Linux 操作系统原理 — 内存 — 内存分配算法

目录
前文列表
《Linux 操作系统原理 — 内存 — 物理存储器与虚拟存储器》
《Linux 操作系统原理 — 内存 — 基于 MMU 硬件单元的虚/实地址映射技术》
《Linux 操作系统原理 — 内存 — 基于局部性原理实现的内/外存交换技术》
内存碎片
Linux 操作系统的页式虚拟存储器文内存管理带来了很多好处。但如果就这样直接把内存分页使用的话还是会存在一些问题,例如:内存空间碎片化严重。
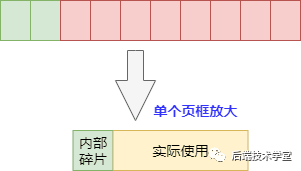
物理内存页分配会出现外部碎片和内部碎片问题,所谓的内部和外部是针对 “页内外” 而言的,一个页内的内存碎片是内部碎片,多个页间的碎片是外部碎片。
-
内部碎片:当实际只需要很小内存的时候,也会分配一张至少 4K 的页面,而内核中有很多需要以字节为单位分配内存的场景,这样本来只想要几个字节而已却不得不分配一页内存,除去用掉的字节剩下的就形成了内部碎片。

-
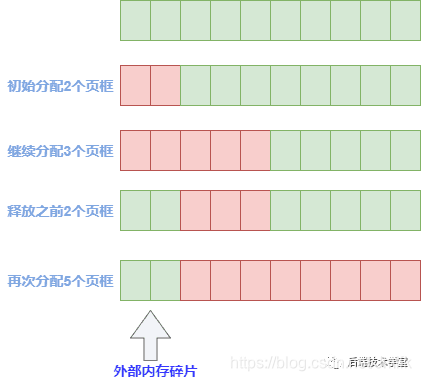
外部碎片:当需要分配大块内存的时候,需要用好几页组合起来才够,而系统分配物理内存页的时候会尽量分配连续的内存页面,频繁的分配与回收物理页导致大量的小块内存夹杂在已分配页面中间,形成外部碎片。
避免内存碎片的办法主要由客观手段和主观手段两种。
客观手段,即良好的编程习惯:
- 少用动态内存分配的函数,尽量使用栈空间。
- 分配内存和释放的内存尽量实现在同一个函数中。
- 尽量一次性申请较大的内存,而不要反复申请小内存。
- 尽可能申请大块的 2 的指数幂大小的内存空间。
- 自己进行内存管理工作,设计内存池程序模块。
主观手段,即操作系统自身的内存分配算法:
- 伙伴系统算法:避免外部碎片。
- Slab 算法:避免内部碎片。
其中伙伴算法和 Slab 高速缓存都在物理内存映射区分配物理内存,而 vmalloc 机制则在高端内存映射区分配物理内存。
伙伴(Buddy)分配算法
伙伴系统算法(Buddy system),顾名思义,就是把相同大小的页通过链表串起来,多张页就像手拉手的好伙伴(算法名称的由来)。伙伴算法负责大块连续物理内存的分配和释放,以页为基本单位。
伙伴分配算法的原理就是:将所有的空闲页框分组为 11 个块链表,每个块链表分别包含大小为 1,2,4,8,16,32,64,128,256,512 和 1024 个连续页的页块。最大可以申请 1024 个连续页,对应 4MB 大小的连续内存。因为任何正整数都可以由 2^n 的和组成,所以总能找到合适大小的内存块分配出去,减少了外部碎片产生 。
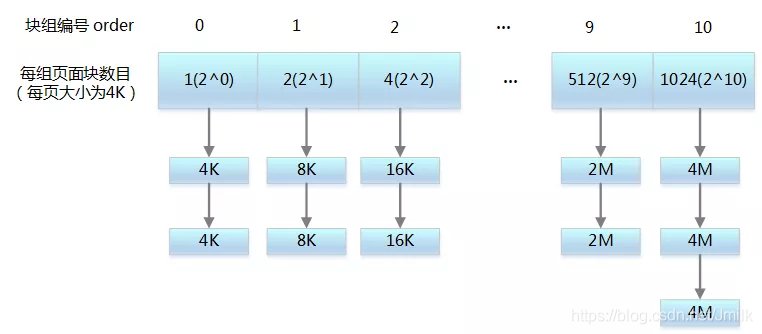
如此的,假设需要申请 4 个页,但是长度为 4 个连续页块链表没有空闲的页块,伙伴系统会从连续 8 个框块的链表获取一个,并将其拆分为两个连续 4 个页块,取其中一个,另外一个放入连续 4 个页块的空闲链表中。释放的时候会检查,释放的这几个页前后的页框是否空闲,能否组成下一级长度的块。
在 Linux 操作系统中可以通过命令查看:
$ cat /proc/buddyinfo
Node 0, zone DMA 1 0 0 0 2 1 1 0 1 1 3
Node 0, zone DMA32 189 209 119 80 38 17 11 1 1 2 627
Node 0, zone Normal 1298 1768 1859 661 743 461 275 133 68 61 2752
- 1
- 2
- 3
- 4
Slab 算法
一般来说,内核对象的生命周期是:分配内存 -> 初始化 -> 释放内存。而内核中会有大量的小对象,比如:文件描述结构对象、任务描述结构对象,如果按照伙伴系统按页分配和释放内存,就会对小对象频繁的执行上述过程,会非常消耗性能。另外,伙伴系统分配出去的内存还是以页为单位,而对于内核的很多场景都是分配小片内存,远用不到一页内存大小的空间。
为了解决伙伴算法的不足,Jeff Bonwick 最初在 SunOS 操作系统引入了 Slab 算法,并实现了 Slab 分配器。它的基本思想是:将内核中经常使用的对象放到高速缓存中,并且由系统保持为初始的可利用状态。比如进程描述符,内核中会频繁对此数据进行申请和释放。
Slab 分配器为每一种对象建立高速缓存,通过将内存按使用对象不同再划分成不同大小的空间,应用于内核对象的缓存,内核对该对象的分配和释放均是在这块高速缓存中操作。
