实战篇:LogMiner 分析数据泵导入参数 TABLE_EXISTS_ACTION 的秘密

前言
前几天,技术交流群里看到大家讨论 Oracle 数据泵导入时使用 table_exists_action 参数,存在一些疑惑。于是,我打算通过 LogMiner 来分析一下在线重做日志,看看到底是怎么玩的。
- 关于 LogMiner 的官方文档:Using LogMiner to Analyze Redo Log Files
- 关于 TABLE_EXISTS_ACTION 的官方文档:TABLE_EXISTS_ACTION
建议先阅读简单了解一下,下面👇🏻就开始~ ヾ(◍°∇°◍)ノ゙
环境准备
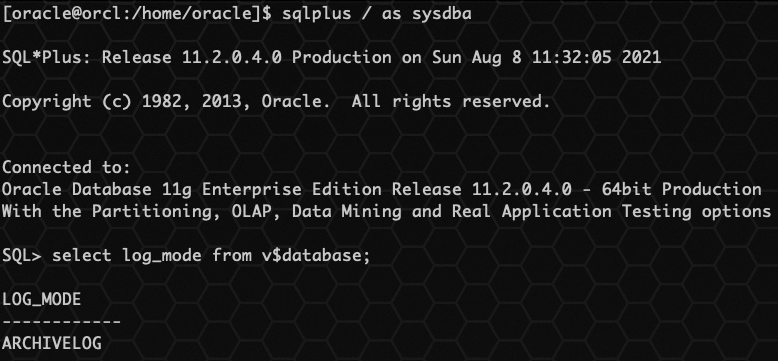
已有 Oracle 11GR2 数据库环境,已开启归档模式。
1、安装 LogMiner
Oracle 自带的 sql 脚本与 LogMiner 相关的有以下三个:
 在默认情况下,Oracle已经安装了LogMiner工具,如果没有安装,可以依次执行以下 sql 脚本,创建 LogMiner 相关的对象:
在默认情况下,Oracle已经安装了LogMiner工具,如果没有安装,可以依次执行以下 sql 脚本,创建 LogMiner 相关的对象:
sqlplus / as sysdba @?/rdbms/admin/dbmslm.sql
sqlplus / as sysdba @?/rdbms/admin/dbmslmd.sql
- 1
- 2
脚本需要用 SYS 用户执行,可重复执行。
2、创建数据字典文件
