小白都能看懂的简单爬虫入门案例剖析(爬虫入门看它就够了!)

目录
Hello!大家好,我是努力赚钱买生发水的灰小猿,很多学习了Python的小伙伴都希望可以拥有一条属于自己的爬虫,所以今天大灰狼就来和小伙伴们分享一下简单的爬虫程序编写。
允许我在这里为小伙伴们卖一下关子哈。
什么是网络爬虫?
所谓网络爬虫,简单来说,就是通过程序来打开特定的网页并且爬取网页上存在的某些信息。想象一下,把一个网页比作一片田地的话,爬虫就是生活在这片田地里,从田头爬到田尾,并且只捕食这片田地上某一类食物的昆虫。哈哈,比喻有些糙,但网络爬虫的实际作用也就跟这个差不多啦。
想深入了解的小伙伴也可以看我的这篇文章“Python一分钟带你探秘不为人知的网络昆虫!”啦!
爬虫的原理是什么?
那可能有小伙伴就问了,爬虫程序是如何工作的呢?
举个栗子:
我们所看到的所有的网页都是由特定的代码组成的,这些代码中涵盖了这个网页中所存在的所有信息,在我们打开某一个网页的时候,按F12键就可以看到这个网页的代码了,我们以百度图片搜索皮卡丘的网页为例,按F12后,就可以看到如下的涵盖整个网页所有内容的代码了。
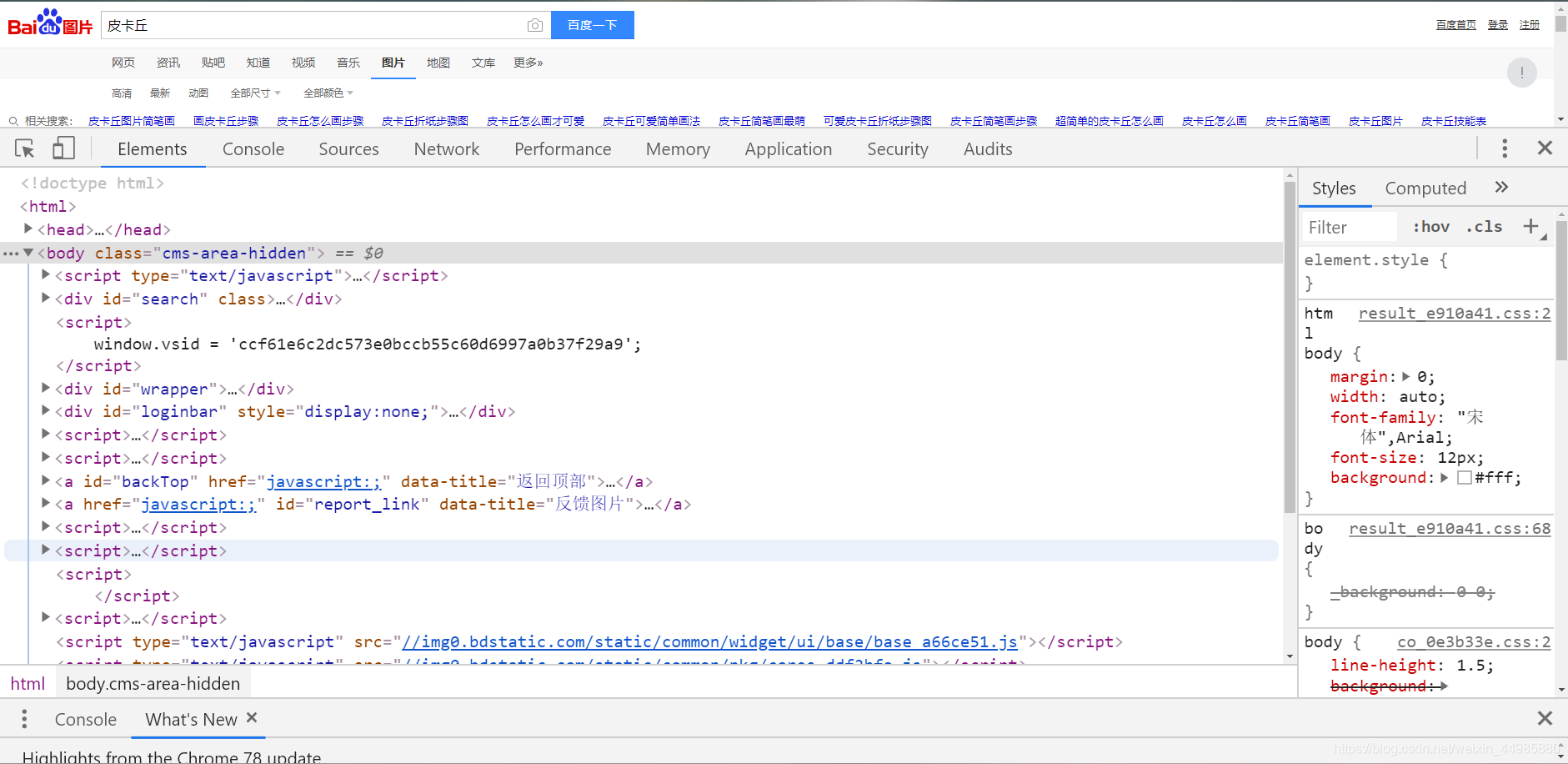
以一条爬取“皮卡丘图片”的爬虫为例,我们的爬虫要爬取这个网页上所有的皮卡丘图片,所以我们的爬虫要做的就是,找到这个网页的代码中包括皮卡丘图片的链接,并且将这个链接下的图片下载。
所以爬虫的工作原理就是从网页的代码中找到并提取出特定的代码,就好比从一个很长的字符串中找到特定格式的字符串是一样的,对这一块知识感兴趣的小伙伴也可以阅读我的这篇文章“Python实战之特定文本提取,挑战高效办公的第一步”,
了解了以上两点之后,就是如何去编写这样一条爬虫了。
Python爬虫常用的第三方模块有urllib2和requests,大灰狼个人认为urllib2模块要比requests模块复杂些,所以在这里以requests模块为例来编写爬虫程序。
