【算法与数据结构 08】字符串 —— 字符串匹配算法(面试高频考点!)

一、白话字符串
1.1 什么是字符串
字符串是由 n 个字符组成的一个有序整体( 其中,n >= 0 )。例如,s = “AI Jun” ,s 代表这个串的串名,AI Jun 是串的值。这里的双引号不是串的值,作用只是为了将串和其他结构区分开。
在实际操作中,我们经常会用到一些特殊的字符串:
- 空串,指含有零个字符的串。例如,s = " "
- 空格串,只包含空格的串。它和空串是不一样的,空格串中是有内容的,只不过包含的是空格,且空格串中可以包含多个空格。例如,s = " ",就是包含了 2 个空格的字符串。
- 子串,串中任意连续字符组成的字符串叫作该串的子串。
1.2 字符串的存储结构
字符串的存储结构与线性表相同,也有顺序存储和链式存储两种。
- 字符串的顺序存储结构,是用一组地址连续的存储单元来存储串中的字符序列,一般是用定长数组来实现。有些语言会在串值后面加一个不计入串长度的结束标记符,比如 \0 来表示串值的终结。
- 字符串的链式存储结构,与线性表是相似的,但由于串结构的特殊性(结构中的每个元素数据都是一个字符),如果也简单地将每个链结点存储为一个字符,就会造成很大的空间浪费。因此,一个结点可以考虑存放多个字符,如果最后一个结点未被占满时,可以使用 “#” 或其他非串值字符补全。如下图所示:

在链式存储中,每个结点设置字符数量的多少,与串的长度、可以占用的存储空间以及程序实现的功能相关:
- 如果字符串中包含的数据量很大,但是可用的存储空间有限,那么就需要提高空间利用率,相应地减少结点数量。
- 而如果程序中需要大量地插入或者删除数据,应该相应地增加节点数,这样方便增删操作。
