性能工具之常见压力工具是否能模拟前端


前言
前几天在整理前端的性能分析时,觉得有个问题点似乎从来没人说起过。
就是压力测试的工具,是否可以模拟出前端的完整的请求链?比如说,loadrunner/Jmeter 等压力工具。
我们都知道,现在的很多性能测试都从接口开始做了,而前端的性能成了一个独立的一部分。
在早期的性能测试工具中,一直秉承的理念是“模拟真实用户的行为”。
而纵观现在的性能测试策略和方法,离真实的用户越来越远的感觉。
所以现在提出了另一个思路:全链路性能测试。而这一观念的改变中基于架构的转变来的。但是从实际的操作上来说,性能测试策略、场景等一些本质的东西并没有发生变化。
鉴于一些项目的经验,以后我会从全链路的思路上来做更多的整理和分析。
今天我只想说一个点就是压力工具有哪些前端的动作没有模拟得到?
浏览器的渲染原理
我们先来看一下浏览器的渲染过程:
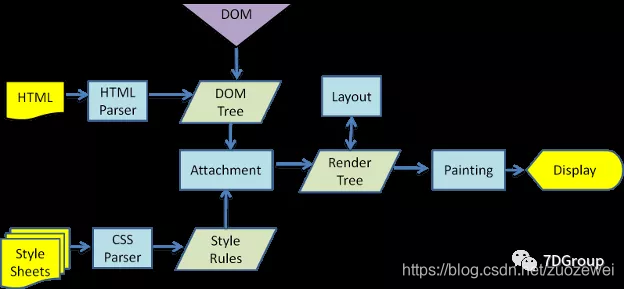
是 webkit 内核的工作过程。从 HTML 解析到 Display 的整个过程中,大家可以清晰的看到前端在干什么事情。显然,这些在浏览器端做的事情压力工具都是不可能做得到的。比如说:HTML解析、DOMtree 创建、CSS 解析、渲染树、绘制等等,这些压力工具都是不会干的。
那压力工具能干什么呢?
我们换个姿势来看。
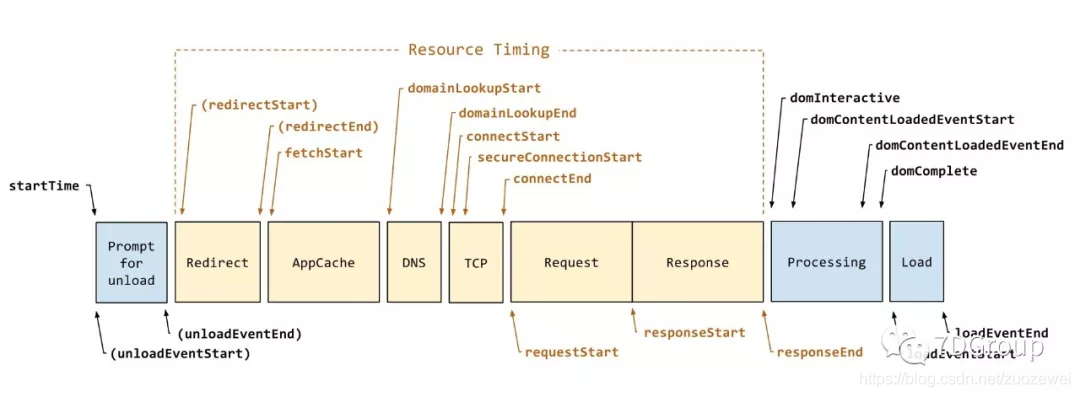
从在浏览器中输入 URL 到开始加载这个过程,浏览器做的动作,压力工具是都不会模拟到的。
但是从 redirect 开始、AppCache、DNS 解析、TCP 创建、请求的发送、响应的接收,这个过程中压力工具不可避免要做的事情。
