Python 3.9:很酷的新功能供您试用

Python 3.9 来了!在过去的一年里,来自世界各地的志愿者一直致力于改进 Python。虽然测试版已经推出一段时间了,但 Python 3.9 的第一个官方版本于2020年10 月 5 日发布。
Python 的每个版本都包含新的、改进的和弃用的功能,Python 3.9 也不例外。该文档提供了完整的更改列表。下面,您将深入了解最新版本的 Python 带来的最酷的功能。
在本教程中,您将了解:
- 访问和计算时区
- 有效地合并和更新字典
- 使用基于表达式的装饰器
- 结合类型提示和其他注解
要自己试用新功能,您需要安装 Python 3.9。您可以从Python 主页下载并安装它。或者,您可以使用官方 Docker 映像进行试用。有关更多详细信息,请参阅在 Docker 中运行 Python 版本:如何尝试最新的 Python 版本。
正确的时区支持
Python 广泛支持通过datetime标准库中的模块处理日期和时间。但是,对使用时区的支持有些缺乏。到目前为止,推荐的处理时区的方法是使用第三方库,如dateutil.
在纯 Python 中处理时区的最大挑战是您必须自己实现时区规则。Adatetime支持设置时区,但只有UTC是立即可用的。其他时区需要在抽象tzinfo基类之上实现。
访问时区
您可以从库中获取UTC 时间戳,datetime如下所示:
>>> from datetime import datetime, timezone
>>> datetime.now(tz=timezone.utc)
datetime.datetime(2020, 9, 8, 15, 4, 15, 361413, tzinfo=datetime.timezone.utc)
请注意,生成的时间戳是时区感知的。它具有由 指定的附加时区tzinfo。没有任何时区信息的时间戳称为naive。
Paul Ganssle多年来一直是 的维护者dateutil。他于 2019 年加入 Python 核心开发人员,并帮助添加了一个新的zoneinfo标准库,使处理时区变得更加方便。
zoneinfo提供对互联网号码分配机构 (IANA)时区数据库的访问。IANA每年都会多次更新其数据库,它是最权威的时区信息来源。
使用zoneinfo,您可以获得描述数据库中任何时区的对象:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
zoneinfo.ZoneInfo(key='America/Vancouver')
您可以使用多个键之一访问时区。在这种情况下,您使用"America/Vancouver".
注意: zoneinfo使用驻留在本地计算机上的 IANA 时区数据库。有可能——特别是在 Windows 上——你没有任何这样的数据库或者zoneinfo无法找到它。如果您收到类似以下的错误,则表示zoneinfo无法找到时区数据库:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZoneInfoNotFoundError: 'No time zone found with key America/Vancouver'
IANA 时区数据库的 Python 实现可在PyPI 上以tzdata. 您可以使用以下命令安装它pip:
$ python -m pip install tzdata
一旦tzdata被安装,zoneinfo应该能够了解所有支持的时区信息。tzdata由 Python 核心团队维护。请注意,您需要保持包更新才能访问 IANA 时区数据库中的最新更改。
您可以使用tz或tzinfo函数参数制作时区感知时间戳datetime:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> datetime.now(tz=ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 9, 8, 17, 12, 0, 939001,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
>>> datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
datetime.datetime(2020, 10, 5, 3, 9,
tzinfo=zoneinfo.ZoneInfo(key='America/Vancouver'))
使用时间戳记录时区非常适合记录保存。它还可以方便地在时区之间进行转换:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
>>> release.astimezone(ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 10, 5, 12, 9,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
请注意,奥斯陆的时间比温哥华的时间晚九个小时。
调查时区
IANA 时区数据库非常庞大。您可以使用zoneinfo.available_timezones()以下命令列出所有可用的时区:
>>> import zoneinfo
>>> zoneinfo.available_timezones()
{'America/St_Lucia', 'SystemV/MST7', 'Asia/Aqtau', 'EST', ... 'Asia/Beirut'}
>>> len(zoneinfo.available_timezones())
609
数据库中的时区数量可能因您的安装而异。在此示例中,您可以看到609列出了时区名称。这些时区中的每一个都记录了发生的历史变化,您可以更仔细地查看它们中的每一个。
Kiritimati,也被称为圣诞岛,目前位于世界上最西端的时区,UTC+14。情况并非总是如此。1995 年之前,该岛位于国际日期变更线的另一边,UTC-10。为了穿越日期变更线,Kiritimati 完全跳过了 1994 年 12 月 31 日。
您可以通过仔细查看"Pacific/Kiritimati"时区对象来了解这是如何发生的:
>>> from datetime import datetime, timedelta
>>> from zoneinfo import ZoneInfo
>>> hour = timedelta(hours=1)
>>> tz_kiritimati = ZoneInfo("Pacific/Kiritimati")
>>> ts = datetime(1994, 12, 31, 9, 0, tzinfo=ZoneInfo("UTC"))
>>> ts.astimezone(tz_kiritimati)
datetime.datetime(1994, 12, 30, 23, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
>>> (ts + 1 * hour).astimezone(tz_kiritimati)
datetime.datetime(1995, 1, 1, 0, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
1994 年 12 月 30 日 23:00,在基里蒂马蒂,新的一年开始了。1994 年 12 月 31 日,从未发生过!
