【Yolo】⚠️一文看懂 Yolo 目标检测⚠️ ☢️万字长文, 建议手收藏☢️ 【百变AI秀】

概述
Yolo (You Only Look Once) 是目标检测 one-state 的一种神经网络. Yolo 可以帮助我们在图片中找出特定物体, 并识别种类和位置.

one-stage
- 典型代表: yolo
- 优点: 速度快, 可以实时检测
- 缺点: 效果不如 two-stage
two-stage
- 经典代表: Mask-Rcnn
- 优点: 效果好
- 缺点: 速度慢
Yolo 原理
核心思想:

分割图片
Yolo 会首先将图片分割成一个 S * S 的网格.

如图, 图片被分割成了 7 * 7 的网格.
预选框
图片呗分成了 49 个框, 每个框包含 2 个预选框 (bounding box).

完整的图:

如图, 总共有 2 * 49 = 98 个预选框. 其中置信度比较高的框会较粗, 置信度低的较细.
计算参数
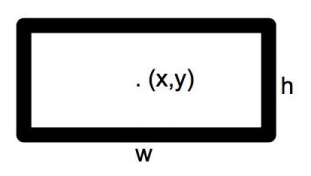
其中每个网格包含 2 * 5 (x, y, w, h, c) + 20 个类别.
- 2: 2 个预选框
- x, y 为物体的中心点
- w, h 为物体的长宽
- c (confidence): 置信度

总共有 7 * 7 * 30 = 49 * 30 个参数.
预测物体
类别的概率 = 在物体中是类别的概率 * 是物体的概率:
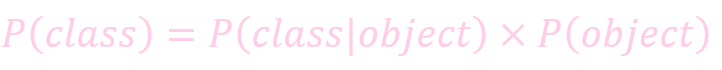
例如: 物体是狗的概率是 0.7, 是物体的概率是 0.8 => 是狗狗的概率是 0.7 * 0.8 = 0.56

得到结果

指标
IOU
IOU (Intersection Over Union) 反应了预测位置和真实物位置的相似度.
IOU = 交集 / 并集:
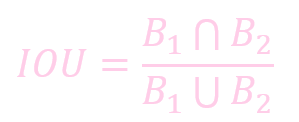

置信度
置信度 (box 内存在对象的概率 * box 与该对象实际 box 的 IOU)
公式:
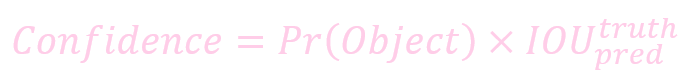
一个预测框的置信度 (Confidence) 代表了是否包含对象且位置正确的准确度.
mAP
mAP (Mean Average Precision) 平均精度均值 是用来评价目标检测的常用指标.

mAP 是准确率和召回率的一个综合考量.

NMSE
NMSE (None-maximal Suppression) 非极大值抑制. 可以帮助我们消除多余的候选框.

B1,B2, B3, B4 四个框框都包含狗狗, 我们通过 NMSE 保留最大置信度 (B1), 去掉其他的候选框.
损失函数

Yolov1 vs Yolov2
网络结构
v1:

v2:

标准化
v2 版本舍弃 Dropout, 卷积后全部加入 Batch Normalization. 经过 Bach Normalization 处理后, 收敛相对更容易, 网络会提升 2.4% 的 mAP

高分辨率
- v1 训练时用的是 224 * 224, 测试使用 448 * 448. v2 训练时额外又进行了 10 次 448 * 448 的微调. 使用高分辨率分类器后, v2 的 mAP 提升了约 4%
无全连接层
v2 版本舍弃了 FC (Fully Connect) 层, 使用平均池化代替了全连接层.

锚框
以往的模型一个窗口只能预测一个目标. 通过引入锚框 (anchor box), 在训练中我们将每一个锚框视为一个训练样本, 通过使用不同形状的锚框, 可以使得预测框更有针对性.

Yolov2 vs Yolov3
网络结构
v2 (Darknet-19):
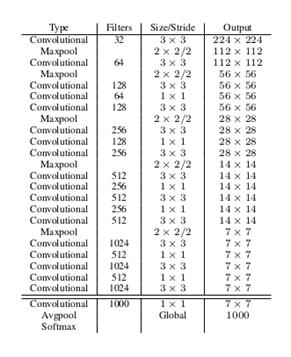
v3 (Darknet-53):

v3 去除了 maxpool, 通过步长为 2 的卷积来实现下采样.
Scale
为了能检测不同大小的物体, 设计了 3 种大小, 三种规格, 一共 9 种不同的先验框:

一个物体和哪个锚框匹配度最高就会被指定给这个锚框.