DBMS_LOGMNR_D.BUILD 过程需要访问可以放置字典文件的目录。 因为 PL/SQL 过程通常不访问用户目录,所以必须指定一个目录供 DBMS_LOGMNR_D.BUILD 过程使用,否则该过程将失败。
mkdir /oradata/orcl/logmnr
sqlplus / as sysdba
CREATE DIRECTORY utlfile AS '/oradata/orcl/logmnr';
alter system set utl_file_dir='/oradata/orcl/logmnr' scope=spfile;
shutdown immediate;
startup;
- 1
- 2
- 3
- 4
- 5
- 6
要指定目录,需要在初始化参数文件中设置初始化参数 UTL_FILE_DIR,需要重启数据库生效参数。

执行 PL/SQL 过程 DBMS_LOGMNR_D.BUILD。 指定字典的文件名和文件的目录路径名。 此过程创建字典文件。 例如,输入以下内容在 /oradata/orcl/logmnr 中创建文件 dictionary.ora:
EXECUTE DBMS_LOGMNR_D.BUILD('dictionary.ora','/oradata/orcl/logmnr',DBMS_LOGMNR_D.STORE_IN_FLAT_FILE);
- 1

由于本次仅作实验所用,不单独创建用户和表空间。
3、添加在线重做日志
通过 LogMiner.ADD_LOGFILE 添加所有 REDO LOG :
-- 查询所有在线重做日志
