Apache Sqoop 教程 - 在 HDFS 和 RDBMS 之间导入/导出数据

在开始本 Apache Sqoop 教程之前,让我们先退一步。您是否还记得数据摄取的重要性,正如我们在之前关于Apache Flume 的博客中所讨论的那样。现在,我们知道 Apache Flume 是用于非结构化源的数据摄取工具,但组织将其操作数据存储在关系数据库中。因此,需要一种可以从关系数据库导入和导出数据的工具。这就是 Apache Sqoop 诞生的原因。Sqoop 可以轻松地与 Hadoop 集成并从 HDFS 上的关系数据库转储结构化数据,从而补充 Hadoop 的强大功能。这就是为什么 Apache Sqoop 和 Flume 有充分的了解。
最初,Sqoop 是由 Cloudera 开发和维护的。后来,在 2011 年 7 月 23 日,它被 Apache 孵化。2012年4月,Sqoop项目被提升为Apache的顶级项目。
在这个 Apache Flume 教程博客中,我们将介绍:
我们将通过介绍 Apache Sqoop 开始本 Apache Sqoop 教程。然后继续前进,我们将了解使用 Apache Sqoop 的优势。
Apache Sqoop 教程:Sqoop 介绍
 通常,应用程序使用 RDBMS 与关系数据库进行交互,因此这使得关系数据库成为生成大数据的最重要来源之一。此类数据以关系结构存储在 RDB 服务器中。在这里,Apache Sqoop 在Hadoop 生态系统中扮演着重要的角色,提供关系数据库服务器和 HDFS 之间的可行交互。
通常,应用程序使用 RDBMS 与关系数据库进行交互,因此这使得关系数据库成为生成大数据的最重要来源之一。此类数据以关系结构存储在 RDB 服务器中。在这里,Apache Sqoop 在Hadoop 生态系统中扮演着重要的角色,提供关系数据库服务器和 HDFS 之间的可行交互。
因此,Apache Sqoop 是Hadoop 生态系统中的一个工具,旨在在HDFS(Hadoop 存储)和关系数据库服务器(如 MySQL、Oracle RDB、SQLite、Teradata、Netezza、Postgres 等)之间传输数据。Apache Sqoop 将数据从关系数据库导入 HDFS ,并将数据从 HDFS 导出到关系数据库。它有效地在 Hadoop 和外部数据存储(如企业数据仓库、关系数据库等)之间传输批量数据。
这是Sqoop如何得到它的名字- “ SQ L到当初接力和Hadoop的到SQL”。
此外,Sqoop 用于将数据从外部数据存储导入 Hadoop 生态系统的工具,如Hive和HBase。
现在,我们知道什么是 Apache Sqoop。因此,让我们继续我们的 Apache Sqoop 教程,了解为什么 Sqoop 被组织广泛使用。
