ICML2021 | 自提升策略规划真实且可执行的分子逆合成路线


今天给大家介绍的是韩国科学技术院(KAIST)与穆罕默德·本·扎耶德人工智能大学(MBZUAI)研究人员联合发表在ICML2021上的一篇文章。作者提出一种端到端的框架,用于直接训练深度神经网络,使预测的反应路线更符合现实中的反应要求。实验表明,该方案显著提高了解决逆合成问题的成功率,同时保持了网络预测有效反应的性能。
1.介绍
发现目标产物的合成路线在许多应用中发挥着重要作用。其中,逆合成面临的主要挑战包含两方面:(1)找到一个准确的单步逆合成模型来预测给定产物的单步反应;(2)设计一种有效的搜索算法设计完整的合成路线。目前已提出的用于单步逆合成的模型可分为三类:对产物分子应用模板以预测反应物、从头生成每种反应物、修改产物原子数目或更改化学键以获得反应物。而用于规划完整路线的搜索算法主要包含两类:将其视为顺序决策的过程、应用树搜索算法。逆合成框架的评估可以从以下两个方面出发:(1)模型提出的反应路线是否是现实世界中的反应;(2)模型预测的路线(从分子构建块开始合成)的成功率。目前的逆合成设计框架不是端到端的,而是朝着上述两个目标分别优化单步逆合成模型和搜索策略,因此模型的性能可能并未达到最佳。受此启发,作者提出了一个新的端到端逆合成框架,该框架在训练过程中同时考虑最大化搜索算法的成功率以及在真实世界中存在的反应。
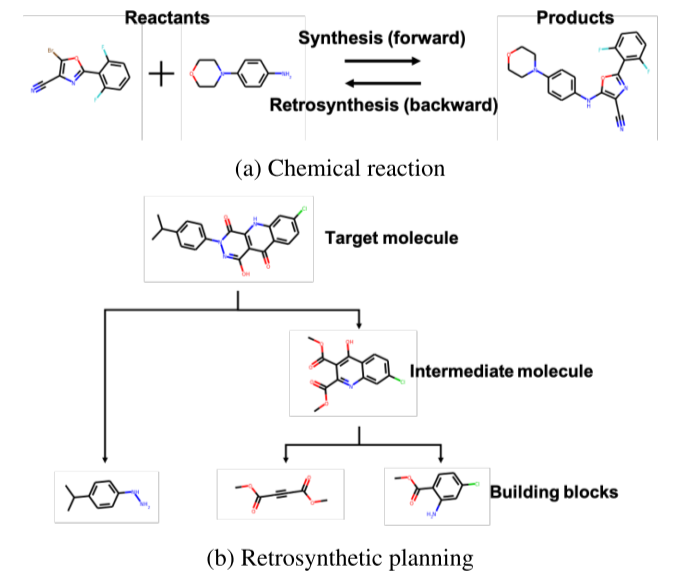
2.模型
概述
(1).单步逆合成策略 本文的单步逆合成方法是一个利用多层感知机搭建的基于模板的模型。该模型以摩根指纹作为输入,训练多层感知机预测合适的反应模板以应用。
(2).搜索算法策略 因Retro*及Retro*-0的优异表现,作者采用该搜索策略实现多步合成路线设计。Retro*算法模仿A*算法,基于当前路径的成本和到目标的估计成本进行最佳优先搜索。Retro*-0是Retro*算法的变体,不依赖值函数进行扩展,而是在模型表现和一个表示值函数的额外的DNN之间进行权衡。