可见,Slab 内存分配器是对伙伴分配算法的补充。Slab 缓存负责小块物理内存的分配,并且它也作为高速缓存,主要针对内核中经常分配并释放的对象。
Slab 的好处:
- Slab 内存管理基于内核小对象,不用每次都分配一页内存,充分利用内存空间,避免内部碎片。
- Slab 对内核中频繁创建和释放的小对象做缓存,重复利用一些相同的对象,减少内存分配次数。

kmem_cache 是一个cache_chain 的链表组成节点,代表的是一个内核中的相同类型对象的高速缓存,每个kmem_cache 通常是一段连续的内存块,包含了三种类型的 slabs 链表:
- slabs_full:完全分配的 slab 链表
- slabs_partial:部分分配的 slab 链表
- slabs_empty:没有被分配对象的 slab 链表
slab 是 Slab 分配器的最小单位,一个 slab 由一个或多个连续的物理页组成(通常只有一页)。单个 slab 可以在 slab 链表之间移动,例如:如果一个半满 slabs_partial 链表被分配了对象后变满了,就要从 slabs_partial 中删除,同时插入到全满 slabs_full 链表中去。内核 slab 对象的分配过程是这样的:
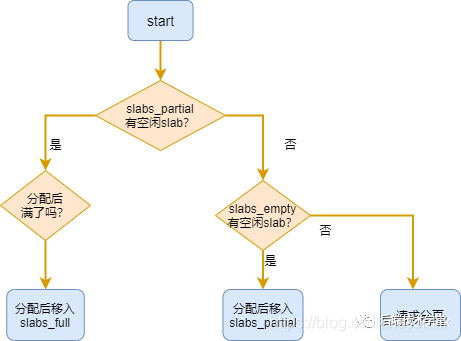
- 如果 slabs_partial 链表还有未分配的空间,分配对象,若分配之后变满,移动 slab 到 slabs_full 链表。
- 如果 slabs_partial 链表没有未分配的空间,进入下一步。
- 如果 slabs_empty 链表还有未分配的空间,分配对象,同时移动 slab 进入 slabs_partial 链表。
- 如果 slabs_empty 为空,请求伙伴系统分页,创建一个新的空闲 slab, 按步骤 3 分配对象。
在 Linux 上查看 Slab 内存的信息:
[root@c-dev ~]# cat /proc/slabinfo
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
isofs_inode_cache 50 50 640 25 4 : tunables 0 0 0 : slabdata 2 2 0
kvm_async_pf 0 0 136 30 1 : tunables 0 0 0 : slabdata 0 0 0
kvm_vcpu 0 0 14976 2 8 : tunables 0 0 0 : slabdata 0 0 0
xfs_dqtrx 0 0 528 31 4 : tunables 0 0 0 : slabdata 0 0 0
xfs_dquot 0 0 488 33 4 : tunables 0 0 0 : slabdata 0 0 0
xfs_ili 40296 40296 168 24 1 : tunables 0 0 0 : slabdata 1679 1679 0
xfs_inode 41591 41616 960 34 8 : tunables 0 0 0 : slabdata 1224 1224 0
xfs_efd_item 1053 1053 416 39 4 : tunables 0 0 0 : slabdata 27 27 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
显示内核中的 Slab 内存缓存信息:
$ slabtop
- 1
Slab 高速缓存分为两类:
-
通用高速缓存:slab 分配器中用 kmem_cache 来描述高速缓存的结构,它本身也需要 slab 分配器对其进行高速缓存。cache_cache 保存着对高速缓存描述符的高速缓存,是一种通用高速缓存,保存在 cache_chain 链表中的第一个元素。另外,slab 分配器所提供的小块连续内存的分配,也是通用高速缓存实现的。通用高速缓存所提供的对象具有几何分布的大小,范围为 32 到 131072 字节。内核中提供了 kmalloc() 和 kfree() 两个接口分别进行内存的申请和释放。slab 分配器所提供的小块连续内存的分配是通过通用高速缓存实现的。
-