Apache Sqoop 教程:为什么选择 Sqoop?
对于 Hadoop 开发人员来说,真正的游戏是在数据加载到 HDFS 之后开始的。他们使用这些数据以获得隐藏在 HDFS 中存储的数据中的各种见解。
因此,对于此分析,需要将驻留在关系数据库管理系统中的数据传输到 HDFS。编写MapReduce代码以将数据从关系数据库导入和导出到 HDFS 的任务无趣且乏味。这就是 Apache Sqoop 来拯救并消除他们的痛苦的地方。它使导入和导出数据的过程自动化。
Sqoop 通过提供用于导入和导出数据的 CLI 使开发人员的生活变得轻松。他们只需要提供数据库认证、来源、目的地、操作等基本信息。剩下的部分由它来处理。
Sqoop 在内部将命令转换为 MapReduce 任务,然后在 HDFS 上执行。它使用 YARN 框架来导入和导出数据,在并行性之上提供容错。
在此 Sqoop 教程博客中继续前进,我们将了解 Sqoop 的主要功能,然后我们将继续介绍 Apache Sqoop 架构。
Apache Sqoop 教程:Sqoop 的主要特性
Sqoop 提供了许多突出的功能,例如:
- Full Load:Apache Sqoop 可以通过单个命令加载整个表。您还可以使用单个命令从数据库加载所有表。
- 增量 加载:Apache Sqoop 还提供了增量加载功能,您可以在表更新时加载其中的一部分。
- 并行 导入/导出:Sqoop 使用 YARN 框架来导入和导出数据,它在并行性之上提供容错。
- 导入 结果 的 SQL 查询:您还可以导入从HDFS的SQL查询返回的结果。
- 压缩:您可以使用带有 –compress 参数的 deflate(gzip) 算法或指定 –compression-codec 参数来压缩数据。您还可以在Apache Hive 中加载压缩表。
- 连接器 对 所有 主要 RDBMS 数据库:阿帕奇Sqoop提供连接器,用于多RDBMS数据库,几乎覆盖了整个圆周。
- Kerberos 安全 集成:Kerberos 是一种计算机网络身份验证协议,它基于“票据”工作,允许节点通过非安全网络进行通信,以安全方式相互证明其身份。Sqoop 支持 Kerberos 身份验证。
- 将 数据 直接 加载到 HIVE/HBase 中:您可以将数据直接加载到Apache Hive 中进行分析,也可以将数据转储到 HBase 中,HBase 是一个 NoSQL 数据库。
- 对 Accumulo 的支持:您还可以指示 Sqoop 导入 Accumulo 中的表而不是 HDFS 中的目录。
该架构是一种赋予 Apache Sqoop 以这些好处的架构。现在,当我们了解了 Apache Sqoop 的特性后,让我们继续前进并了解 Apache Sqoop 的架构和工作原理。
Apache Sqoop 教程:Sqoop 架构和工作
