性能监控之初识 Prometheus

概述
Prometheus 是一套开源的监控、报警、时间序列数据库的组合,起始是由 SoundCloud 公司开发的,源于谷歌 borgmon。从 2016 年加入CNCF,2016 年 6 月正式发布 1.0 版本,2017 年底发布了基于全新存储层的 2.0 版本,能更好地与容器平台、云平台配合,到 2018 年8月毕业,现在已经成为 Kubernetes 的官方监控方案,社区活跃,第三方集成非常丰富。

监控的目标
在《SRE: Google运维解密》一书中指出,监控系统需要能够有效的支持白盒监控和黑盒监控。通过白盒能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。而黑盒监控,常见的如 HTTP探针,TCP 探针等,可以在系统或者服务在发生故障时能够快速通知相关的人员进行处理。通过建立完善的监控体系,从而达到以下目的:
- 长期趋势分析:通过对监控样本数据的持续收集和统计,对监控指标进行长期趋势分析。例如,通过对磁盘空间增长率的判断,我们可以提前预测在未来什么时间节点上需要对资源进行扩容。
- 对照分析:两个版本的系统运行资源使用情况的差异如何?在不同容量情况下系统的并发和负载变化如何?通过监控能够方便的对系统进行跟踪和比较。
- 告警:当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从而能够对问题进行快速的处理或者提前预防问题的发生,避免出现对业务的影响。
- 故障分析与定位:当问题发生后,需要对问题进行调查和处理。通过对不同监控监控以及历史数据的分析,能够找到并解决根源问题。
- 数据可视化:通过可视化仪表盘能够直接获取系统的运行状态、资源使用情况、以及服务运行状态等直观的信息。
Prometheus 的优势
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统 Prometheus 具有以下优点:
-
易于管理:只有一个单独的二进制文件,不存在任何的第三方依赖,采用 Pull-based 的方式拉取数据,Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus 服务发现(Service Discovery)的能力动态管理监控目标。
-
监控服务的内部运行状态:Pometheus 鼓励用户监控服务的内部状态,基于 Prometheus 丰富的 Client 库,用户可以轻松的在应用程序中添加对 Prometheus 的支持,从而让用户可以获取服务和应用内部真正的运行状态。

-
强大的数据模型:时间序列数据库 TSDB,golang,实现每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识,表示维度的标签可能来源于你的监控对象的状态,比如 code=404 或者 content_path=/api/path 。也可能来源于的你的环境定义,比如 environment=produment。基于这些 Labels 我们可以方便地对监控数据进行聚合,过滤,裁剪。
http_request_status{code='200',content_path='/api/path', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
http_request_status{code='200',content_path='/api/path2', environment='produment'} => [value1@timestamp1,value2@timestamp2...]
- 强大的查询语言 PromQL:内置了一个强大的数据查询语言 PromQL,可以实现多种查询、聚合,同时 PromQL 也被应用于数据可视化(如Grafana)以及告警当中。通过 PromQL 可以轻松回答类似于以下问题:
- 在过去一段时间中 95% 应用延迟时间的分布范围?
- 预测在 4 小时后,磁盘空间占用大致会是什么情况?
