Python爬虫:滤网架构处理爬虫数据

【摘要】 业务场景: 1、爬虫数据直接入库会出现id自增过大的问题。要么就入库之前做一次查询,确保数据不存在再插入,这样一来就速度就减慢了。而且,爬虫程序运行速度往往较快,查询操作过多对数据库造成压力也不小。
2、一个表的数据分别来自不同地方,需要多个程序对其进行数据补全操作,这样一来,就会出现数据缺失现象。如果直接入业务库会出现数据不全,虽然不是bug,但是影响体验
为了...
业务场景:
1、爬虫数据直接入库会出现id自增过大的问题。要么就入库之前做一次查询,确保数据不存在再插入,这样一来就速度就减慢了。而且,爬虫程序运行速度往往较快,查询操作过多对数据库造成压力也不小。
2、一个表的数据分别来自不同地方,需要多个程序对其进行数据补全操作,这样一来,就会出现数据缺失现象。如果直接入业务库会出现数据不全,虽然不是bug,但是影响体验
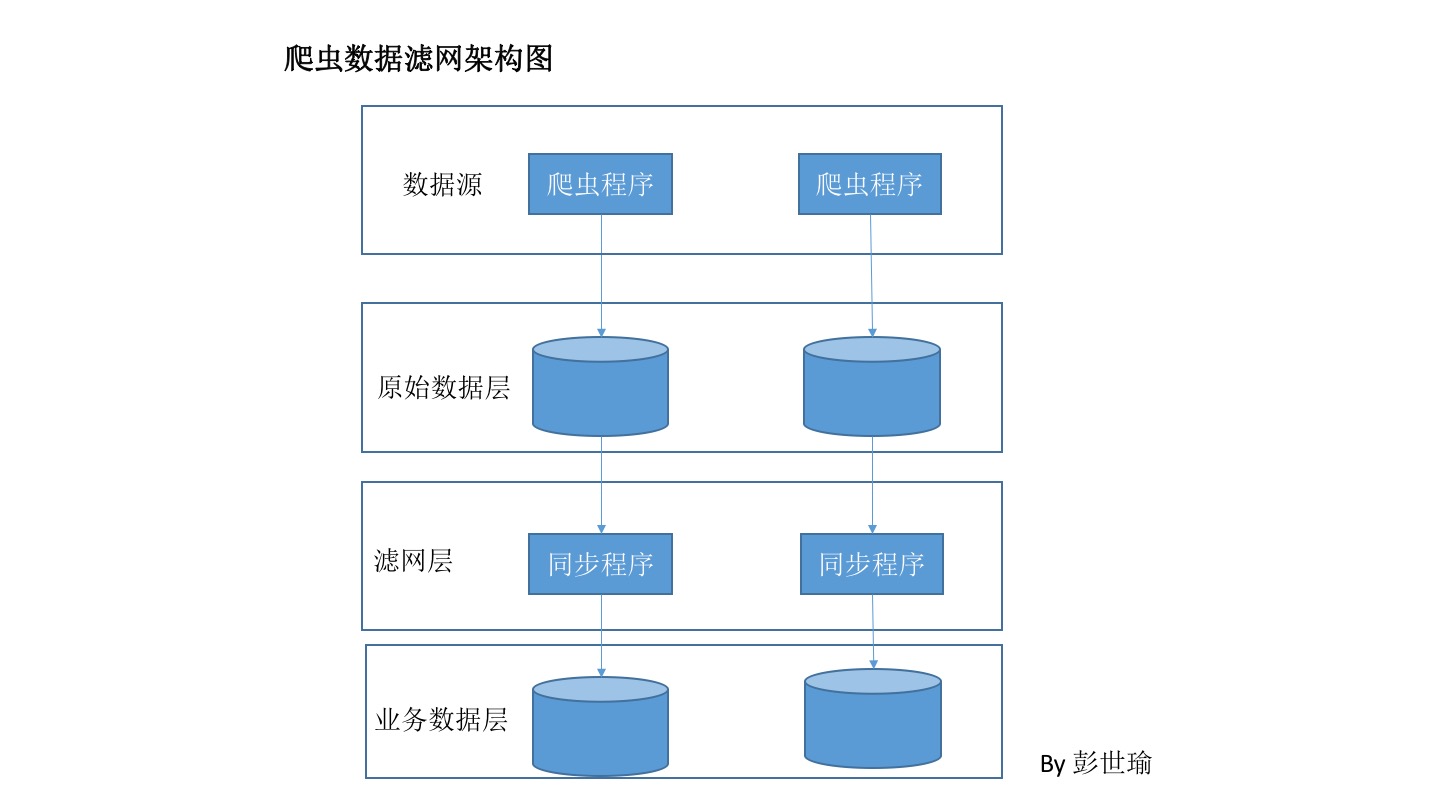
为了解决以上两个问题,采用了爬虫数据 和业务数据 分层的做法
原始数据层接收来自爬虫的数据滤网层负责对数据进行过滤,对符合条件的数据进行入库操作,按需入库,同时也能减少对业务数据库的操作业务数据层保存过滤之后的最终数据
数据经过一系列处理后,业务层拿到的数据就是优质数据了。而且利于数据维护
比如,业务层的数据库莫名出问题了,那么直接从原始数据库导过去就行了,就不需要重新抓取数据。
不过这样做的缺点是工作复杂度升高了,时间紧任务重就不推荐此方法了
文章来源: pengshiyu.blog.csdn.net,作者:彭世瑜,版权归原作者所有,如需转载,请联系作者。
原文链接:pengshiyu.blog.csdn.net/article/details/89351969

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)