python编程:tabula、pdfplumber、camelot进行表格数据识别

【摘要】 本文就目前python图表识别的库进行测试 1、tabula 2、pdfplumber 3、camelot
准备数据
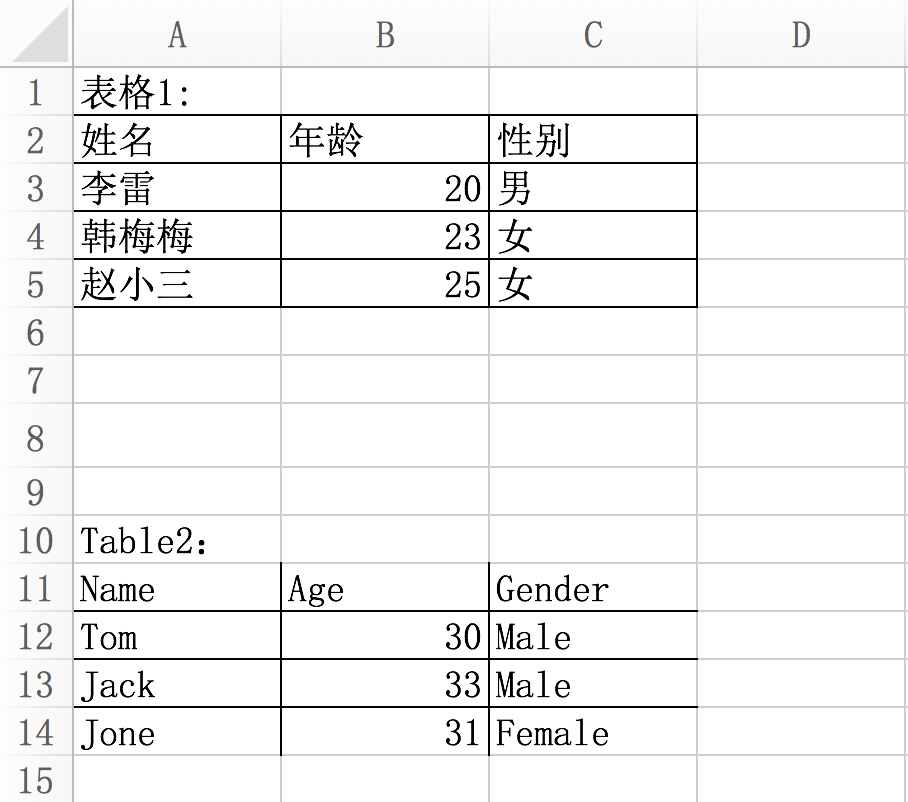
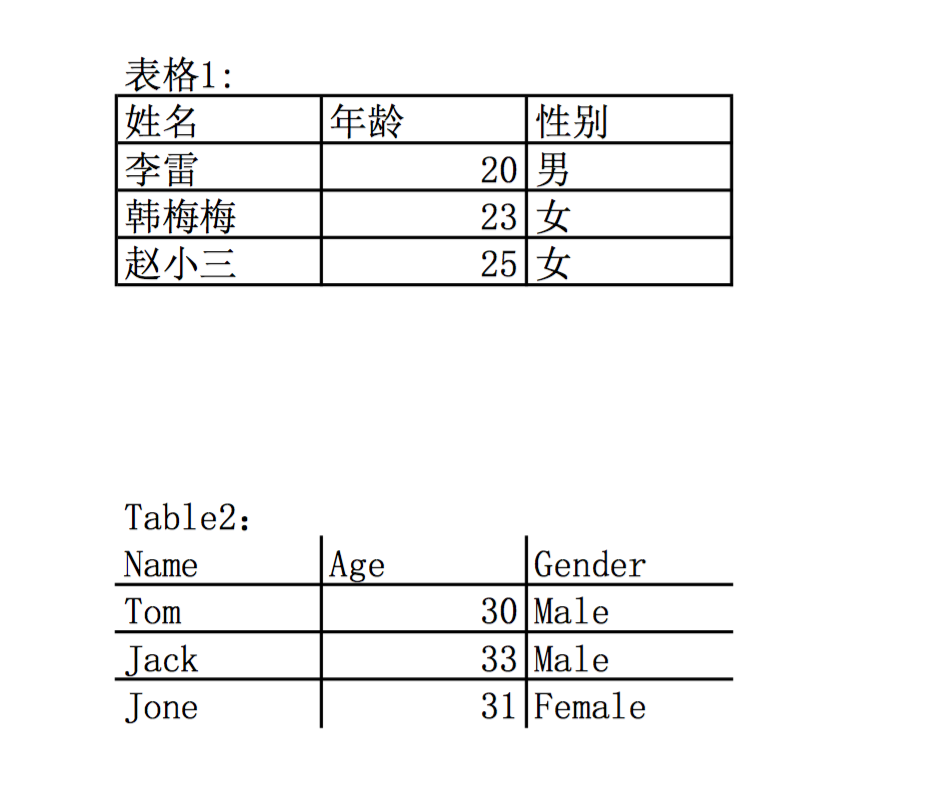
excel:names.xlsx,两个表格 表格1:所有字段都被线条包围 表格2:最外层没有线条包围
将excel另存为pdf:names.pdf
1、tabula
java项目:https://github.com/tabulapdf
...
