Elasticsearch自定义分析器analyzer分词实践

【摘要】 基础知识回顾
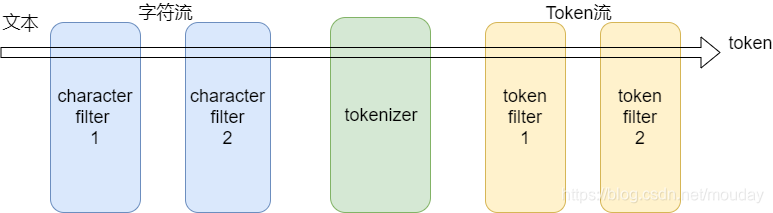
分析器的组成结构:
分析器(analyzer)
- Character filters (字符过滤器)0个或多个
- Tokenizer (分词器)有且只有一个
- Token filters (token过滤器)0个或多个
1234
内置分析器
1、whitespace 空白符分词
POST _analyze
{
"analyze...
基础知识回顾
分析器的组成结构:
分析器(analyzer)
- Character filters (字符过滤器)0个或多个
- Tokenizer (分词器)有且只有一个
- Token filters (token过滤器)0个或多个
- 1
- 2
- 3
- 4
内置分析器
1、whitespace 空白符分词
POST _analyze
{
"analyzer": "whitespace", "text": "你好 世界"
}
{
"tokens": [ { "token": "你好", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "世界", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 }
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2、pattern正则表达式分词,默认表达式是\w+(非单词字符)
配置参数
pattern : 一个Java正则表达式,默认 \W+
flags : Java正则表达式flags。比如:CASE_INSENSITIVE 、COMMENTS
lowercase : 是否将terms全部转成小写。默认true
stopwords : 一个预定义的停止词列表,或者包含停止词的一个列表。默认是 _none_
stopwords_path : 停止词文件路径
- 1
- 2
- 3
- 4
- 5
// 拆分中文不正常
POST _analyze
{
"analyzer": "pattern", "text": "你好世界"
}
{
"tokens": []
}
// 拆分英文正常
POST _analyze
{
"analyzer": "pattern", "text": "hello world"
}
{
"tokens": [ { "token": "hello", "start_offset": 0, "end_offset": 5, "type": "word", "position": 0 }, { "token": "world", "start_offset": 6, "end_offset": 11, "type": "word", "position": 1 }
]
}
// 在索引上自定义分析器-竖线分隔
PUT my-blog
{
"settings": { "analysis": { "analyzer": { "vertical_line": { "type": "pattern", "pattern": "\\|" } } }
},
"mappings": { "doc": { "properties": { "content": { "type": "text", "analyzer": "vertical_line" } } }
}
}
// 测试索引分析器
POST /blog-v4/_analyze
{
"analyzer": "vertical_line",
"text": "你好|世界"
}
POST /blog-v4/_analyze
{
"field": "content",
"text": "你好|世界"
}
// 两者结果都是
{
"tokens": [ { "token": "你好", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "世界", "start_offset": 3, "end_offset": 5, "type": "word", "position": 1 }
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
文章来源: pengshiyu.blog.csdn.net,作者:彭世瑜,版权归原作者所有,如需转载,请联系作者。
原文链接:pengshiyu.blog.csdn.net/article/details/108854769

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)