使用 Python 进行情感分析对电影评论进行分类

目录
情感分析是一种强大的工具,可以让计算机理解一篇文章的潜在主观基调。这是人类难以解决的问题,正如您想象的那样,计算机也并非总是那么容易。但是使用正确的工具和 Python,您可以使用情绪分析来更好地理解一篇文章的情绪。
你为什么要这样做?情绪分析有很多用途,例如通过使用社交媒体数据或汇总评论来了解股票交易员对特定公司的看法,您将在本教程结束时完成这些工作。
在本教程中,您将学习:
- 如何使用自然语言处理 (NLP)技术
- 如何使用机器学习来确定文本的情感
- 如何使用 spaCy构建一个 NLP 管道,该管道将输入情感分析分类器
本教程非常适合希望获得以项目为中心的指南来使用 spaCy 构建情感分析管道的机器学习初学者。
您应该熟悉基本的机器学习技术(如二元分类)及其背后的概念,如训练循环、数据批次以及权重和偏差。如果您不熟悉机器学习,那么您可以通过学习逻辑回归来开始您的旅程。
准备好后,您可以通过从以下链接下载源代码来学习本教程中的示例:
使用自然语言处理预处理和清理文本数据
任何情绪分析工作流程都从加载数据开始。但是一旦数据加载完毕,你会怎么做呢?您需要先通过自然语言处理管道对其进行处理,然后才能使用它做任何有趣的事情。
必要的步骤包括(但不限于)以下步骤:
- 标记句子以将文本分解为句子、单词或其他单元
- 删除停用词,如“if”、“but”、“or”等
- 通过将单词的所有形式压缩为单个形式来规范化单词
- 通过将文本转换为数字表示以供分类器使用来对文本进行矢量化
所有这些步骤都有助于减少任何人类可读文本中固有的噪音,并提高分类器结果的准确性。有很多很棒的工具可以帮助解决这个问题,例如Natural Language Toolkit、TextBlob和spaCy。在本教程中,您将使用 spaCy。
注意: spaCy 是一个非常强大的工具,具有许多功能。要深入了解其中的许多功能,请查看使用 spaCy 的自然语言处理。
在继续之前,请确保您安装了 spaCy 及其英文模型:
$ pip install spacy==2.3.5
$ python -m spacy download en_core_web_sm
第一个命令安装 spaCy,第二个命令使用 spaCy 下载其英语语言模型。spaCy 支持多种不同的语言,这些语言在spaCy 网站上列出。
警告:本教程仅适用于 spaCy 2.X,与 spaCy 3.0 不兼容。为了获得最佳体验,请安装上面指定的版本。
接下来,您将学习如何使用 spaCy 来帮助您完成之前了解的预处理步骤,从标记化开始。
标记化
标记化是将文本块分解成更小的部分的过程。spaCy 带有一个从标记化开始的默认处理管道,使这个过程变得轻而易举。在 spaCy 中,您可以进行句子标记化或单词标记化:
- 单词标记化将文本分解为单个单词。
- 句子标记化将文本分解为单独的句子。
在本教程中,您将使用单词标记化将文本分成单独的单词。首先,您将文本加载到 spaCy,它为您完成标记化工作:
>>> import spacy
>>> text = """
Dave watched as the forest burned up on the hill,
only a few miles from his house. The car had
been hastily packed and Marta was inside trying to round
up the last of the pets. "Where could she be?" he wondered
as he continued to wait for Marta to appear with the pets.
"""
>>> nlp = spacy.load("en_core_web_sm")
>>> doc = nlp(text)
>>> token_list = [token for token in doc]
>>> token_list
[
, Dave, watched, as, the, forest, burned, up, on, the, hill, ,,
, only, a, few, miles, from, his, house, ., The, car, had,
, been, hastily, packed, and, Marta, was, inside, trying, to, round,
, up, the, last, of, the, pets, ., ", Where, could, she, be, ?, ", he, wondered,
, as, he, continued, to, wait, for, Marta, to, appear, with, the, pets, .,
]
在此代码中,您设置了一些示例文本以进行标记化,加载 spaCy 的英语模型,然后通过将其传递给nlp构造函数来对文本进行标记化。此模型包含一个您可以自定义的默认处理管道,您将在稍后的项目部分中看到。
之后,您生成一个令牌列表并打印它。您可能已经注意到,“单词标记化”是一个稍微具有误导性的术语,因为捕获的标记包括标点符号和其他非单词字符串。
Tokens 是 spaCy 中一种重要的容器类型,具有非常丰富的特性。在下一节中,您将学习如何使用其中一个功能过滤掉停用词。
删除停用词
停用词是在人类交流中可能很重要但对机器价值不大的词。spaCy 带有一个默认的停用词列表,您可以自定义这些停用词。现在,您将看到如何使用标记属性来删除停用词:
>>> filtered_tokens = [token for token in doc if not token.is_stop]
>>> filtered_tokens
[
, Dave, watched, forest, burned, hill, ,,
, miles, house, ., car,
, hastily, packed, Marta, inside, trying, round,
, pets, ., ", ?, ", wondered,
, continued, wait, Marta, appear, pets, .,