让我们使用下图了解 Apache Sqoop 的工作原理:
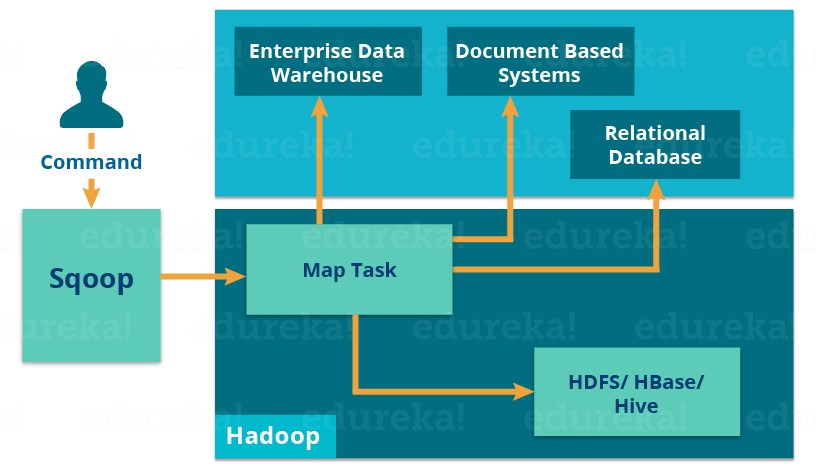
导入工具将单个表从 RDBMS 导入到 HDFS。表中的每一行都被视为 HDFS 中的一条记录。
当我们提交 Sqoop 命令时,我们的主要任务被分成子任务,这些子任务由各个 Map Task 内部处理。Map Task是子任务,将部分数据导入Hadoop生态系统。总的来说,所有 Map 任务都会导入整个数据。
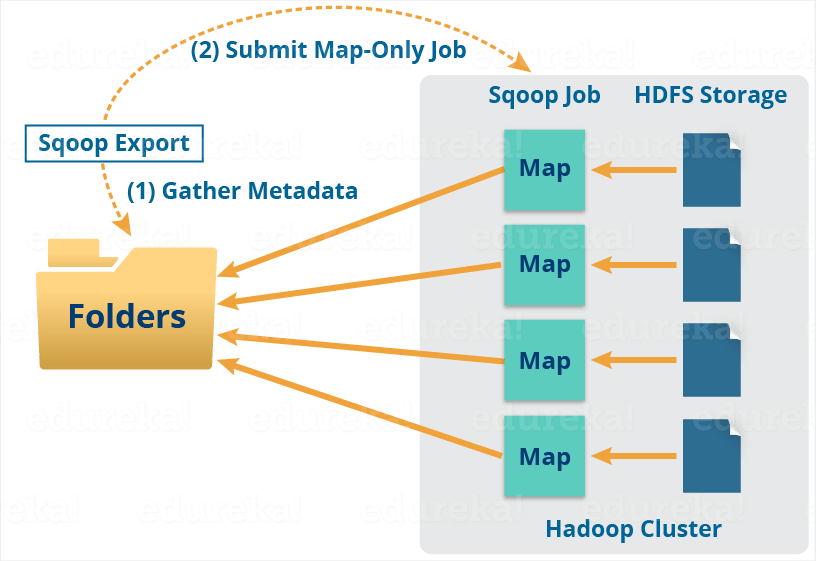
导出也以类似的方式工作。
导出工具将一组文件从 HDFS 导出回 RDBMS。作为 Sqoop 输入的文件包含记录,在表中称为行。
当我们提交我们的 Job 时,它被映射到 Map Tasks 中,它从 HDFS 中获取数据块。这些块被导出到结构化数据目标。结合所有这些导出的数据块,我们在目的地接收整个数据,在大多数情况下是一个 RDBMS(MYSQL/Oracle/SQL Server)。
在聚合的情况下需要减少阶段。但是,Apache Sqoop 只是导入和导出数据;它不执行任何聚合。映射作业根据用户定义的数量启动多个映射器。对于 Sqoop 导入,每个映射器任务都会分配一部分要导入的数据。Sqoop 在映射器之间平均分配输入数据以获得高性能。然后每个映射器使用 JDBC 创建与数据库的连接,并根据 CLI 中提供的参数获取 Sqoop 分配的部分数据并将其写入 HDFS 或 Hive 或 HBase。
现在我们了解了 Apache Sqoop 的架构和工作方式,让我们了解 Apache Flume 和 Apache Sqoop 之间的区别。
Apache Sqoop 教程:Flume 与 Sqoop
Flume 和 Sqoop 的主要区别在于:
- Flume 只将非结构化数据或半结构化数据摄取到 HDFS 中。
- Sqoop 可以将结构化数据从 RDBMS 或企业数据仓库导入和导出到 HDFS,反之亦然。
现在,在我们的 Apache Sqoop 教程中前进是时候了解 Apache Sqoop 命令了。
Apache Sqoop 教程:Sqoop 命令
-
Sqoop – 导入命令
导入命令用于将关系数据库中的表导入到 HDFS。在我们的例子中,我们要将表从 MySQL 数据库导入到 HDFS。
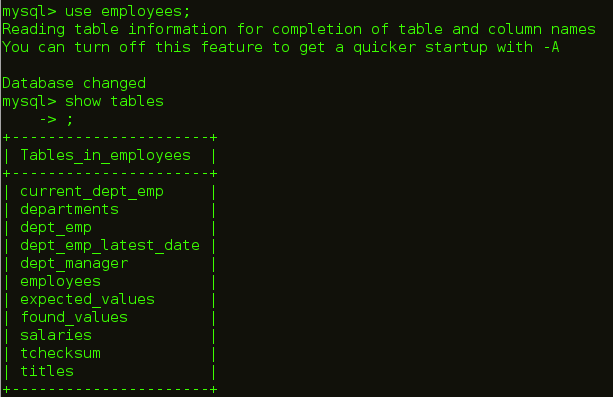
如下图所示,我们在员工数据库中有员工表,我们将把它导入到 HDFS 中。
导入表的命令是:
sqoop import --connect jdbc:mysql://localhost/employees --username edureka --table employees