专用高速缓存:内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为指定的对象分配 Slab 缓存。内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为具体的对象分配 slab 缓存。kmem_cache_create() 用于对一个指定的对象创建高速缓存。它从 cache_cache 普通高速缓存中为新的专有缓存分配一个高速缓存描述符,并把这个描述符插入到高速缓存描述符形成的 cache_chain 链表中。kmem_cache_alloc() 在其参数所指定的高速缓存中分配一个 slab。相反, kmem_cache_free() 在其参数所指定的高速缓存中释放一个 slab。
随着大规模多处理器系统和 NUMA 系统的广泛应用,Slab 也暴露出了一下问题:
- 复杂的队列管理。
- 管理数据和队列存储开销较大。
- 长时间运行 partial 队列可能会非常长。
- 对 NUMA 支持非常复杂。
为了解决问题,基于 Slab 推出了 Slub:改造 Page 结构来削减 Slab 管理结构的开销、每个 CPU 都有一个本地活动的 slab(kmem_cache_cpu),对于小型的嵌入式系统存在一个 Slab 模拟层 Slob,在这种系统中它更有优势。
虚拟内存的分配
虚拟内存的分配,包括用户态虚拟内存和内核态虚拟内存分配。需要注意的是:分配的虚拟内存还没有映射到物理内存,只有当访问申请的虚拟内存时,才会发生缺页异常,再通过上面介绍的伙伴系统和 slab 分配器申请物理内存。
内核态内存分配
先来回顾一下内核地址空间。
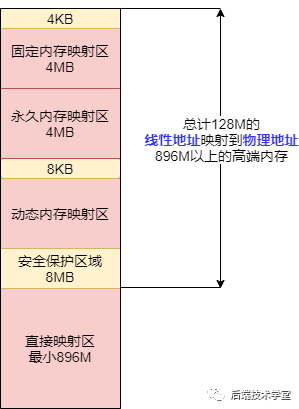
在内核态申请内存比在用户态申请内存要更为直接,它没有采用用户态那种延迟分配(通过缺页机制来反馈)内存技术。一旦有内核函数申请内存,那么就必须立刻满足该申请内存的请求,并且这个请求一定是正确合理的。相反,对于用户态申请内存的请求,内核总是尽量延后分配物理内存,用户进程总是先获得一个虚拟内存区的使用权,最终通过缺页异常获得一块真正的物理内存。
内核虚拟地址空间只有 1GB 大小,因此可以直接将 1GB 大小的物理内存映射到内核地址空间,但超出 1GB 大小的物理内存(高端内存)就不能映射到内核空间。为此,内核采取了下面的方法使得内核可以使用所有的物理内存:
-
高端内存不能全部映射到内核空间,也就是说这些物理内存没有对应的线性地址。不过,内核为每个物理页都分配了对应的页描述符,所有的页框描述符都保存在 mem_map 数组中,因此每个页描述符的线性地址都是固定存在的。内核此时可以使用 alloc_pages() 和 alloc_page() 来分配高端内存,因为这些函数返回页框描述符的线性地址。
-
内核地址空间的后 128MB 专门用于映射高端内存,否则,没有线性地址的高端内存不能被内核所访问。这些高端内存的内核映射显然是暂时映射的,否则也只能映射 128MB 的高端内存。当内核需要访问高端内存时就临时在这个区域进行地址映射,使用完毕之后再用来进行其他高端内存的映射。
由于要进行高端内存的内核映射,因此直接能够映射的物理内存大小只有 896MB,该值保存在 high_memory 中。内核地址空间的线性地址区间如下图所示:
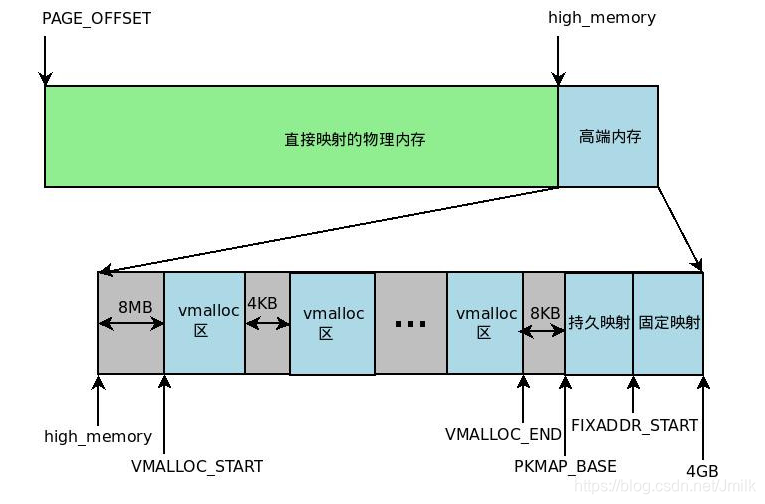
从图中可以看出,内核采用了三种机制将高端内存映射到内核空间:永久内核映射、固定映射和 vmalloc 机制。
内核 API:
- mempool_create:创建内存池对象
- mempool_alloc:分配函数获得该对象
- mempool_free:释放一个对象
- mempool_destroy:销毁内存池

vmalloc 函数

kmalloc 和 vmalloc 分别用于分配不同映射区的虚拟内存。
vmalloc 分配的虚拟地址区间,位于 vmalloc_start 与 vmalloc_end 之间的动态内存映射区。一般用分配大块内存,释放内存对应于 vfree,分配的虚拟内存地址连续,物理地址上不一定连续。函数原型在 <linux/vmalloc.h> 中声明。一般用在为活动的交换区分配数据结构,为某些 I/O 驱动程序分配缓冲区,或为内核模块分配空间。
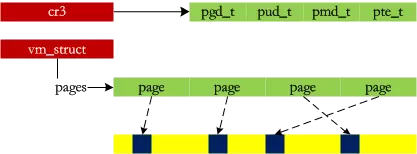