]
在一行 Python 代码中,您可以使用.is_stoptoken 属性从标记化的文本中过滤掉停用词。
您注意到此输出与标记文本后得到的输出之间有什么区别?移除停用词后,标记列表更短,帮助您理解标记的上下文也更少。
规范化单词
规范化比标记化稍微复杂一些。它需要将一个词的所有形式压缩成该词的单一表示。例如,“watched”、“watching”和“watches”都可以归一化为“watch”。有两种主要的归一化方法:
- 词干
- 词形还原
随着词干,一个词在其切断干,这个词,从中可以创建后代词的最小单位。你刚刚在上面看到了一个带有“watch”的例子。Stemming 只是使用常见的结尾来截断字符串,因此它会遗漏“feel”和“felt”之间的关系,例如。
词形还原旨在解决这个问题。此过程使用一种数据结构,将单词的所有形式关联回其最简单的形式,或lemma。因为词形还原通常比词干更强大,所以它是 spaCy 提供的唯一规范化策略。
幸运的是,您不需要任何额外的代码来做到这一点。它发生自动,连同其他一些活动,如词性标注和命名实体识别-当你打电话nlp()。您可以利用以下.lemma_属性检查每个标记的引理:
>>> lemmas = [
... f"Token: {token}, lemma: {token.lemma_}"
... for token in filtered_tokens
... ]
>>> lemmas
['Token: \n, lemma: \n', 'Token: Dave, lemma: Dave',
'Token: watched, lemma: watch', 'Token: forest, lemma: forest',
# ...
]
您在这里所做的只是通过遍历过滤的标记列表来生成一个可读的标记和引理列表,利用.lemma_属性来检查引理。此示例仅显示前几个标记和引理。你的输出会更长。
注意:注意.lemma_属性上的下划线。这不是打字错误。这是 spaCy 中的一个约定,它获取属性的人类可读版本。
下一步是以机器可以理解的方式表示每个令牌。这称为矢量化。
矢量化文本
向量化是将标记转换为向量或数值数组的过程,在 NLP 的上下文中,向量是唯一的并表示标记的各种特征。在底层使用向量来查找单词相似性、对文本进行分类以及执行其他 NLP 操作。
这种特殊的表示是一个密集数组,其中数组中的每个空间都有定义的值。这与使用稀疏数组的早期方法相反,其中大多数空间都是空的。
与其他步骤一样,nlp()调用会自动处理矢量化。由于您已经有了一个标记对象列表,您可以像这样获得标记之一的向量表示:
>>> filtered_tokens[1].vector
array([ 1.8371646 , 1.4529226 , -1.6147211 , 0.678362 , -0.6594443 ,
1.6417935 , 0.5796405 , 2.3021278 , -0.13260496, 0.5750932 ,
1.5654886 , -0.6938864 , -0.59607106, -1.5377437 , 1.9425622 ,
-2.4552505 , 1.2321601 , 1.0434952 , -1.5102385 , -0.5787632 ,
0.12055647, 3.6501784 , 2.6160972 , -0.5710199 , -1.5221789 ,
0.00629176, 0.22760668, -1.922073 , -1.6252862 , -4.226225 ,
-3.495663 , -3.312053 , 0.81387717, -0.00677544, -0.11603224,
1.4620426 , 3.0751472 , 0.35958546, -0.22527039, -2.743926 ,
1.269633 , 4.606786 , 0.34034157, -2.1272311 , 1.2619178 ,
-4.209798 , 5.452852 , 1.6940253 , -2.5972986 , 0.95049495,
-1.910578 , -2.374927 , -1.4227567 , -2.2528825 , -1.799806 ,
1.607501 , 2.9914255 , 2.8065152 , -1.2510269 , -0.54964066,
-0.49980402, -1.3882618 , -0.470479 , -2.9670253 , 1.7884955 ,
4.5282774 , -1.2602427 , -0.14885521, 1.0419178 , -0.08892632,
-1.138275 , 2.242618 , 1.5077229 , -1.5030195 , 2.528098 ,
-1.6761329 , 0.16694719, 2.123961 , 0.02546412, 0.38754445,
0.8911977 , -0.07678384, -2.0690763 , -1.1211847 , 1.4821006 ,
1.1989193 , 2.1933236 , 0.5296372 , 3.0646474 , -1.7223308 ,
-1.3634219 , -0.47471118, -1.7648507 , 3.565178 , -2.394205 ,
-1.3800384 ], dtype=float32)
在这里,您使用列表中.vector第二个标记上的属性filtered_tokens,在这组示例中是单词Dave。
注意:如果您得到不同的.vector属性结果,请不要担心。这可能是因为您使用的是不同版本的en_core_web_sm模型,或者可能是 spaCy 本身。
现在您已经了解了 spaCy 中的一些典型文本预处理步骤,您将学习如何对文本进行分类。
机器学习工具
Python 中有许多工具可用于解决分类问题。以下是一些比较受欢迎的:
此列表并不包含所有内容,但这些是 Python 中可用的更广泛使用的机器学习框架。它们是大型、强大的框架,需要花费大量时间才能真正掌握和理解。
