Python爬虫网页解析神器Xpath快速入门教学!!!

【摘要】 Python爬虫网页解析神器Xpath快速入门教学!!!
1、Xpath介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
2、Xpath路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
3、结合实例讲解
这里我就是使用百度的界面为大家进行讲解

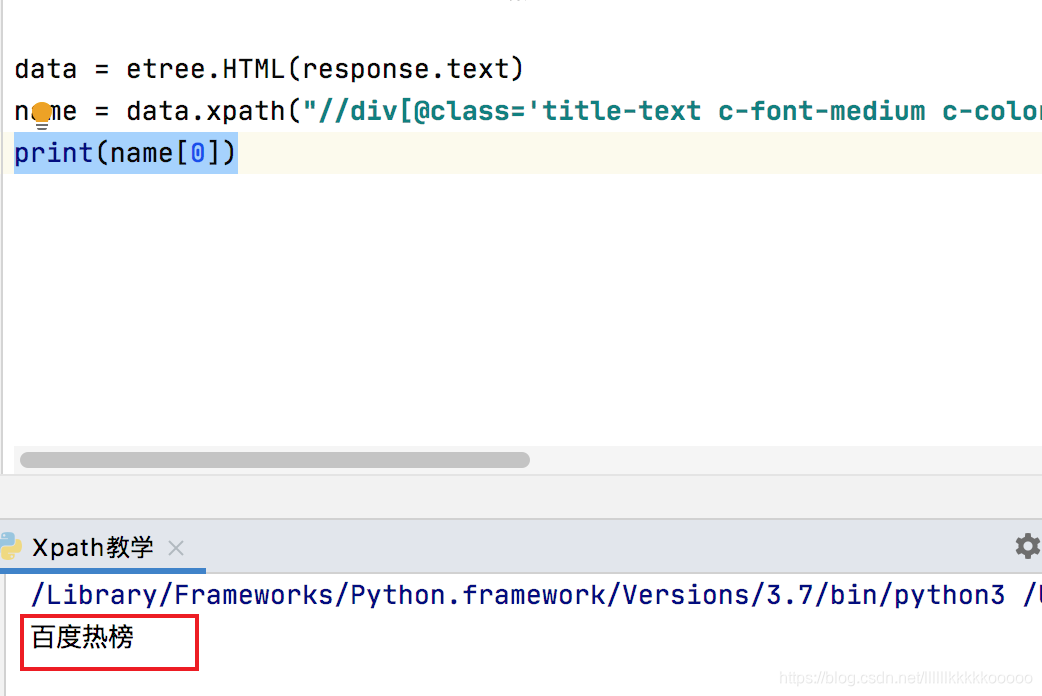
==例==:我想获取图中的百度热榜,打开控制台,我们可直接根据div标签的class值进行定位(这是我们平时使用xpath语法比较多的地方)

