Python爬虫实践 四种姿势爬取豆瓣电影Top250信息!

【摘要】
文章目录
一、分析网页
二、正则表达式
三、BeautifulSoup
四、PyQuery
五、Xpath
六、总结
一、分析网页
电影信息在 ol class 为 grid_view 下的 li 标签里,获取到所有li标签的内容,然后遍历,从中提取出每一条电影的信息。
翻页查看url变化规律:
第1页:ht...
一、分析网页
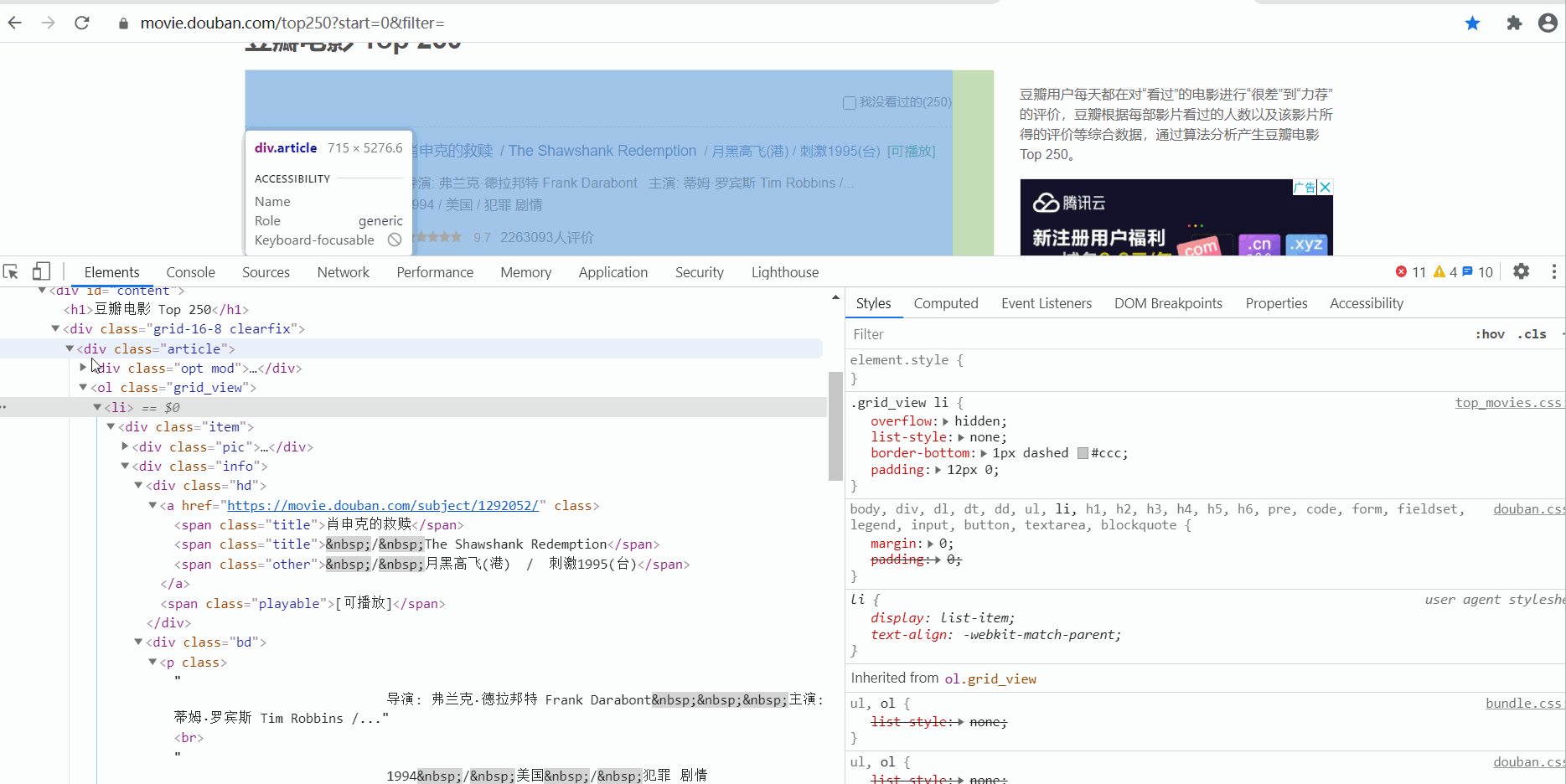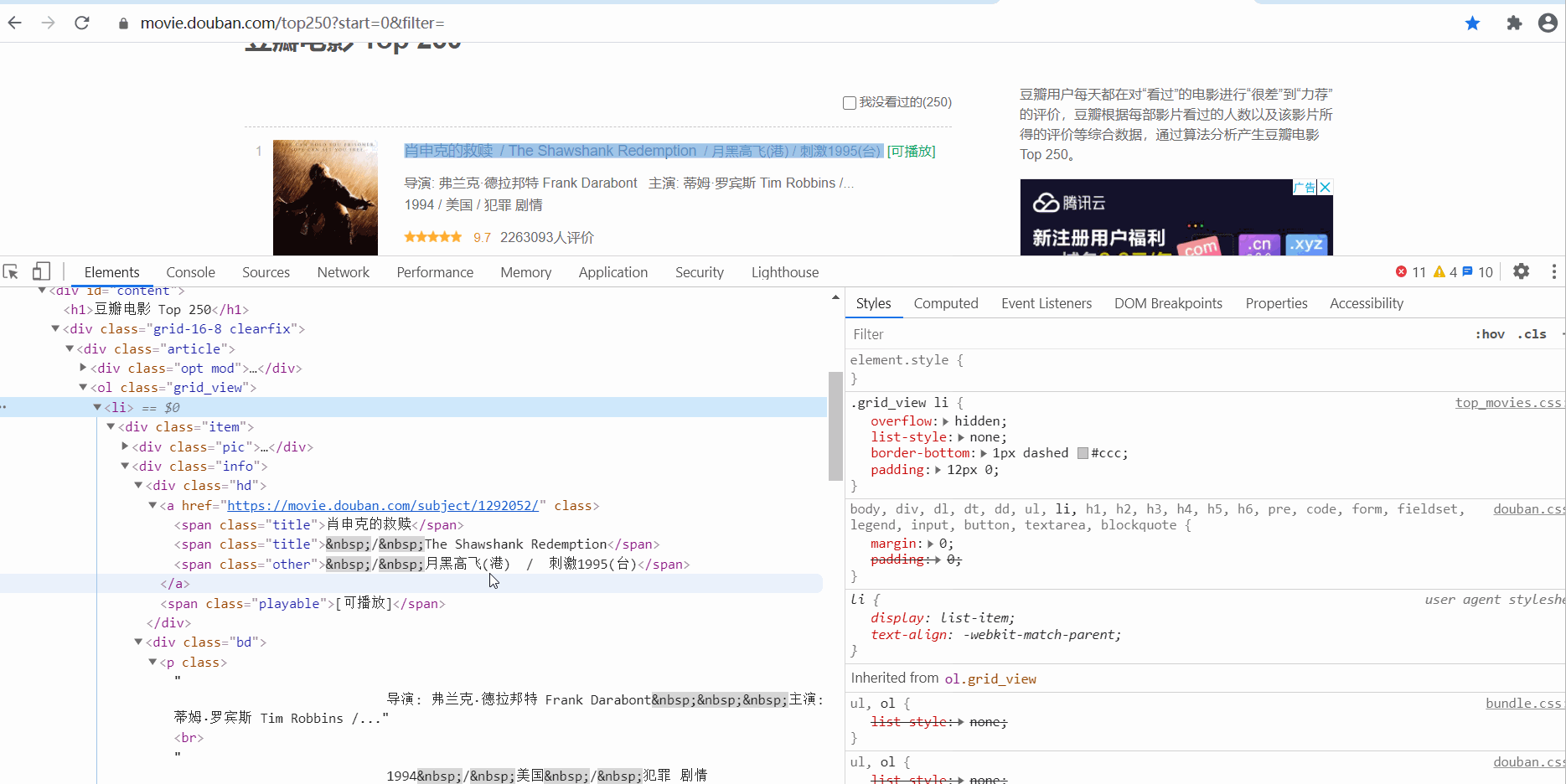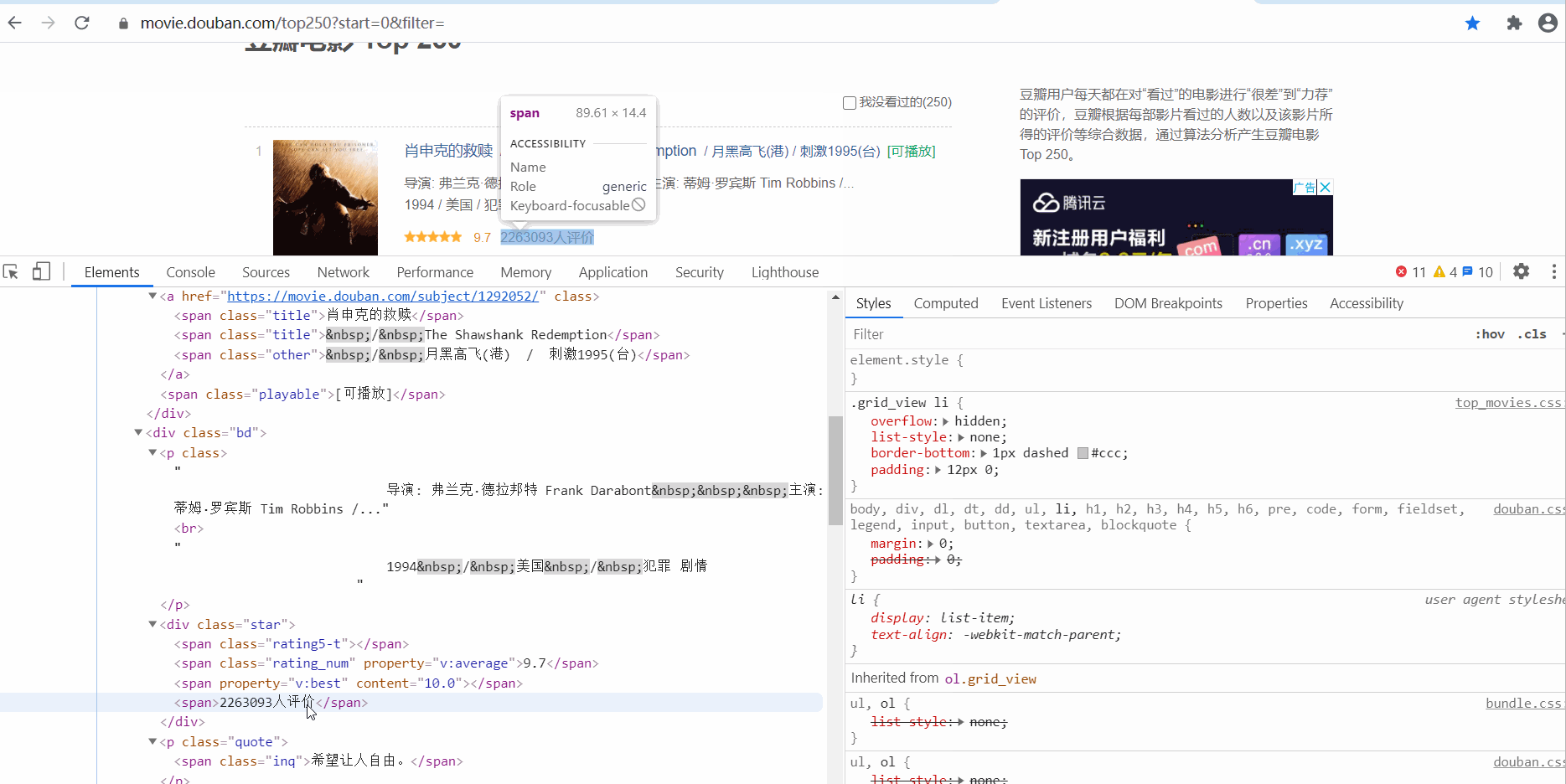