TensorFlow由 Google 开发,是最流行的机器学习框架之一。您主要使用它来实现您自己的机器学习算法,而不是使用现有算法。它的级别相当低,为用户提供了很多能力,但它具有陡峭的学习曲线。
PyTorch是 Facebook 对 TensorFlow 的回应,并实现了许多相同的目标。然而,它的构建目的是让 Python 程序员更熟悉,并且已经成为一个非常流行的框架。因为它们具有相似的用例,所以如果您正在考虑学习一个框架,比较 TensorFlow 和 PyTorch是一个有用的练习。
scikit-learn与 TensorFlow 和 PyTorch 形成对比。它是更高级别的,允许您使用现成的机器学习算法,而不是构建自己的算法。它缺乏可定制性,但它弥补了易用性,让您只需几行代码即可快速训练分类器。
幸运的是,spaCy 提供了一个相当简单的内置文本分类器,稍后您将了解它。然而,首先,了解任何分类问题的一般工作流程很重要。
分类的工作原理
别担心,在本节中,您不会深入研究线性代数、向量空间或其他通常为机器学习提供动力的深奥概念。相反,您将获得对分类问题常见的工作流和约束的实用介绍。
获得矢量化数据后,分类的基本工作流程如下所示:
- 将您的数据拆分为训练集和评估集。
- 选择模型架构。
- 使用训练数据来训练您的模型。
- 使用测试数据来评估模型的性能。
- 在新数据上使用经过训练的模型来生成预测,在这种情况下,它将是一个介于 -1.0 和 1.0 之间的数字。
此列表并非详尽无遗,为了提高准确性,还可以执行许多其他步骤和变体。例如,机器学习从业者经常将他们的数据集分成三组:
- 培训
- 验证
- 测试
该训练集,顾名思义,是用来训练你的模型。该验证集是用来帮助调整超参数模型,这可能会导致更好的性能。
注意:超参数控制模型的训练过程和结构,可以包括学习率和批量大小等内容。但是,哪些超参数可用在很大程度上取决于您选择使用的模型。
所述测试集合是包括各种各样的数据的准确判断模型的性能的数据集。测试集通常用于比较多个模型,包括不同训练阶段的相同模型。
现在您已经了解了分类的一般流程,是时候用 spaCy 将其付诸实践了。
如何使用 spaCy 进行文本分类
您已经了解了 spaCy 如何使用nlp()构造函数为您完成大部分文本预处理工作。这真的很有帮助,因为训练分类模型需要很多有用的例子。
此外,spaCy 提供了一个管道功能,当您调用nlp(). 默认管道在与您使用的任何预先存在的模型相关联的JSON文件中定义(en_core_web_sm对于本教程),但如果您愿意,您也可以从头开始构建一个。
注意:要了解有关创建自己的语言处理管道的更多信息,请查看spaCy 管道文档。
这和分类有什么关系?spaCy 提供的内置管道组件之一称为textcat(简称TextCategorizer),它使您能够为文本数据分配类别(或标签)并将其用作神经网络的训练数据。
此过程将生成一个经过训练的模型,然后您可以使用该模型来预测给定文本片段的情绪。要利用此工具,您需要执行以下步骤:
- 将
textcat组件添加到现有管道。 - 向
textcat组件添加有效标签。 - 加载、洗牌和拆分您的数据。
- 训练模型,评估每个训练循环。
- 使用训练好的模型来预测非训练数据的情绪。
- (可选)保存经过训练的模型。
注意:您可以在spaCy 文档示例 中看到这些步骤的实现。这是在 spaCy 中对文本进行分类的主要方式,因此您会注意到项目代码大量借鉴了此示例。
在下一部分中,您将学习如何通过构建自己的项目来将所有这些部分组合在一起:电影评论情感分析器。
构建您自己的 NLP 情感分析器
在前面的部分中,您可能已经注意到构建情感分析管道的四个主要阶段:
- 加载数据
- 预处理
- 训练分类器
- 分类数据
为了构建现实生活中的情感分析器,您将完成组成这些阶段的每个步骤。您将使用Andrew Maas编译的大型电影评论数据集来训练和测试您的情绪分析器。准备就绪后,继续下一部分以加载数据。
加载和预处理数据
如果您还没有,请下载并提取大型电影评论数据集。花几分钟时间四处看看,看看它的结构,并对一些数据进行采样。这将告知您如何加载数据。对于这一部分,您将使用spaCy 的textcat示例作为粗略指南。
您可以(并且应该)将加载阶段分解为具体的步骤,以帮助规划您的编码。下面是一个例子:
- 从文件和目录结构加载文本和标签。
- 打乱数据。
- 将数据拆分为训练集和测试集。
- 返回两组数据。
这个过程是相对独立的,所以它至少应该是它自己的功能。在考虑此函数将执行的操作时,您可能已经想到了一些可能的参数。
由于您正在拆分数据,因此控制这些拆分大小的能力可能很有用,因此split包含一个很好的参数。您可能还希望使用limit参数限制您处理的文档总数。你可以打开你最喜欢的编辑器并添加这个函数签名:
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0
) -> tuple:
有了这个签名,你就可以利用 Python 3 的类型注释来明确你的函数期望的类型以及它将返回的类型。
此处的参数允许您定义存储数据的目录以及训练数据与测试数据的比率。一个好的开始比例是 80% 的数据用于训练数据,20% 用于测试数据。除非另有说明,否则所有这些和以下代码都应位于同一个文件中。
接下来,您需要遍历此数据集中的所有文件并将它们加载到列表中:
import os
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0
) -> tuple:
# Load from files
reviews = []
for label in ["pos", "neg"]:
labeled_directory = f"{data_directory}/{label}"
for review in os.listdir(labeled_directory):
if review.endswith(".txt"):
with open(f"{labeled_directory}/{review}") as f:
text = f.read()
text = text.replace("<br />", "\n\n")
if text.strip():