本文就目前python图表识别的库进行测试
1、tabula
2、pdfplumber
3、camelot
准备数据
excel:names.xlsx,两个表格
表格1:所有字段都被线条包围
表格2:最外层没有线条包围
将excel另存为pdf:names.pdf
1、tabula
java项目:https://github.com/tabulapdf
自带可视化界面的pdf提取表格数据工具:
https://tabula.technology/
python接口:https://github.com/chezou/tabula-py
安装:
pip install tabula-py
- 1
依赖:
Java 7, 8
代码示例:
import tabula
tabula.convert_into( input_path="source/names.pdf", output_path="source/names.csv", output_format='csv'
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
转换出来的names.csv,发现只有表格1被提取出来了,而且不规范,中间多了逗号
"姓名",年龄,性别
"李雷",,20 男
"韩梅梅",,23 女
"赵小三",,25 女
- 1
- 2
- 3
- 4
- 5
2、pdfplumber
github: https://github.com/jsvine/pdfplumber
安装
pip install pdfplumber
- 1
代码示例:
import pdfplumber
import pandas as pd
with pdfplumber.open("source/names.pdf") as pdf: # 获取第一页 first_page = pdf.pages[0] # 解析文本 text = first_page.extract_text() print(text) # 解析表格 tables = first_page.extract_tables() for table in tables: print(table) # df = pd.DataFrame(table[1:], columns=table[0]) for row in table: for cell in row: print(cell, end="\t|") print()
"""
表格1:
姓名 年龄 性别
李雷 20 男
韩梅梅 23 女
赵小三 25 女
Table2:
Name Age Gender
Tom 30 Male
Jack 33 Male
Jone 31 Female
[['姓名', '年龄', '性别'], ['李雷', '20', '男'], ['韩梅梅', '23', '女'], ['赵小三', '25', '女']]
姓名 |年龄 |性别 |
李雷 |20 |男 |
韩梅梅 |23 |女 |
赵小三 |25 |女 |
[['30'], ['33']]
30 |
33 |
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
文本解析的很全,只有表格1解析完全了,表格2只是解析了有框的部分
3、camelot
github: https://github.com/socialcopsdev/camelot
安装:
pip install camelot-py[cv]
- 1
示例
import camelot
tables = camelot.read_pdf("source/names.pdf")
tables.export("source/names.csv")
- 1
- 2
- 3
- 4
生成2个文件:
source/names-page-1-table-1.csv
"姓名","年龄","性别"
"李雷","20 男",""
"韩梅梅","23 女",""
"赵小三","25 女",""
- 1
- 2
- 3
- 4
- 5
source/names-page-1-table-2.csv
"Name","Age","Gender"
"Tom","","30 Male"
"Jack","","33 Male"
"Jone","","31 Female"
- 1
- 2
- 3
- 4
- 5
发现表格2的内容被解析出来了,不过两个表格的内容都错位了
经过测试后,发现这3个库对表格识别都不是太好
总结
| 库名 | 说明 |
|---|---|
| tabula | 能提取完整表格,提取结果不规范 |
| pdfplumber | 能提取完整表格,提取结果较为规范 |
| camelot | 能提取完整表格和不完整表格,提取结果不规范 |
文章来源: pengshiyu.blog.csdn.net,作者:彭世瑜,版权归原作者所有,如需转载,请联系作者。
原文链接:pengshiyu.blog.csdn.net/article/details/85057226

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)