特征融合
对不同的特征图分别利用:

对不同的特征图进行融合:

预测
使用 logistic 激活函数代替 softmax, 解决了物体检测任务中可能一个物体有多个标签的问题.

Yolov4 vs Yolov5
Yolo 之父 Joe Redmon 在相继发布了 yolov1 (2015) yolov2 (2016), yolov2 (2018) 的两年后. 在 2020 年 2 月 20 号在 Twitter 上宣布退出 CV 界.

俄罗斯的 Alexey 大佬扛起了 Yolov4 的重任.
网络结构
yolov3:

yolov4:

BOF
BOF (Bag of Freebies) 是一种增加训练成本但是能显著提高精度的方法集.

数据增强
通过调整亮度, 对比度, 色调, 缩放, 剪切, 旋转等方法增加训练图像的多样性. 从而使得模型有更强的泛化能力 (Generaliztion Ability).
不同的数据增强对比:

- Mixup: 将随机的两张样本按比例混合, 分类的结果按比例分配
- Cutout: 随机的将样本中的部分区域裁剪掉, 并填充 0 像素值, 分类的结果不变
- CutMix: 将一部分区域裁剪掉, 并随机用训练集中的其他数据区域像素值进行填充, 结果按一定比例分配
马赛克数据增强
马赛克数据增强 (Mosaic Data Augmentation) 通过把四张图片随机裁剪混合成一张图片来实现数据增强. Yolov4 中使用的 Mostic 是 CutMix 的一种延伸. 例如:

Mosaic 的优点:
- 丰富数据集: 使用 4 张随机图片缩放拼接, 丰富了检测数据集, 增加了很多小目标
- 减少 GPU: 通过缩放, 以及一次计算 4 张图片. 充分利用了 GPU 资源, 使得 batch_size 不用很大就能达到很好的效果
对抗训练
SAT (Self Adversaraial Training) 即对抗训练. 样本会被添加很小比例的噪声, 从而增加模型的泛化能力. 如图:
Drop Block
Drop Block 会随机 drop 图片的一个区域从而增加学习的强度. 如图:

公式 (了解即可):
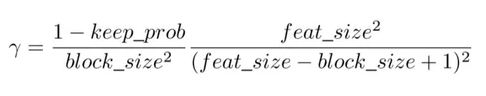
Drop Block 效果:

BOS
BOS (Bag of Specials) 指的是可以提升检测效果但只些微增加成本的一组方法.
SPPNet
SPPNet(Spatial Pyramid Pooling) 即金字塔池化, 可以帮助我们将图像切分成各种粗细级别, 然后整合特征.

金字塔池化解决了固定图像尺寸的限制 (最大池化), 并提高了提取特征的效率.
CSPNet
CSPNet (Cross Stage Partial Network) CSPNet 通过将梯度的变化从头到尾地集成到特征图中, 在减少了计算量的同时可以保证准确率.

如上图, 将一层分为两部分. 一半不进行操作直接连接, 另一半进行卷积操作.
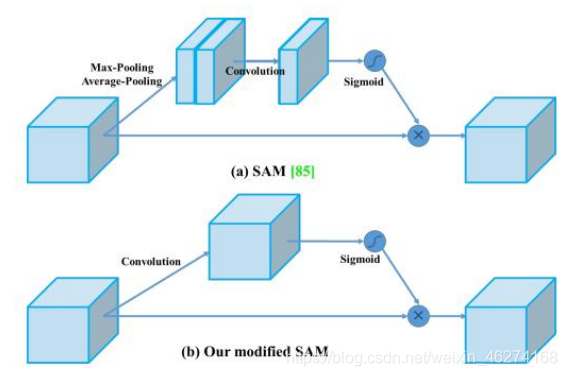
CBAM
CBAM (Convolutional Block Attention Module) 注意力模块, 通过空间和通道两个维度推断出注意力权重. 然后与原特征相乘来对特征进行自适应调整.