select member from v$logfile;
-- 添加所有在线重做日志
BEGIN DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '/oradata/orcl/redo03.log',OPTIONS => DBMS_LOGMNR.NEW); DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '/oradata/orcl/redo01.log',OPTIONS => DBMS_LOGMNR.ADDFILE); DBMS_LOGMNR.ADD_LOGFILE(LOGFILENAME => '/oradata/orcl/redo02.log',OPTIONS => DBMS_LOGMNR.ADDFILE);
end;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
添加第一个文件时,OPTIONS 需要指定 DBMS_LOGMNR.NEW,后面添加的文件指定 DBMS_LOGMNR.ADDFILE。
4、启动 LogMiner
begin DBMS_LOGMNR.START_LOGMNR(DictFileName => '/oradata/orcl/logmnr/dictionary.ora');
end;
- 1
- 2
- 3
这里需要注意的是,执行启动 LogMiner 的 SESSION 才可以进行查询,否则不能查询。
5、准备数据泵导入数据
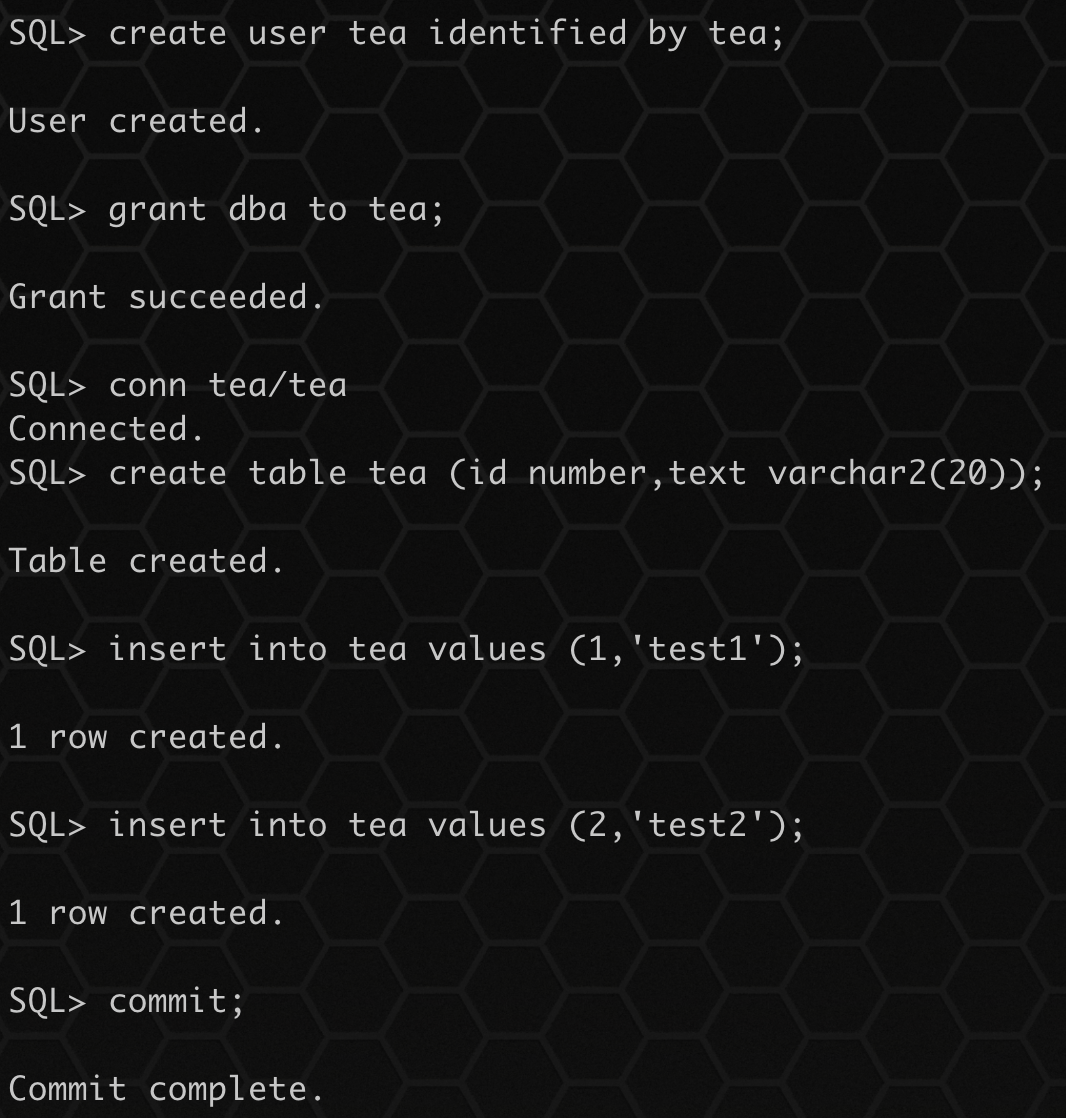