您还可以看到与 UTC 的偏移量发生了变化:
>>> tz_kiritimati.utcoffset(datetime(1994, 12, 30)) / hour
-10.0
>>> tz_kiritimati.utcoffset(datetime(1995, 1, 1)) / hour
14.0
.utcoffset()返回一个timedelta. 计算给定值代表多少小时的最有效方法timedelta是将其除以timedelta代表一小时的时间。
关于时区还有许多其他奇怪的故事。Paul Ganssle 在他的 PyCon 2019 演讲中介绍了其中的一些,使用时区:你希望你不需要知道的一切。看看您是否可以在时区数据库中找到任何其他人的踪迹。
使用最佳实践
处理时区可能很棘手。然而,随着zoneinfo标准库中的 可用,它变得更容易一些。在处理日期和时间时,请牢记以下几点建议:
-
会议时间、火车出发时间或音乐会时间等民用时间最好存储在其本地时区。您通常可以通过将一个简单的时间戳与时区的 IANA 密钥一起存储来做到这一点。以字符串形式存储的民用时间的一个示例是
"2020-10-05T14:00:00,Europe/Oslo". 拥有有关时区的信息可确保您始终可以恢复信息,即使时区本身发生变化。 -
时间戳代表特定的时刻,通常记录事件的顺序。计算机日志就是一个例子。您不希望您的日志仅仅因为您的时区从夏令时更改为标准时间而变得混乱。通常,您会将这些类型的时间戳存储为 UTC 中的原始日期时间。
由于 IANA 时区数据库一直在更新,因此您应该注意保持本地时区数据库同步。如果您正在运行任何对时区敏感的应用程序,这一点尤其重要。
在 Mac 和 Linux 上,您通常可以信任您的系统来保持本地数据库更新。如果你依赖tzdata包,那么你应该记得不时更新它。特别是,您不应该将其固定在一个特定版本上多年。
像这样的名称可以"America/Vancouver"让您明确访问给定的时区。但是,在向用户传达时区感知日期时间时,最好使用常规时区名称。这些.tzname()在时区对象上可用:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> tz = ZoneInfo("America/Vancouver")
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=tz)
>>> f"Release date: {release:%b %d, %Y at %H:%M} {tz.tzname(release)}"
'Release date: Oct 05, 2020 at 03:09 PDT'
您需要向 提供时间戳.tzname()。这是必要的,因为时区的名称可能会随着时间的推移而改变,例如夏令时:
>>> tz.tzname(datetime(2021, 1, 28))
'PST'
冬季,温哥华使用太平洋标准时间 (PST),而夏季使用太平洋夏令时 (PDT)。
zoneinfo仅在 Python 3.9 及更高版本的标准库中可用。但是,如果您使用的是早期版本的 Python,那么您仍然可以利用zoneinfo. PyPI上提供了一个 backport ,可以通过以下方式安装pip:
$ python -m pip install backports.zoneinfo
然后,您可以在导入时使用以下习语zoneinfo:
try:
import zoneinfo
except ImportError:
from backports import zoneinfo
这使您的程序与 3.6 及更高版本的所有 Python 版本兼容。有关的更多详细信息,请参阅PEP 615zoneinfo。
更简单的字典更新
字典是 Python 中的基本数据结构之一。它们在语言中随处可见,并且随着时间的推移得到了相当大的优化。
有多种方法可以合并两个字典。但是,语法有点神秘或繁琐:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> {**pycon, **europython}
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> merged = pycon.copy()
>>> for key, value in europython.items():
... merged[key] = value
...
