惊!\u202a错误,百分之九十都不知道的隐藏在文件路径里的惊天秘密!(干货收藏)

@TOC
今天在做Python文件处理的时候遇到这样一个问题。
使用鼠标右键获取到文件路径并使用的时候发现总是发生错误,导致文件路径读取失败。
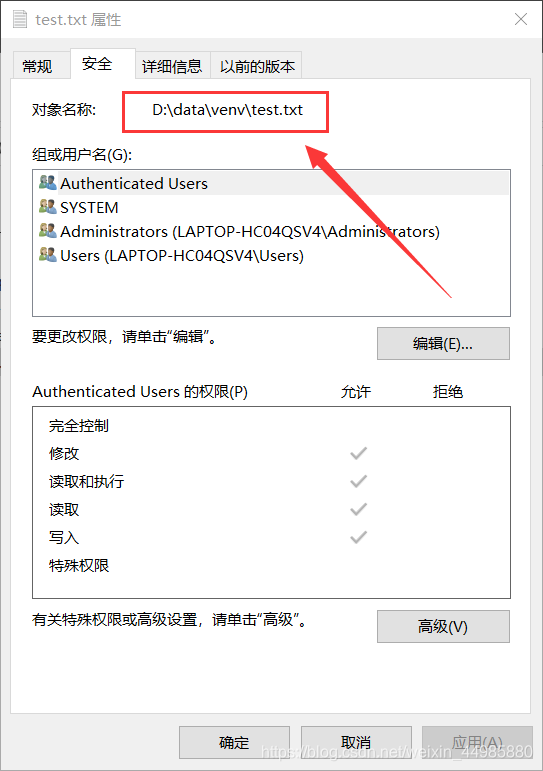
然后上网查了一下发现很多小伙伴都经历过类似的问题,网上的回答也有很多,但是大部分都是说在路径字符串前加r变成原始字符串、或者手动输入路径字符串进行解决。
以下是大灰狼按照网上已有一些方法进行的尝试:
尝试一:将复制到的路径前加上r成为原始字符串:
#文件路径修改为原始字符串
import shutil
import os.path as op
path1 = r'D:\data\venv\test.txt' #从文件夹直接复制而来的路径
path2 = r'D:\data\.idea' #从文件夹直接复制而来的路径
shutil.copy(path1, path2)
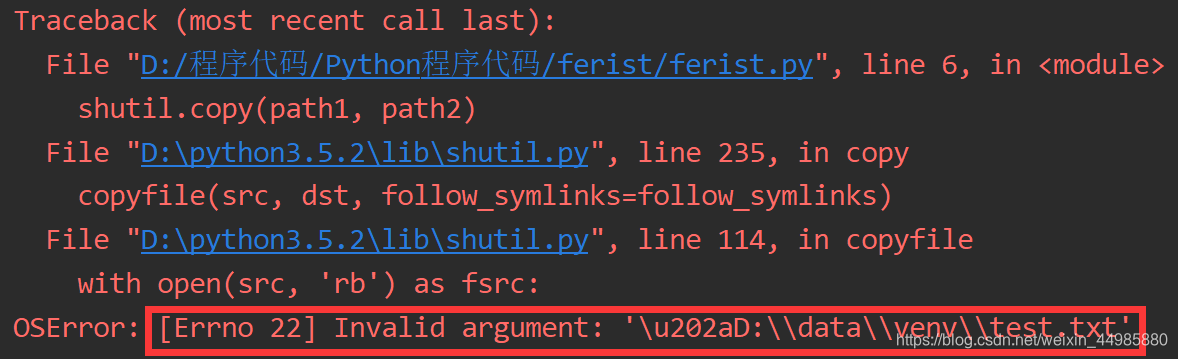
如上面代码所示,在复制到的文件路径前加上r成为原始字符串之后,运行结果并没有任何变化,仍然是显示这样的错误:
尝试二:文件路径手动输入
之后大灰狼又将字符手动输入,并在字符串前方分别使用了r和没有使用r。
发现文件路径在手动输入的情况下,即使不将路径变为原始字符串,程序仍然可以运行:
#文件路径手动输入
import shutil
import os.path as op
path1 = r'D:\data\venv\test.txt' #手写的路径
path2 = r'D:\data\.idea' #手写的路径
shutil.copy(path1, path2)
运行结果:

但是将前后两个代码细心对比的小伙伴就会发现。
除了文件路径一个是复制过来的、一个是手动输入的以外,在代码上并没有任何区别,但是就是这样的两个代码,手动输入的可以运行,而复制过来的路径无法运行。
这就很是疑惑了,明明是看上去一模一样的两个代码,为什么运行之后会有这样的差别呢?
尝试三:文件路径分割
于是我将复制而来的文件路径进行了分割对比,这一对比,那可坏了!
代码是这样的:
#文件路径分割
import shutil
import os.path as op
path1 = r'D:\data\venv\test.txt' #从文件夹直接复制而来的路径
path2 = r'D:\data\.idea' #从文件夹直接复制而来的路径
print(path1.split('\\'))
print(path2)
shutil.copy(path1, path2)
我将复制过来的两个路径字符串,第一个以反斜杠将其分割成列表形式,而第二个不做任何处理直接输出,发现运行结果是这样的:

未做处理的路径在输出出来以后并没有发现什么异常,但是经过反斜杠分割处理后的路径就不一样了。在文件路径的的最前方竟然出现了\u202a!
当时的我也是十分的懵逼…
从代码中可以看到,我们的文件路径的字符串中并未有\u202a,而在经过分割之后的列表中竟然出现了\u202a,但是第二个同样也是复制过来的路径,未处理直接输出,却没有\u202a的字符串出现。
此时此刻的大灰狼也是吓出了一身冷汗…难道这就是传说中神秘的\u202a字符嘛?

真相大白!
带着对\u202a百思不得其解的好奇,我踏上了询问度娘的漫漫征程。
好家伙,不查不知道,一查吓一跳!
\u202a这个字符其实一直都存在,只不过是我们凡人的肉眼还没有齐天大圣般程序猿的法力,单凭借简单的输出并不能让这个字符显出原形。
但不可否认的是,在我们右击文件复制其路径的时候,\u202a这个字符就已经存在我们的剪切板上了,但是在我们粘贴的时候它并不会让我们看见。

更神奇的是,这个字符并不是我们每次右击复制文件路径时都会出现。
它只会在我们从右向左复制的时候出现\u202a,而从左向右复制的时候并不会出现这个字符。
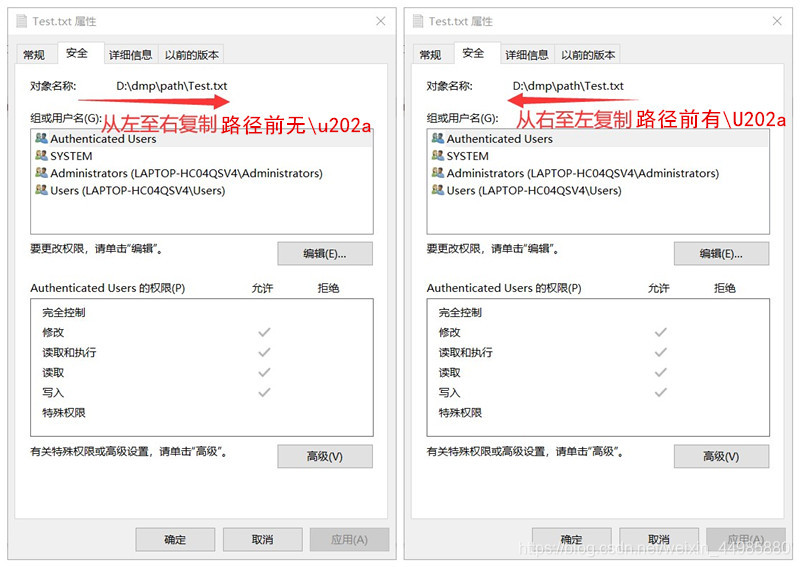
嗯…还有这神操作…