创建用户和测试表:
create user tea identified by tea;
grant dba to tea;
conn tea/tea
create table tea (id number,text varchar2(20));
insert into tea values (1,'test1');
insert into tea values (2,'test2');
commit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
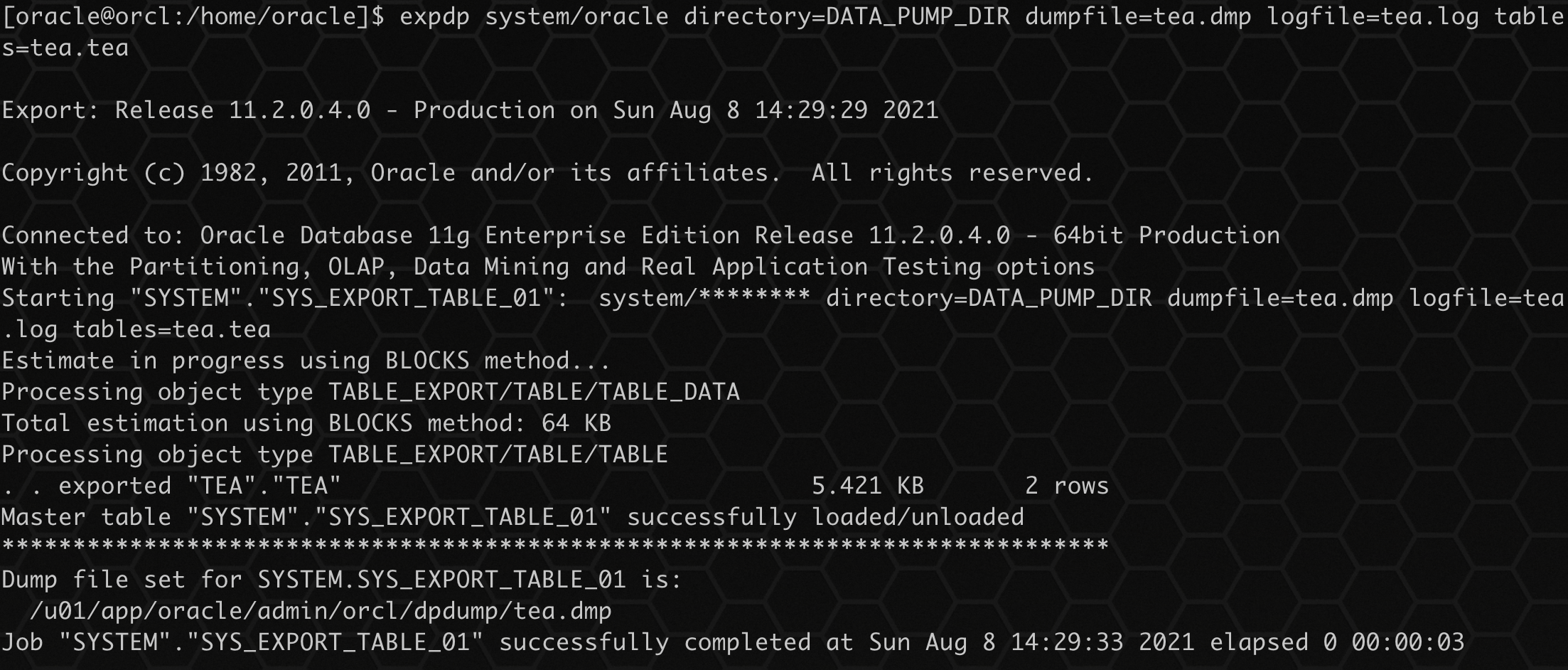
数据泵导出表:
expdp system/oracle directory=DATA_PUMP_DIR dumpfile=tea.dmp logfile=tea.log tables=tea.tea
- 1
6、查询 LogMiner 记录
alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:mi:ss';
SELECT timestamp, sql_redo, sql_undo, seg_owner FROM v$logmnr_contents WHERE seg_name='TEA' AND seg_owner='TEA';
- 1
- 2

通过查询可以看到上面建表的 DDL 语句已经被查询到。
开始实验
数据泵导入参数 TABLE_EXISTS_ACTION,通常用于数据库中表已存在的情况下,导入数据时处理的参数。
