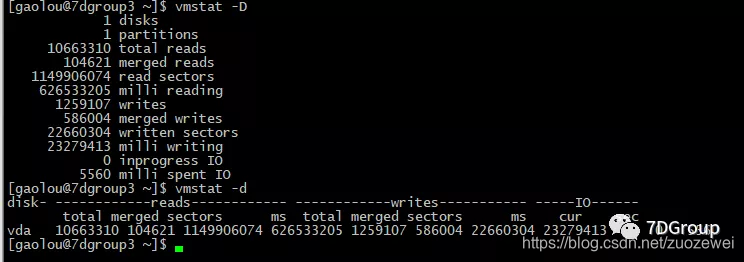
使用 vmstat 中关于磁盘也就是 bo/bi/wa:
- bo 这表示在前一间隔内写入磁盘的块总数。(在vmstat中,磁盘的块大小通常为1024字节。)
- bi 显示在上一间隔中从磁盘读取的块数。(在vmstat中,磁盘的块大小通常为1024字节。)
- wa 表示等待I/O完成所花费的CPU时间。每秒写入磁盘块的速率
在 linux 操作系统中 I/O 分析最常见的命令是 iostat
iostat -d -x -k 1 10
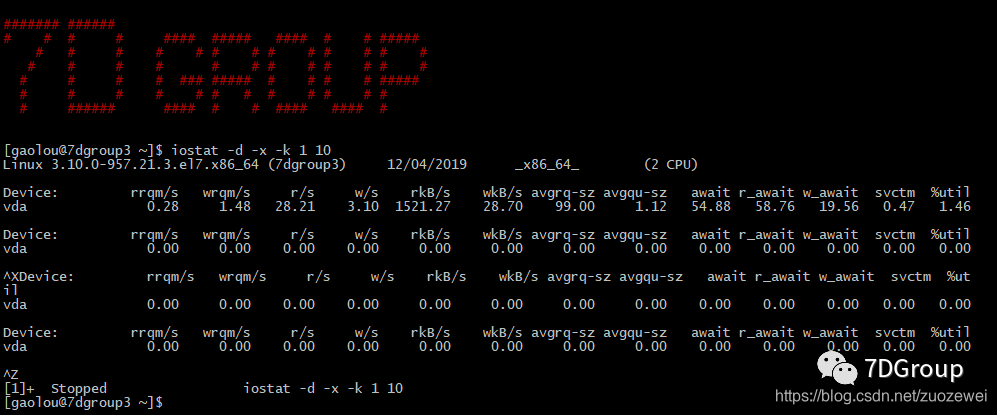
计数器信息的含义:
- rsec/s:每秒读取的扇区数;
- wsec/:每秒写入的扇区数。
- avgrq-sz:平均请求扇区的大小
- avgqu-sz:是平均请求队列的长度。毫无疑问,队列长度越短越好。
- await:每一个 I/O 请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为 I/O 的响应时间,一般系统 I/O 响应时间应该低于 5ms,如果大于 10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await 大于 svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
- svctm:表示平均每次设备 I/O 操作的服务时间(以毫秒为单位)。如果 svctm 的值与 await 很接近,表示几乎没有 I/O 等待,磁盘性能很好,如果 await 的值远高于 svctm 的值,则表示 I/O 队列等待太长,系统上运行的应用程序将变慢。
- %util:在统计时间内所有处理 I/O 时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有 0.8 秒在处理 I/O,而 0.2 秒闲置,那么该设备的
%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是 100 %表示设备已经接近满负荷运行了(当然如果是多磁盘,即使 %util 是 100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
主要关注计数器:
-
util
-
avgqu-sz
-
await:
-
svtm
-
util
出现瓶颈的计数器:
- %util 很高
- await 远大于 svctm
- avgqu-sz 比较大
- cpu > wa 过大 (参考值超过 20)
- system > bi&bo 过大(参考值超过 2000)
构建内存分析决策树
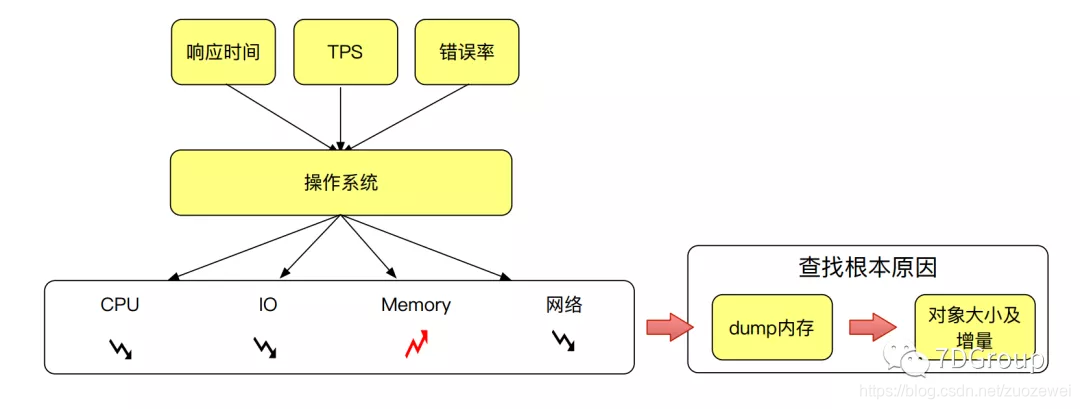
在这一层咱们主要关注 mem ,既然是关注 mem,如果 mem 高应该怎么去分析?怎么定位?