内核通过它来申请非连续的物理内存,若申请成功,该函数返回连续内存区的起始地址,否则,返回 NULL。vmalloc() 和 kmalloc() 申请的内存有所不同,kmalloc() 所申请内存的线性地址与物理地址都是连续的,而 vmalloc() 所申请的内存线性地址连续而物理地址则是离散的,两个地址之间通过内核页表进行映射。vmalloc() 使得内核通过连续的线性地址来访问非连续的物理页,这样可以最大限度的使用高端物理内存。
vmalloc() 的工作方式理解起来很简单:
- 寻找一个新的连续线性地址空间;
- 依次分配一组非连续的页框;
- 为线性地址空间和非连续页框建立映射关系,即修改内核页表;
vmalloc() 的内存分配原理与用户态的内存分配相似,都是通过连续的虚拟内存来访问离散的物理内存,并且虚拟地址和物理地址之间是通过页表进行连接的,通过这种方式可以有效的使用物理内存。但是应该注意的是,vmalloc() 申请物理内存时是立即分配的,因为内核认为这种内存分配请求是正当而且紧急的;相反,用户态有内存请求时,内核总是尽可能的延后,毕竟用户态跟内核态不在一个特权级。
可见,vmalloc 的主要目的就是用多个碎片来拼凑出一个大内存,相当于收集一些 “边角料”,组装成一个成品后再 “出售”。
kmalloc
kmalloc() 分配的虚拟地址范围在内核空间的直接内存映射区。按字节为单位虚拟内存,一般用于分配小块内存,释放内存对应于 kfree ,可以分配连续的物理内存。函数原型在 <linux/kmalloc.h> 中声明,一般情况下在驱动程序中都是调用 kmalloc() 来给数据结构分配内存。
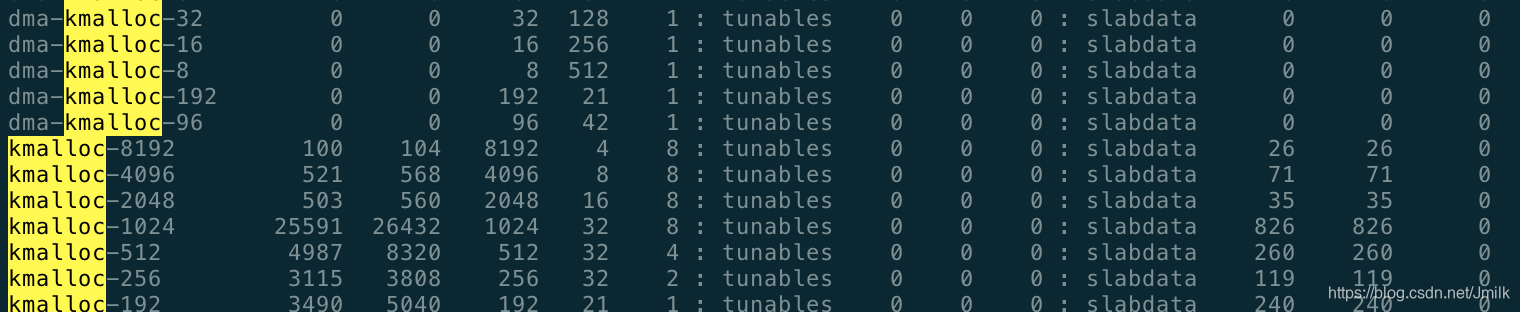
kmalloc 是基于 Slab 分配器的,同样可以用 cat /proc/slabinfo 命令,查看 kmalloc 相关 slab 对象信息,下面的 kmalloc-8、kmalloc-16 等等就是基于 Slab 分配的 kmalloc 高速缓存。
用户态内存分配
用户态内存分配函数:
- alloca 是向栈申请内存,因此无需释放。
- malloc 所分配的内存空间未被初始化,使用 malloc() 函数的程序开始时(内存空间还没有被重新分配)能正常运行,但经过一段时间后(内存空间已被重新分配)可能会出现问题。
- calloc 会将所分配的内存空间中的每一位都初始化为零。
- realloc 扩展现有内存空间大小。
- 如果当前连续内存块足够 realloc 的话,只是将 p 所指向的空间扩大,并返回 p 的指针地址。这个时候 q 和 p 指向的地址是一样的。
- 如果当前连续内存块不够长度,再找一个足够长的地方,分配一块新的内存,q,并将 p 指向的内容 copy 到 q,返回 q。并将 p 所指向的内存空间删除。
malloc 申请内存
malloc 用于申请用户空间的虚拟内存:
- 当申请小于 128KB 小内存的时,malloc 使用 sbrk 或 brk 分配内存;
- 当申请大于 128KB 的内存时,使用 mmap 函数申请内存。
存在的问题:由于 brk/sbrk/mmap 属于系统调用,如果每次申请内存都要产生系统调用开销,CPU 在用户态和内核态之间频繁切换,非常影响性能。而且,堆是从低地址往高地址增长,如果低地址的内存没有被释放,高地址的内存就不能被回收,容易产生内存碎片。
解决:因此,malloc 采用的是内存池的实现方式,先申请一大块内存,然后将内存分成不同大小的内存块,然后用户申请内存时,直接从内存池中选择一块相近的内存块分配出去。
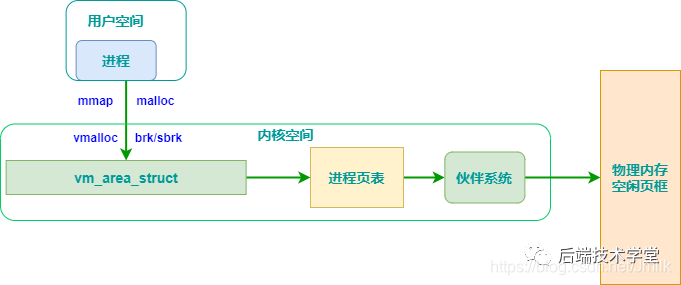
调用 malloc 函数时,它沿 free_chuck_list 连接表寻找一个大到足以满足用户请求所需要的内存块。

free_chuck_list 连接表的主要工作是维护一个空闲的堆空间缓冲区链表。如果空间缓冲区链表没有找到对应的节点,需要通过系统调用 sys_brk 延伸进程的栈空间。

用户进程内存分配示例
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main(void)
{ char *s; unsigned long int i; s = strdup("test_memory"); if (NULL == s) { fprintf(stderr, "Can't allocate mem with malloc.\n"); return EXIT_FAILURE; } i = 0; while (s) { printf("[%lu] %s (%p)\n", i, s, (void *)s); sleep(1); i++; } return EXIT_SUCCESS;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