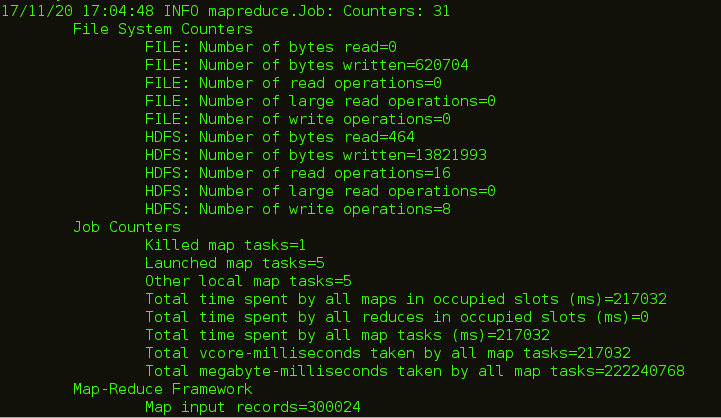
如下图所示,执行此命令后,Map 任务将在后端执行。
代码执行完后,可以查看HDFS的Web UI即localhost:50070导入数据。


-
Sqoop – 带有目标目录的 IMPORT 命令
您还可以使用以下命令在 HDFS 的特定目录中导入表:
sqoop import --connect jdbc:mysql://localhost/employees --username edureka --table employees --m 1 --target-dir /employees
Sqoop 从大多数数据库源并行导入数据。-m属性用于指定要执行的映射器的数量。
Sqoop 从大多数数据库源并行导入数据。您可以使用-m或–num-mappers参数指定用于执行导入的映射任务(并行进程)的数量。这些参数中的每一个都采用一个整数值,该值对应于要采用的并行度。
您可以独立于目录中存在的文件数来控制映射器的数量。导出性能取决于并行度。默认情况下,Sqoop 将并行使用四个任务进行导出过程。这可能不是最佳选择,您需要尝试自己的特定设置。额外的任务可能会提供更好的并发性,但如果数据库在更新索引、调用触发器等方面已经遇到瓶颈,那么额外的负载可能会降低性能。

您可以在下图中看到,mapper 任务的数量为 1。

导入 MySQL 表时创建的文件数等于创建的映射器数。

-
Sqoop – 带有 Where 子句的 IMPORT 命令
您可以使用 Sqoop 导入工具中的“where”子句导入表的子集。它在相应的数据库服务器中执行相应的 SQL 查询,并将结果存储在 HDFS 的目标目录中。您可以使用以下命令导入带有“ where ”子句的数据:
sqoop import --connect jdbc:mysql://localhost/employees --username edureka --table employees --m 3 --where "emp_no > 49000" --target-dir /Latest_Employees


-
Sqoop – 增量导入
Sqoop 提供了一种增量导入模式,可用于仅检索比某些先前导入的行集更新的行。Sqoop 支持两种类型的增量导入:append 和lastmodified。您可以使用 –incremental 参数指定要执行的增量导入的类型。
您应该在导入表时指定追加模式,其中新行随着行 id 值的增加而不断添加。您可以使用–check-column指定包含行 ID的列。Sqoop 导入检查列的值大于用–last-value指定的值的行。
Sqoop 支持的另一种表更新策略称为lastmodified模式。当源表的行可能被更新时,您应该使用它,并且每次这样的更新都会将最后修改列的值设置为当前时间戳。
在运行后续导入时,您应该以这种方式指定–last-value以确保仅导入新的或更新的数据。这是通过将增量导入创建为保存的作业来自动处理的,这是执行重复增量导入的首选机制。
首先,我们插入一个新行,该行将在我们的 HDFS 中更新。

增量导入的命令是:
sqoop import --connect jdbc:mysql://localhost/employees --username edureka --table employees --target-dir /Latest_Employees --incremental append --check-column emp_no --last-value 499999