通道注意力模块:
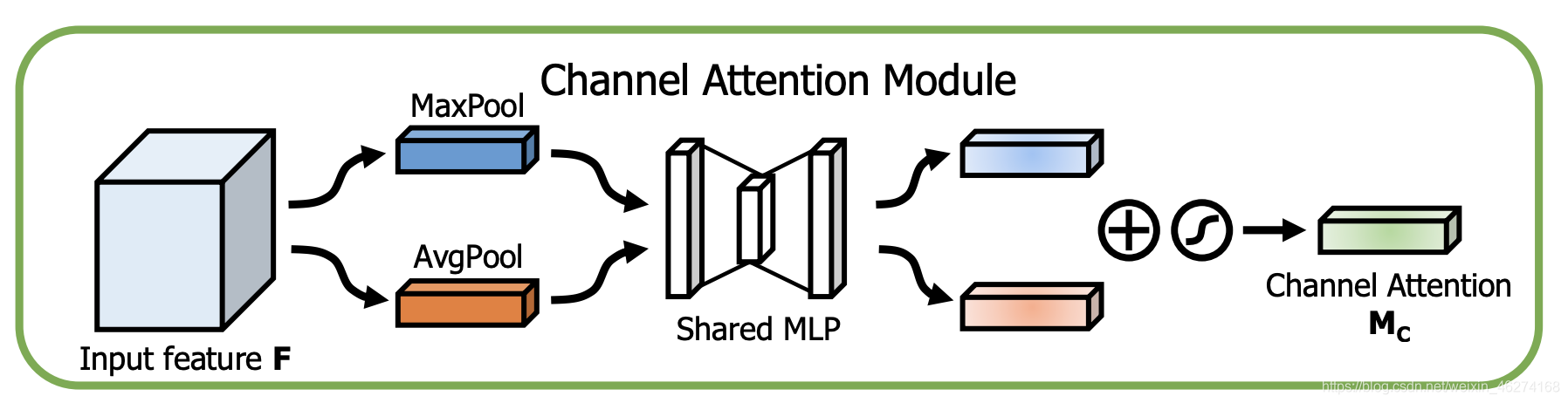
特征的每一个通道都代表一个专门的检测器. 通道注意力是关注什么样的特征是有意义的.
空间注意力模块:
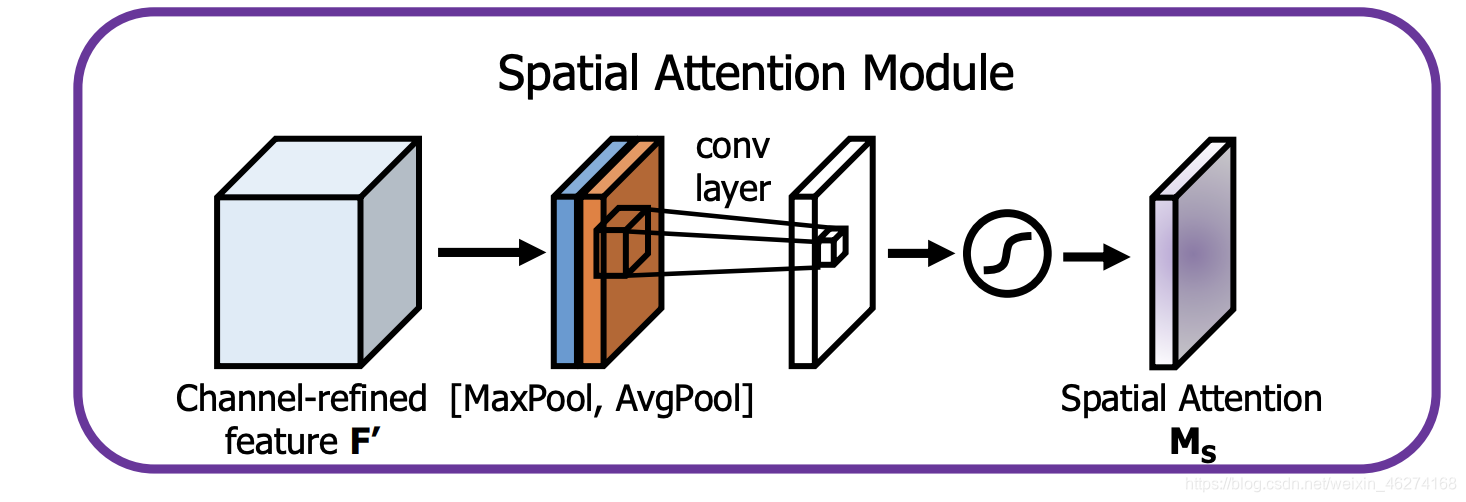 引入空间注意力模块来关注哪里的特征是有意义的.
引入空间注意力模块来关注哪里的特征是有意义的.
Yolo4 对空间注意力模块进行了简化:
PANet
PANet (Path Aggregation Network) 路径聚合网络, 通过添加自下而上的路径增强缩短了较低层和顶层之间的信息路径. 高层神经元反映了整个目标, 底层神经元反映了目标的基础信息.
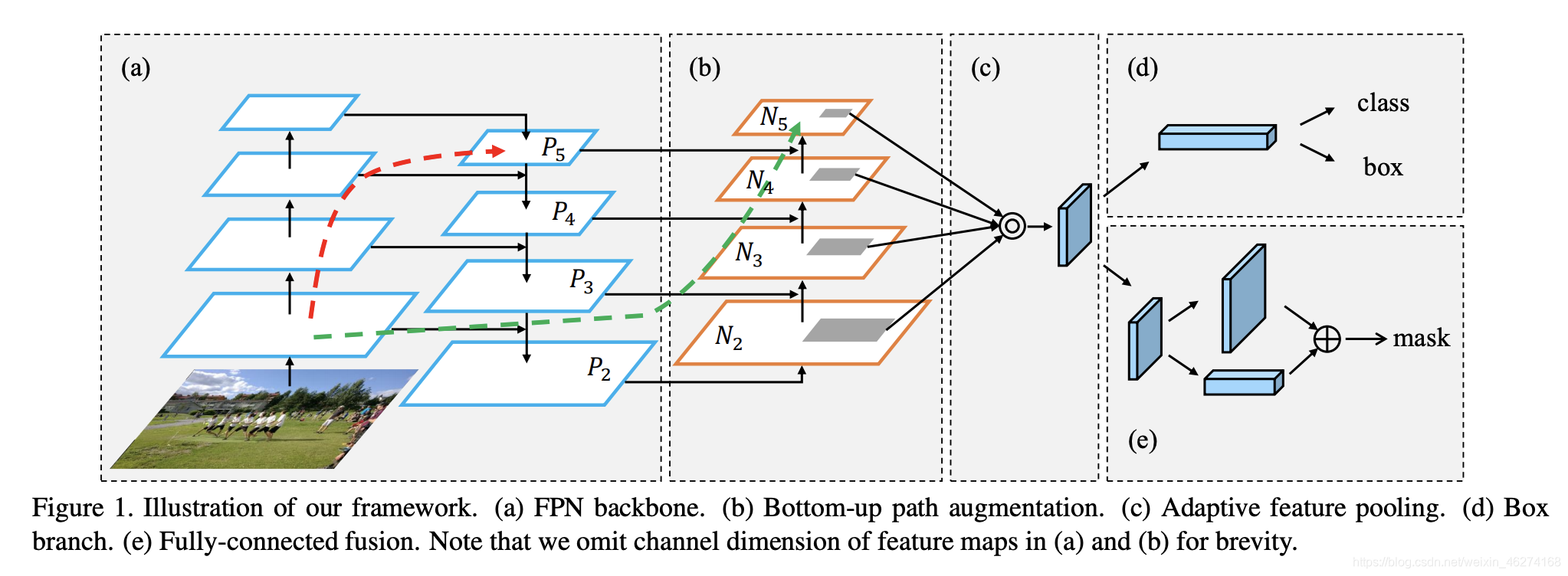