(3).提升反应质量策略 为了从模仿学习的反应路径中提升反应质量,(1)作者引入一个与上述单步逆合成策略架构相同的参考逆向反应模型,该模型在真实数据集上训练以能判断某个反应是否与真实存在的反应相似;(2)提出一个基于正向反应模型的反应增强策略,以增加反应的多样性。
(4).损失设计 作者同时优化预测反应路径的真实性与成本,将参考逆向模型下反应的负对数似然的和作为合成路线的损失。
步骤
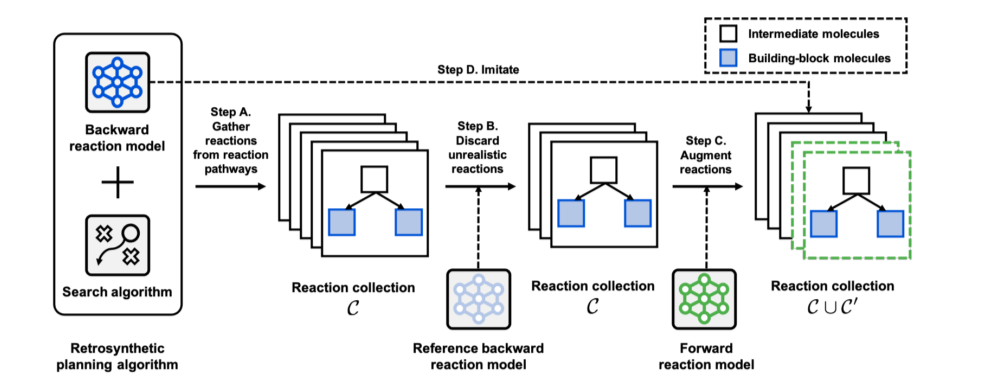
图2模型框架图
Step A.产生反应集。利用搜索算法和单步逆合成模型先产生一系列反应路径,然后收集上述反应路径中的反应形成一个初始反应集。
Step B.过滤不真实的反应。利用参考逆向模型丢弃初始反应集中与实际不符的反应以得到一个真实反应集。
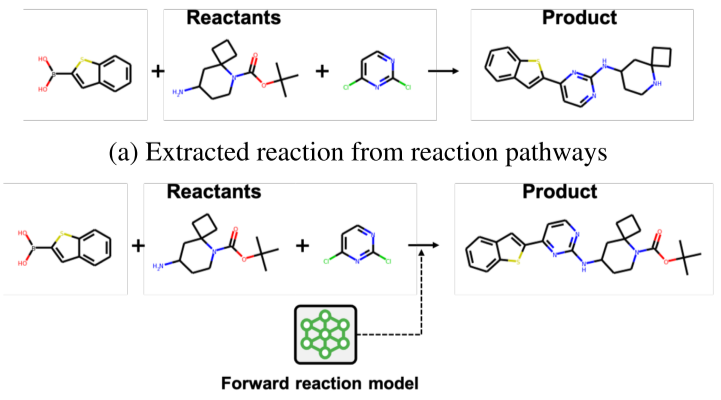
图3 增强反应示例
Step C.增强反应集。基于正向反应模型替换真实反应集中反应的产物以获得增强的反应集。
Step D.训练逆向反应模型。模拟真实反应集和增强反应集中的反应(即最大化对数似然)以训练逆合成模型。

图4 算法图
3.实验
实验设置
数据集 分子构件块来自于eMolecules,产物分子和化学反应来自于USPTO数据集。该方法中数据集的处理及训练测试验证集的划分与Retro*方法一致。
评估指标 预测整条路线的损失通过路线中反应的负对数似然之和衡量,逆合成模型通过top-k匹配成功率衡量。
实验结果
单步逆合成反应模型使用TOP-1和TOP-10的精确匹配度进行评估。使用SUCC.RATE,LENGTH,TIME,COST对反应路径进行评估。N表示逆合成反应模型调用的极限。LENGTH是指路线中的反应数量。TIME是由逆合成反应模型调用的数量来衡量的,上限为500。GREEDY DFS、MCTS和DFPN-E的实验结果来自Chen等人的文章。最好的结果用粗体字标注。括号中报告了与不使用该框架的对应方法指标的相对增益。