总的来说,串的链式存储结构在连接串与串操作时有一定的方便。但是更常用的还是字符串的顺序存储结构,因为它更灵活,与数组相似,可直接通过索引获取元素。
二、字符串的增删查操作
字符串问题中考察更多的是查找子串的位置、替换等操作。下来我们以顺序存储为例,详细介绍一下字符串对于另一个字符串的增删查操作。
2.1 新增操作
字符串的新增操作和数组非常相似,也有两种情况:(假设 s1=“123”, s2=“abc”)
- 在字符串末尾新增,时间复杂度是O(1)。比如,s1 的最后插入 s2,也叫作字符串的连接,最终得到"123abc"。
- 在字符串中间位置新增,时间复杂度是O(n)。比如,在s1的1和2之前新增s2得到“1abc23”。
2.2 删除操作
字符串的删除操作和数组同样非常相似,也有两种情况:
- 删除字符串末尾元素时,不涉及字符的挪位,所以时间复杂度是O(1)。
- 牵涉删除字符串后字符的挪移操作,那么时间复杂度是 O(n)。
2.3 查找操作
- 一般而言,只是根据索引值进行一次查找,时间复杂度是O(1)。
- 更为常见的考点是查找子串是否在字符串中出现过,这类问题也被称作子串查找或字符串匹配。具体的时间复杂度要看情况而定。接下来我们来重点分析。
三、字符串匹配算法
3.1 案例1
题目如下:
字符串 s = "goodgoogle",判断字符串 t = "google" 在 s 中是否存在。
- 1
题目分析:
首先,我们来定义两个概念,主串和模式串。我们在字符串 A 中查找字符串 B,则 A 就是主串,B 就是模式串。我们把主串的长度记为 n,模式串长度记为 m。由于是在主串中查找模式串,因此,主串的长度肯定比模式串长,n>m。因此,字符串匹配算法的时间复杂度就是 n 和 m 的函数。
算法流程:
假设要从主串 s = “goodgoogle” 中找到 t = “google” 子串。根据我们的思考逻辑,则有:
- 首先,我们从主串 s 第 1 位开始,判断 s 的第 1 个字符是否与 t 的第 1 个字符相等。
- 如果不相等,则继续判断主串的第 2 个字符是否与 t 的第1 个字符相等。直到在 s 中找到与 t 第一个字符相等的字符时,然后开始判断它之后的字符是否仍然与 t 的后续字符相等。
- 如果持续相等直到 t 的最后一个字符,则匹配成功。
- 如果发现一个不等的字符,则重新回到前面的步骤中,查找 s 中是否有字符与 t 的第一个字符相等。
- 如下图所示,s 的第1 个字符和 t 的第 1 个字符相等,则开始匹配后续。直到发现前三个字母都匹配成功,但 s 的第 4 个字母匹配失败,则回到主串继续寻找和 t 的第一个字符相等的字符。这时我们发现主串 s 第 5 位开始相等,并且随后的 6 个字母全匹配成功,则找到结果。

C++实现如下:
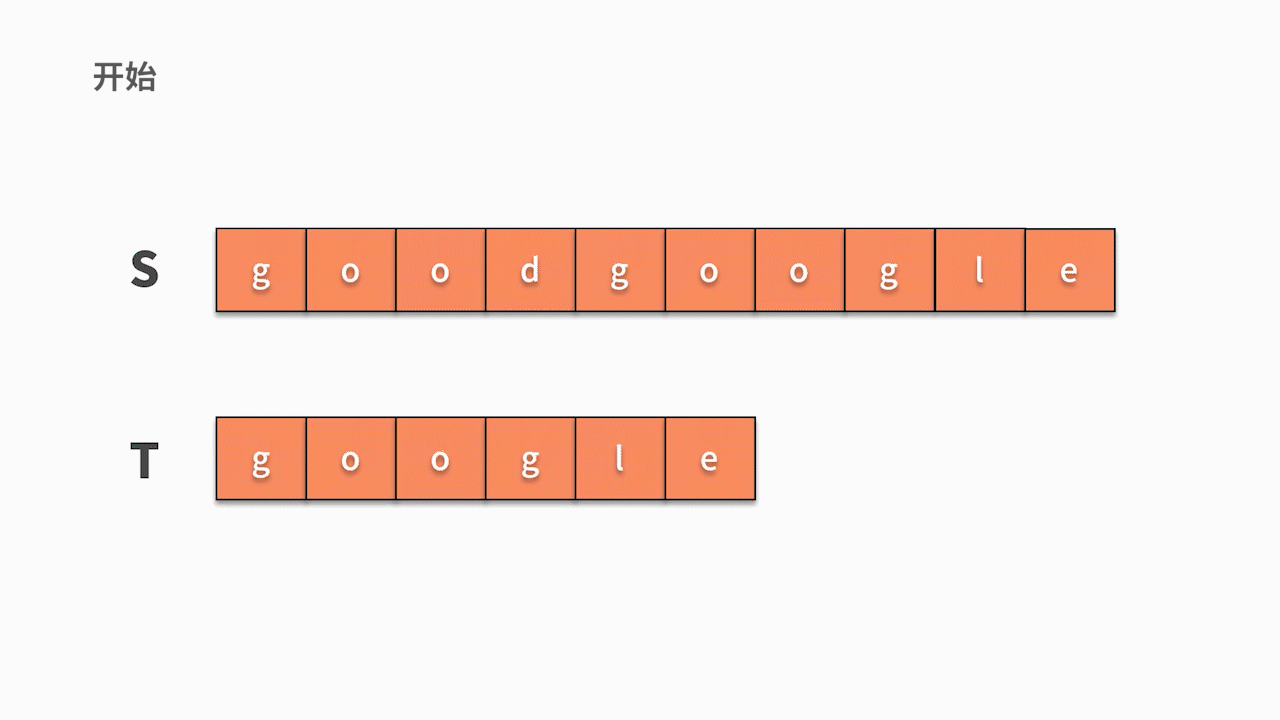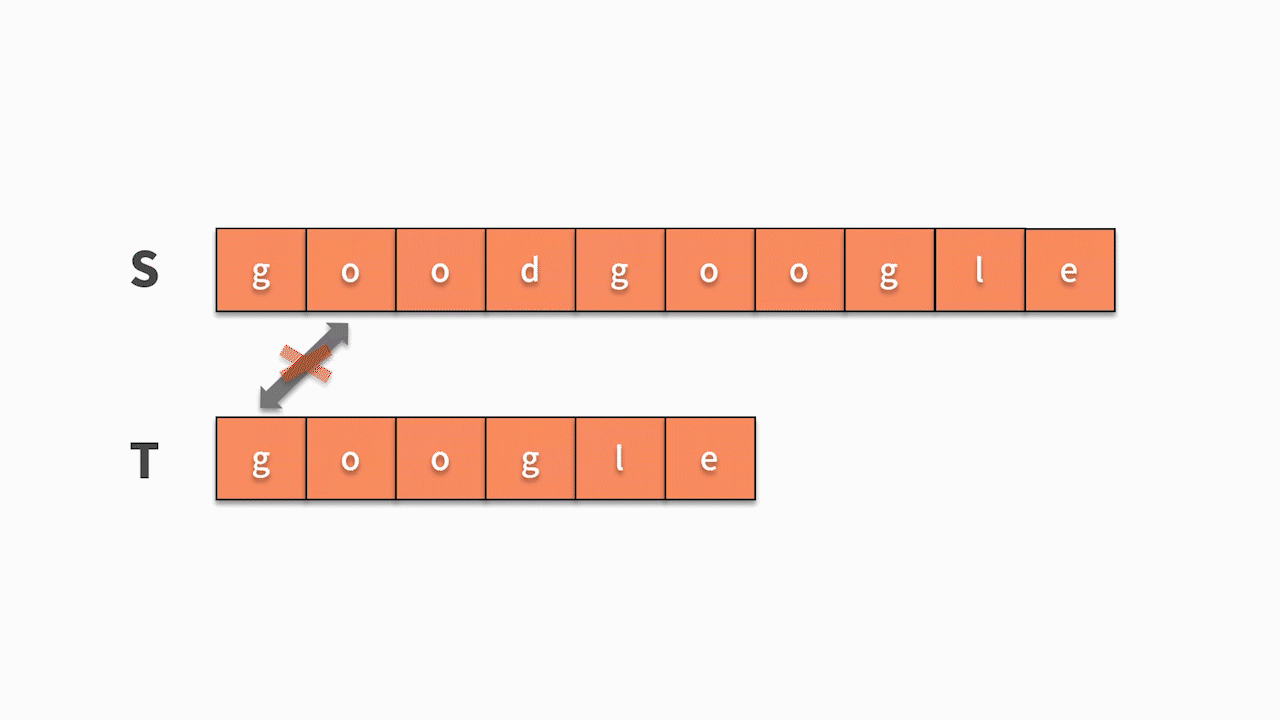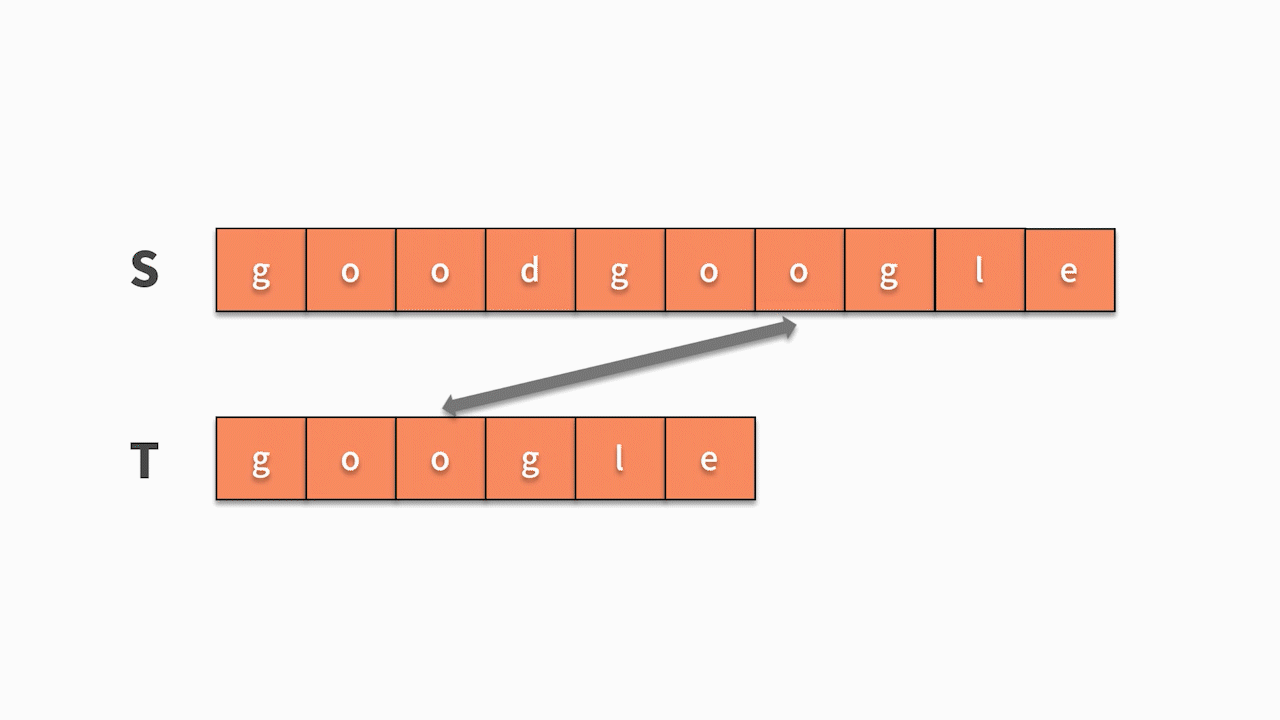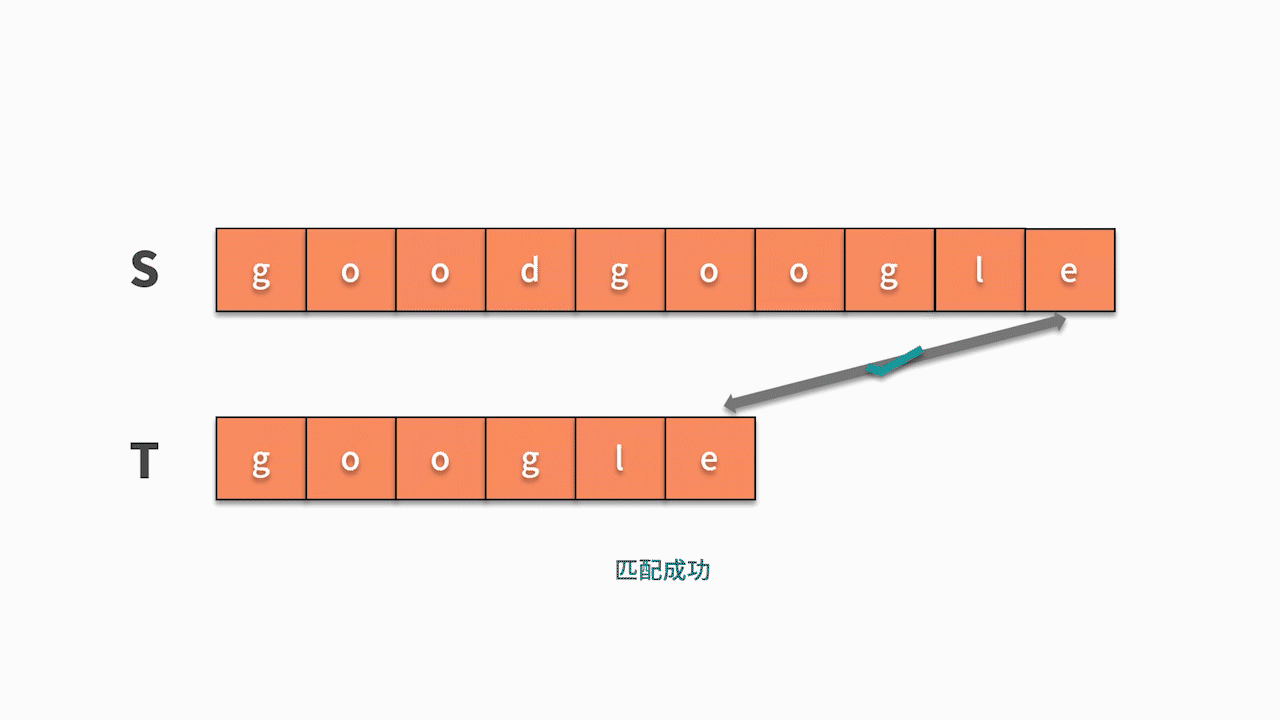
#include<iostream>
#include<string>
using namespace std;
int main()
{ string s = "goodgoogle"; string t = "google"; int isfind = 0; for(int i=0; i<s.length() - t.length() + 1; i++) { if(s[i] == t[0]) { int findIndex = 0; for(int