- (a) 是 FPN (Feature Pyramid Networks)
- (b) 通过自下而上的捷径使得低层信息更好的向高层传播
- © 允许每个提案访问所有层的信息来进行预测
yolov5 PanNet 流程:
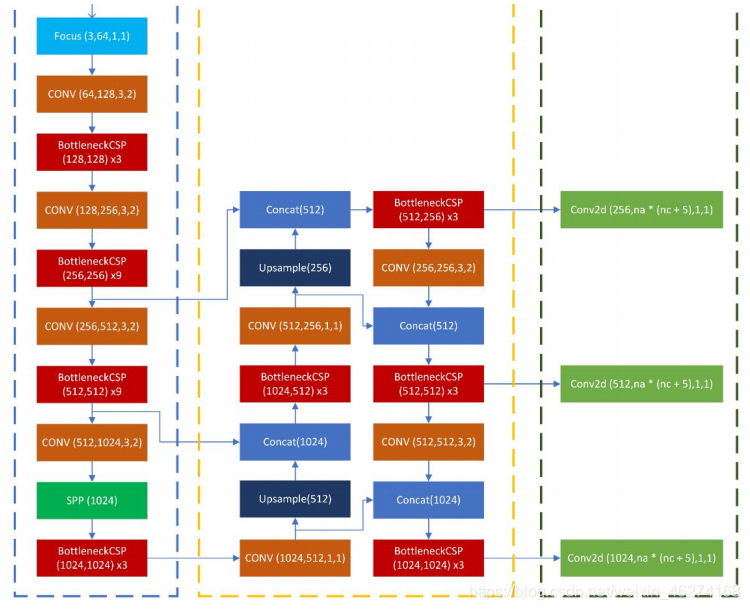
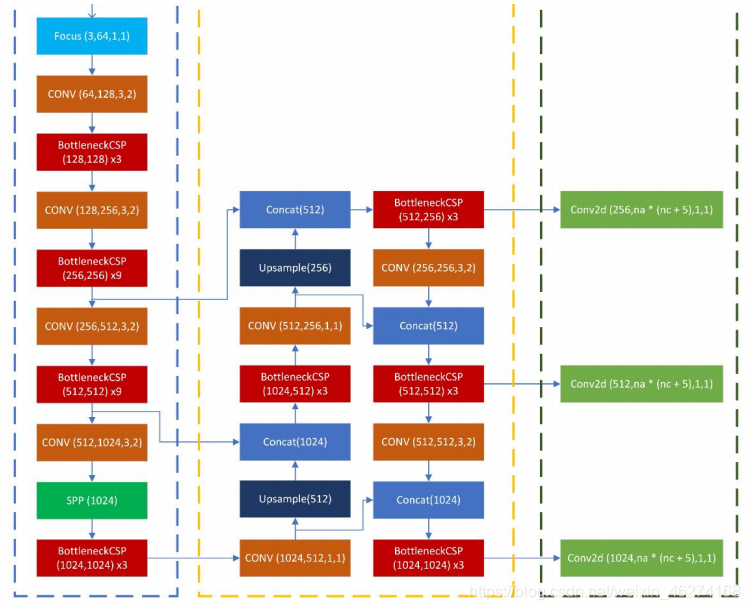
损失函数
标签平滑
标签平滑 (Label Smoothing) 是一种损失函数的修正, 可以帮助我们提高图像分类的准确性. 标签平滑将神经网络的训练目标从 “1” 调整为 “1 - 标签平滑矫正”.
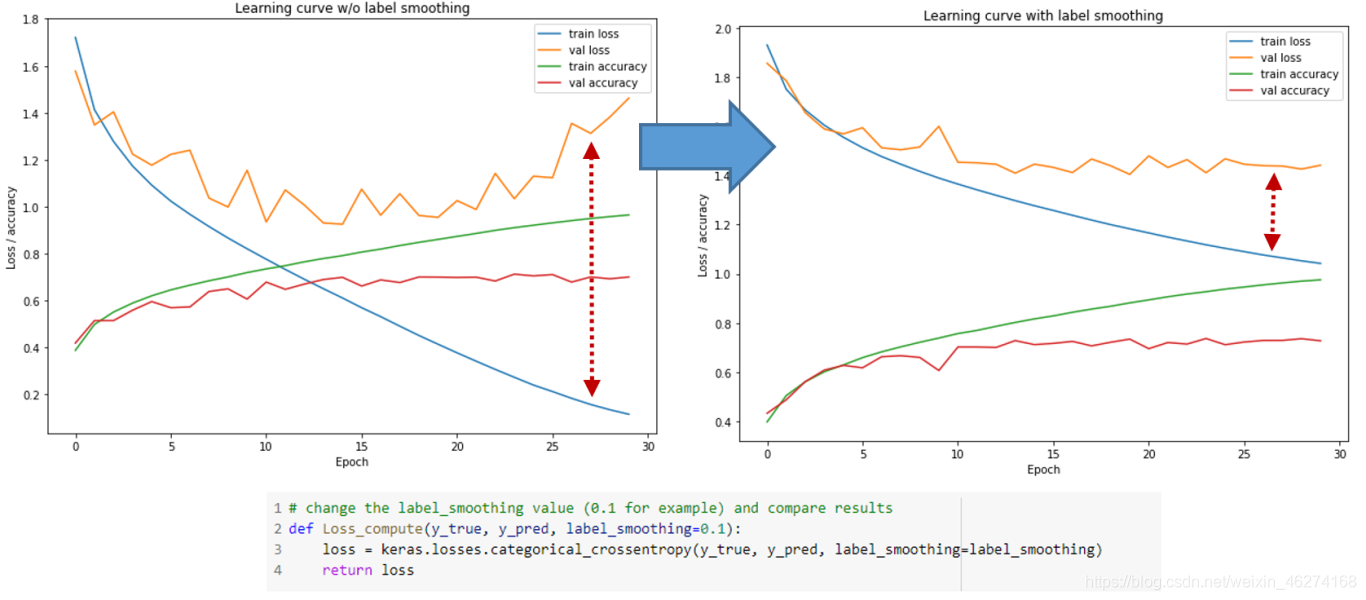