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
这两种方法都在不改变原始数据的情况下合并字典。请注意,"Cleveland"已被"Edinburgh"in覆盖merged。您还可以就地更新字典:
>>> pycon.update(europython)
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
但是,这会更改您的原始字典。请记住,.update()它不会返回更新后的字典,因此.update()在保持原始数据不变的情况下使用的巧妙尝试效果不佳:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> merged = pycon.copy().update(europython) # Does NOT work
>>> print(merged)
None
注意merged是None,虽然两个库合并,这一结果已经被扔掉了。您可以使用Python 3.8 中引入的walrus 运算符( :=)来完成这项工作:
>>> (merged := pycon.copy()).update(europython)
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
尽管如此,这并不是一个特别易读或令人满意的解决方案。
基于PEP 584,新版本的 Python 为字典引入了两个新的运算符:union ( |) 和in-place union ( |=)。您可以使用|合并两个字典,同时|=将更新一个字典:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> pycon | europython
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> pycon |= europython
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
如果d1和d2是两个字典,则d1 | d2与{**d1, **d2}. 该|操作是用于计算的套工会,所以符号可能已经很熟悉了。
使用的一个优点|是它适用于不同的类似字典的类型,并通过合并保持类型:
>>> from collections import defaultdict
>>> europe = defaultdict(lambda: "", {"Norway": "Oslo", "Spain": "Madrid"})
>>> africa = defaultdict(lambda: "", {"Egypt": "Cairo", "Zimbabwe": "Harare"})
>>> europe | africa
defaultdict(<function <lambda> at 0x7f0cb42a6700>,
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'})
>>> {**europe, **africa}
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}
defaultdict当您想有效地处理丢失的键时,您可以使用 a 。请注意,|保留defaultdict, 而{**europe, **africa}不会。
|字典的+工作方式和列表的工作方式有一些相似之处。事实上,+operator最初也被提议合并字典。当您查看就地运算符时,这种对应关系变得更加明显。
的基本用途|=是就地更新字典,类似于.update():
>>> libraries = {
... "collections": "Container datatypes",
... "math": "Mathematical functions",
... }
>>> libraries |= {"zoneinfo": "IANA time zone support"}
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support'}
当您将字典与 合并时|,两个字典都需要是正确的字典类型。另一方面,就地运算符 ( |=) 很乐意处理任何类似字典的数据结构:
>>> libraries |= [("graphlib", "Functionality for graph-like structures")]
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support',
'graphlib': 'Functionality for graph-like structures'}
在此示例中,您libraries从 2 元组列表进行更新。当您要合并的两个字典中有重叠的键时,保留最后一个值:
>>> asia = {"Georgia": "Tbilisi", "Japan": "Tokyo"}
>>> usa = {"Missouri": "Jefferson City", "Georgia": "Atlanta"}
>>> asia | usa
{'Georgia': 'Atlanta', 'Japan': 'Tokyo', 'Missouri': 'Jefferson City'}
>>> usa | asia
{'Missouri': 'Jefferson City', 'Georgia': 'Tbilisi', 'Japan': 'Tokyo'}
在第一个示例中,"Georgia"指向"Atlanta"因为usa是合并中的最后一个字典。"Tbilisi"来自的值asia已被覆盖。请注意,键"Georgia"仍然是结果字典中的第一个,因为它是asia. 反转合并的顺序会改变 的位置和值"Georgia"。
运营商|和|=已加入不仅定期字典也让许多类似字典类,包括UserDict,ChainMap,OrderedDict,defaultdict,WeakKeyDictionary,WeakValueDictionary,_Environ,和MappingProxyType。他们没有被添加到抽象基类Mapping或MutableMapping。该Counter容器已经使用|查找最大计数。这没有改变。
你可以改变的行为|,并|=通过实施.__or__()和.__ior__()分别。有关更多详细信息,请参阅PEP 584。
更灵活的装饰器
传统上,装饰器必须是一个命名的、可调用的对象,通常是一个函数或一个类。PEP 614允许装饰器是任何可调用的表达式。
大多数人不认为旧的装饰器语法是有限制的。事实上,放松装饰器的语法主要有助于一些小众用例。根据 PEP,激励用例与GUI 框架中的回调有关。
PyQT使用信号和槽将小部件与回调连接起来。从概念上讲,您可以执行以下操作来将clicked信号连接button到插槽say_hello():
button = QPushButton("Say hello")
@button.clicked.connect
def say_hello():
message.setText("Hello, World!")
Hello, World!当您单击Say hello按钮时,这将显示文本。
注意:这不是一个完整的示例,如果您尝试运行它,它将引发错误。它故意保持简短以将重点放在装饰器上,而不是陷入 PyQT 工作原理的细节中。
有关 PyQT 入门和设置完整应用程序的更多信息,请参阅Python 和 PyQt:构建 GUI 桌面计算器。
现在假设您有几个按钮,为了跟踪它们,您将它们存储在字典中:
buttons = {
"hello": QPushButton("Say hello"),
"leave": QPushButton("Goodbye"),
"calculate": QPushButton("3 + 9 = 12"),
}
这一切都很好。但是,如果您想使用装饰器将按钮连接到插槽,这会给您带来挑战。在早期版本的 Python 中,您无法在使用装饰器时使用方括号访问项目。您需要执行以下操作:
hello_button = buttons["hello"]
@hello_button.clicked.connect
def say_hello():
message.setText("Hello, World!")