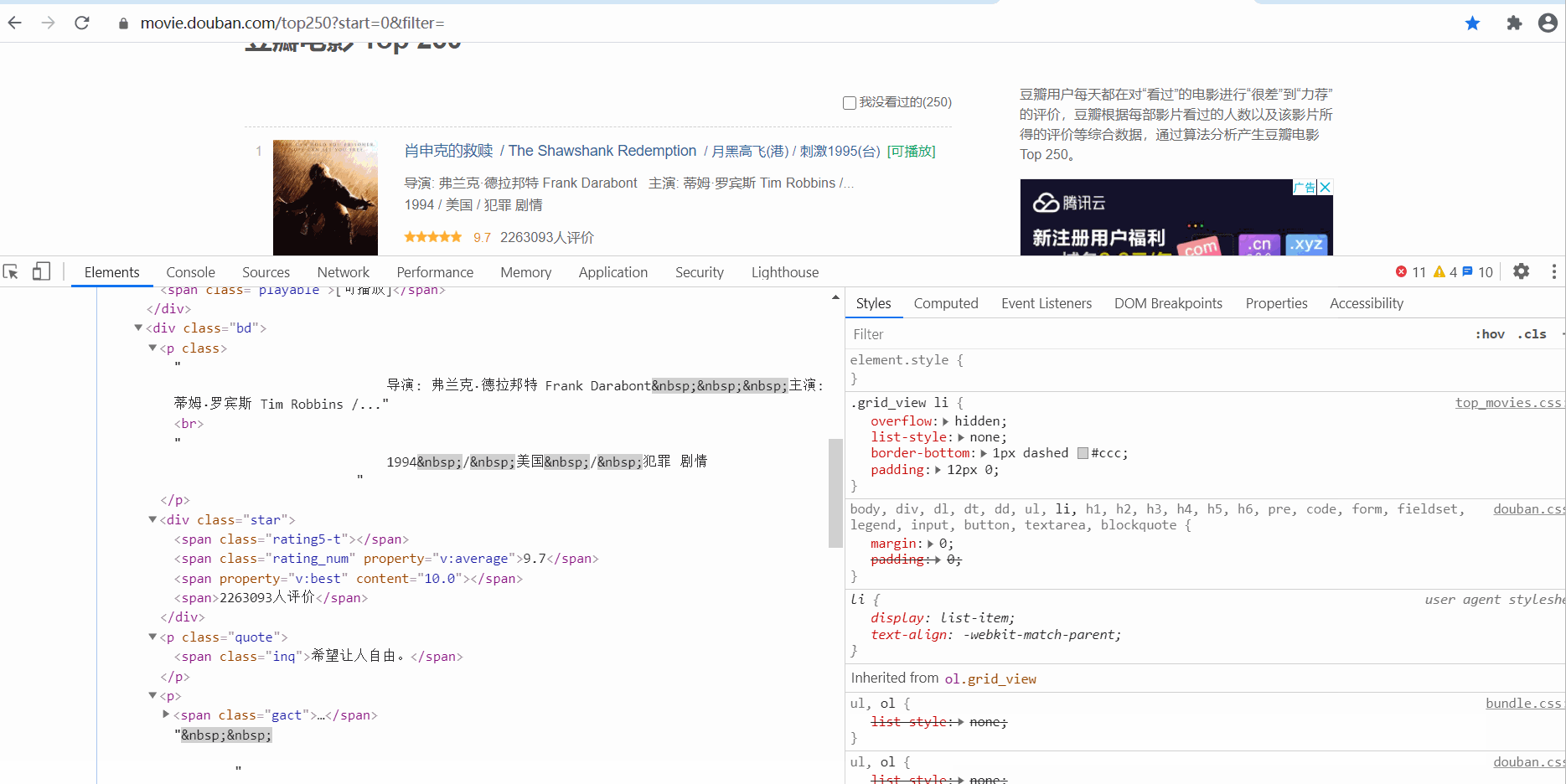
电影信息在 ol class 为 grid_view 下的 li 标签里,获取到所有li标签的内容,然后遍历,从中提取出每一条电影的信息。
翻页查看url变化规律:
第1页:https://movie.douban.com/top250?start=0&
文章来源: yetingyun.blog.csdn.net,作者:叶庭云,版权归原作者所有,如需转载,请联系作者。
原文链接:yetingyun.blog.csdn.net/article/details/117231520

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)