spacy_label = {
"cats": {
"pos": "pos" == label,
"neg": "neg" == label
}
}
reviews.append((text, spacy_label))
虽然这看起来很复杂,但您所做的是构建数据的目录结构,查找并打开文本文件,然后将内容元组和标签字典附加到reviews列表中。
标签字典结构是 spaCy 模型在训练循环期间所需的格式,您很快就会看到。
注意:在本教程和 Python 之旅中,您将阅读和编写文件。这是需要掌握的基本技能,因此请务必在学习本教程时复习它。
由于此时您已打开每条评论,因此最好<br />将文本中的HTML 标记替换为换行符并.strip()用于删除所有前导和尾随空格。
对于此项目,您不会立即从训练数据中删除停用词,因为它可能会改变句子或短语的含义,从而降低分类器的预测能力。这在某种程度上取决于您使用的停用词列表。
加载文件后,您想对它们进行随机播放。这可以从加载训练数据的顺序中消除任何可能的偏差。由于该random模块可以轻松地在一行中完成,您还将看到如何拆分混洗数据:
import os
import random
def load_training_data(
data_directory: str = "aclImdb/train",
split: float = 0.8,
limit: int = 0
) -> tuple:
# Load from files
reviews = []
for label in ["pos", "neg"]:
labeled_directory = f"{data_directory}/{label}"
for review in os.listdir(labeled_directory):
if review.endswith(".txt"):
with open(f"{labeled_directory}/{review}") as f:
text = f.read()
text = text.replace("<br />", "\n\n")
if text.strip():
spacy_label = {
"cats": {
"pos": "pos" == label,
"neg": "neg" == label}
}
reviews.append((text, spacy_label))
random.shuffle(reviews)
if limit:
reviews = reviews[:limit]
split = int(len(reviews) * split)
return reviews[:split], reviews[split:]在这里,您可以通过调用 来调整数据random.shuffle()。然后,您可以选择使用一些数学来截断和拆分数据,以将拆分转换为定义拆分边界的多个项目。最后,您使用列表切片返回reviews列表的两个部分。
这是一个示例输出,为简洁起见被截断:
(
'When tradition dictates that an artist must pass (...)',
{'cats': {'pos': True, 'neg': False}}
)
要了解有关random工作原理的更多信息,请查看在 Python中生成随机数据(指南)。
注意: spaCy 的制造商还发布了一个名为的包thinc,其中包括对大型数据集的简化访问,包括您用于该项目的 IMDB 评论数据集。
您可以在 GitHub 上找到该项目。如果你调查它,看看他们如何处理加载 IMDB 数据集,看看他们的代码和你自己的代码之间存在哪些重叠。
现在您已经构建了数据加载器并完成了一些简单的预处理,现在是构建 spaCy 管道和分类器训练循环的时候了。
训练分类器
将 spaCy 管道放在一起可以让您快速构建和训练卷积神经网络(CNN) 以对文本数据进行分类。当您在这里使用它进行情感分析时,只要您为其提供训练数据和标签,它就足以处理任何类型的文本分类任务。
在项目的这一部分,您将完成三个步骤:
- 修改基础 spaCy 管道以包含
textcat组件 - 构建训练循环来训练
textcat组件 - 在给定数量的训练循环后评估模型训练的进度
首先,您将添加textcat到默认的 spaCy 管道。
修改 spaCy 管道以包含 textcat
对于第一部分,您将加载与在本教程开头的示例中所做的相同的管道,然后添加textcat组件(如果该组件尚不存在)。之后,您将数据使用的标签("pos"正面和"neg"负面)添加到textcat. 完成后,您就可以构建训练循环了:
import os
import random
import spacy
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Build pipeline
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
如果您已经看过 spaCy 文档的textcat示例,那么这应该看起来很熟悉。首先,加载内置en_core_web_sm管道,然后检查.pipe_names属性以查看textcat组件是否已经可用。
如果不是,则使用 来创建组件(也称为管道).create_pipe(),并传入配置字典。TextCategorizer文档中描述了一些您可以使用的选项。
最后,使用 将组件添加到管道中.add_pipe(),last参数表示应将此组件添加到管道的末尾。
接下来,您将处理textcat存在组件的情况,然后添加将用作文本类别的标签:
import os
import random
import spacy
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Build pipeline
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")如果组件存在于加载的管道中,那么您只需将.get_pipe()其分配给一个变量,以便您可以对其进行处理。对于这个项目,您要做的就是从数据中添加标签,以便textcat知道要查找的内容。你会用.add_label().