TABLE_EXISTS_ACTION=[SKIP | APPEND | TRUNCATE | REPLACE]
可用选项有 4 种,接下来我们依次使用参数来进行测试。
- SKIP:跳过当前表进行下一个。 如果 CONTENT 参数设置为 DATA_ONLY,这不是有效选项。
- APPEND:从源加载数据并保持现有数据不变。
- TRUNCATE:删除现有表数据,然后从源加载数据。
- REPLACE:删除现有表,然后从源创建并加载数据。 如果 CONTENT 参数设置为 DATA_ONLY,这不是有效选项。
默认值:SKIP(注意,如果指定了 CONTENT=DATA_ONLY,则默认值是 APPEND,而不是 SKIP)
1、SKIP
SKIP 参数是指导入时跳过已存在的表,添加参数 TABLE_EXISTS_ACTION=SKIP 测试。
执行导入:
impdp system/oracle directory=DATA_PUMP_DIR dumpfile=tea.dmp logfile=tea.log tables=tea.tea table_exists_action=skip
- 1
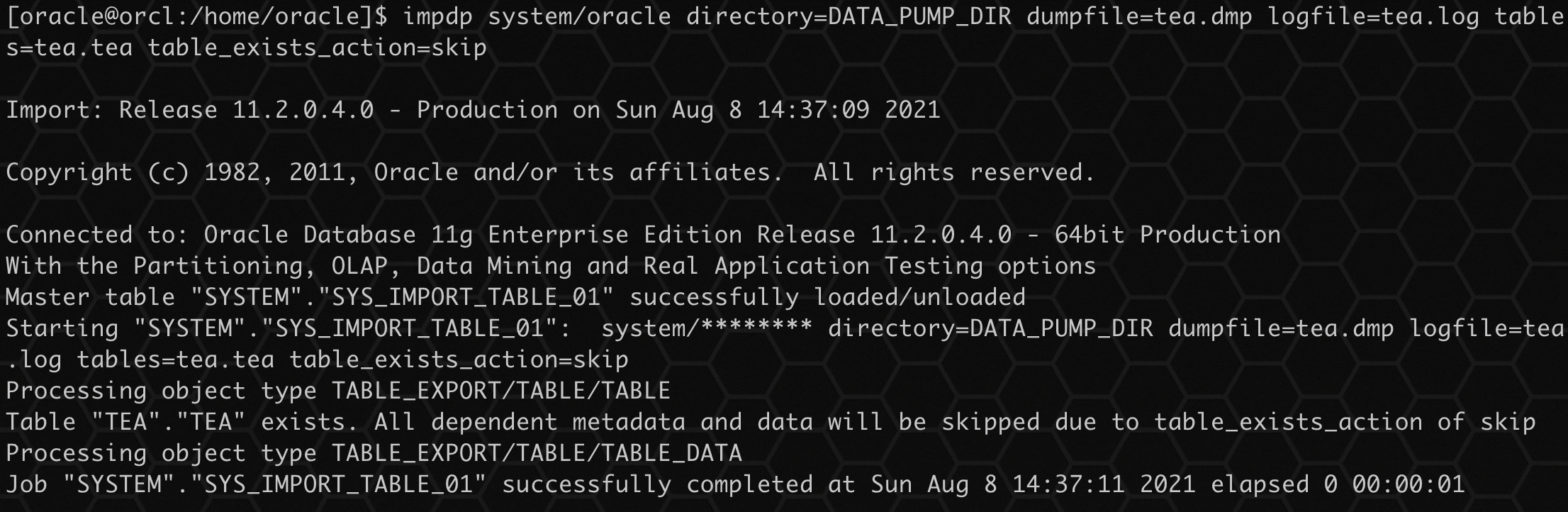
这个参数比较简单明了,就是直接跳过了存在的表,不进行导入,表数据不变。
2、APPEND
APPEND 参数是指导入时对已存在表进行增量导入,添加参数TABLE_EXISTS_ACTION=APPEND 测试。
由于目前表数据一样,无法看出效果,先修改表中数据:
delete from tea.tea where id=2;