在 Python 3.9 中,取消了这些限制,您现在可以使用任何表达式,包括访问字典中的项目:
@buttons["hello"].clicked.connect
def say_hello():
message.setText("Hello, World!")
虽然这不是一个很大的变化,但它允许您在少数情况下编写更清晰的代码。扩展的语法还可以更轻松地在运行时动态选择装饰器。假设您有以下装饰器可用:
# story.py
import functools
def normal(func):
return func
def shout(func):
@functools.wraps(func)
def shout_decorator(*args, **kwargs):
return func(*args, **kwargs).upper()
return shout_decorator
def whisper(func):
@functools.wraps(func)
def whisper_decorator(*args, **kwargs):
return func(*args, **kwargs).lower()
return whisper_decorator
该@normal装饰完全不改变原有的功能,而@shout和@whisper提出的是从函数大写或小写返回任何文本。然后,您可以将这些装饰器的引用存储在字典中并使它们可供用户使用:
# story.py (continued)
DECORATORS = {"normal": normal, "shout": shout, "whisper": whisper}
voice = input(f"Choose your voice ({', '.join(DECORATORS)}): ")
@DECORATORS[voice]
def get_story():
return """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into
the book her sister was reading, but it had no pictures or
conversations in it, "and what is the use of a book," thought Alice
"without pictures or conversations?"
"""
print(get_story())
当您运行此脚本时,系统会询问您将哪个装饰器应用于story。然后将结果文本打印到屏幕上:
$ python3.9 story.py
Choose your voice (normal, shout, whisper): shout
ALICE WAS BEGINNING TO GET VERY TIRED OF SITTING BY HER SISTER ON THE
BANK, AND OF HAVING NOTHING TO DO: ONCE OR TWICE SHE HAD PEEPED INTO
THE BOOK HER SISTER WAS READING, BUT IT HAD NO PICTURES OR
CONVERSATIONS IN IT, "AND WHAT IS THE USE OF A BOOK," THOUGHT ALICE
"WITHOUT PICTURES OR CONVERSATIONS?"
此示例与@shout应用于get_story(). 但是,这里它已根据您的输入在运行时应用。与按钮示例一样,您可以通过使用临时变量在早期版本的 Python 中实现相同的效果。
有关装饰器的更多信息,请查看Python 装饰器入门。有关宽松语法的更多详细信息,请参阅PEP 614。
带注释的类型提示
Python 3.0中引入了函数注释。该语法支持向 Python 函数添加任意元数据。下面是一个向公式添加单位的示例:
# calculator.py
def speed(distance: "feet", time: "seconds") -> "miles per hour":
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
在此示例中,注释仅用作读者的文档。稍后您将看到如何在运行时访问注释。
PEP 484建议对类型提示使用注解。随着类型提示越来越流行,它们几乎排挤了 Python 中注释的任何其他用途。
由于静态类型之外的注释有几个用例,PEP 593引入了typing.Annotated,您可以使用它来将类型提示与其他信息结合起来。你可以calculator.py像这样重做上面的例子:
# calculator.py
from typing import Annotated
def speed(
distance: Annotated[float, "feet"], time: Annotated[float, "seconds"]
) -> Annotated[float, "miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Annotated至少需要两个参数。第一个参数是常规类型提示,其余参数是任意元数据。类型检查器只关心第一个参数,将元数据的解释留给您和您的应用程序。类似的类型提示Annotated[float, "feet"]将被float类型检查器同等对待。
您可以.__annotations__像往常一样访问注释。进口speed()自calculator.py:
>>> from calculator import speed
>>> speed.__annotations__
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
每个注释都可以在字典中找到。您定义的元数据Annotated存储在.__metadata__:
>>> speed.__annotations__["distance"].__metadata__
('feet',)
>>> {var: th.__metadata__[0] for var, th in speed.__annotations__.items()}
{'distance': 'feet', 'time': 'seconds', 'return': 'miles per hour'}
最后一个示例通过读取每个变量的第一个元数据项来挑选出所有单元。在运行时访问类型提示的另一种方法是get_type_hints()从typing模块中使用。get_type_hints()默认情况下将忽略元数据:
>>> from typing import get_type_hints
>>> from calculator import speed
>>> get_type_hints(speed)
{'distance': <class 'float'>,
'time': <class 'float'>,
'return': <class 'float'>}
这应该允许大多数在运行时访问类型提示的程序无需更改即可继续工作。您可以使用新的可选参数include_extras来请求包含元数据:
>>> get_type_hints(speed, include_extras=True)
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
使用Annotated可能会导致非常冗长的代码。保持代码简短易读的一种方法是使用类型别名。您可以定义表示注释类型的新变量:
# calculator.py
from typing import Annotated
Feet = Annotated[float, "feet"]
Seconds = Annotated[float, "seconds"]
MilesPerHour = Annotated[float, "miles per hour"]
def speed(distance: Feet, time: Seconds) -> MilesPerHour:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
类型别名的设置可能需要一些工作,但它们可以使您的代码非常清晰易读。
如果您有一个广泛使用注释的应用程序,您还可以考虑实现一个注释工厂。将以下内容添加到 的顶部calculator.py:
# calculator.py
from typing import Annotated
class AnnotationFactory:
def __init__(self, type_hint):
self.type_hint = type_hint
def __getitem__(self, key):
if isinstance(key, tuple):
return Annotated[(self.type_hint, ) + key]
else:
return Annotated[self.type_hint, key]
def __repr__(self):
return f"{self.__class__.__name__}({self.type_hint})"
AnnotationFactory可以创建Annotated具有不同元数据的对象。您可以使用注释工厂来创建更多动态别名。更新calculator.py使用AnnotationFactory:
# calculator.py (continued)
Float = AnnotationFactory(float)
def speed(
distance: Float["feet"], time: Float["seconds"]
) -> Float["miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Float[<metadata>]代表Annotated[float, <metadata>],所以这个例子与前两个例子完全一样。
更强大的 Python 解析器
Python 3.9 最酷的功能之一是您在日常编码生活中不会注意到的功能。Python 解释器的一个基本组件是parser。在最新版本中,解析器已被重新实现。
从一开始,Python 就使用基本的LL(1) 解析器将源代码解析为解析树。您可以将 LL(1) 解析器视为一次读取一个字符并弄清楚如何在不回溯的情况下解释源代码的解析器。
使用简单解析器的一个优点是它的实现和推理相当简单。一个缺点是您需要通过特殊黑客来规避一些困难的情况。
在一系列博客文章中,Python 的创造者 Guido van Rossum 研究了PEG(解析表达式语法)解析器。PEG 解析器比 LL(1) 解析器更强大,并且不需要特殊的 hack。作为 Guido 研究的结果,在 Python 3.9 中实现了一个 PEG 解析器。有关更多详细信息,请参阅PEP 617。
新的 PEG 解析器的目标是生成与旧的 LL(1) 解析器相同的抽象语法树 (AST)。最新版本实际上附带了两个解析器。虽然 PEG 解析器是默认的,但您可以通过-X oldparser命令行标志使用旧的解析器运行您的程序:
$ python -X oldparser script_name.py
或者,您可以设置PYTHONOLDPARSER环境变量。
旧的解析器将在Python 3.10 中删除。这将允许新功能不受 LL(1) 语法的限制。目前正在考虑包含在 Python 3.10 中的此类功能之一是结构模式匹配,如PEP 622 中所述。
让两个解析器都可用非常适合验证新的 PEG 解析器。您可以在两个解析器上运行任何代码并在 AST 级别进行比较。在测试过程中,对整个标准库以及许多流行的第三方包进行了编译和比较。
您还可以比较两个解析器的性能。通常,PEG 解析器和 LL(1) 的性能相似。在整个标准库中,PEG 解析器稍微快一点,但它也使用更多的内存。实际上,在使用新解析器时,您不应注意到性能的任何变化,无论好坏。
其他非常酷的功能
到目前为止,您已经看到了 Python 3.9 中最大的新特性。但是,Python 的每个新版本也包含许多小的更改。该官方文档包括所有这些更改的列表。在本节中,您将了解一些可以开始使用的其他非常酷的新功能。
字符串前缀和后缀
如果您需要删除字符串的开头或结尾,那么.strip()它似乎可以完成这项工作:
>>> "three cool features in Python".strip(" Python")
'ree cool features i'
后缀" Python"已被删除,但"th"在字符串的开头也已删除。的实际行为.strip()有时令人惊讶——并且引发了许多 错误 报告。很自然地假设这.strip(" Python")将删除子字符串" Python",但它会删除单个字符" ", "P", "y", "t", "h", "o", and "n"。
要实际删除字符串后缀,您可以执行以下操作:
>>> def remove_suffix(text, suffix):
... if text.endswith(suffix):
... return text[:-len(suffix)]
... else:
... return text
...