您已经创建了管道并textcat为将用于训练的标签准备了组件。现在是时候编写允许textcat对电影评论进行分类的训练循环了。
建立你的训练循环来训练 textcat
要开始训练循环,您首先将管道设置为仅训练textcat组件,使用 spaCy和实用程序为其生成批量数据,然后遍历它们并更新您的模型。minibatch()compounding()
一个批次就是你的数据的一个子集。对数据进行批处理可以减少训练期间的内存占用,并更快地更新超参数。
注意:复合批量大小是一种相对较新的技术,应该有助于加快训练速度。您可以在spaCy 的培训技巧 中了解有关复合批量大小的更多信息。
这是上述训练循环的实现:
import os
2import random
3import spacy
4from spacy.util import minibatch, compounding
5
6def train_model(
7 training_data: list,
8 test_data: list,
9 iterations: int = 20
10) -> None:
11 # Build pipeline
12 nlp = spacy.load("en_core_web_sm")
13 if "textcat" not in nlp.pipe_names:
14 textcat = nlp.create_pipe(
15 "textcat", config={"architecture": "simple_cnn"}
16 )
17 nlp.add_pipe(textcat, last=True)
18 else:
19 textcat = nlp.get_pipe("textcat")
20
21 textcat.add_label("pos")
22 textcat.add_label("neg")
23
24 # Train only textcat
25 training_excluded_pipes = [
26 pipe for pipe in nlp.pipe_names if pipe != "textcat"
27 ]在第 25 到 27 行,您创建了管道中所有不是textcat组件的组件的列表。然后,您可以使用nlp.disable()上下文管理器为上下文管理器范围内的所有代码禁用这些组件。
现在您已准备好添加代码以开始训练:
import os
import random
import spacy
from spacy.util import minibatch, compounding
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Build pipeline
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Train only textcat
training_excluded_pipes = [
pipe for pipe in nlp.pipe_names if pipe != "textcat"
]
with nlp.disable_pipes(training_excluded_pipes):
optimizer = nlp.begin_training()
# Training loop
print("Beginning training")
batch_sizes = compounding(
4.0, 32.0, 1.001
) # A generator that yields infinite series of input numbers在这里,您调用nlp.begin_training(),它返回初始优化器函数。这nlp.update()将用于更新基础模型的权重。
然后您使用该compounding()实用程序创建一个生成器,为您提供一个无限系列,batch_sizes该minibatch()实用程序稍后将使用该生成器。
现在,您将开始对成批数据进行训练:
import os
import random
import spacy
from spacy.util import minibatch, compounding
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Build pipeline
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Train only textcat
training_excluded_pipes = [
pipe for pipe in nlp.pipe_names if pipe != "textcat"
]
with nlp.disable_pipes(training_excluded_pipes):
optimizer = nlp.begin_training()
# Training loop
print("Beginning training")
batch_sizes = compounding(
4.0, 32.0, 1.001
) # A generator that yields infinite series of input numbers
for i in range(iterations):
loss = {}
random.shuffle(training_data)
batches = minibatch(training_data, size=batch_sizes)
for batch in batches:
text, labels = zip(*batch)
nlp.update(
text,
labels,
drop=0.2,
sgd=optimizer,
losses=loss
)现在,对于train_model()签名中指定的每次迭代,您创建一个名为的空字典loss,将由 更新和使用nlp.update()。您还可以对训练数据进行混洗,并使用 将其拆分为不同大小的批次minibatch()。
对于每个批次,您将文本和标签分开,然后输入它们、空loss字典和optimizerto nlp.update()。这将对每个示例运行实际训练。
该dropout参数nlp.update()指示要跳过该批次中训练数据的比例。这样做是为了让模型更难以意外地记住训练数据而没有提出可泛化的模型。
这将需要一些时间,因此定期评估您的模型很重要。您将使用从训练集(也称为保留集)中保留的数据来执行此操作。
评估模型训练的进度
由于您将进行许多评估,每个评估都有许多计算,因此编写一个单独的evaluate_model()函数是有意义的。在此函数中,您将针对未完成的模型运行测试集中的文档以获得模型的预测,然后将它们与该数据的正确标签进行比较。
使用该信息,您将计算以下值:
-
真阳性是模型正确预测为阳性的文档。对于这个项目,这映射到积极情绪,但在二元分类任务中泛化到您试图识别的类。
-
误报是您的模型错误地预测为正但实际上为负的文档。
-
真阴性是您的模型正确预测为阴性的文档。
-
假阴性是您的模型错误地预测为阴性但实际上是阳性的文档。
由于您的模型将为每个标签返回 0 到 1 之间的分数,因此您将根据该分数确定正面或负面结果。从上述四个统计量中,您将计算精度和召回率,它们是分类模型性能的常用度量:
-
精度是真阳性与您的模型标记为阳性(真阳性和假阳性)的所有项目的比率。精度为 1.0 意味着您的模型标记为正面的每条评论都属于正面类别。
-
召回率是真阳性与所有实际阳性的评论的比率,或真阳性的数量除以真阳性和假阴性的总数。