常用命令 free:
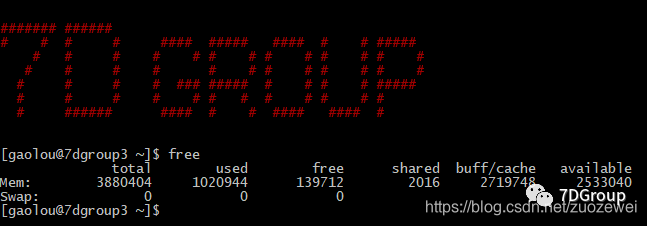
计数器说明:
- total:总计物理内存的大小
- used:已使用多大
- free:可用有多少
- Shared:多个进程共享的内存总额
- Buffers/cached:磁盘缓存的大小
vmstat 可以提供的 CPU 计数器外,还可以在内存统计时使用:
vmstat [-a] [-s] [-m] [-d] [-p] [n] [-f] [-v]
参数说明:
- -a:显示活跃和非活跃内存
- -f:显示从系统启动至今的fork数量 。
- -m:显示 slabinfo
- -n:只在开始时显示一次各字段名称。
- -s:显示内存相关统计信息及多种系统活动数量。
- delay:刷新时间间隔。如果不指定,只显示一条结果。
- count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
- -d:显示磁盘相关统计信息。
- -p:显示指定磁盘分区统计信息
- -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
- -V:显示 vmstat 版本信息。
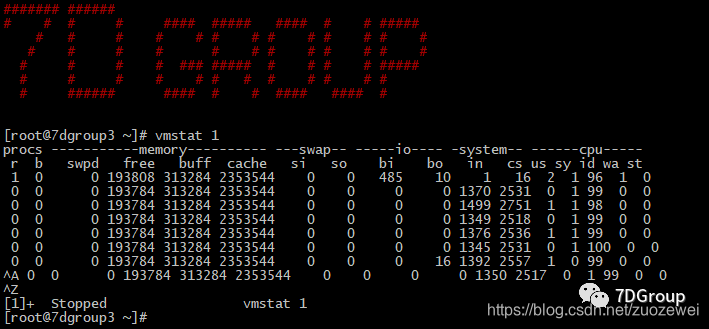
以上计数器具体每个信息代表什么,大家自行搜索一下,网上资料多如牛毛。
vmstat -m显示的信息与 cat /proc/slabinfo 显示的信息相同:
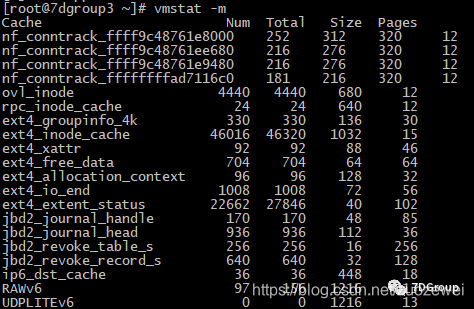
这详细描述了内核的内存是如何分配的,并且有助于确定内核的哪个区域消耗的内存最多(通过这个命令就能知道内存在那个区域消耗最多)
vmstat -s
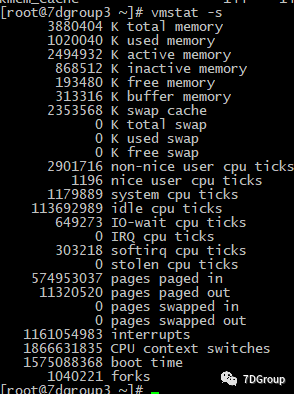
其准确跟踪内核如何使用其内存时非常有用。
我们可以使用 vmstat 命令,监控包括 Linux 的CPU使用率,内存使用,虚拟内存交换情况,IO 读写情况,用于分析磁盘的压力在哪里,在 swap,还是在 load 文件等;
构建网络分析决策树
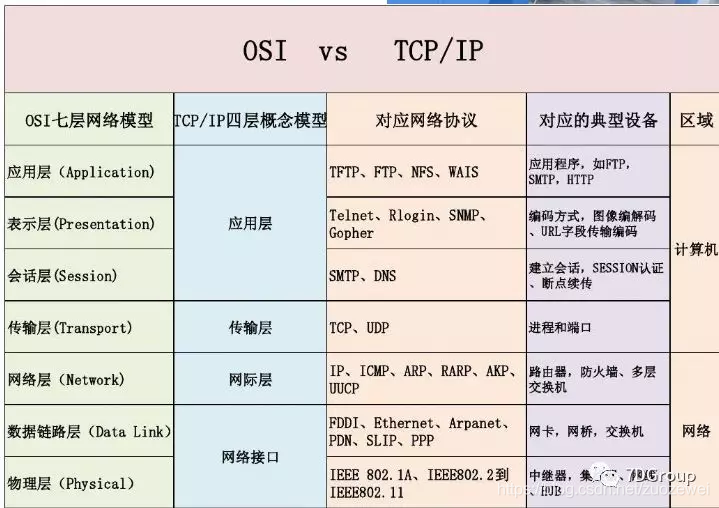