- CPU 占用率前 5 位的服务有哪些?(过滤)
- 高性能:对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而 Prometheus 可以高效地处理这些数据,对于单一Prometheus Server 实例而言它可以处理:
- 数以百万的监控指标
- 每秒处理数十万的数据点
- 上千个 targets
- 易扩展:Prometheus 是如此简单,因此你可以在每个数据中心、每个团队运行独立的 Prometheus Sevrer。Prometheus 对于联邦集群的支持,可以让多个 Prometheus 实例产生一个逻辑集群,当单实例 Prometheus Server 处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展,实现多数据中心。
- 易集成:使用 Prometheus 可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: Java, JMX, Python, Go,Ruby, .Net, Node.js 等等语言的客户端SDK,基于这些 SDK 可以快速让应用程序纳入到 Prometheus 的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持 Prometheus,还能支持 Graphite 这些其他的监控工具。同时 Prometheus 还支持与其他的监控系统进行集成:Graphite, Statsd, Collected, Scollector, muini, Nagios等。Prometheus社区还提供了大量第三方实现的监控数据采集支持:JMX, CloudWatch, EC2, MySQL, PostgresSQL, Haskell, Bash, SNMP, Consul, Haproxy, Mesos, Bind, CouchDB, Django, Memcached, RabbitMQ, Redis, RethinkDB, Rsyslog等等。总之,支持多种语言的 SDK 进行应用程序数据埋点,社区有丰富插件,白盒&黑盒监控都支持,DevOps友好。
- 可视化:Prometheus Server 中自带了一个 Prometheus UI,通过这个 UI 可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。同时 Prometheus 还提供了一个独立的基 于Ruby On Rails的 Dashboard 解决方案 Promdash。最新的Grafana 可视化工具也已经提供了完整的 Prometheus 支持,基于 Grafana 可以创建更加精美的监控图标。基于 Prometheus 提供的 API 还可以实现自己的监控可视化 UI。
- 开放性:通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于 Prometheus 来说,使用 Prometheus 的 client library 的输出格式不止支持 Prometheus 的格式化数据,也可以输出支持其它监控系统的格式化数据,比如 Graphite。
因此你甚至可以在不使用 Prometheus 的情况下,采用 Prometheus 的 client library 来让你的应用程序支持监控数据采集。也就是说使用 sdk 采集的数据可以被其他监控系统使用,不一定非要用 Prometheus。
Prometheus 的基本架构
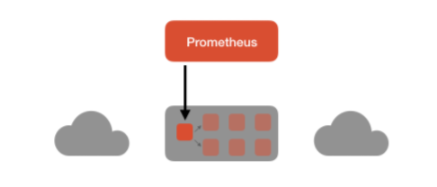
作为一个监控系统,Prometheus 项目的作用和工作方式,其实可以用如下所示的一张官方示意图来解释:
Prometheus 是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),比如从 exporter 拉取数据,或者间接地通过网关 gateway 拉取数据(如果在 k8s 内部署,可以使用服务发现的方式),它默认本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,然后再把这些结果保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。有了这套核心监控机制, Prometheus 剩下的组件就是用来配合这套机制的运行。比如Pushgateway ,可以允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据。而 Alertmanager,则可以根据 Metrics 信息灵活地设置报警。当然, Prometheus 最受用户欢迎的功能,还是通过 Grafana 对外暴露出的、可以灵活配置的监控数据可视化界面。
组件内容
-
Prometheus Server:Prometheus Server 是 Prometheus ,组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server 可以通过静态配置管理监控目标,也可以配合使用 Service Discovery 的方式动态管理监控目标,并从这些监控目标中获取数据。其次 Prometheus Server 需要对采集到的监控数据进行存储,Prometheus Server 本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后 Prometheus Server 对外提供了自定义的 PromQL 语言,实现对数据的查询以及分析。
- Retrieval: 采样模块
- TSDB: 存储模块默认本地存储为tsdb
- HTTP Server: 提供http接口查询和面板,默认端口为9090
-
Exporters/Jobs:负责收集目标对象(host, container…)的性能数据,并通过 HTTP 接口供 Prometheus Server 获取,Prometheus Server通过访问该 Exporter 提供的Endpoint端点,即可获取到需要采集的监控数据。支持数据库、硬件、消息中间件、存储系统、http服务器、jmx等。只要符合接口格式,就可以被采集。
- 直接采集:这一类 Exporter 直接内置了对 Prometheus 监控的支持,比如 cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向 Prometheus 暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持 Prometheus,因此我们需要通过 Prometheus 提供的 Client Library 编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
-
Short-lived jobs:瞬时任务的场景,无法通过pull方式拉取,需要使用push方式,与PushGateway搭配使用
-
PushGateway:可选组件,主要用于短期的 jobs。由于 Prometheus 数据采集基于 Pull 模型进行设计,因此在网络环境的配置上必须要让 Prometheus Server 能够直接与 Exporter 进行通信。 当这种网络需求无法直接满足时,就可以利用 PushGateway 来进行中转。可以通过 PushGateway 将内部网络的监控数据主动 Push 到 Gateway 当中。而Prometheus Server则可以采用同样Pull 的方式从 PushGateway 中获取到监控数据。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
-
客户端sdk:官方提供的客户端类库有go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持nodejs、php、erlang等
-
PromDash:使用 rails 开发的 dashboard,用于可视化指标数据,已废弃
-
Alertmanager:在 Prometheus Server 中支持基于 PromQL 创建告警规则,如果满足 PromQL 定义的规则,则会产生一条告警,而告警的后续处理流程则由 AlertManager 进行管理。在 AlertManager 中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过 Webhook 自定义告警处理方式。AlertManager 即 Prometheus 体系中的告警处理中心。
-
Service Discovery:服务发现,Prometheus 支持多种服务发现机制:文件,DNS,Consul,Kubernetes,OpenStack,EC2等等。基于服务发现的过程并不复杂,通过第三方提供的接口,Prometheus查询到需要监控的Target列表,然后轮训这些Target获取监控数据。
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动 Prometheus Server。
从二进制包安装
对于非 Docker 用户,可以从 https://prometheus.io/download/ 找到最新版本的 Prometheus Sevrer软件包:
export VERSION=2.25.2
curl -LO https://github.com/prometheus/prometheus/releases/download/v$VERSION/prometheus-$VERSION.darwin-amd64.tar.gz
解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-${VERSION}.darwin-amd64.tar.gz
cd prometheus-${VERSION}.darwin-amd64
解压后当前目录会包含默认的 Prometheus 配置文 件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Promtheus 作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为 data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数 --storage.tsdb.path="data/" 修改本地数据存储的路径。
启动 prometheus 服务,其会默认加载当前路径下的 prometheus.yaml 文件:
./prometheus
正常的情况下,你可以看到以下输出内容:
level=info ts=2021-03-21T04:40:31.632Z caller=main.go:722 msg="Starting TSDB ..."