在F-得分是另一种流行的精度测量,尤其是在NLP的世界。解释它可能需要自己的文章,但您将在代码中看到计算。与准确率和召回率一样,分数范围从 0 到 1,其中 1 表示性能最高,0 表示性能最低。
对于evaluate_model(),您需要传入管道的tokenizer组件、textcat组件和您的测试数据集:
def evaluate_model(
tokenizer, textcat, test_data: list
) -> dict:
reviews, labels = zip(*test_data)
reviews = (tokenizer(review) for review in reviews)
true_positives = 0
false_positives = 1e-8 # Can't be 0 because of presence in denominator
true_negatives = 0
false_negatives = 1e-8
for i, review in enumerate(textcat.pipe(reviews)):
true_label = labels[i]
for predicted_label, score in review.cats.items():
# Every cats dictionary includes both labels. You can get all
# the info you need with just the pos label.
if (
predicted_label == "neg"
):
continue
if score >= 0.5 and true_label["pos"]:
true_positives += 1
elif score >= 0.5 and true_label["neg"]:
false_positives += 1
elif score < 0.5 and true_label["neg"]:
true_negatives += 1
elif score < 0.5 and true_label["pos"]:
false_negatives += 1
precision = true_positives / (true_positives + false_positives)
recall = true_positives / (true_positives + false_negatives)
if precision + recall == 0:
f_score = 0
else:
f_score = 2 * (precision * recall) / (precision + recall)
return {"precision": precision, "recall": recall, "f-score": f_score}在此函数中,您将评论及其标签分开,然后使用生成器表达式标记您的每个评估评论,准备将它们传递给textcat. 生成器表达式是spaCy 文档中推荐的一个很好的技巧,它允许您遍历标记化的评论,而无需将每个评论都保留在内存中。
然后使用score和true_label来确定真假阳性和真假阴性。然后,您可以使用它们来计算精度、召回率和 f 分数。现在剩下的就是实际调用evaluate_model():
def train_model(training_data: list, test_data: list, iterations: int = 20):
# Previously seen code omitted for brevity.
# Training loop
print("Beginning training")
print("Loss\tPrecision\tRecall\tF-score")
batch_sizes = compounding(
4.0, 32.0, 1.001
) # A generator that yields infinite series of input numbers
for i in range(iterations):
loss = {}
random.shuffle(training_data)
batches = minibatch(training_data, size=batch_sizes)
for batch in batches:
text, labels = zip(*batch)
nlp.update(
text,
labels,
drop=0.2,
sgd=optimizer,
losses=loss
)
with textcat.model.use_params(optimizer.averages):
evaluation_results = evaluate_model(
tokenizer=nlp.tokenizer,
textcat=textcat,
test_data=test_data
)
print(
f"{loss['textcat']}\t{evaluation_results['precision']}"
f"\t{evaluation_results['recall']}"
f"\t{evaluation_results['f-score']}"
)在这里,您添加一个打印语句来帮助组织输出evaluate_model(),然后使用.use_params()上下文管理器调用它,以便在当前状态下使用模型。然后调用evaluate_model()并打印结果。
训练过程完成后,最好保存您刚刚训练的模型,以便您可以再次使用它而无需训练新模型。在您的训练循环之后,添加此代码以将训练后的模型保存到model_artifacts位于您的工作目录中的名为的目录中:
# Save model
with nlp.use_params(optimizer.averages):
nlp.to_disk("model_artifacts")
此代码段将您的模型保存到一个名为的目录中,model_artifacts以便您可以在不重新训练模型的情况下进行调整。您的最终训练函数应如下所示:
def train_model(
training_data: list,
test_data: list,
iterations: int = 20
) -> None:
# Build pipeline
nlp = spacy.load("en_core_web_sm")
if "textcat" not in nlp.pipe_names:
textcat = nlp.create_pipe(
"textcat", config={"architecture": "simple_cnn"}
)
nlp.add_pipe(textcat, last=True)
else:
textcat = nlp.get_pipe("textcat")
textcat.add_label("pos")
textcat.add_label("neg")
# Train only textcat
training_excluded_pipes = [
pipe for pipe in nlp.pipe_names if pipe != "textcat"
]
with nlp.disable_pipes(training_excluded_pipes):
optimizer = nlp.begin_training()
# Training loop
print("Beginning training")
print("Loss\tPrecision\tRecall\tF-score")