看到这里,相比我们这等凡人对于\u202a的神秘之处也略知一二了吧。
没错,我们平常读取文件路径的时候,都是从左向右读取的,依次是:某一个盘/文件夹/文件,并不是文件/文件夹/某一个盘这样。
但是在我们右击文件复制路径的时候,难免会从左或从右开始复制,所以在计算机上,为了对于那些从右至左复制而来的路径,在读取的时候可以从左向右读取,就会在文件路径前隐式的加上\u202a,表示路径是从左向右读取的。
所以这个符号应该是windows在做文件名显示的时候,为了保证文件路径是从左往右显示所加的强制字符。
现在了解了\u202a存在的原因,接下来就是在我们复制文件路径之后并在程序中使用它的时候,如何去掉这个看不见的字符串,
尝试四:normpath()函数处理路径
大灰狼在网上也有看到说使用os.path包的normpath()函数可以解决。
在这里说明一下normpath()函数的作用:将路径正规化:去除多余的分隔符,将 . 和 … 变成真实路径,处理错误的斜杠。
听着好像是有点用哈,于是大灰狼带着满心的疑惑使用normpath()函数尝试了一下,万一可以呢不是。
并且为了更加直观的看到normpath()函数是否可以将文件路径正规化,大灰狼将同样将经过normpath()函数处理后的两个文件路径分割和不分割处理,代码如下:
#normpath()函数处理
import shutil
import os.path as op
path1 = op.normpath(r'D:\data\venv\test.txt') #从文件夹直接复制而来的路径
path2 = op.normpath(r'D:\data\.idea') #从文件夹直接复制而来的路径
print(path1.split('\\')) #将路径1以反斜杠分隔为列表输出
print(path2)
shutil.copy(path1, path2)
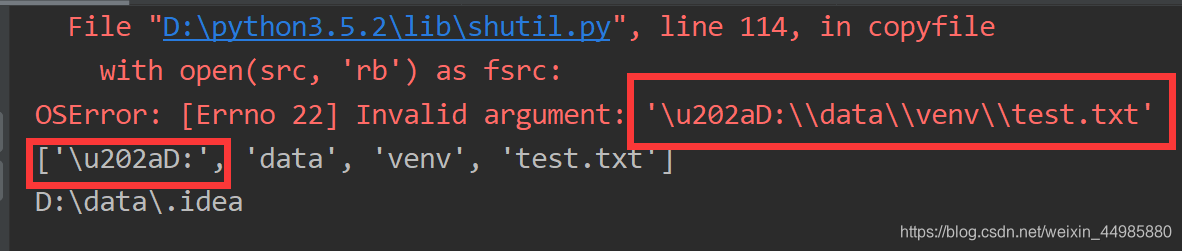
结果可想而知,normpath()函数并没有对文件路径做出改变,在进行分割时候输出的结果上还是存在\u202a。
这下可好了,尝试了网上的很多方法,还是无法解决这个\u202a的文件路径问题。
但是对于我这样一个连写代码都不想多敲一下键盘的程序猿来说,怎么可能一次次的手动输入文件路径,或者一次次的修改路径呢,于是就有了这样的神奇操作…
定义函数处理问题
没错!为了更好的偷懒,我写了这样一个处理函数,该函数接收的变量是一个文件路径,也就是我们从文件属性中复制过来的文件路径,经过该函数的处理之后,可以重新返回一个可以被程序使用的没有\u202a的正规路径。
并且是使用正斜杠连接,不会出现因为反斜杠而导致的转义字符错误。
我的代码实现效果如下:
#函数处理
import shutil
import os.path as op
path1 = 'D:\dmp\path\Test.txt' #从文件夹直接复制而来的路径
path2 = 'D:\dmp\deposit' #从文件夹直接复制而来的路径
'''将负责路径而来的路径标准化'''
def path_normal(path):
path = path.split('\\')
path[0] = path[0][-2: len(path[0])]
path = '/'.join(path)
return path
print('转换前:' + path1)
print('分割成列表:')
print(path1.split('\\'))
path1 = path_normal(path1) #调用函数进行路径转换
print('转换后:' + path1)
print('分割成列表:')
print(path1.split('/'))
path2 = path_normal(path2)
shutil.copy(path1, path2) #复制文件和文件夹
运行结果:
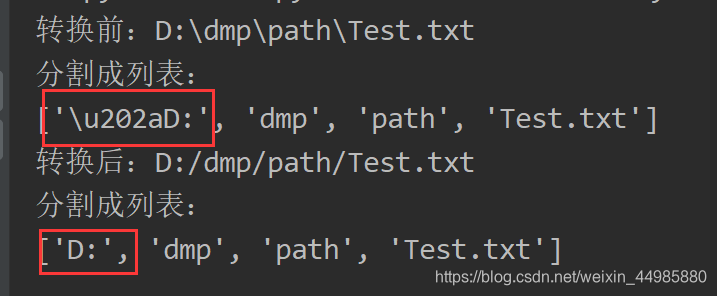
可以看出,经过这个函数处理后的文件路径再次以斜杠分割以后,并没有出现\u202a的字符串,并且在直接运用到文件处理的函数时没有报错。
函数比较简单,只有四行代码便将在文件路径前看不到\u202a分离出来了,比较实用。
函数的使用方法是传入需要处理的文件路径,并将处理后的正规路径返回出来,只需要接收就可以使用了。
路径标准化处理函数
以下是该函数的代码:
#路径标准化处理
'''将负责路径而来的路径标准化'''
def path_normal(path):
path = path.split('\\')
path[0] = path[0][-2: len(path[0])]
path = '/'.join(path)
return path
现在,你应该对于复制文件路径报错的原因和处理方法有了简单的了解了吧,虽然比较简单,但也的确是很多程序中比较常见和容易忽略的错误。收藏起来以备后用!
觉得不错记得点赞关注喔,
大灰狼期待与你一同进步!

- 点赞
- 收藏
- 关注作者
评论(0)