level=info ts=2021-03-21T04:40:31.632Z caller=web.go:528 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-03-21T04:40:31.632Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1615788000000 maxt=1615852800000 ulid=01F0WFKTA8JPYE3GTA5RP9XMB5
level=info ts=2021-03-21T04:40:31.633Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1615852800000 maxt=1615917600000 ulid=01F0YDDARF4MHECC8PZ603CZR1
level=info ts=2021-03-21T04:40:31.633Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1615917600000 maxt=1615982400000 ulid=01F10B6WRZNYGJXZW90R2BQENK
level=info ts=2021-03-21T04:40:31.633Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1615982400000 maxt=1616047200000 ulid=01F1290D3KN9JNGVMJXHP57EPR
level=info ts=2021-03-21T04:40:31.633Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616047200000 maxt=1616112000000 ulid=01F146SZ7Q4MB39SRVBRSDQKMM
level=info ts=2021-03-21T04:40:31.633Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616112000000 maxt=1616176800000 ulid=01F164KFHDRKCNXR7Y9H6Y8GE2
level=info ts=2021-03-21T04:40:31.634Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616176800000 maxt=1616241600000 ulid=01F182D1JXT487YV58WYFZMJZS
level=info ts=2021-03-21T04:40:31.634Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616241600000 maxt=1616263200000 ulid=01F18Q04A506Q2942TQAPKNVYE
level=info ts=2021-03-21T04:40:31.634Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616284800000 maxt=1616292000000 ulid=01F19BK905YGNE1WV8CVX9RZQA
level=info ts=2021-03-21T04:40:31.634Z caller=repair.go:57 component=tsdb msg="Found healthy block" mint=1616263200000 maxt=1616284800000 ulid=01F19BKB09BVDWBE7QZPXNETX0
level=info ts=2021-03-21T04:40:31.741Z caller=head.go:645 component=tsdb msg="Replaying on-disk memory mappable chunks if any"
level=info ts=2021-03-21T04:40:31.799Z caller=head.go:659 component=tsdb msg="On-disk memory mappable chunks replay completed" duration=57.298066ms
level=info ts=2021-03-21T04:40:31.799Z caller=head.go:665 component=tsdb msg="Replaying WAL, this may take a while"
level=info ts=2021-03-21T04:40:32.030Z caller=head.go:691 component=tsdb msg="WAL checkpoint loaded"
level=info ts=2021-03-21T04:40:32.475Z caller=head.go:717 component=tsdb msg="WAL segment loaded" segment=1134 maxSegment=1137
使用容器安装
对于 Docker 用户,直接使用 Prometheus 的镜像即可启动 Prometheus Server:
docker run -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,可以通过 http://localhost:9090 访问 Prometheus 的UI界面:
使用 Kubernetes Operator 安装
参考:Kubernetes 集群监控 kube-prometheus 部署
小结
我们初步了解了 Prometheus 以及相比于其他相似方案的优缺点,可以为大家在选择监控解决方案时,提供一定的参考。同时我们介绍了 Prometheus 的生态以及核心能力,相信大家通过本文能够对 Prometheus 有一个直观的认识。
参考资料:

- 点赞
- 收藏
- 关注作者
评论(0)