接下来的本地的这些处理的动作是压力工具都不干的了。
这下似乎明白了吧。
那我们再换个姿势看一下:
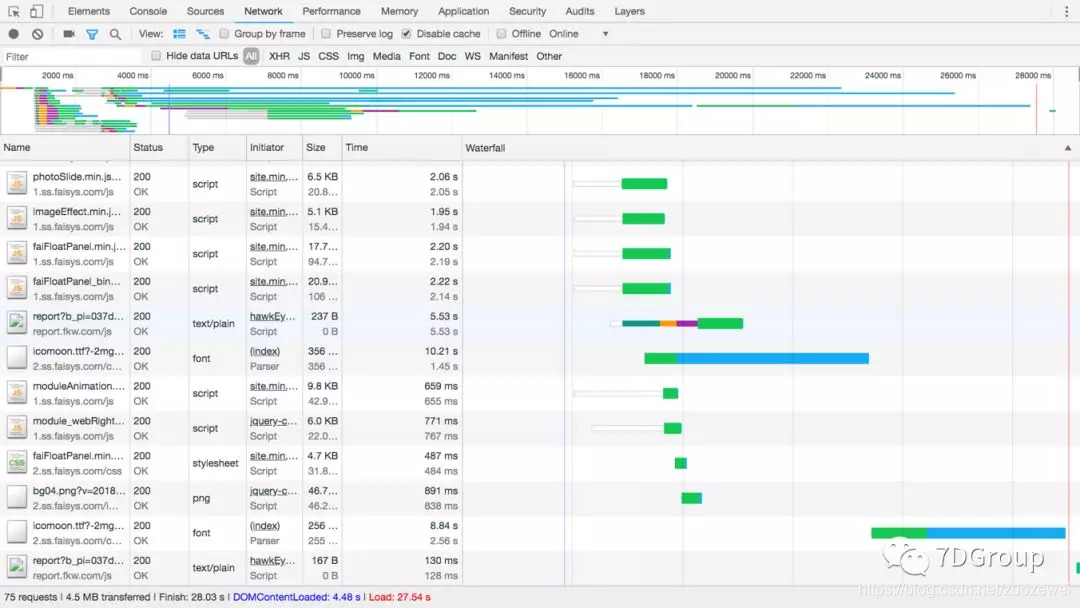
一个 URL 请求发送了之后,有更多的细分资源需要一一处理。而这些资源的处理就会一遍遍在走着请求的发送、响应的接收这个循环。因为 AppCache、DNS 解析、TCP 创建这些部分是可以复用的(这句话有歧义,大家自行揣摩)。
另外,在 RFC2616 中的 8.1.1 节明确说明了限制浏览器的并发。大概翻译如下,有兴趣的去读下原文:
- 少开 TCP 链接,可以节省路由和主机(客户端、服务端、代理、网关、通道、缓存)的 CPU 资源和内存资源。
- HTTP 请求和响应可以通过 Pipelining 在一个连接上发送。Pipelining 允许客户端发出多个请求而不用等待每个返回,一个 TCP 连接更为高效。
- 通过减少打开的 TCP 来减少网络拥堵,也让 TCP 有充足的时间解决拥堵。
- 后续请求不用在 TCP 三次握手上再花时间,延迟降低。
- 因为报告错误时,没有关闭 TCP 连接的惩罚,而使 HTTP 可以升级得更为优雅(原文使用 gracefully)。
- 如果不限制的话,一个客户端发出很多个链接到服务器,服务器的资源可以同时服务的客户端就会减少。
我们常见的浏览器有如下的并发限制。
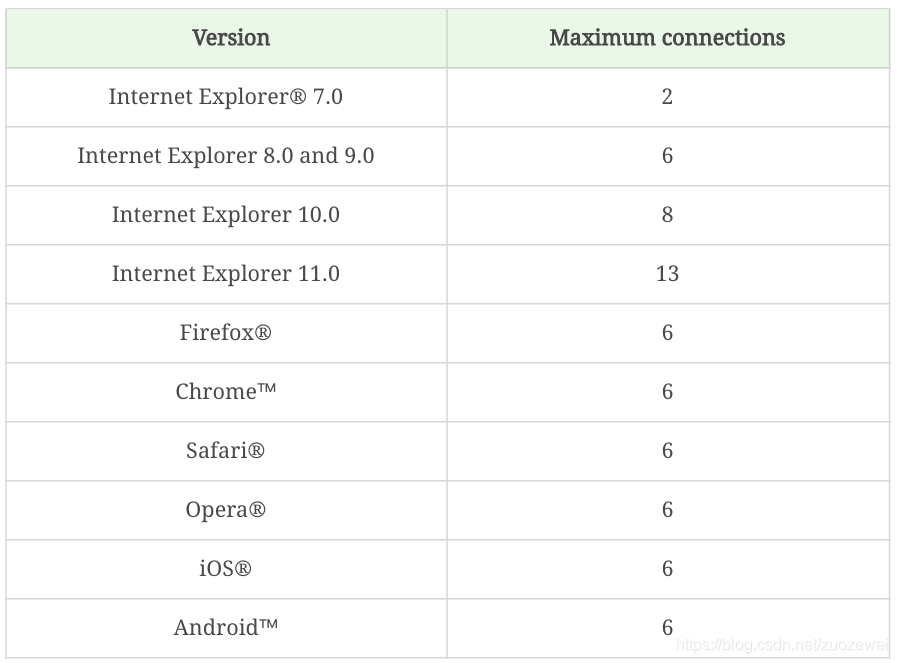
在压力工具中,并没有参数来控制这个并发值,如果是在同一个线程中,就是并行着执行下去。
我们再细分一下一个请求的具体的动作。
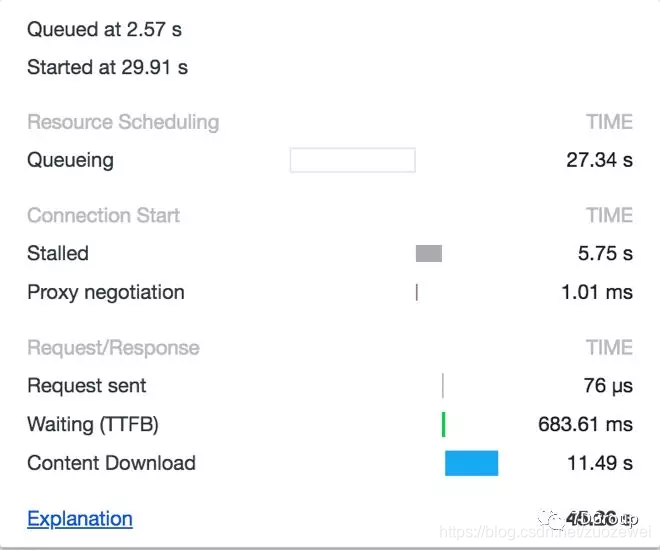