batch_sizes = compounding(
4.0, 32.0, 1.001
) # A generator that yields infinite series of input numbers
for i in range(iterations):
print(f"Training iteration {i}")
loss = {}
random.shuffle(training_data)
batches = minibatch(training_data, size=batch_sizes)
for batch in batches:
text, labels = zip(*batch)
nlp.update(text, labels, drop=0.2, sgd=optimizer, losses=loss)
with textcat.model.use_params(optimizer.averages):
evaluation_results = evaluate_model(
tokenizer=nlp.tokenizer,
textcat=textcat,
test_data=test_data
)
print(
f"{loss['textcat']}\t{evaluation_results['precision']}"
f"\t{evaluation_results['recall']}"
f"\t{evaluation_results['f-score']}"
)
# Save model
with nlp.use_params(optimizer.averages):
nlp.to_disk("model_artifacts")在本节中,您学习了如何训练模型并在训练时评估其性能。然后,您构建了一个函数,用于在输入数据上训练分类模型。
分类评论
现在您有了一个经过训练的模型,是时候根据真实评论对其进行测试了。出于本项目的目的,您将对评论进行硬编码,但您当然应该尝试通过阅读其他来源的评论(例如文件或评论聚合器的 API)来扩展该项目。
这个新功能的第一步是加载之前保存的模型。虽然您可以在内存中使用模型,但加载保存的模型工件允许您有选择地完全跳过训练,稍后您将看到。这是test_model()签名以及加载已保存模型的代码:
def test_model(input_data: str=TEST_REVIEW):
# Load saved trained model
loaded_model = spacy.load("model_artifacts")
在此代码中,您定义了test_model(),其中包含input_data参数。然后加载之前保存的模型。
您正在使用的 IMDB 数据包括unsup训练数据目录中的一个目录,其中包含可用于测试模型的未标记评论。这是一篇这样的评论。您应该将它(或您选择的另一个)保存在TEST_REVIEW文件顶部的常量中:
import os
import random
import spacy
from spacy.util import minibatch, compounding
TEST_REVIEW = """
Transcendently beautiful in moments outside the office, it seems almost
sitcom-like in those scenes. When Toni Colette walks out and ponders
life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide
whether it's slapstick, farce, magical realism, or drama, but the best of it
doesn't matter. (The worst is sort of tedious - like Office Space with less humor.)
"""
接下来,您将此评论传递到您的模型中以生成预测,准备显示,然后将其显示给用户:
def test_model(input_data: str = TEST_REVIEW):
# Load saved trained model
loaded_model = spacy.load("model_artifacts")
# Generate prediction
parsed_text = loaded_model(input_data)
# Determine prediction to return
if parsed_text.cats["pos"] > parsed_text.cats["neg"]:
prediction = "Positive"
score = parsed_text.cats["pos"]
else:
prediction = "Negative"
score = parsed_text.cats["neg"]
print(
f"Review text: {input_data}\nPredicted sentiment: {prediction}"
f"\tScore: {score}"
)
在此代码中,您将 your 传递给input_datayour loaded_model,它会cats在parsed_text变量的属性中生成预测。然后您检查每种情绪的分数并将最高的分数保存在prediction变量中。
然后将该情绪的分数保存到score变量中。这将使创建人类可读的输出变得更容易,这是此函数的最后一行。
现在,你已经写了load_data(),train_model(),evaluate_model(),和test_model()功能。这意味着是时候将它们放在一起并训练您的第一个模型了。
连接管道
到目前为止,您已经构建了许多独立的函数,这些函数结合在一起将加载数据,并在 Python 中训练、评估、保存和测试情感分析分类器。
使这些函数可用的最后一步是在脚本运行时调用它们。您将使用if __name__ == "__main__":习语来完成此操作:
if __name__ == "__main__":
train, test = load_training_data(limit=2500)
train_model(train, test)
print("Testing model")
test_model()
在这里,您可以使用您在加载和预处理数据部分中编写的函数加载您的训练数据,并限制用于2500总计的评论数量。然后,您使用train_model()您在Training Your Classifier 中编写的函数训练模型,完成后,您调用test_model()以测试模型的性能。
注意:使用此数量的训练示例,训练可能需要 10 分钟或更长时间,具体取决于您的系统。您可以减少训练集大小以缩短训练时间,但您将面临模型精度较低的风险。
你的模型预测了什么?你同意这个结果吗?如果limit在加载数据时增加或减少参数会发生什么?您的分数甚至您的预测可能会有所不同,但您应该期望输出如下所示:
$ python pipeline.py
Training model
Beginning training
Loss Precision Recall F-score
11.293997120810673 0.7816593886121546 0.7584745762390477 0.7698924730851658
1.979159922178951 0.8083333332996527 0.8220338982702527 0.8151260503859189
[...]
