在 Hadoop 2.X 中设置多节点集群

Hadoop 2.x 中的多节点集群
从我们之前的Hadoop 教程系列博客中 ,我们学习了如何设置Hadoop 单节点集群。现在,我将展示如何设置Hadoop 多节点集群。Hadoop 中的多节点集群在分布式 Hadoop 环境中包含两个或多个 DataNode。这实际上在组织中用于存储和分析其 PB 和 Exabytes 的数据。
在这里,我们正在使用两台机器 - master和slave。在两台机器上,都会运行一个 Datanode。
让我们从在 Hadoop 中设置多节点集群开始。
先决条件
- Cent OS 6.5
- Hadoop-2.7.3
- JAVA 8
- SSH
在 Hadoop 中设置多节点集群
我们有两台带有 IP 的机器(主机和从机):
主IP:192.168.56.102
从IP:192.168.56.103
STEP 1:检查所有机器的IP地址。
命令: ip addr show(你也可以使用 ifconfig 命令)
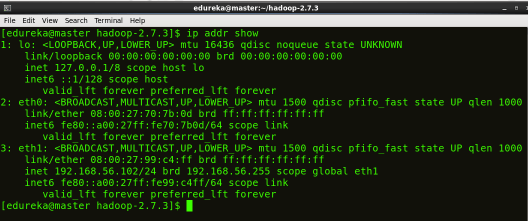

步骤 2:禁用防火墙限制。
命令: service iptables stop
命令: sudo chkconfig iptables off

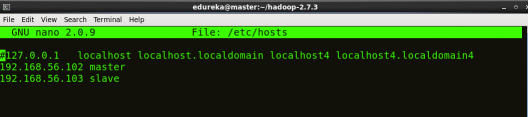
STEP 3:打开hosts文件,添加主节点和数据节点各自的IP地址。
命令: sudo nano /etc/hosts
相同的属性将显示在主从主机文件中。

第四步:重启sshd服务。
命令: service sshd restart

STEP 5:在主节点创建SSH Key。(当它要求您输入文件名以保存密钥时按回车按钮)。
命令: ssh-keygen -t rsa -P “”
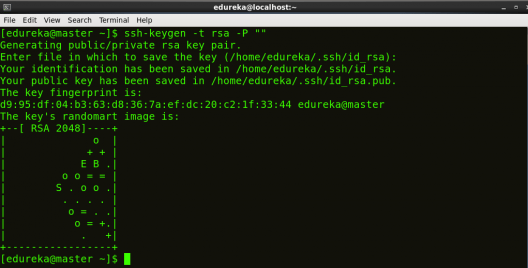
STEP 6:将生成的ssh key复制到master节点的授权key中。
命令: cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

STEP 7: 将master节点的ssh key复制到slave的授权key中。
命令: ssh-copy-id -i $HOME/.ssh/id_rsa.pub edureka@slave

第 8 步:单击此处下载 Java 8 包。将此文件保存在您的主目录中。
步骤 9:在所有节点上提取 Java Tar 文件。
命令: tar -xvf jdk-8u101-linux-i586.tar.gz

步骤 10:在所有节点上下载 Hadoop 2.7.3 包。
命令: wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz

步骤 11:在所有节点上提取 Hadoop tar 文件。
命令: tar -xvf hadoop-2.7.3.tar.gz

第 12步:在所有节点上的 bash 文件 (.bashrc) 中添加 Hadoop 和 Java 路径。
打开。 .bashrc文件。现在,添加 Hadoop 和 Java 路径,如下所示:
命令: sudo gedit .bashrc
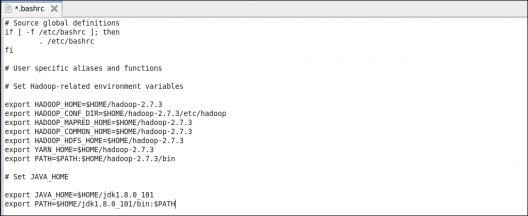
然后,保存 bash 文件并关闭它。
要将所有这些更改应用于当前终端,请执行 source 命令。
命令:源.bashrc

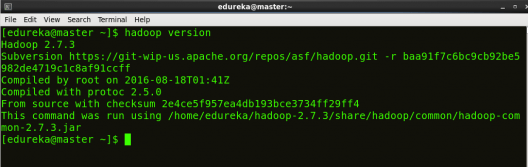
要确保 Java 和 Hadoop 已正确安装在您的系统上并可通过终端访问,请执行 java -version 和 hadoop version 命令。
命令: java -version

命令: hadoop 版本
现在编辑hadoop-2.7.3/etc/hadoop目录中的配置文件。
STEP 13:创建masters文件并在master和slave机器上编辑如下:
命令:sudo gedit masters

STEP 14:在主机中编辑 slaves 文件如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/slaves

STEP 15:在slave机器上编辑slaves文件如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/slaves

步骤 16:在主从机器上编辑 core-site.xml 如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/core-site.xml

STEP 7:在 master 上编辑 hdfs-site.xml 如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
STEP 18:在从机上编辑 hdfs-site.xml 如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
第 19步:从配置文件夹中的模板中复制 mapred-site 并在主从机器上编辑 mapred-site.xml,如下所示:
命令: cp mapred-site.xml.template mapred-site.xml
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/mapred-site.xml


STEP 20:在master和slave机器上编辑yarn-site.xml如下:
命令: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/yarn-site.xml

第 21 步:格式化 namenode(仅在主机上)。
命令: hadoop 目的 -format

步骤 22:启动所有守护进程(仅在主机上)。
命令: ./sbin/start-all.sh

步骤 23:检查在主从机器上运行的所有守护进程。
命令: jps


最后,打开浏览器,在你的主机上访问master : 50070/dfshealth.html,这将给你 NameNode 界面。向下滚动并查看活动节点的数量,如果是2,则您已成功设置多节点 Hadoop 集群。如果不是 2,您可能错过了我上面提到的任何步骤。不过不用担心,您可以返回并再次验证所有配置以查找问题并进行更正。
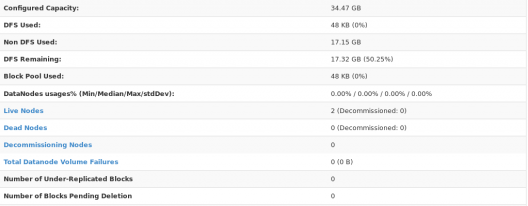
在这里,我们只有 2 个 DataNode。如果需要,您可以根据需要添加更多 DataNode,请参阅我们关于在 Hadoop 集群中调试和停用节点的博客。

- 点赞
- 收藏
- 关注作者
评论(0)