Nat.Commun.|使用基于注意力机制的多标签神经网络预测并解释12种RNA修饰

编译 | 周珍冉
审稿 | 杨慧丹

今天介绍来自西交利物浦大学和福建医科大学的Zitao Song, Daiyun Huang等人六月份发表在Nature Communication的文章“Attention-based multi-label neural networks for integrated prediction and interpretation of twelve widely occurring RNA modifications”。文中提出了一种建立在基于注意力机制的多标签深度学习框架上的方法——MultiRM,它不仅可以同时预测12种广泛发生的RNA修饰的假定位点,而且还可以返回对阳性预测贡献最大的关键序列上下文。该模型从相关序列上下文的角度揭示了不同类型的RNA修饰之间的强关联,能够综合分析并理解基于序列的RNA修饰机制。
简介
RNA转录后修饰增加了RNA分子的结构和功能多样性,调节了RNA生命的所有阶段。因此,准确识别出 RNA 修饰位点对于理解各种 RNA 的功能和调控机制至关重要。目前已经有许多计算方法根据初级 RNA 序列对 RNA 修饰位点进行计算预测,极大地提高了我们在不同条件下对不同物种多种 RNA 修饰类型的定位的理解。然而,当前大多数方法存在以下问题:
仅关注单一的RNA修饰类型,对不同RNA修饰机制之间的相互作用的研究有限。
仅依赖单一来源的有限数据,没有充分利用可用的表观转录组(epi-transcriptome)信息。
仅专注预测的准确性,却没有对其预测结果提供清晰直观的解释。
目前仍没有为一些RNA修饰类型(如m6AM)开发预测框架。
基于上述问题,作者通过集成多种技术生成的数据集来支持多种RNA修饰,开发了统一的预测框架MultiRM。MultiRM,是一种基于注意力机制的多标签神经网络方法,根据初级RNA序列(或相应DNA序列)对RNA修饰进行集成预测和解释。模型支持12种RNA修饰类型,包括m6A, m1A, m5C, m5U, m6Am, m7G, Ψ, I, Am, Cm, Gm, 和 Um。模型的多标签结构能够在充分利用不同RNA修饰的独特特征的同时适应它们的共享结构。为了解决多标签学习中训练数据不平衡的问题,采用了OHEM (online hard examples mining)和不确定加权(Uncertain Weighting)方法。使用当前最先进的机器学习算法XGBoost 和 CatBoost 作为基准。使用积分梯度 (IG) 和注意力权重(attention weights)来深入了解训练后的整体模型并解释每个单独的预测。最后,作者开发了可以免费访问的web服务器。
结果
MultiRM框架
给定一组基本分辨率修饰位点,MultiRM框架学习位点序列上下文和修饰类型之间的映射。一旦学会这种映射,注意力机制和IG方法使得MultiRM可以解释模型,并且提取对阳性预测贡献最大的序列上下文,即序列模体(sequence motif)。集成模型采用的多标签框架也有助于学习不同RNA修饰之间的潜在关联。
如图1,MultiRM由一个嵌入模块和一个LTSM-Attention模块组成,用于提取和学习有用的特征。然后,通过注意力过滤的特征被输入到多标签模块中,以同时预测 RNA 修饰。嵌入模块使用核苷酸之间固有的短长相互作用来表示输入RNA序列,接着嵌入表示被提供给LTSM层,提取所有修饰共享的底层序列特征。然后注意力机制根据需求每种特定修饰类型的输入RNA序列的相关区域。最后,包含两个全连接层(FC)的多标签模块同时预测多个修饰位点。框架使用OHEM和不确定性加权法增强的交叉熵损失(cross-entropy loss)进行训练。
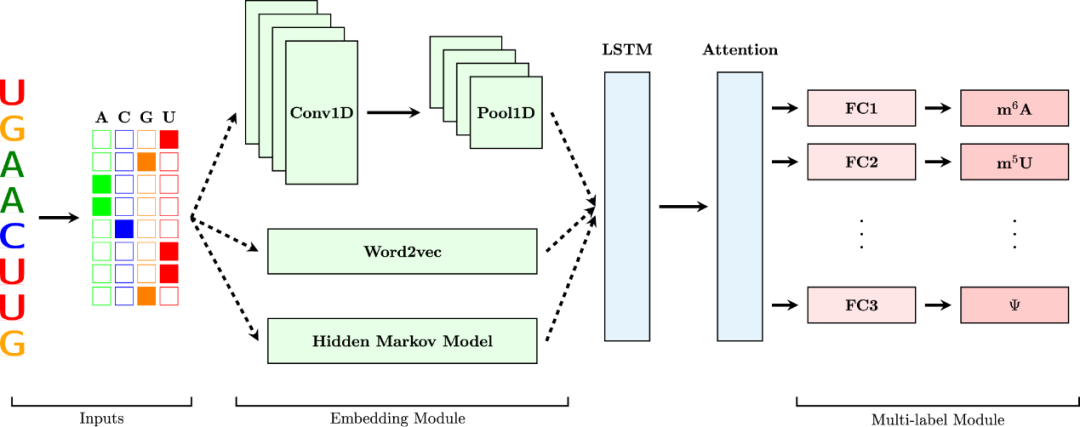
图1. MultiRM模型体系结构
MultiRM性能分析
本文研究目的主要是建立一种可解释的预测因子,能够在识别初级RNA序列中广泛出现的多种RNA修饰方面达到最优的准确性。
作者首先尝试根据AUCb来优化输入序列的长度,使用Word2vec embedding,以21-bp、51-bp和101-bp的RNA序列作为输入来评估多标签模型。结果如表1,其中51-bp的平均性能最优。