from lxml import etree
import requests
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36"
}
url = "https://www.baidu.com/"
response = requests.get(url=url,headers=headers)
#使用etree进行解析
data = etree.HTML(response.text)
#可参考上表格进行对比,//div可理解为任意路径下的一个div标签,@class表示选取class属性,text()表示获取text文本
name = data.xpath("//div[@class='title-text c-font-medium c-color-t']/text()")
print(name[0])
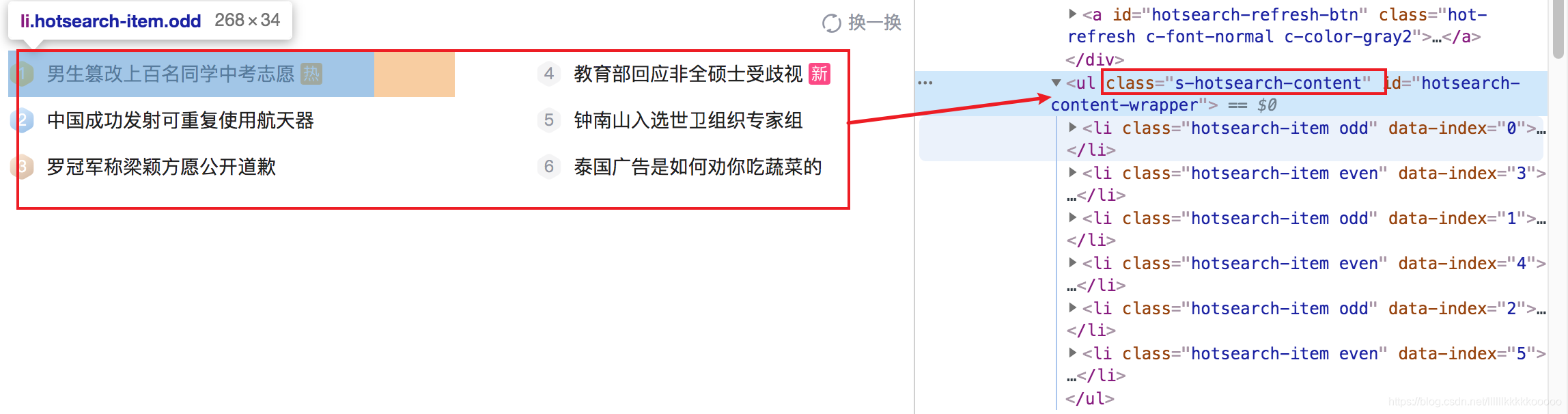
==例==:我想获取热榜有哪些信息,参考下图可见其全部在ul标签下,每一个信息对于一个li标签
data = etree.HTML(response.text)
#//ul表示任意路径下的ul标签,
#表示获取ul下的所有li标签
ul = data.xpath("//ul[@class='s-hotsearch-content']/li")
#当然,大家在爬取过程中可能会遇到没有class属性的标签,这时可使用id定位,又或者定位其父标签,再往下找
#ul = data.xpath("//ul[@id='hotsearch-content-wrapper']/li")
#遍历
for li in ul:
# .//span表示当前节点下的任意span标签,我们再根据class值定位,使用text()获取文本信息
name = li.xpath(".//span[@class='title-content-title']/text()")
print(name[0])

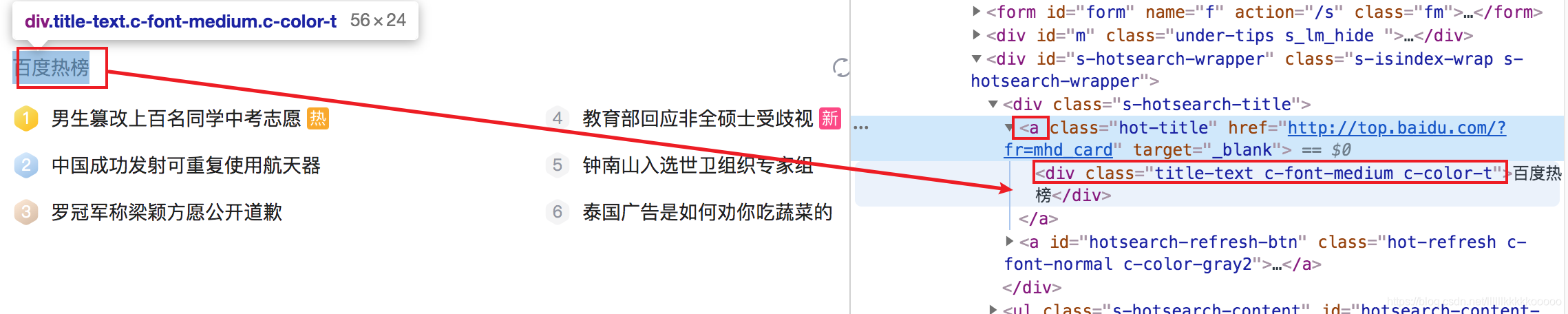
==例==:定位百度热榜找它的父节点也就是a标签的href属性
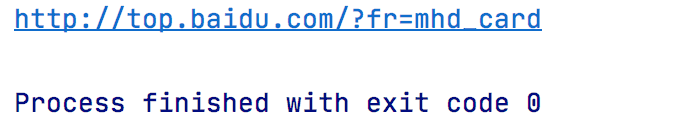
data = etree.HTML(response.text)
#..表示其父节点
url = data.xpath("//div[@class='title-text c-font-medium c-color-t']/../@href")
print(url[0])
Xpath语法其实不难的,大家需要多练习,进行实战,这样熟练掌握会很快的,可以下方的爬虫教程索引,里面有很多爬虫使用xpath写的,可以阅读看看。
博主会持续更新,有兴趣的小伙伴可以点赞、关注和收藏下哦,你们的支持就是我创作最大的动力!

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)