insert into tea.tea values (3,'test3');
commit;
- 1
- 2
- 3
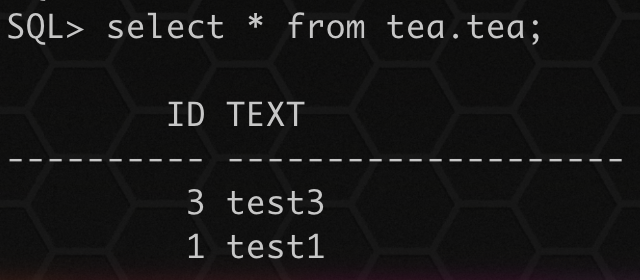
执行导入:
impdp system/oracle directory=DATA_PUMP_DIR dumpfile=tea.dmp logfile=tea.log tables=tea.tea table_exists_action=append
- 1
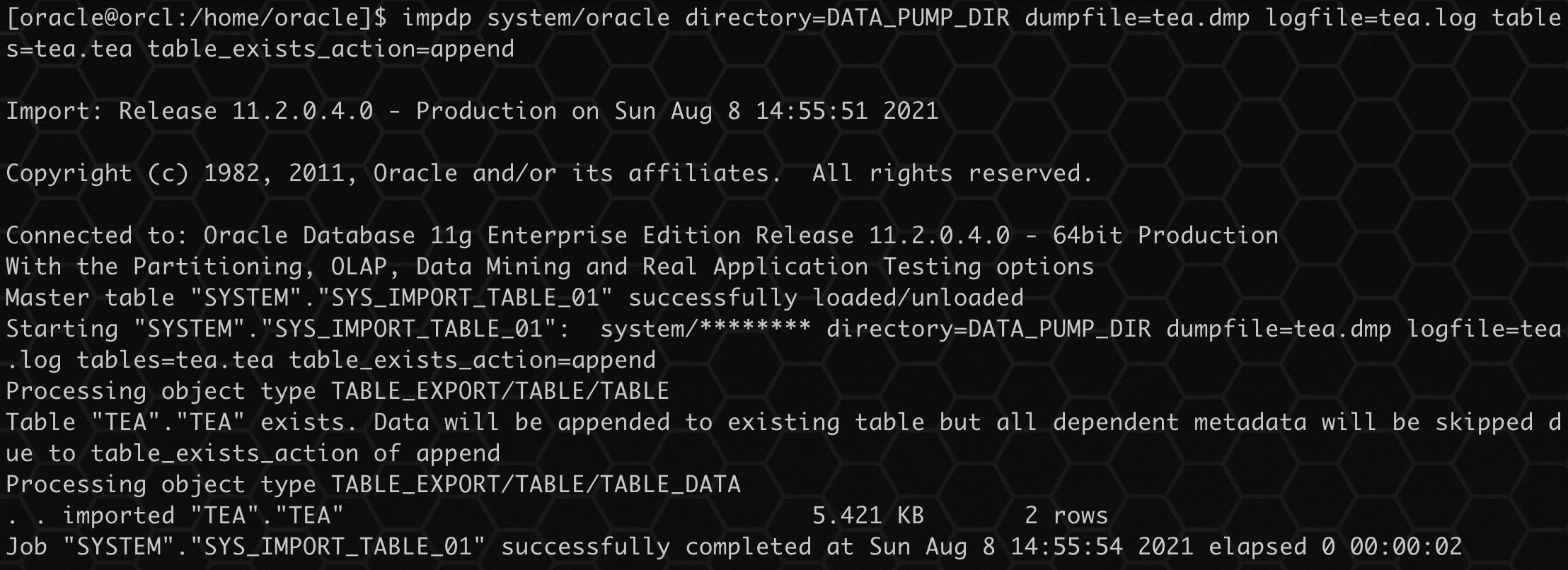
由于建表时没有主键唯一限制,因此允许存在重复数据,导入后数据如下:
select * from tea.tea;
- 1
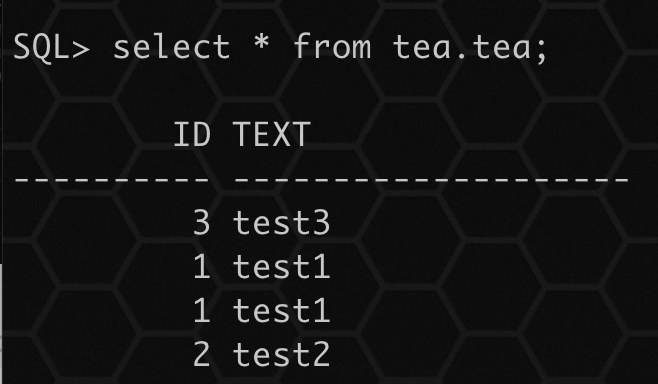
当使用 APPEND 参数,如果发现存在表,将导入数据进行增量导入,如果有唯一限制时,有重复数据,将会导入失败。
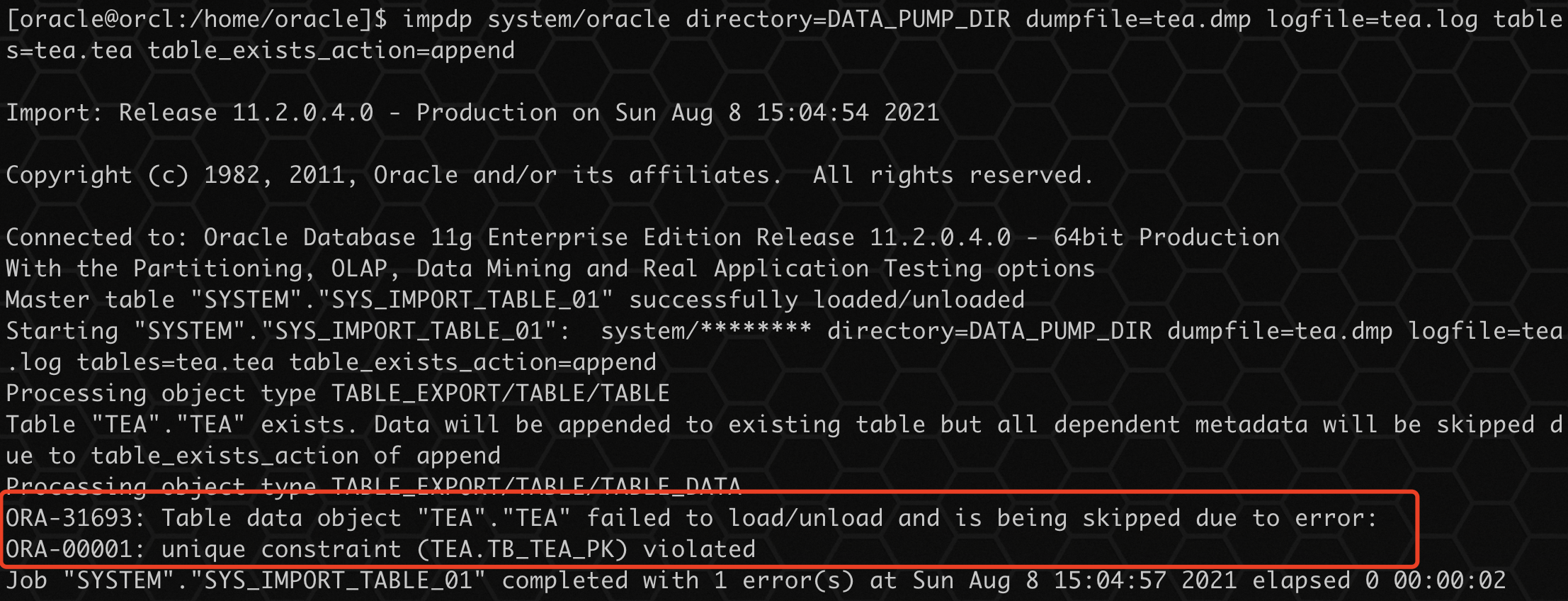
也可以通过在导入命令行上指定 DATA_OPTIONS=SKIP_CONSTRAINT_ERRORS 来覆盖此行为。如果有必须加载的数据,但可能会导致违反约束,可以考虑禁用约束,加载数据,然后在重新启用约束之前删除有问题的行。
3、TRUNCATE
TRUNCATE 参数会删除原表中所有的数据,并且导入新数据,添加参数TABLE_EXISTS_ACTION=TRUNCATE 测试。
执行导入:
impdp system/oracle directory=DATA_PUMP_DIR dumpfile=tea.dmp logfile=tea.log tables=tea.tea table_exists_action=truncate
- 1
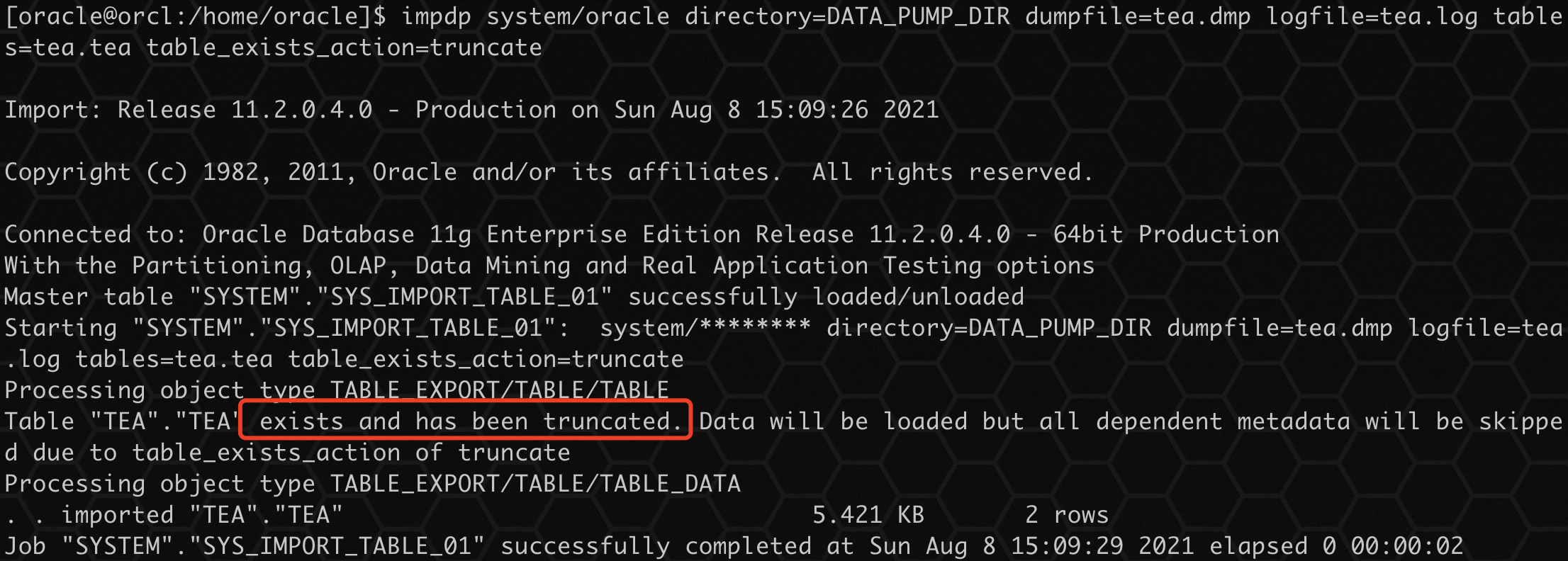
查询导入后数据:
select * from tea.tea;
- 1
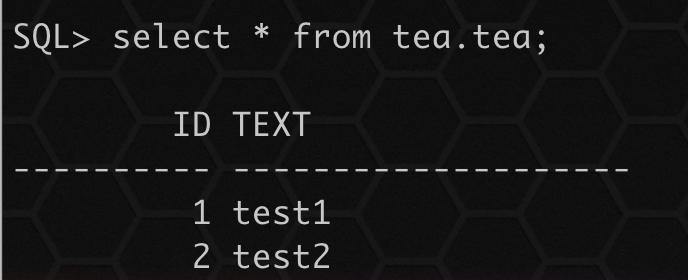
可以看到之前的数据已经不存在,数据重新导入。
SELECT timestamp, sql_redo, sql_undo, seg_owner FROM v$logmnr_contents WHERE seg_name='TEA' AND seg_owner='TEA';
- 1

通过比对导入时间和 LogMiner 表中记录时间,可以看到 TEA 表执行了 TRUNCATE 操作。
4、REPLACE
REPLACE 参数会删除已存在的表然后重新创建,并且导入新数据,添加参数TABLE_EXISTS_ACTION=REPLACE 测试。
导入前插入几条数据:
insert into tea values(3,'test3');
insert into tea values(4,'test4');
commit;
- 1
- 2
- 3
执行导入:
impdp system/oracle directory=DATA_PUMP_DIR dumpfile=tea.dmp logfile=tea.log tables=tea.tea table_exists_action=replace