在学习网络这一层需要了解下网络的七层协议:
常用命令:
- hostname
- ping
- ifconfig
- wconfig
- netstat
- nslookup
- traceroute
- finger
- telnet
- ethtool
ip -s [-s] 链接
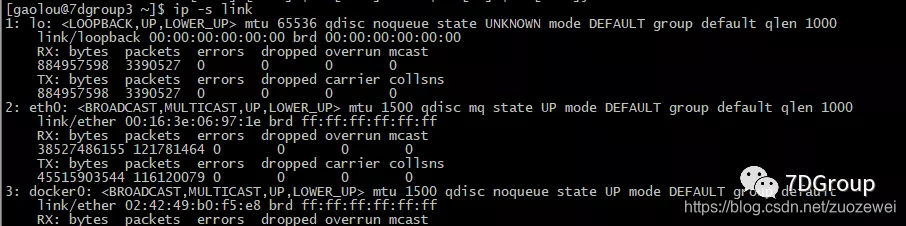
计数器解释:
- bytes:发送或接收的字节总数。
- packets:发送或接收的数据包总数。
- errors:发送或接收时发生的错误数。
- dropped:由于网卡资源不足而未发送或接收的数据包数。
- overruns:网络没有足够缓冲空间发送或接收更多数据包的次数。
- mcast:已接收的多播数据包数。
- carrier:由于链路媒体故障(如电缆故障)而丢弃的数据包数。
- collsns:这是设备在传输时遇到的冲突数。当两台设备试图同时使用网络时,就会发生这种情况。
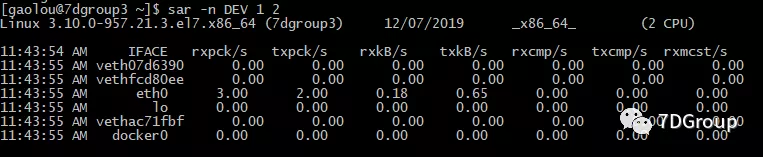
sar [-n DEV | EDEV | 袜子 | FULL ] [DEVICE] [间隔] [计数]
也可使用命令:
yum install iptraf
iptraf-ng -d eth0 -t 1
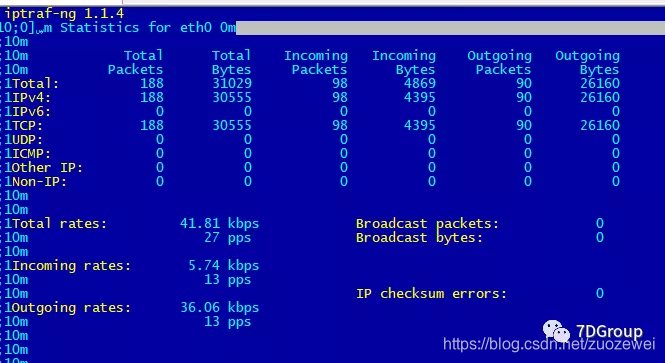
查看哪个端口进出流量是多少?
iptraf-ng -s eth0 -t 10

网络统计:
[-p] [-c] [–interfaces=<名称>] [-s] [-t] [-u] [-w]
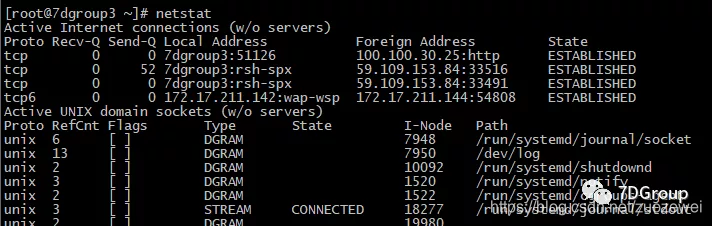
netstat -t -c

netstat -t -p

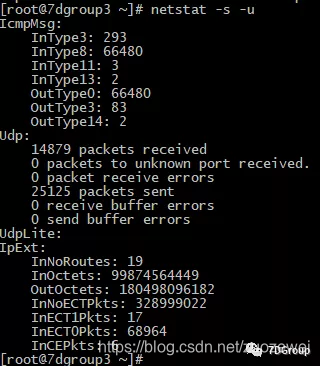
netstat -s -u
总结
如果你看到 Linux 操作系统架构图就头大,那么这时候应该觉得有了希望。我觉得操作系统上的问题判断是比较清晰的,所以基于决策树,每个人都可以做到对操作系统中性能问题的证据链查找。

- 点赞
- 收藏
- 关注作者
评论(0)