0.000415042785704145 0.7926829267970453 0.8262711864056664 0.8091286306718204
Testing model
Review text:
Transcendently beautiful in moments outside the office, it seems almost
sitcom-like in those scenes. When Toni Colette walks out and ponders
life silently, it's gorgeous.<br /><br />The movie doesn't seem to decide
whether it's slapstick, farce, magical realism, or drama, but the best of it
doesn't matter. (The worst is sort of tedious - like Office Space with less humor.)
Predicted sentiment: Positive Score: 0.8773064017295837
当您的模型训练时,您将看到每次训练迭代的损失、精度和召回率以及 F 分数。您应该会看到损失通常会减少。准确率、召回率和 F 分数都会反弹,但理想情况下它们会增加。然后您将看到测试评论、情绪预测和该预测的分数——越高越好。
您现在已经使用自然语言处理技术和带有 spaCy 的神经网络训练了您的第一个情感分析机器学习模型!以下两张图表显示了模型在 20 次训练迭代中的表现。第一个图表显示了训练过程中损失的变化:
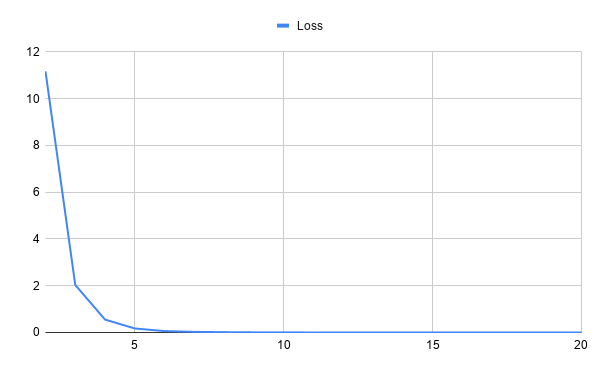
虽然上图显示了随时间的损失,但下图绘制了同一训练期间的准确率、召回率和 F 分数:
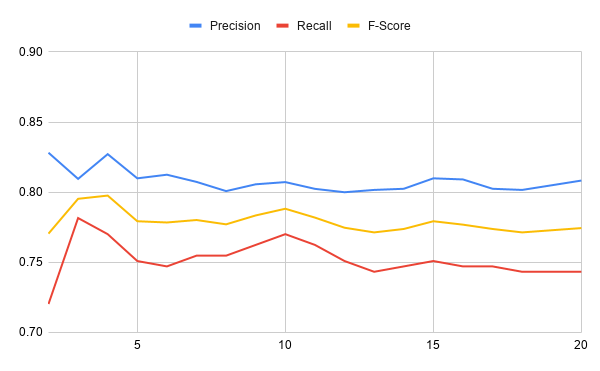
在这些图表中,您可以看到损失开始很高,但在训练迭代中下降得非常快。在前几次训练迭代后,精度、召回率和 F 分数非常稳定。您可以修改什么来提高这些值?
结论
恭喜你用 Python 构建了你的第一个情感分析模型!你觉得这个项目怎么样?您不仅构建了一个有用的数据分析工具,而且还掌握了自然语言处理和机器学习的许多基本概念。
在本教程中,您学习了如何:
- 使用自然语言处理技术
- 使用机器学习分类器确定已处理文本数据的情绪
- 使用 spaCy构建您自己的NLP 管道
您现在拥有基本工具包来构建更多模型来回答您可能遇到的任何研究问题。如果您想复习所学内容,可以通过以下链接下载并试验本教程中使用的代码:
你还能用这个项目做什么?请参阅下面的一些建议。
情绪分析和 Python 的后续步骤
这是一个核心项目,根据您的兴趣,您可以围绕它构建很多功能。以下是一些帮助您开始扩展此项目的想法:
-
数据加载过程在
load_data(). 你可以通过使用生成器函数来提高内存效率吗? -
重写您的代码以在预处理或数据加载期间删除停用词。模式性能如何变化?您可以将此预处理合并到管道组件中吗?
-
使用Click to generate an interactive command-line interface 之类的工具。
-
将您的模型部署到AWS等云平台并将 API 连接到该平台。这可以构成基于网络的工具的基础。
-
探索的配置参数的
textcat管道组件和具有不同配置的实验。 -
探索传递新评论以生成预测的不同方式。
-
参数化选项,例如保存和加载训练模型的位置、是跳过训练还是训练新模型等。
该项目使用由Andrew Maas维护的大型电影评论数据集。感谢 Andrew 使这个精选的数据集广泛可用。

- 点赞
- 收藏
- 关注作者
评论(0)