>>> remove_suffix("three cool features in Python", suffix=" Python")
'three cool features in'
这效果更好,但有点麻烦。这段代码也有一个微妙的错误:
>>> remove_suffix("three cool features in Python", suffix="")
''
如果后缀恰好是空字符串,则不知何故整个字符串已被删除。这是因为空字符串的长度是 0,所以text[:0]最终会被返回。您可以通过将测试改写为 on 来解决此问题suffix and text.endswith(suffix)。
在 Python 3.9 中,有两个新的字符串方法可以解决这个确切的用例。您可以使用.removeprefix()和.removesuffix()分别删除字符串的开头或结尾:
>>> "three cool features in Python".removesuffix(" Python")
'three cool features in'
>>> "three cool features in Python".removeprefix("three ")
'cool features in Python'
>>> "three cool features in Python".removeprefix("Something else")
'three cool features in Python'
请注意,如果给定的前缀或后缀与字符串不匹配,那么您将原封不动地恢复字符串。
.removeprefix()并.removesuffix()删除最多一份词缀副本。如果您想确保删除所有这些,那么您可以使用while循环:
>>> text = "Waikiki"
>>> text.removesuffix("ki")
'Waiki'
>>> while text.endswith("ki"):
... text = text.removesuffix("ki")
...
>>> text
'Wai'
有关和 的更多信息,请参阅PEP 616。.removeprefix().removesuffix()
直接键入提示列表和字典
它通常是很简单添加类型提示为基本类型,如str,int和bool。您直接使用类型进行注释。这种情况与您自己创建的自定义类型类似:
radius: float = 3.9
class NothingType:
pass
nothing: NothingType = NothingType()
泛型是一个不同的故事。泛型类型通常是可以参数化的容器,例如数字列表。由于技术原因,在以前的 Python 版本中,您无法使用list[float]或list(float)作为类型提示。相反,您需要从typing模块导入不同的列表对象:
from typing import List
numbers: List[float]
在 Python 3.9 中,不再需要这种并行层次结构。您现在终于可以使用list正确的类型提示了:
numbers: list[float]
这将使您的代码更易于编写并消除同时具有list和的混淆List。将来,使用typing.List和类似的泛型,例如typing.Dict和typing.Type将被弃用,并且泛型最终将从typing.
如果您需要编写与旧版本 Python 兼容的代码,那么您仍然可以通过使用Python 3.7 中提供的__future__导入来利用新语法。在 Python 3.7 中,您通常会看到如下内容:
>>> numbers: list[float]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
但是,使用__future__导入使此示例工作:
>>> from __future__ import annotations
>>> numbers: list[float]
>>> __annotations__
{'numbers': 'list[float]'}
这是有效的,因为注释不是在运行时评估的。如果您尝试评估注释,那么您仍然会遇到TypeError. 有关此新语法的更多信息,请参阅PEP 585。
拓扑排序
由节点和边组成的图可用于表示不同类型的数据。例如,当您使用pip从PyPI安装包时,该包可能依赖于其他包,而这些包又可能具有更多依赖项。
这种结构可以用一个图来表示,其中每个包都是一个节点,每个依赖项都由一条边表示:
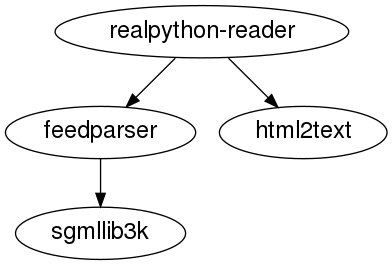
该图显示了realpython-reader包的依赖关系。它直接依赖于feedparser和html2text,而feedparser反过来又依赖于sgmllib3k。
假设您要按顺序安装这些包,以便始终满足所有依赖项。然后,您将执行所谓的拓扑排序来查找依赖项的总顺序。
Python 3.9graphlib在标准库中引入了一个新模块 ,用于进行拓扑排序。您可以使用它来查找集合的总顺序,或者考虑可以并行化的任务进行更高级的调度。要查看示例,您可以在字典中表示较早的依赖项:
>>> dependencies = {
... "realpython-reader": {"feedparser", "html2text"},
... "feedparser": {"sgmllib3k"},
... }
...