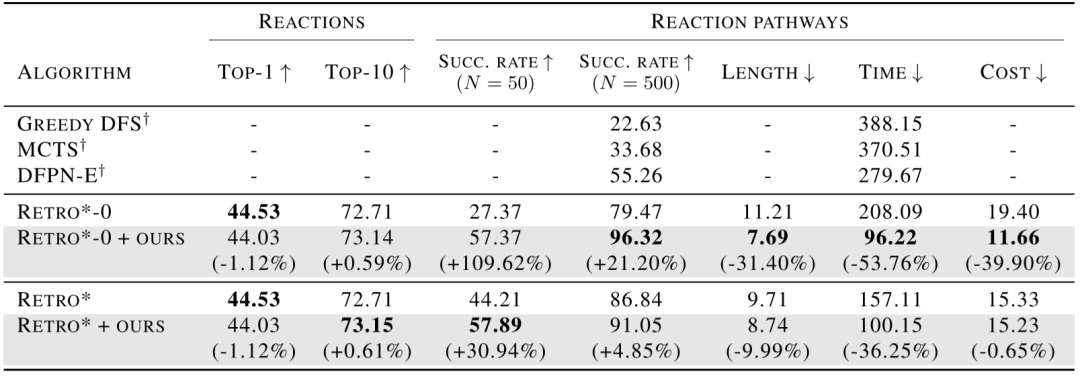
表1 在USPTO数据集上的模型性能对比表
表1和图5结果表明,该框架与Retro*或Retro*-0结合显著优于基线。另外,在设计合成路径的成本和长度上,Retro*-0+OURS 和Retro*+OURS也有明显的优势。
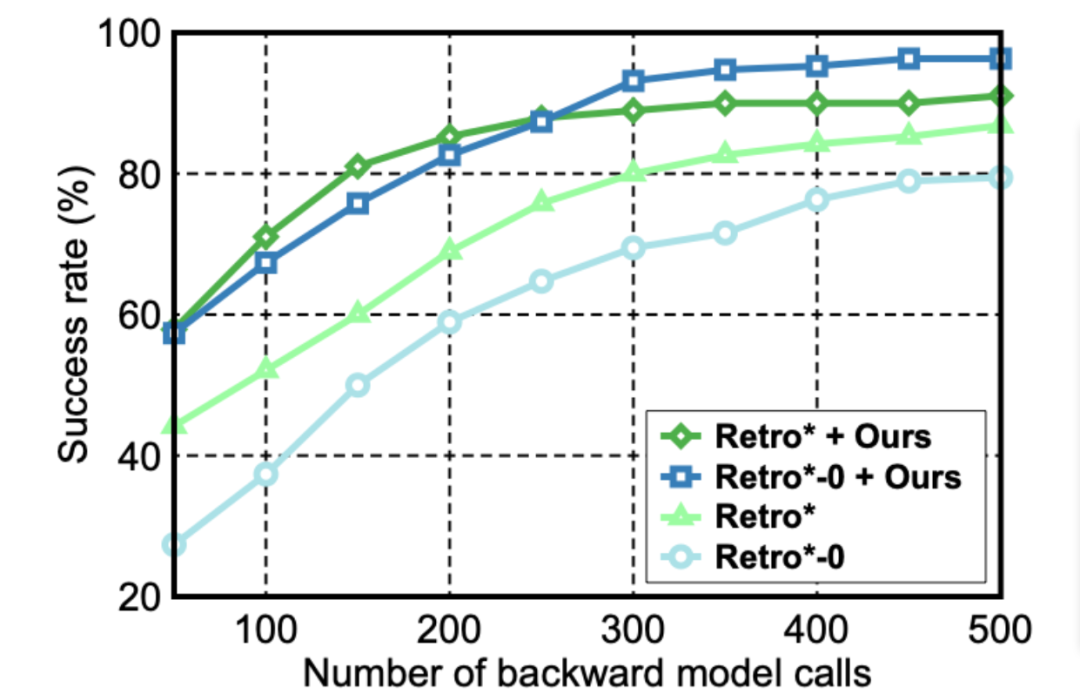
图5 在不同的逆合成反应模型调用限制下的成功率
下图展现了同一目标分子分别由(a)Retro*-0+OURS和(b)Retro*-0搜索得出的反应路径。在这个例子中,Retro*-0规划的反应路径长度较短,即更易在实验室中合成。
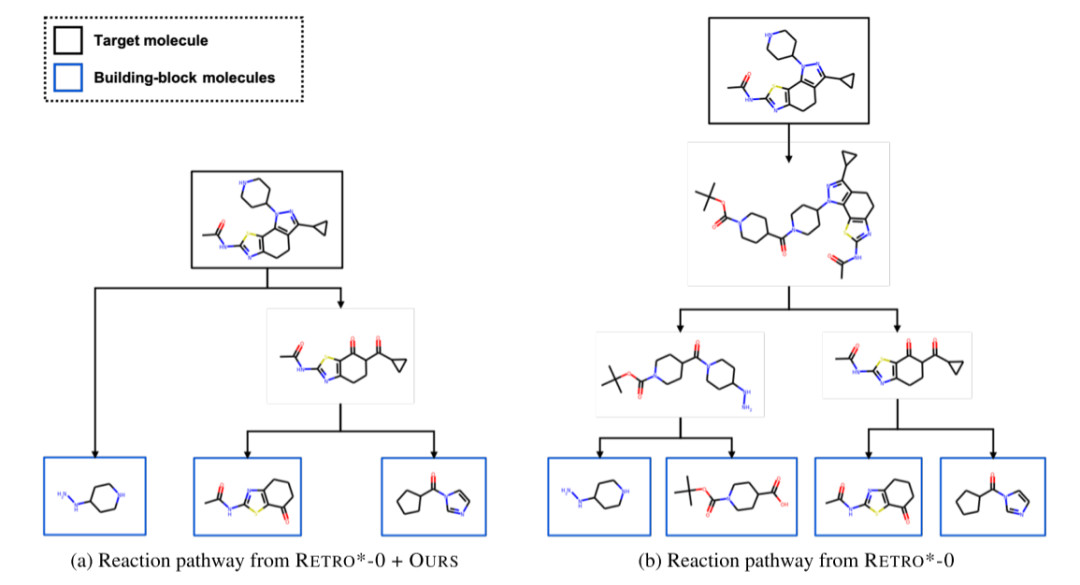
图6 Retro*-0+OURS和Retro*-0示例
4.总结
在这项工作中,作者提出了一个基于自提升模型适应的逆合成规划框架。该框架训练一个逆反应模型用以发现成功的合成路线,另外通过正向反应模型产生新的反应使训练多样化。实验表明,该框架可从构件分子中生成真实且可执行的反应。该工作缩小了有监督的单步逆合成模型与逆向合成规划目标之间的差距。最后,作者表明利用不真实的反应样本改进过滤模块以及开发更好的增强策略将是未来可以关注的研究方向。
参考资料
https://arxiv.org/abs/2106.04880
Retro*代码链接:
https://github.com/binghong-ml/retro_star
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/119363205

- 点赞
- 收藏
- 关注作者
评论(0)