j=0; j<t.length();j++) { if(s[i+j] != t[j]) break; findIndex = j; } if(findIndex == t.length()-1) isfind = 1; } } cout<<isfind<<endl; return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这种匹配算法需要从主串中找到跟模式串的第 1 个字符相等的位置,然后再去匹配后续字符是否与模式串相等。显然,从实现的角度来看,需要两层的循环。第一层循环,去查找第一个字符相等的位置,第二层循环基于此去匹配后续字符是否相等。因此,这种匹配算法的时间复杂度为 O(nm)。
3.2 案例2
题目如下:
查找出两个字符串的最大公共子串。
假设有且仅有 1 个最大公共子串。比如,输入 a = "13452439", b = "123456"。
由于字符串 "345" 同时在 a 和 b 中出现,且是同时出现在 a 和 b 中的最长子串。因此输出 "345"。
- 1
- 2
- 3
算法分析:
这是一道求最大公共子串的题,核心思想还是字符串匹配。
假设字符串 a 的长度为 n,字符串 b 的长度为 m,可见时间复杂度是 n 和 m 的函数。具体算法实现过程如下:
- 首先,你需要对于字符串 a 和 b 找到第一个共同出现的字符,这跟前面讲到的匹配算法在主串中查找第一个模式串字符一样。
- 然后,一旦找到了第一个匹配的字符之后,就可以同时在 a 和 b 中继续匹配它后续的字符是否相等。这样 a 和 b 中每个互相匹配的字串都会被访问一遍。全局还要维护一个最长子串及其长度的变量,就可以完成了。
C++实现如下:
#include<iostream>
#include<string>
using namespace std;
int main()
{ string a = "13452439"; string b = "123456"; int maxLength=0; string maxString; for(int i=0; i<a.length(); i++) { for(int j=0; j<b.length(); j++) { if(a[i]==b[j]) { for(int m=i, n=j; m<a.length()&&n<b.length(); m++,n++) { if(a[m] != b[n]) break; if(maxLength<m-i+1) { maxLength = m-i+1; maxString = a.substr(i, maxLength); } } } } } cout<<maxString<<endl; return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
从代码结构来看,第一步需要两层的循环去查找共同出现的字符,这就是 O(nm)。一旦找到了共同出现的字符之后,还需要再继续查找共同出现的字符串,这也就是又嵌套了一层循环。可见最终的时间复杂度是 O(nmm),即 O(nm²)。
四、相关推荐
【C++养成计划】动态数组 —— 快速上手 STL vector 类(Day14)
【白话数据结构 07】数组 —— 数组的基本操作( 增删查与时间复杂度的关系!)
文章来源: ai-wx.blog.csdn.net,作者:AI 菌,版权归原作者所有,如需转载,请联系作者。
原文链接:ai-wx.blog.csdn.net/article/details/108363260

- 点赞
- 收藏
- 关注作者
评论(0)