深度学习笔记(二):激活函数的前世今生

一、激活函数的前世今生
早在1958 年,美国心理学家 Frank Rosenblatt 就提出了第一个可以自动学习权重的神经元模型,称为感知机。它的模型如下:

从图中可以看出,他使用的是一个简单的一层网络,其中激活函数是阶跃函数(这也是最早使用的激活函数)。
于是这个感知机模型的公式可表示为:
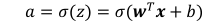
其中的激活函数可表示为:
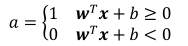
也就是说,当wx+b<0时,令输出为0,代表类别0;当wx+b>=0时,令输出为1,代表类别1。然后通过感知机收敛算法一步步迭代,优化参数w和b,最终实现了最原始的二分类模型。
于是有些同学会问,为什么不是用梯度下降算法呢??
对,熟悉人工智能历史的同学肯定知道,那时候反向传播算法都还没有提出,肯定不会有梯度下降的说法。那为什么聪明的 Frank没有想到梯度下降呢?
其实这里有一个不可抗力的原因。而这个原因和激活函数密切相关!在当时,最常用的激活函数不外乎:阶跃函数和符号函数,我们来直观地看一下它们的函数图:

左边是阶跃函数,右边是符号函数。这两个函数有一个共通的特点:在 z=0处是不连续的,其他位置导数为 0,这就使得无法利用梯度下降算法进行参数优化。
注:梯度都为0了,梯度下降自然就无效了,这也是后面要说到的梯度弥散现象。
感知机模型的不可导特性严重约束了它的潜力,使得它只能解决极其简单的任务。所以现代深度学习,在感知机的基础上,将不连续的阶跃激活函数换成了其它平滑连续激活函数,使得模型具有可导性。实际上,现代大规模深度学习的核心结构与感知机并没有多大差别,只是通过堆叠多层网络层来增强网络的表达能力。
那么,下面将主要介绍现在最常用的一些平滑连续激活函数
二、不得不知的激活函数
1. Sigmoid
Sigmoid 函数也叫 Logistic 函数,定义为:
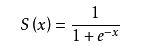
如下图所示,Sigmoid 函数连续可导,其值域为(0, 1),相对于阶跃函数,可以直接利用梯度下降算法优化网络参数,应用的非常广泛。

作为激活函数,将输入映射到0~1,因此可以通过 Sigmoid 函数将输出转译为概率输出,常用于表示分类问题的事件概率。
对S(x)求导:
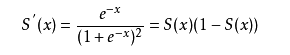
导数性质:在输入x=0时,导数最大为0.25;当输入为正负无穷时,梯度趋于0,会发生梯度弥散。
优点:平滑、易于求导
缺点:指数级计算,计算量大;容易出现梯度弥散的情况。
2. Tanh
Tanh函数,即双曲正切函数,其定义为:
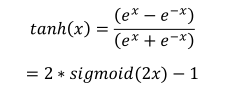
可以看到 tanh 激活函数可通过 Sigmoid 函数缩放平移后实现,函数曲线如下图::

Tanh 函数能够将输入x映射到[−1,1]区间。是Sigmoid函数的改进版,输出有正有负,是以0为中心的对称函数,收敛速度快,不容易出现loss值震荡。但是无法解决梯度弥散问题,同时计算量也大。
3. ReLU
在 ReLU(REctified Linear Unit,修正线性单元)激活函数提出之前,Sigmoid 函数通常是神经网络的激活函数首选。但是 Sigmoid 函数在输入值较大或较小时容易出现梯度弥散现象,网络参数长时间得不到更新,很难训练较深层次的网络模型。2012 年提出的 8 层 AlexNet 采用了一种名叫 ReLU 的激活函数,使得网络层数达到了 8 层。ReLU 函数定义为:ReLU(x) = max(0, x)
ReLU 对小于 0 的值全部抑制为 0;对于正数则直接输出,这种单边抑制特性来源于生物学。其函数曲线如下:

优点:
(1) 使训练快速收敛,解决了梯度弥散。在信息传递的过程中,大于0的部分梯度总是为1。
(2) 稀疏性:模拟神经元的激活率是很低的这一特性;ReLU的输入在大于0时才能传播信息,正是这样的稀疏性提高了网络的性能。
缺点:在输入小于0的时候,即使有很大的梯度传播过来也会戛然而止。
ReLU 函数的设计源自神经科学,计算十分简单,同时有着优良的梯度特性,在大量的深度学习应用中被验证非常有效,是应用最广泛的激活函数之一。
4. Leaky ReLU
ReLU 函数在输入x < 0时梯度值恒为 0,也可能会造成梯度弥散现象,为了克服这个问题,提出了Leaky ReLU,定义如下:
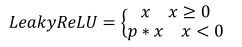
其中p为用户自行设置的某较小数值的超参数,如 0.02 等。当p = 0时,LeayReLU 函数退化为 ReLU 函数。当p ≠ 0时,x < 0能够获得较小的梯度值,从而避免了梯度弥散。函数曲线如下:

5. Softmax
Softmax 函数定义:
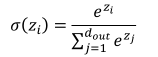
Softmax 函数不仅可以将输出值映射到[0,1]区间,还满足所有的输出值之和为 1 的特性。如下图的例子,输出层的输出为[2.,1.,0.1],经过 Softmax 函数计算后,得到输出为[0.7,0.2,0.1],可以看到每个值代表了当前样本属于每个类别的概率,概率值之和为 1。
通过 Softmax 函数可以将输出层的输出转译为类别概率,在多分类问题中使用的非常频繁。
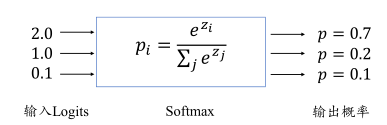
另外,在softmax函数多分类问题中,若损失函数选用交叉熵,则下降梯度计算起来将会非常方便,使得网络训练过程中的迭代计算复杂度大大降低。
6. Softplus
函数定义为: f ( x ) = l n ( 1 + e x ) f(x)=ln(1+e^x) f(x)=ln(1+ex),值域为(0,+无穷),其图像如下图所示:

softplus可以看作是ReLu的平滑。根据神经科学家的相关研究,softplus和ReLu与脑神经元激活频率函数有神似的地方。也就 是说,相比于早期的激活函数,softplus和ReLU更加接近脑神经元的激活模型。
7. Mish
在YOLOv3中,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU。而在YOLOv4的主干网络CSPDarknet53中,使用Mish代替了原来的Leaky ReLU。Leaky ReLU和Mish激活函数的公式与图像如下:
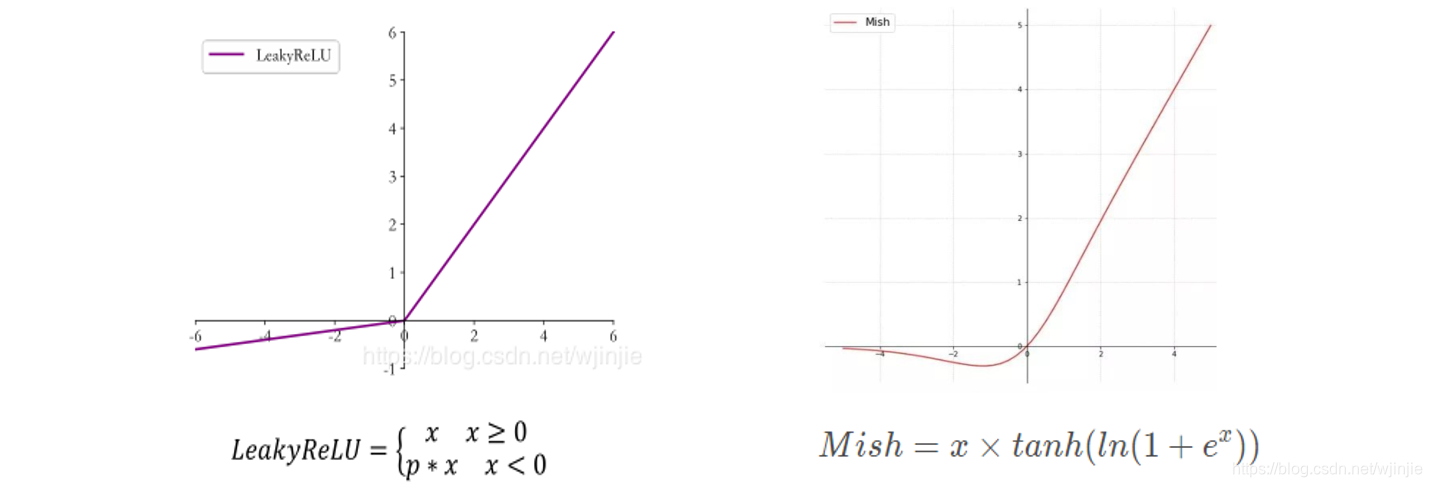
常见的激活函数总结:

文章来源: ai-wx.blog.csdn.net,作者:AI 菌,版权归原作者所有,如需转载,请联系作者。
原文链接:ai-wx.blog.csdn.net/article/details/104729911

- 点赞
- 收藏
- 关注作者
评论(0)