学习YOLOv2

1.论文总述
在YOLOv1的基础上,通过改进,提出了YOLOv2和YOLO9000算法思想。重点解决YOLOv1召回率和定位精度方面的误差。在提出时,YOLOv2在多种数据集中,都要快过其他检测系统,并可以在速度与精确度上进行权衡。
YOLOv2采用Darknet-19作为特征提取网络,增加了批量标准化(Batch Normalization)的预处理,并使用224×224和448×448两阶段训练ImageNet,得到预训练模型后fine-tuning。
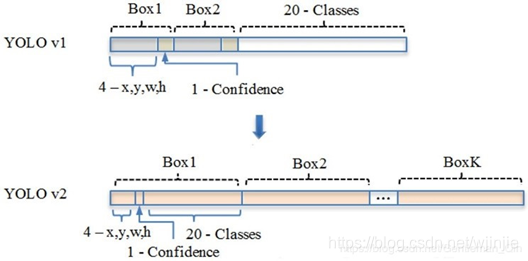
相比于YOLOv1是利用FC层直接预测Bounding Box的坐标,YOLOv2借鉴了FSR-CNN的思想,引入Anchor机制,利用K-Means聚类的方式在训练集中聚类计算出更好的Anchor模板,在卷积层使用Anchor Boxes操作,增加Region Proposal的预测,同时采用较强约束的定位方法,大大提高算法召回率。同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
下图1展示了:YOLOv2中不同改进点带来的性能提升
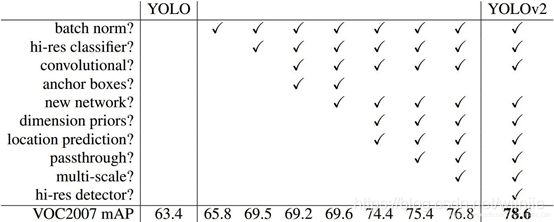
YOLO9000 的主要检测网络也是YOLOv2,同时使用WorldTree来混合来自不同资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,目的是利用数量较大的分类数据集来帮助训练检测模型,因此,YOLO9000的网络结构允许实时地检测超过9000种物体分类,进一步缩小了检测数据集与分类数据集之间的大小代沟。
2.YOLOv2各个改进点
2.1 Batch Normalization(mAP提升2%)
BN是2015年Google研究员在论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》一文中提出的,具体细节可参考这篇论文。
作用:
对数据进行预处理(统一格式、均衡化、去噪等)能够大大提高训练速度,提升训练效果。BN正是基于这个假设的实践,对每一层输入的数据进行加工。
在YOLOv2中,就是就是对网络的每一个卷积层的输入都做归一化,这样网络就不需要每层都去学数据的分布,收敛会更快。
优点:
a.神经网络每层输入的分布总是发生变化,加入BN,通过标准化上层输出,均衡输入数据分布,加快训练速度,提高了网络的收敛性。
b.输入标准化对应样本正则化,BN在一定程度上可以替代 Dropout解决过拟合问题。
BN算法实现:
在卷积或池化之后,激活函数之前,对每个数据输出进行标准化,实现方式如下图所示:

图中前三行是对Batch进行数据归一化(如果一个Batch中有训练集每个数据,那么同一Batch内数据近似代表了整体训练数据),第四行引入了附加参数 γ 和 β,这两个参数的具体取值算法可以参考BN论文。
2.2 High Resolution Classifier (mAP提升4%)
所有先进的检测方法都是在ImageNet上进行分类预训练。
YOLOv1在预训练时采用的是224224的输入(在ImageNet数据集上进行),然后在检测的时候采用448448的输入,这会导致从分类模型切换到检测模型的时候,模型还要适应图像分辨率的改变。
YOLOv2则将预训练分成两步:
a.用224224的输入在ImageNet数据集训练分类网络,将所有训练数据循环跑160次。
b.将输入调整到448448,再在ImageNet数据集上训练,将所有训练数据循环跑10次(10个epoch)。
然后利用预训练得到的模型在detection数据集上fine tuning。这样训练得到的模型,在检测时用448*448的图像作为输入可以顺利检测。
使用了fine Turing思想,具体原理是:先在标准数据集(如ImageNet等)上进行一定次数的预训练,或采用已经训练好的模型。在此模型参数的基础上,来训练自己的数据集,得到最终的模型参数。
优点:由于在训练初始阶段,网络模型的参数还比较发散,使得loss值很大,模型准确率都会从很低的值开始慢慢上升。因此在已经训练好的基础再进行训练,可以使得在较少的迭代次数之后达到不错的效果,,大大缩短了训练周期。
具体的训练过程将在后面给到。
2.3 Convolution With Anchor Boxes (mAP下降0.3%,recall提升7%)
YOLOv1将输入图像分成77的网格,每个网格预测2个Bounding Box,因此一共有98个Box,同时YOLOv1包含有全连接层,从而能直接预测Bounding Boxes的坐标值,但也导致丢失较多的空间信息,定位不准。除此之外,一个致命的缺陷就是:一个grid cell只能预测一个class,当一个grid cell中同时出现多个类时,就无法检测出所有类。基于这些问题,YOLOv2做出了相应的改进。
YOLOv2的改进:
首先将YOLOv1网络的FC层和最后一个Pooling层去掉,使得最后的卷积层的输出可以有更高的分辨率特征。
然后缩减网络,用416416大小的输入代替原来的448448,使得网络输出的特征图有奇数大小的宽和高,进而使得每个特征图在划分单元格(Cell)的时候只有一个中心单元格(Center Cell)。YOLOv2通过5个Pooling层进行下采样,得到的输出是1313的像素特征。
借鉴Faster R-CNN, YOLOv2通过引入Anchor Boxes,预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。
采用Faster R-CNN中的方式,每个Cell可预测出9个Anchor Box,共13139=1521个(YOLOv2确定Anchor Boxes的方法见是维度聚类,每个Cell选择5个Anchor Box)。比YOLOv1预测的98个bounding box 要多很多,因此在定位精度方面有较好的改善。
2.4 Dimension Clusters(维度聚类)
在Faster R-CNN中Anchor Box的大小和比例是按,经验设定的,然后网络会在训练过程中调整Anchor Box的尺寸,最终得到准确的Anchor Boxes。若一开始就选择了更好的、更有代表性的先验Anchor Boxes,那么网络就更容易学到准确的预测位置。
YOLOv2使用K-means聚类方法类训练Bounding Boxes,可以自动找到更好的宽高维度的值用于一开始的初始化。传统的K-means聚类方法使用的是欧氏距离函数,意味着较大的Anchor Boxes会比较小的Anchor Boxes产生更多的错误,聚类结果可能会偏离。由于聚类目的是确定更精准的初始Anchor Box参数,即提高IOU值,这应与Box大小无关,因此YOLOv2采用IOU值为评判标准,即K-means 采用的距离函数(度量标准)为:
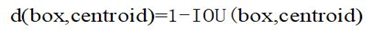
聚类效果图如下:
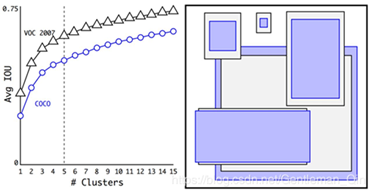
其中紫色和灰色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。
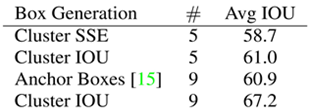
从表中可以看出,YOLOv2采用5种Anchor比Faster R-CNN采用9种Anchor得到的Avg IOU还略高,并且当YOLOv2采用9种时,Avg IOU有显著提高。说明K-means方法的生成的boxes更具有代表性。为了权衡精确度和运算开销,最终选择K=5。
文章来源: ai-wx.blog.csdn.net,作者:AI 菌,版权归原作者所有,如需转载,请联系作者。
原文链接:ai-wx.blog.csdn.net/article/details/104433200

- 点赞
- 收藏
- 关注作者
评论(0)