编译运行:
$ gcc -Wall -Wextra -pedantic -Werror test4.c -o test4; ./test4
[0] test_memory (0xcba010)
[1] test_memory (0xcba010)
...
- 1
- 2
- 3
- 4
执行环节是 IA64,所以示例程序的虚拟内存高地址为 0xffffffffffffffff、低地址为 0x0,程序主动申请的堆(Heap)地址为 0xcba010。我们知道堆地址是靠近低地址的,所以从数值上看也符合。

查看程序进程:
$ ps -ef | grep test
root 18539 16745 0 13:18 pts/1 00:00:00 ./test4
- 1
- 2
查看进程内存信息:
$ cat /proc/18539/maps
00400000-00401000 r-xp 00000000 fd:01 1065575 /root/workspace/test/test4
00600000-00601000 r--p 00000000 fd:01 1065575 /root/workspace/test/test4
00601000-00602000 rw-p 00001000 fd:01 1065575 /root/workspace/test/test4
00cba000-00cdb000 rw-p 00000000 00:00 0 [heap]
7f28da826000-7f28da9e9000 r-xp 00000000 fd:01 1051055 /usr/lib64/libc-2.17.so
7f28da9e9000-7f28dabe9000 ---p 001c3000 fd:01 1051055 /usr/lib64/libc-2.17.so
7f28dabe9000-7f28dabed000 r--p 001c3000 fd:01 1051055 /usr/lib64/libc-2.17.so
7f28dabed000-7f28dabef000 rw-p 001c7000 fd:01 1051055 /usr/lib64/libc-2.17.so
7f28dabef000-7f28dabf4000 rw-p 00000000 00:00 0
7f28dabf4000-7f28dac16000 r-xp 00000000 fd:01 1053320 /usr/lib64/ld-2.17.so
7f28dae07000-7f28dae0a000 rw-p 00000000 00:00 0
7f28dae13000-7f28dae15000 rw-p 00000000 00:00 0
7f28dae15000-7f28dae16000 r--p 00021000 fd:01 1053320 /usr/lib64/ld-2.17.so
7f28dae16000-7f28dae17000 rw-p 00022000 fd:01 1053320 /usr/lib64/ld-2.17.so
7f28dae17000-7f28dae18000 rw-p 00000000 00:00 0
7ffe852fa000-7ffe8531b000 rw-p 00000000 00:00 0 [stack]
7ffe85331000-7ffe85333000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在 Linux 操作系统中,可以通过 /proc/[pid]/mem 访问和修改进程的内存页,可以通过 /proc/[pid]/maps 看到进程当前已映射的内存区域,如上所示。从 maps 中可以看到堆空间(00cba000-00cdb000)靠近低地址,而栈空间(7ffe852fa000-7ffe8531b000)靠近高地址。还可以看到 heap 的访问权限是 rw(可读写)。
所以我们可以通过堆地址找到示例程序中字符串的地址,并通过修改 mem 文件对应地址的数据内容,从而可以修改字符串。这里我们使用下述的 Python 脚本进行试验。
#!/usr/bin/env python3