标签平滑可以帮助我们在一定程度上避免过拟合, 帮助我们提高模型对新数据的预测能力.
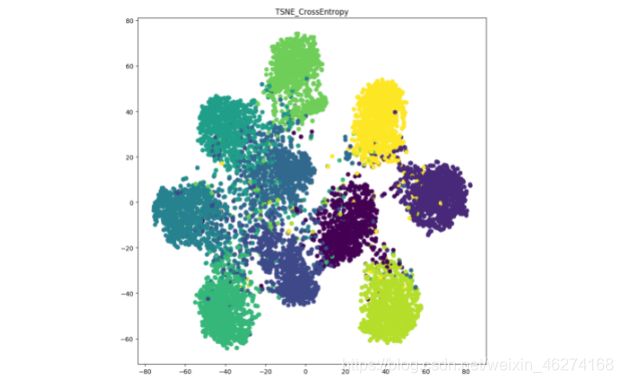
未使用标签平滑:
使用标签平滑:
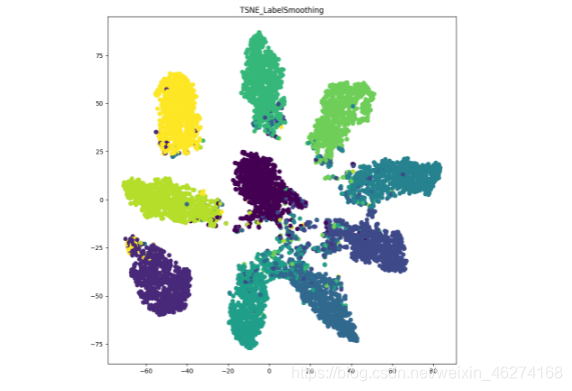
我们可以看出, 通过标签平滑, 分类的簇更紧密, 簇间距离更大.
IOU
在计算 IOU (Intersection over Union) 也就是交并比.
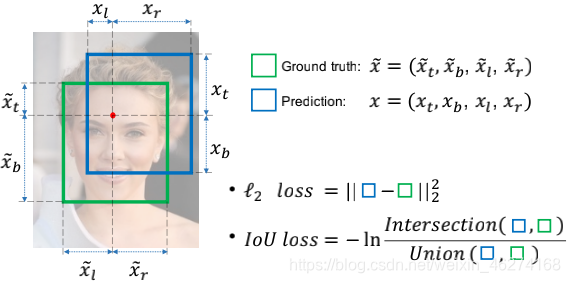
在使用 IOU 的时候我们会发现 2 个问题:
- 当预测框和实际框没有交集的时候 IOU 的值为 0, 我们就无法完成梯度计算
- IOU 无法精确反映预测框和真实框的重合度大小.