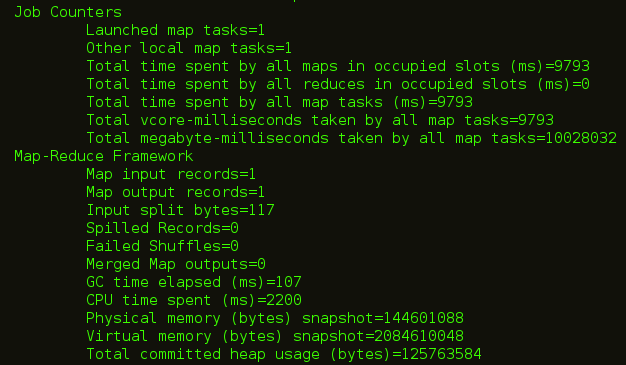
您可以在下图中看到,使用更新后的数据创建了一个新文件。

-
Sqoop - 导入所有表
您可以将 RDBMS 数据库服务器中的所有表导入 HDFS。每个表数据存储在单独的目录中,目录名与表名相同。该数据库中的每个表都必须有一个主键字段。从数据库中导入所有表的命令是:
sqoop import-all-tables --connect jdbc:mysql://localhost/employees --username edureka


-
Sqoop – 列出数据库
您可以使用 Sqoop 列出关系数据库中存在的数据库。Sqoop list-databases 工具解析并执行针对数据库服务器的“SHOW DATABASES”查询。列出数据库的命令是:
sqoop list-databases --connect jdbc:mysql://localhost/ --username edureka

-
Sqoop – 列出表
您还可以使用 Sqoop 列出 MySQL 数据库服务器中特定数据库的表。Sqoop 列表表工具解析并执行“SHOW TABLES”查询。列出表是一个数据库的命令是:
sqoop list-tables --connect jdbc:mysql://localhost/employees --username edureka


-
Sqoop – 导出
如上所述,您还可以将数据从 HDFS 导出到 RDBMS 数据库。目标表必须存在于目标数据库中。 数据作为记录存储在 HDFS 中。这些记录被读取、解析并使用用户指定的分隔符进行分隔。 默认操作是使用 INSERT 语句将输入文件中的所有记录插入到数据库表中。在更新模式下,Sqoop 生成 UPDATE 语句将现有记录替换到数据库中。
所以,首先我们创建一个空表,我们将在其中导出我们的数据。

将数据从 HDFS 导出到关系数据库的命令是:
sqoop export --connect jdbc:mysql://localhost/employees --username edureka --table emp --export-dir /user/edureka/employees


-
Sqoop - 代码生成器
在面向对象的应用程序中,每个数据库表都有一个数据访问对象类,其中包含用于初始化对象的“getter”和“setter”方法。Codegen 自动生成 DAO 类。它基于表模式结构在 Java 中生成 DAO 类。
生成java代码的命令是:
sqoop codegen --connect jdbc:mysql://localhost/employees --username edureka --table employees

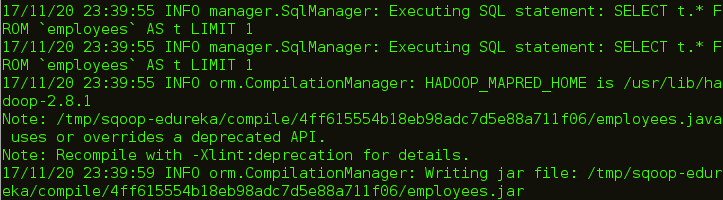
您可以在上图中看到生成代码的路径。让我们去路径并检查创建的文件。

我希望这个博客能给你提供信息并增加价值。如果您有兴趣了解更多信息,可以阅读此Hadoop 教程系列 ,该 系列向您介绍大数据以及 Hadoop 如何解决与大数据相关的挑战。

- 点赞
- 收藏
- 关注作者
评论(0)