''' Locates and replaces the first occurrence of a string in the heap
of a process Usage: ./read_write_heap.py PID search_string replace_by_string
Where: - PID is the pid of the target process
- search_string is the ASCII string you are looking to overwrite
- replace_by_string is the ASCII string you want to replace
search_string with
'''
import sys
def print_usage_and_exit(): print('Usage: {} pid search write'.format(sys.argv[0])) sys.exit(1)
# check usage
if len(sys.argv) != 4: print_usage_and_exit()
# get the pid from args
pid = int(sys.argv[1])
if pid <= 0: print_usage_and_exit()
search_string = str(sys.argv[2])
if search_string == "": print_usage_and_exit()
write_string = str(sys.argv[3])
if search_string == "": print_usage_and_exit()
# open the maps and mem files of the process
maps_filename = "/proc/{}/maps".format(pid)
print("[*] maps: {}".format(maps_filename))
mem_filename = "/proc/{}/mem".format(pid)
print("[*] mem: {}".format(mem_filename))
# try opening the maps file
try: maps_file = open('/proc/{}/maps'.format(pid), 'r')
except IOError as e: print("[ERROR] Can not open file {}:".format(maps_filename)) print(" I/O error({}): {}".format(e.errno, e.strerror)) sys.exit(1)
for line in maps_file: sline = line.split(' ') # check if we found the heap if sline[-1][:-1] != "[heap]": continue print("[*] Found [heap]:") # parse line addr = sline[0] perm = sline[1] offset = sline[2] device = sline[3] inode = sline[4] pathname = sline[-1][:-1] print("\tpathname = {}".format(pathname)) print("\taddresses = {}".format(addr)) print("\tpermisions = {}".format(perm)) print("\toffset = {}".format(offset)) print("\tinode = {}".format(inode)) # check if there is read and write permission if perm[0] != 'r' or perm[1] != 'w': print("[*] {} does not have read/write permission".format(pathname)) maps_file.close() exit(0) # get start and end of the heap in the virtual memory addr = addr.split("-") if len(addr) != 2: # never trust