C 语言编程 — 大小端区分

【摘要】 目录
文章目录
目录大端、小端区分方式 1区分方式 2
大端、小端
大端:高位字节放在内存的低地址端,低位字节放在内存的高地址端,CPU 对操作数的存放方式从高字节到低字节。
小端:低位字节放在内存的低地址端,高位字节放在内存的高地址端,CPU 对操作数的存放方式从低字节到高字节。
假设我们的内存是这样的:
我们要存一个数据 0x4433221...
目录
大端、小端
大端:高位字节放在内存的低地址端,低位字节放在内存的高地址端,CPU 对操作数的存放方式从高字节到低字节。
小端:低位字节放在内存的低地址端,高位字节放在内存的高地址端,CPU 对操作数的存放方式从低字节到高字节。
假设我们的内存是这样的:
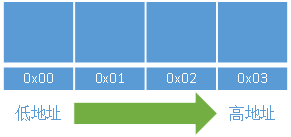
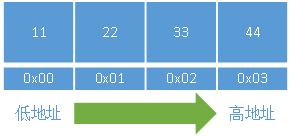
我们要存一个数据 0x44332211 到这块内存里面去如果系统是 小端模式 的话,存储方式如下图:
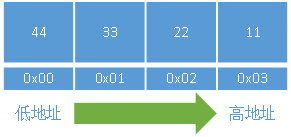
如果系统是 大端模式 的话,存储方式如下图:
区分方式 1
通过判断内存的低地址是否为 1 来区分大小端:指针类型转换,将长度大的 int 类型转换为长度小的 char 类型,最后再取 char* 指针的值,就知道数据 1 存放在高端地址还是低端地址了。
#include <stdio.h>
int main()
{ int i = 1; (*(char*)&i == 1) ? printf("Little-endian\n") : printf("Big-endian\n"); return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
区分方式 2
利用共用体的特点:使用长度最大的那个数据类型作为共用体的大小。所以,char a 使用的是 int b 的空间大小,判断 a 的值,也就是判断低地址的数据值。
#include <stdio.h>
union System { char a; int b;
};
int main()
{ union System s; s.b = 1; printf("0x%x\n", &s.a); printf("0x%x\n", &s.b); if (s.a == 1) { printf("Little-endian\n"); } else { printf("Big-endian\n"); } return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
文章来源: is-cloud.blog.csdn.net,作者:范桂飓,版权归原作者所有,如需转载,请联系作者。
原文链接:is-cloud.blog.csdn.net/article/details/106898871

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)