以爬取百度皮卡丘图片为例。
根据爬虫的原理,我们的爬虫程序要做的依次是:
- 获取百度图片中“皮卡丘图片”的网页链接
- 获取该网页的全部代码
- 查找代码中图片的链接
- 根据图片链接写出通用的正则表达式
- 通过设定的正则表达式匹配代码中所有符合要求的图片链接
- 逐个打开图片链接并将图片下载
接下来大灰狼就根据上面的步骤为大家分享一下这条爬虫的编写:
1、获取百度图片中“皮卡丘图片”的网页链接
首先我们打开百度图片的网页链接https://image.baidu.com/

之后再打开关键字搜索“皮卡丘”后的链接
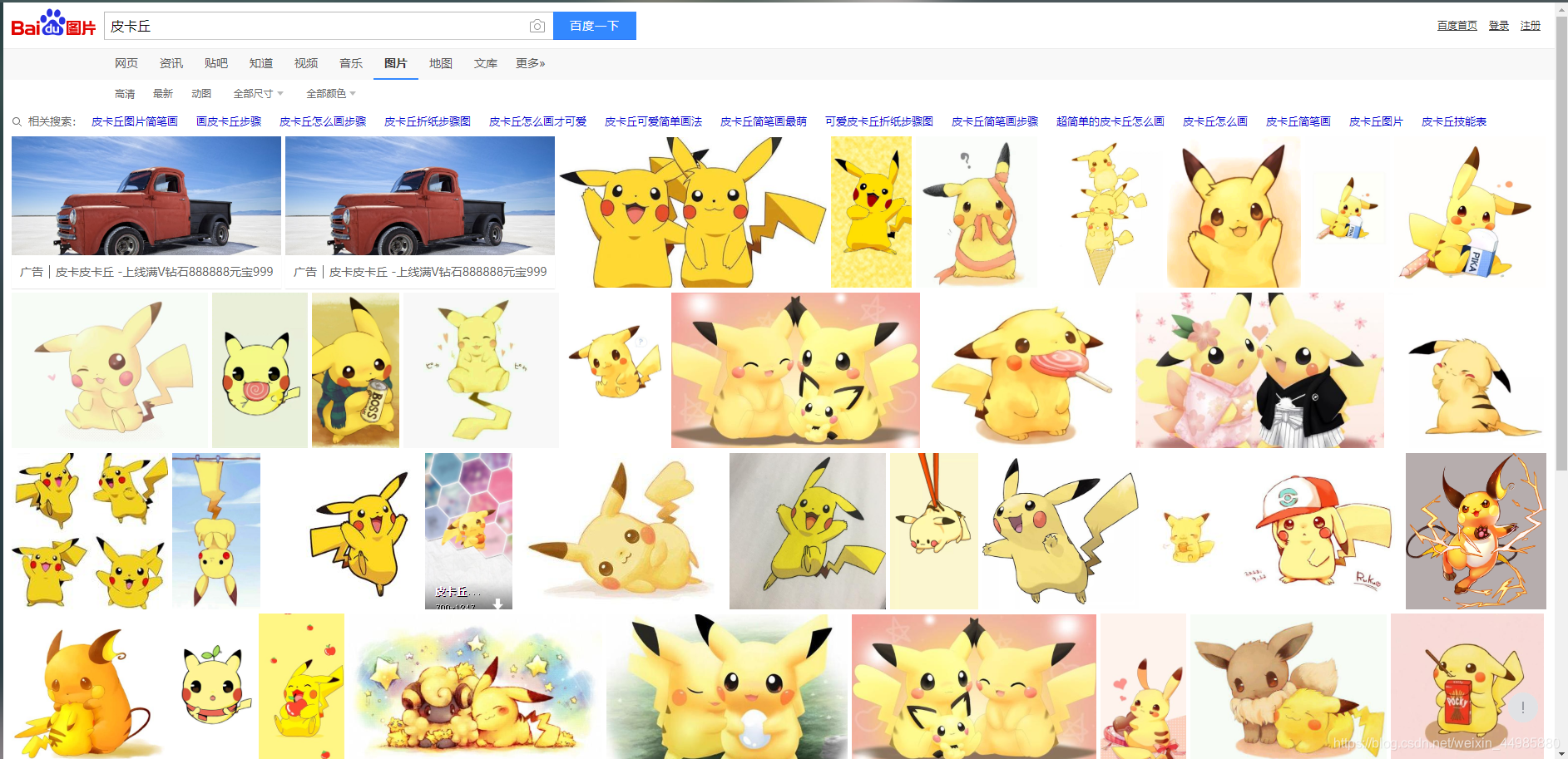
对比一下,剔除多余部分,我们就可以得到百度图片关键词搜索的通用链接长这样:http://image.baidu.com/search/index?tn=baiduimage&word=关键字
现在我们的第一步获取百度图片中“皮卡丘图片”的网页链接已经完成了,接下来就是获取该网页的全部代码
2、获取该网页的全部代码
这个时候,我们可以先使用requests模块下的get()函数打开该链接
然后通过模块中的text函数获取到网页的文本,也就是全部的代码。
url = "http://image.baidu.com/search/index?tn=baiduimage&word=皮卡丘"
urls = requests.get(url) #打开链接
urltext = urls.text #获取链接文本3、查找代码中图片的链接
这一步我们可以先打开该网页链接,按照最开始大灰狼说的方法按下F12查看该网页的全部代码,然后如果说我们要爬取全部的jpg格式的图片,我们可以再按下Ctrl+F查找特定内容的代码,
如我们在该网页的代码中找到带有jpg的代码,然后找到类似于下图这样的代码,