anyone, not even your OS :) print("[*] Wrong addr format") maps_file.close() exit(1) addr_start = int(addr[0], 16) addr_end = int(addr[1], 16) print("\tAddr start [{:x}] | end [{:x}]".format(addr_start, addr_end)) # open and read mem try: mem_file = open(mem_filename, 'rb+') except IOError as e: print("[ERROR] Can not open file {}:".format(mem_filename)) print(" I/O error({}): {}".format(e.errno, e.strerror)) maps_file.close() exit(1) # read heap mem_file.seek(addr_start) heap = mem_file.read(addr_end - addr_start) # find string try: i = heap.index(bytes(search_string, "ASCII")) except Exception: print("Can't find '{}'".format(search_string)) maps_file.close() mem_file.close() exit(0) print("[*] Found '{}' at {:x}".format(search_string, i)) # write the new string print("[*] Writing '{}' at {:x}".format(write_string, addr_start + i)) mem_file.seek(addr_start + i) mem_file.write(bytes(write_string, "ASCII")) # close files maps_file.close() mem_file.close() # there is only one heap in our example break
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
执行脚本对进程的堆空间的内容进行修改:
$ python3 loop.py 18539 test_memory test_hello
[*] maps: /proc/18539/maps
[*] mem: /proc/18539/mem
[*] Found [heap]:
pathname = [heap]
addresses = 00cba000-00cdb000
permisions = rw-p
offset = 00000000
inode = 0
Addr start [cba000] | end [cdb000]
[*] Found 'test_memory' at 10
[*] Writing 'test_hello' at cba010
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果 test_memory 给修改为 test_helloy:
267] test_memory (0xcba010)
[268] test_memory (0xcba010)
[269] test_memory (0xcba010)
[270] test_helloy (0xcba010)
[271] test_helloy (0xcba010)
[272] test_helloy (0xcba010)
[273] test_helloy (0xcba010)
[274] test_helloy (0xcba010)
[275] test_helloy (0xcba010)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
文章来源: is-cloud.blog.csdn.net,作者:范桂飓,版权归原作者所有,如需转载,请联系作者。
原文链接:is-cloud.blog.csdn.net/article/details/106873789

- 点赞
- 收藏
- 关注作者
评论(0)