每个请求,都在这样的循环中消耗着时间。进队列-等-阻塞-发请求-等TTFB-下载。
而这个过程是压力工具可以模拟得到的。
所以,如果要分析前端的性能的话,我们最好可以区分开哪些时间消耗在了前端,哪些时间消耗在了后端。
这样才可以把性能时间拆分更细化。
总结
目前的压力工具大部分是针对服务端,即模拟「网络 API 请求」,而前端程序基本上是由一系列的「用户交互事件」所驱动,其业务状态是一颗 DOM 树。
通常来讲,前端性能关注的是浏览器端的页面渲染时间、资源加载顺序、请求数量、前端缓存使用情况、资源压缩等内容,希望借此找到页面加载过程中比较耗时的操作和资源,然后进行有针对性的优化,最终达到优化终端用户在浏览器端使用体验的目的。
目前获取和衡量一个页面的性能,主要可以通过以下几个方面:Performance Timing API、Prpfile 工具、页面埋点计时、资源加载时序图分析;
Performance Timing API是一个支持 Internet Explorer 9以上版本及 WebKit;
内核浏览器中用于记录页面加载和解析过程中关键时间点的机制,它可以详细记录每个页面资源从开始加载到解析完成这一过程中具体操作发生的时间点,这样根据开始和结束时间戳就可以计算出这个过程所花的时间了;- Profile 是 Chrome 和 Firefox 等标准浏览器提供的一种用于测试页面脚本运行时系统内存和 CPU 资源占用情况的 API;
- 通过脚本埋点计时的方式来统计没部分代码的运行时间;
- 借助浏览器或其他工具的资源加载时序图来帮助分析页面资源加载过程中的性能问题。这种方法可以粗粒度地宏观分析浏览器的所有资源文件请求耗时和文件加载顺序情况。

- 点赞
- 收藏
- 关注作者
评论(0)