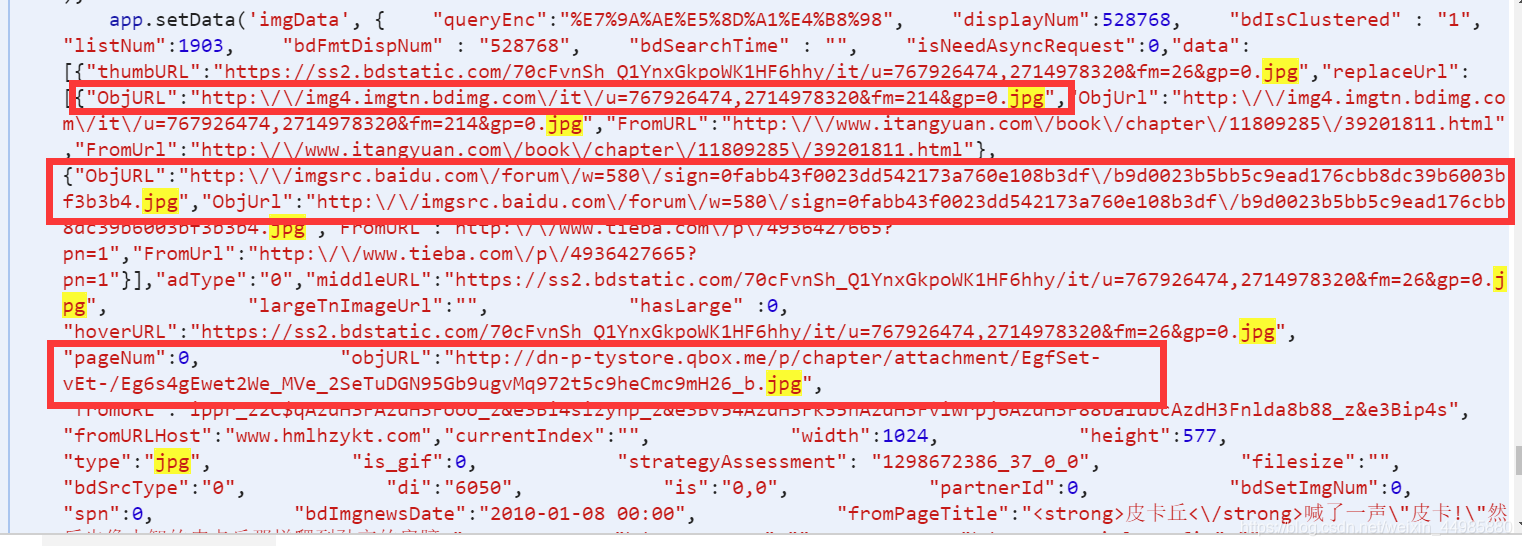
其中的链接就是我们要获取到内容,我们仔细观察这几个链接就会发现它们的相同之处,也就是它们每一个链接前都会有”OpjURL”:进行提示,最后以”进行结尾,
并且我们拿出其中一个链接
http://dnptystore.qbox.me/p/chapter/attachment/EgfSetvEt-/Eg6s4gEwet2We_MVe_2SeTuDGN95Gb9ugvMq972t5c9heCmc9mH26_b.jpg
进行访问,发现也是可以打开该图片的。
所以我们就可以暂时的推断出百度图片中jpg图片的通用格式为“”OpjURL”:XXXX””,
4、根据图片链接写出通用的正则表达式
现在我们已经知道了该类型图片的通用格式为“”OpjURL”:XXXX””,那么接下来就是根据该格式进行正则表达式的书写。
urlre = re.compile('"objURL":"(.*?)"', re.S)
# 其中re.S的作用是让正则表达式中的“.”可以匹配所有的“\n”换行符。对正则表达式使用不了解的小伙伴也可以看我的这两篇文章“Python教程之正则表达式(基础篇)”和“Python教程之正则表达式(提高篇)”
5、通过设定的正则表达式匹配代码中所有符合要求的图片链接
我们在上面已经写好了图片链接的正则表达式,接下来就是通过该正则表达式对全部代码进行匹配了,并且获取到所有链接的列表
urllist = re.findall(urltext)
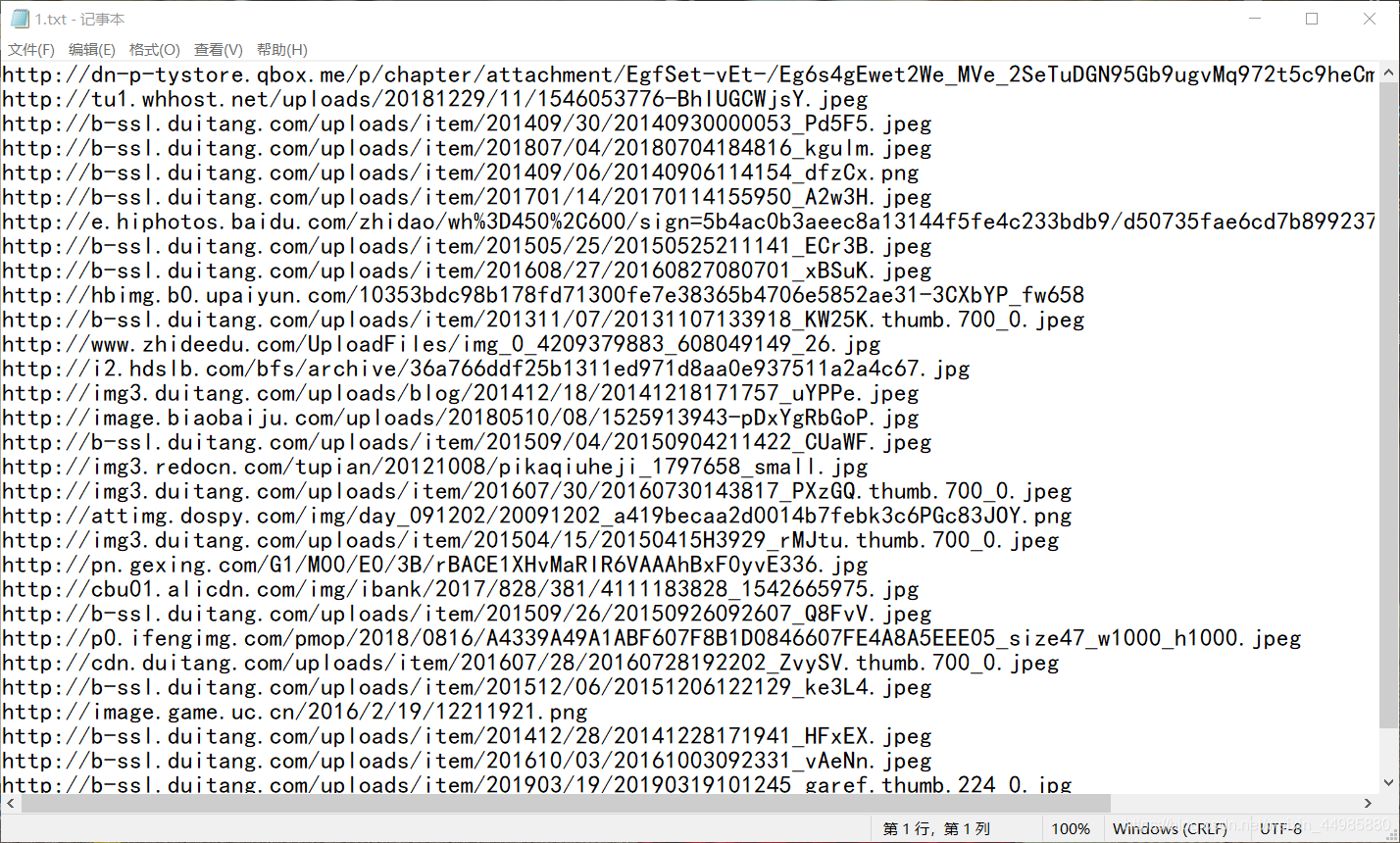
#获取到图片链接的列表,其中的urltext为整个页面的全部代码,接下来我们用几行代码对我们通过正在表达式匹配到的图片链接进行一下验证,将匹配到的所有链接写入txt文件:
with open("1.txt", "w") as txt:
for i in urllist:
txt.write(i + "\n")之后我们在这个文件下就可以看到已经匹配到的图片链接,随便复制一个都是可以打开的。
6、逐个打开图片链接并将图片下载
现在我们已经将所有的图片的链接存放到了列表之中,接下来就是将图片下载即可。
基本思路是:通过for循环遍历列表中的所有链接,以二进制的方式打开该链接,新建一个.jpg文件,将我们的图片以二进制的形式写入该文件。
在这里我们为了避免下载过快,在每次下载前休眠三秒钟,并且每个链接的访问时间最多为5秒,如果超过五秒的访问时间,我们就判定下载失败,继续下载下一章图片。
至于为什么以二进制的方式打开和写入图片,是因为我们的图片需要先用二进制的方式进行解析,然后才能被计算机写入。
下载图片的代码如下,下载张数设定为3张:
i = 0
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout = 5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i+1), urlimg))
imgs.write(img) #将图片写入
i += 1
if i == 3: #为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")现在,一个简单的爬取百度皮卡丘图片的爬虫就完成了,小伙伴也可以任意更改图片关键字和下载张数,培养一只属于自己的爬虫。
最后附上完整源码:
import requests
import re
import time
url = "http://image.baidu.com/search/index?tn=baiduimage&word=皮卡丘"
s = requests.session()
s.headers['User-Agent']='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
