Python网络爬虫之scrapy框架

【摘要】 Python网络爬虫与信息提取 - 嵩天
官网:https://scrapy.org/
安装:pip install scrapy
检测:scrapy -h
scrapy爬虫框架结构
爬虫框架 - 爬虫框架 是实现爬虫功能的一个软件结构和功能组件集合 - 爬虫框架 是一个半成品,能够帮助用户实现专业网络爬虫
5+2结构 - Scheduler - 用户不修...
Python网络爬虫与信息提取 - 嵩天
安装:pip install scrapy
检测:scrapy -h
scrapy爬虫框架结构
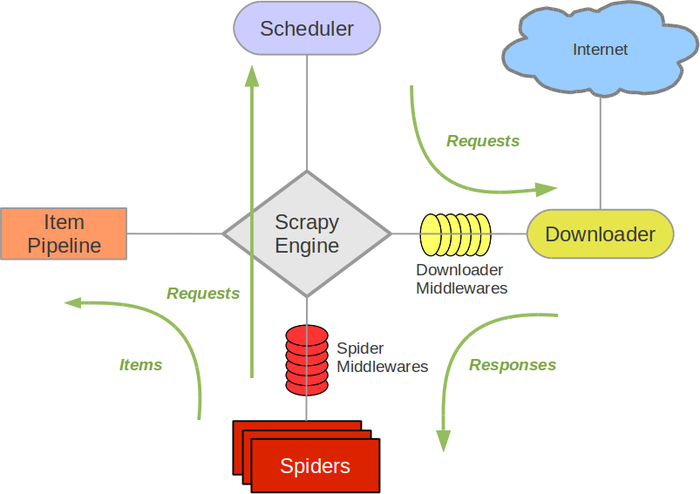
爬虫框架 - 爬虫框架 是实现爬虫功能的一个软件结构和功能组件集合 - 爬虫框架 是一个半成品,能够帮助用户实现专业网络爬虫
5+2结构 - Scheduler - 用户不修改 - 对所有爬取请求进行调度管理 - Engine - 用户不修改 - 控制数据流,根据条件触发事件 - Downloader - 用户不修改 - 根据请求下载网页 - Spider - 用户配置代码 - 解析downloader返回的响应Response - 产生爬取项scrapy item - 产生额外的爬取请求Request - Item-Piplines - 用户配置代码 - 以流水线方式处理Spider产生的爬取项 - 由一组操作顺序组成,类似流水线 - 每个操作是一个Item Pipeline类型 - 操作:清理,检验和查重爬取项中的HTML数据,将数据存储到数据库 - Spider-middleware - 用户配置代码 - 目的:对请求和爬取项在处理 - 功能:修改,丢弃,新增请求或爬取项 - Downloader-middleware - 用户配置代码 - 用户可配置的控制, - 修改,丢弃,新增请求或响应
3个数据流 简单配置,即可完成功能
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
requests vs. scrapy
requests库 - 页面级爬虫 - 功能库 - 并发性考虑不足,性能较差 - 重点在于页面下载 - 定制灵活 - 上手十分简单
scrapy框架 - 网站级爬虫 - 框架 - 并发性好,性能较高 - 重点在于爬虫结构 - 一般定制灵活,深度定制困难 - 入门稍难
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
scrapy常用命令
- startproject 创建一个新工程 scrapy startproject <name> [dir]
- genspider 创建一个爬虫 scrapy genspider [options] <name> <domain>
- settings 获得爬虫配置信息 scrapy settings [options]
- crawl 运行一个爬虫 scrapy crawl <spider>
- list 列出工程中所有爬虫 scrapy list
- shell 启动url调试命令行 scrapy shell [url]
- 保存日志 scrapy crawl <spder_name> -s LOG_FILE=scrapy.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
使用scrapy步骤:
新建项目project -》明确目标item -》 编写爬虫spdier -》 存储内容pipeline
- 建立一个scrapy爬虫工程 scrapy startproject firstspider
- 工程中产生一个scrapy爬虫 scrapy genspider demo demo.com
- 配置产生的spider爬虫 - 编写Spider - start_requests(),产生请求request - parse(),处理响应response - 编写Item Pipeline - 优化配置策略
- 运行爬虫,获取网页 scrapy crawl demo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
工程目录
firstspider/ 外层目录 scrapy.cfg 部署Scrapy爬虫的配置文件 firstspider/ Scrapy框架的用户自定义Python代码 __init__.py 初始化脚本 items.py Items代码模板(继承类) middlewares.py Middlewares代码模板(继承类) pipelines.py Pipelines代码模板(继承类) settings.py Scrapy爬虫的配置文件 __pycache__ 缓存目录,无需修改 spiders/ Spiders代码模板目录(继承类) __init__.py 初始文件,无需修改 __pycache__ 缓存目录,无需修改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
yield 生成器