- 1
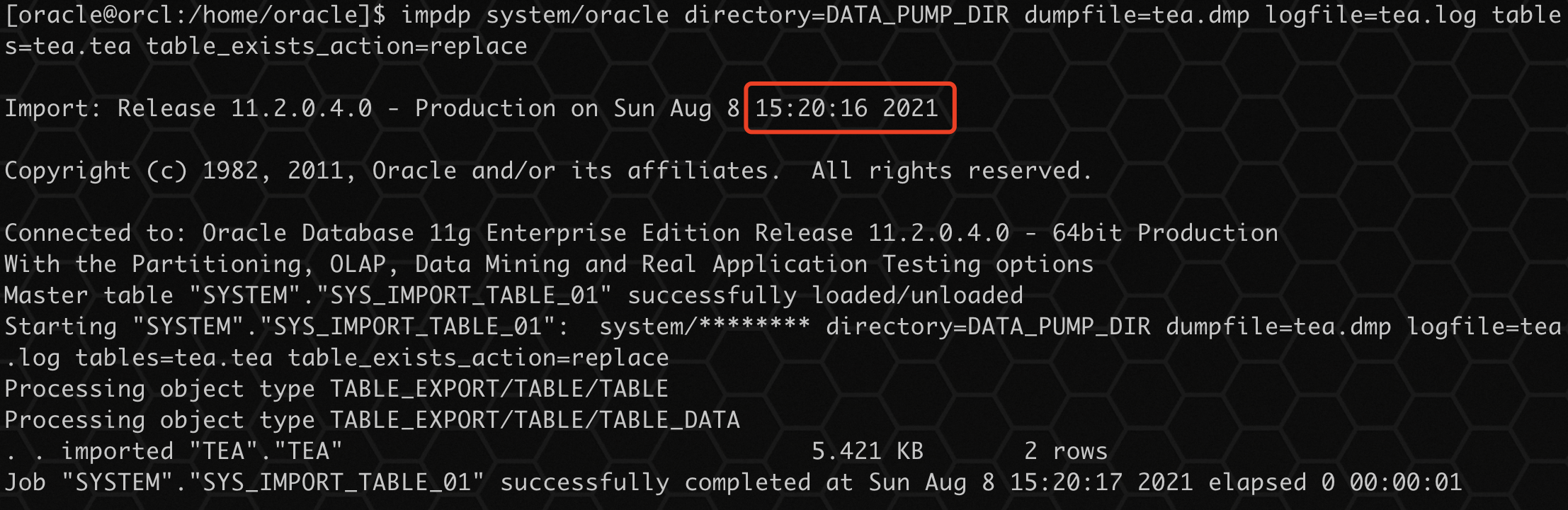
通过导入过程没有看到任何关于表已存在的提示,导入正常,查询数据:
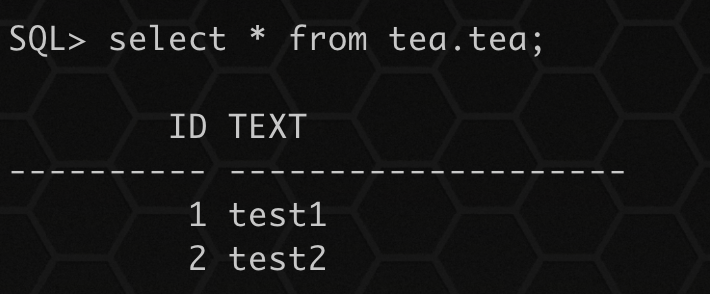
数据只存在导入的数据,导入前新增的数据已经消失。
SELECT timestamp, sql_redo, sql_undo, seg_owner FROM v$logmnr_contents WHERE seg_name='TEA' AND seg_owner='TEA';
- 1

通过比对导入时间和 LogMiner 表中记录时间,可以看到 TEA 表先执行 DROP PURGE 操作,然后执行 CREATE TABLE 重新创建表。
总结
使用 SKIP、APPEND 或 TRUNCATE 时,不会修改源中现有的表相关对象,例如索引、授权、触发器和约束。对于 REPLACE,如果依赖对象未被显式或隐式排除(使用 EXCLUDE)并且它们存在于源转储文件或系统中,则会从源中删除并重新创建它们。
本次分享到此结束啦~
如果觉得文章对你有帮助,点赞、收藏、关注、评论,一键四连支持,你的支持就是我创作最大的动力。
文章来源: blog.csdn.net,作者:Lucifer三思而后行,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/m0_50546016/article/details/119511289

- 点赞
- 收藏
- 关注作者
评论(0)