urls = s.get(url).content.decode('utf-8')
# urls = requests.get(url) # 打开链接
# requests.get(url="https://www.baidu.com/")
urltext = urls # 获取链接全部文本
urlre = re.compile('"objURL":"(.*?)"', re.S) # 书写正则表达式
urllist = urlre.findall(urltext) # 通过正则进行匹配
with open("1.txt", "w") as txt: # 将匹配到的链接写入文件
for i in urllist:
txt.write(i + "\n")
i = 0
# 循环遍历列表并下载图片
for urlimg in urllist:
time.sleep(3) # 程序休眠三秒
img = requests.get(urlimg, timeout=5).content # 以二进制形式打开图片链接
if img:
with open(str(i) + ".jpg", "wb") as imgs: # 新建一个jpg文件,以二进制写入
print("正在下载第%s张图片 %s" % (str(i + 1), urlimg))
imgs.write(img) # 将图片写入
i += 1
if i == 5: # 为了避免无限下载,在这里设定下载图片为3张
break
else:
print("下载失败!")
print("下载完毕!")
觉得有用记得点赞关注哟!
同时你也可以关注我的微信公众号“灰狼洞主”,回复 “Python笔记”获取Python从入门到精通笔记分享和常用函数方法速查手册!
大灰狼期待与你一同进步!


- 点赞
- 收藏
- 关注作者
评论(0)