如图, 三种情况 IOU 都相同. 但是重合度依左往右递减.
GIOU
GIOU (Generalized Intersection over Union) 引入了最小封闭形状的概念, 如图中的 C:

GIOU 能在预测框和真实框不重叠的情况下能让预测框尽可能朝着真实框前进.
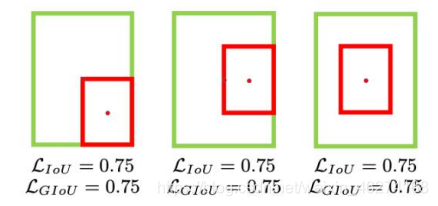
但在重叠的情况下, 就会产生一个问题 GIOU 的值会相等.
DIOU
DIOU (Distance IOU) 在 GIOU 的基础上添加了距离.
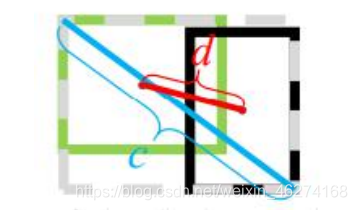
公式:

- 分子: 计算预测框和真实框的中心点欧式距离 d
- 分母: 预测框和真实框最小封闭形状的对角线长度 c
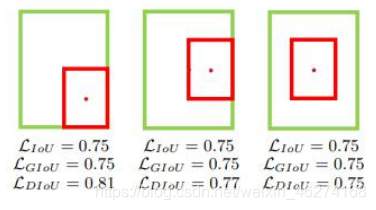
优点:
- 收敛速度快: DIOU 可以直接最小化两个目标框的距离, 比 GIOU 收敛更快
- 解决重叠: DIOU 可以提供一个朝真实框的移动方向
CIOU
CIOU (Complete IOU) 在 DIOU 的基础上增加了回归三要素: 重叠面积, 中心点距离, 长宽比. Yolov4 使用的就是 CIOU.
公式:
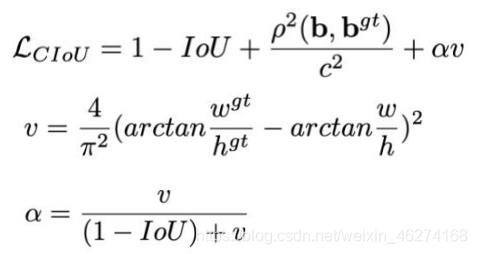
对比
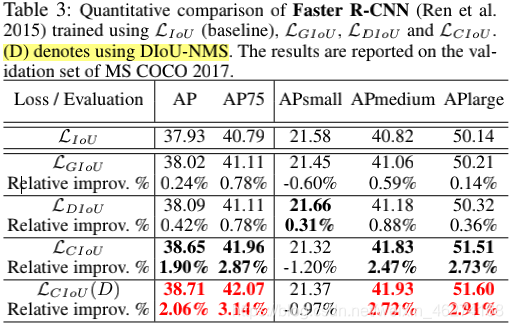
DIOU-NMS
DIOU-NMS (Distance Intersection of Union None Maximal Suppression) 是 NMS (None Maximal Suppression) 的升级版.
公式:

- M: 高置信度候选框
- Bi: 另一个临近的框

当两个不同物体挨得很近时, 由于 IOU 值比较大, 往往经过 NMS 处理后, 就只剩下一个检测框, 这样会导致漏检的错误情况发生. DIOU-NMS 不仅考虑了 IOU, 还考虑了两个框中心点的距离, 从而避免相邻物体被过滤的情况.
SOFT-NMS
SOFT-NMS 在 NMS 的基础上用降分机制取代了直接剔除. 当 M 为当前得分最高框, Bi 为待处理框, Bi 和 M 的 IOU 越大, Bi 的得分 Si 就下降的越厉害.
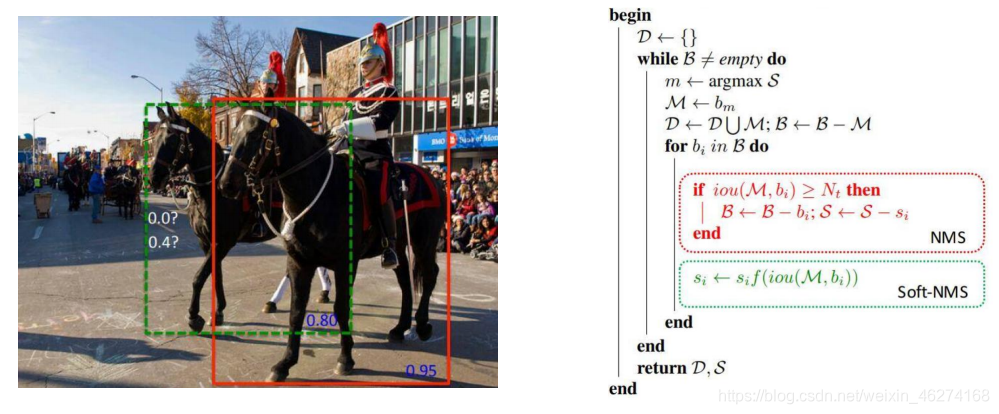
Mish 激活函数
Mish (Self Regularized Non-Monotonic Neural Activation) 自正则的非单调神经激活函数, 一个可能比 Relu 都牛逼的激活函数. 平滑的激活函数允许更好的信息深入神经网络, 从而得到更好的准确性和泛化.
公式:

Mish 激活函数 vs 其他的激活函数:
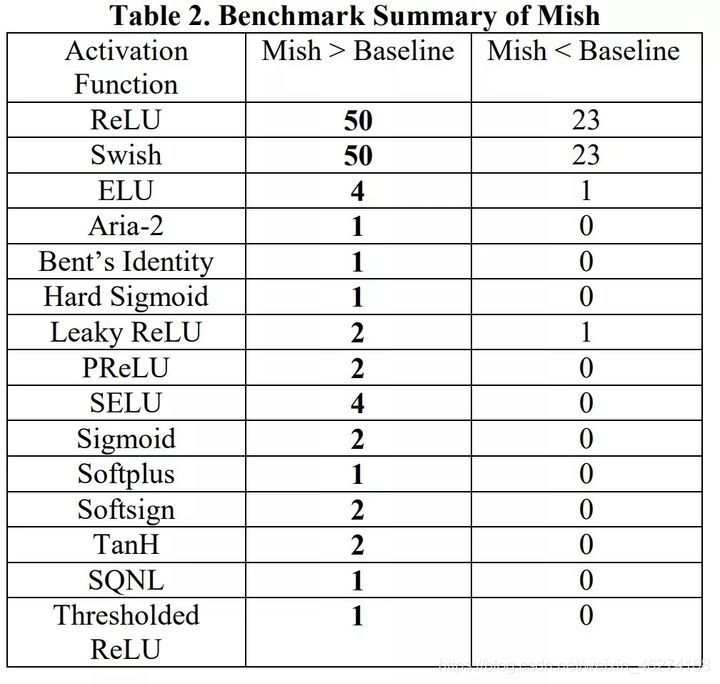
网络敏感性
消除网络敏感性 (Eliminate Grid Sensitivity) 通过在逻辑回归激活函数前面乘上一个大于 1 的系数来避免网络难以达到边界.
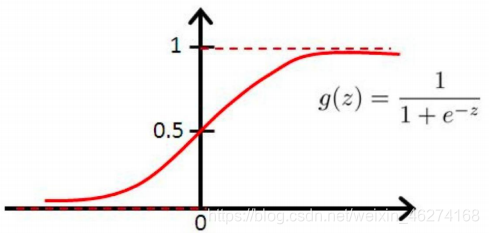
坐标回归的预测值都在 0~1 之间. 如果左边落在了边界就很难达到.
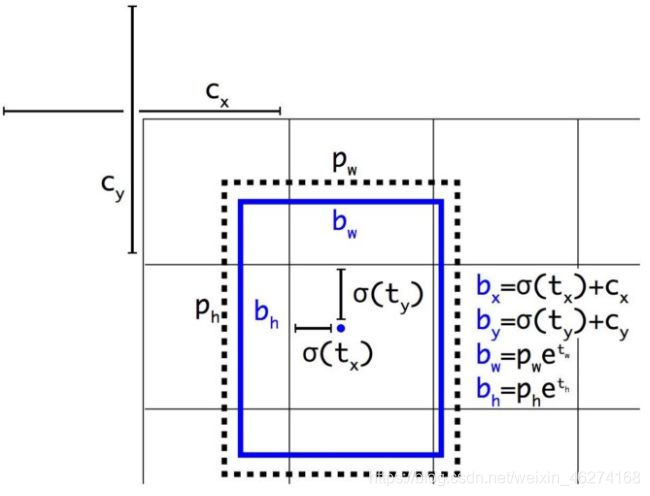
当 bx=cx 和 bx=cx+1 这两种情况, 按照 Sigmod 激活函数必须得到一个极大的负值或正值才能使得 损失很小. 但如果修改公式使 σ 乘以一个系数, 那么要得到较小的损失则容易得多.
公式:
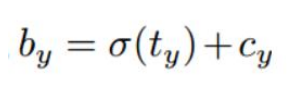

【百变AI秀】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/296704

- 点赞
- 收藏
- 关注作者
评论(0)