这表达了您在上图中看到的依赖关系。例如,realpython-reader取决于feedparser和html2text。在这种情况下, 的特定依赖项realpython-reader被写成一个集合:{"feedparser", "html2text"}。您可以使用任何迭代来指定这些,包括列表。
注意:请记住,字符串是可迭代其字符的。因此,您通常希望将单个字符串包装在某种容器中:
>>> dependencies = {"feedparser": "sgmllib3k"} # Will NOT work
这并不是说feedparser取决于sgmllib3k。相反,它说这feedparser取决于s, g, m, l, l, i, b, 3, 和 中的每一个k。
要计算图形的总阶数,您可以使用TopologicalSorterfrom graphlib:
>>> from graphlib import TopologicalSorter
>>> ts = TopologicalSorter(dependencies)
>>> list(ts.static_order())
['html2text', 'sgmllib3k', 'feedparser', 'realpython-reader']
给定的顺序建议您应该先安装html2text,然后sgmllib3k,然后feedparser,最后realpython-reader。
注意:图的总顺序不一定是唯一的。在这个例子中,其他有效的排序是:
sgmllib3k,html2text,feedparser,realpython-readersgmllib3k,feedparser,html2text,realpython-reader
TopologicalSorter有一个广泛的 API,允许您使用.add(). 您还可以迭代地使用图,这在调度可以并行完成的任务时特别有用。有关完整示例,请参阅文档。
最大公约数 (GCD) 和最小公倍数 (LCM)
一个数的除数是一个重要的性质,在密码学和其他领域都有应用。Python 早就有计算两个数的最大公约数(GCD)的函数了:
>>> import math
>>> math.gcd(49, 14)
7
49 和 14 的 GCD 是 7,因为 7 是能整除 49 和 14 的最大数。
的最小公倍数(LCM)涉及GCD。两个数的 LCM 是能被两者整除的最小数。可以根据 GCD 定义 LCM:
>>> def lcm(num1, num2):
... if num1 == num2 == 0:
... return 0
... return num1 * num2 // math.gcd(num1, num2)
...
>>> lcm(49, 14)
98
49 和 14 的最小公倍数是 98,因为 98 是可以被 49 和 14 整除的最小数。在 Python 3.9 中,您不再需要定义自己的 LCM 函数:
>>> import math
>>> math.lcm(49, 14)
98
两者math.gcd()和math.lcm()现在也支持两个以上的数字。你可以,例如,计算出的最大公约数273,1729和6048这样的:
>>> import math
>>> math.gcd(273, 1729, 6048)
7
请注意,math.gcd()并math.lcm()不能根据清单进行计算。但是,您可以将列表解压缩为逗号分隔的参数:
>>> import math
>>> numbers = [273, 1729, 6048]
>>> math.gcd(numbers)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object cannot be interpreted as an integer
>>> math.gcd(*numbers)
7
在早期版本的 Python 中,您需要嵌套多次调用gcd()或使用functools.reduce():
>>> import math
>>> math.gcd(math.gcd(273, 1729), 6048)
7
>>> import functools
>>> functools.reduce(math.gcd, [273, 1729, 6048])
7
在最新版本的 Python 中,这些计算的编写变得更加简单。
新的 HTTP 状态代码
该IANA协调几个关键的互联网基础设施资源,包括您看到数据库的时区较早。另一个这样的资源是HTTP 状态代码注册表。HTTP 状态代码在http标准库中可用:
>>> from http import HTTPStatus
>>> HTTPStatus.OK
<HTTPStatus.OK: 200>
>>> HTTPStatus.OK.description
'Request fulfilled, document follows'
>>> HTTPStatus(404)
<HTTPStatus.NOT_FOUND: 404>
>>> HTTPStatus(404).phrase
'Not Found'
在 Python 3.9 中,新的 HTTP 状态代码103(早期提示)和425(太早)已添加到http:
>>> from http import HTTPStatus
>>> HTTPStatus.EARLY_HINTS.value
103
>>> HTTPStatus(425).phrase
'Too Early'
如您所见,您可以根据号码和姓名访问新代码。
该超文本咖啡壶控制协议(HTCPCP)引入于1998年4月1日,控制,监视,和诊断咖啡壶。它引入了新方法,例如BREW主要重用现有的 HTTP 状态代码。一个例外是新的418(我是茶壶)状态代码,旨在防止因冲泡咖啡而毁坏好茶壶的灾难。
用于茶叶流出设备的超文本咖啡壶控制协议 (HTCPCP-TEA)还包括 418(我是茶壶),并且该代码还用于许多主流 HTTP 库,包括requests.
2017 年从主要图书馆中删除 418(我是茶壶)的倡议遭到了迅速的抵制。最终,争论以418 被提议作为保留的 HTTP 状态代码而告终。418(我是茶壶)也被添加到http:
>>> from http import HTTPStatus
>>> HTTPStatus(418).phrase
"I'm a Teapot"
>>> HTTPStatus.IM_A_TEAPOT.description
'Server refuses to brew coffee because it is a teapot.'
有几个地方可以看到 418 错误,包括在Google 上。
删除不推荐使用的兼容性代码
去年 Python 的一个重要里程碑是 Python 2的日落。Python 2.7于 2010 年首次发布。2020年 1 月 1 日,对 Python 2 的官方支持结束。
Python 2 为社区服务了近 20 年,并被许多人深情铭记。同时,不用担心保持 Python 3 与 Python 2 的兼容性,核心开发人员可以专注于 Python 3 的持续改进,并在此过程中进行一些清理工作。
许多已弃用但为了与 Python 2 向后兼容而保留的函数已在 Python 3.9 中删除。Python 3.10 中将删除更多内容。如果您想知道您的代码是否使用了这些旧功能中的任何一个,请尝试在开发模式下运行它:
$ python -X dev script_name.py
使用开发模式将向您显示更多警告,以帮助您的代码面向未来。有关要删除的功能的更多信息,请参阅Python 3.9 中的新增功能。
下一个版本的 Python 什么时候来?