- 包含yield语句的函数是一个生成器
- 生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
- 生成器是一个不断产生值的函数
- 1
- 2
- 3
scrapy数据类型
- Request类 - class scrapy.http.Request() - Request对象表示一个HTTP请求 - 由Spider生成,由Downloader执行 - 属性或方法 - url Request对应的请求URL地址 - method 对应的请求方法,'GET' 'POST'等 - headers 字典类型风格的请求头 - body 请求内容主体,字符串类型 - meta 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 - copy() 复制该请求 - Response类 - class scrapy.http.Response() - Response对象表示一个HTTP响应 - 由Downloader生成,由Spider处理 - 属性或方法 - url Response对应的URL地址 - status HTTP状态码,默认是200 - headers Response对应的头部信息 - body Response对应的内容信息,字符串类型 - flags 一组标记 - request 产生Response类型对应的Request对象 - copy() 复制该响应
- Item类 - class scrapy.item.Item() - Item对象表示一个从HTML页面中提取的信息内容 - 由Spider生成,由Item Pipeline处理 - Item类似字典类型,可以按照字典类型操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
Scrapy爬虫信息提取方法
- Beautiful Soup
- lxml
- re
- XPath Selector
- CSS Selector <html>.css("a::attr(href)").extract()
- 1
- 2
- 3
- 4
- 5
- 6
settings.py文件优化配置
CONCURRENT_REQUESTS Downloader最大并发请求下载数量,默认32
CONCURRENT_ITEMS Item Pipeline最大并发ITEM处理数量,默认100
CONCURRENT_REQUESTS_PER_DOMAIN 每个目标域名最大的并发请求数量,默认8
CONCURRENT_REQUESTS_PER_IP 每个目标IP最大的并发请求数量,默认0,非0有效
- 1
- 2
- 3
- 4
技术路线展望
- requests + beautifulsoup + re
- scrapy
- 解析js:phantomjs
- 表单提交,爬取周期,入库存储
- 扩展scrapy-*
- 1
- 2
- 3
- 4
- 5
scrapy爬虫的地位
- python语言最好的爬虫框架
- 具备企业级专业爬虫的扩展性(7x24)
- 千万级url爬取管理与部署
- scrapy足以支撑一般商业服务
- 1
- 2
- 3
- 4
scrapy爬虫的应用高阶价值
基于docker,虚拟化部署
中间件扩展,增加调度和监控
各种反爬取对抗技术
- 1
- 2
- 3
代码实例
# demo.py
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider): name = 'demo' allowed_domains = ['python123.io'] # start_urls = ['https://python123.io/ws/demo.html'] # 两者等价 def start_requests(self): urls = [ 'https://python123.io/ws/demo.html' ] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): filename = response.url.split("/")[-1] with open(filename, "wb") as f: f.write(response.body) self.log("filename : %s was saved!"%filename)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
python2中解决中文乱码的方法,在文件头部加入以下代码:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
- 1
- 2
- 3
文章来源: pengshiyu.blog.csdn.net,作者:彭世瑜,版权归原作者所有,如需转载,请联系作者。
原文链接:pengshiyu.blog.csdn.net/article/details/79736108

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)