Python 3.9 中与代码无关的最后一项更改在PEP 602—Python 的年度发布周期中进行了描述。传统上,新版本的 Python大约每十八个月发布一次。
从 Python 的当前版本开始,新版本将大约每十二个月发布一次,即每年的 10 月。这带来了几个优点,最明显的是更可预测和一致的发布时间表。通过年度发布,可以更轻松地计划和同步其他重要的开发者活动,例如 PyCon US sprint 和年度核心 sprint。
虽然未来版本会更频繁地发布,但 Python 不会更快地变得不兼容或更快地获得新功能。所有版本都将在最初发布后的五年内得到支持,因此 Python 3.9 将在 2025 年之前收到安全修复程序。
发布周期越短,新功能的发布速度就越快。同时,新版本会带来更少的变化,使更新变得不那么重要。
Python指导委员会的选举在每个 Python 版本发布后举行。展望未来,这意味着指导委员会的五个职位将每年举行一次选举。
尽管每 12 个月会发布一个新版本的 Python,但新版本的开发在其发布前大约 17 个月就开始了。这是因为在持续大约五个月的 beta 测试阶段,没有向版本添加新功能。
换句话说,下一个 Python 版本Python 3.10的开发已经在顺利进行中。您已经可以通过运行最新的核心开发人员的 Docker 镜像来测试 Python 3.10 的第一个 alpha 版本。
Python 3.10 的最终特性仍有待决定。但是,版本号有些特殊,因为它是第一个带有两位次要版本的 Python 版本。这可能会导致一些问题,例如,如果您的代码将版本作为字符串进行比较,因为"3.9" > "3.10". 更好的解决方案是将版本作为元组进行比较:(3, 9) < (3, 10). 包flake8-2020测试您的代码中的这些和类似问题。
那么,您应该升级到 Python 3.9 吗?
首先,如果您想尝试本教程中展示的任何很酷的新功能,那么您需要使用 Python 3.9。可以将最新版本与当前版本的 Python 并排安装。最简单的方法是使用环境管理器,如pyenv或conda。通过Docker运行新版本的侵入性更小。
当您考虑升级到 Python 3.9 时,您应该问自己两个不同的问题:
- 您是否应该将您的开发人员或生产环境升级到 Python 3.9?
- 您是否应该让您的项目依赖 Python 3.9,以便您可以利用新功能?
如果您的代码可以在 Python 3.8 中顺利运行,那么在 Python 3.9 中运行相同的代码时应该不会遇到什么问题。主要的绊脚石将是您是否依赖在 Python 的早期版本中已被弃用且现在正在被删除的函数。
新的 PEG 解析器自然没有像旧的那样经过广泛的测试。如果你不走运,你可能会遇到一些奇怪的角落问题。但是,请记住,您可以使用命令行标志切换回旧的解析器。
总而言之,您应该在方便的时候尽早将自己的环境升级到 Python 的最新版本。如果你想更保守一点,那么你可以等待第一个维护版本,Python 3.9.1。
您是否可以开始真正利用自己代码中的新功能在很大程度上取决于您的用户群。如果您的代码仅在您可以控制并升级到 Python 3.9 的环境中运行,那么使用zoneinfo或 新的字典合并运算符没有任何害处。
但是,如果您分发的库被许多其他人使用,那么最好更加保守。Python 3.5的最后一个版本于 9 月发布,不再受支持。如果可能,您仍然应该将您的库与 Python 3.6 和更新版本兼容,以便尽可能多的人可以享受您的努力。
有关为 Python 3.9 准备代码的详细信息,请参阅官方文档中的移植到 Python 3.9。
结论
新 Python 版本的发布对社区来说是一个重要的里程碑。您可能无法立即开始使用这些很酷的新功能,但几年后 Python 3.9 将像今天的 Python 3.6 一样普及。
在本教程中,您已经看到了以下新功能:
- 处理时区的
zoneinfo模块 - 可以更新字典的联合运算符
- 更具表现力的装饰器语法
- 除了类型提示之外,可用于其他用途的注解
有关更多 Python 3.9 技巧和与 Real Python 团队成员的小组讨论,请查看以下附加资源:
留出几分钟来尝试最让您兴奋的功能,然后在下面的评论中分享您的体验!

- 点赞
- 收藏
- 关注作者
评论(0)