表1. 不同输入长度下模型(w2v + LSTM +attention)的AUCb得分
接着,为解决训练数据不平衡的问题,使用了OHEM和不确定性加权来优化模型,以51-bp的输入序列评估性能。作者将MultiRM和基准方法以及其他embedding技术进行了比较,结果如表2。其中MultiRM模型的平均值和中值得分最高,并且有6种RNA修饰性能最佳。

表2. MultiRM 与基准方法和其他嵌入技术的比较AUCb得分
MultiRM解释
为了深入了解预测背后的驱动特征,作者使用注意力权重和IG直观地解释模型是如何做出特定决策的。即在做出不同预测时,重点关注模型最看重的东西,并在通过注意力权重和IG进行阳性预测时获得贡献最大的核苷酸。
汇总在模型中发挥关键作用的共有模体时,作者发现它们中有许多与传统模体发现方法DREME和STREME解释的序列模式相匹配。因此,应用模体比较工具TOMTOM生成p值来量化通过MultiRM 和 DREME/STREME 获得的模体之间的相似性,如图2。
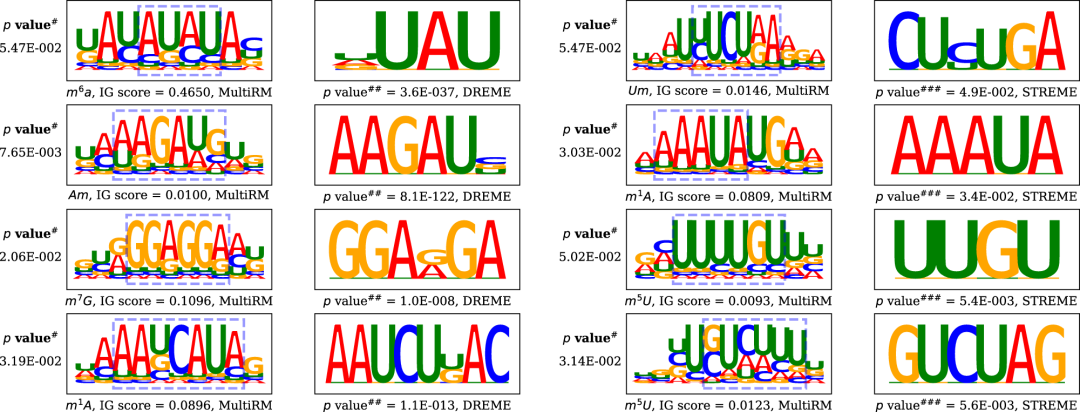
图2.模体匹配
为了更好地理解不同RNA修饰之间固有的共享结构,作者提取了注意力机制中前馈神经网络的权重。这些权重分别为对应于12个RNA修饰的12个向量,并与模型的其他所有成分共同学习。通过计算每对向量的皮尔逊相关系数(ρ)来表示任意两种RNA修饰的相关性。如图3,RNA修饰之间都显示出强烈且显著的正相关,甚至包括那些来自不同核苷酸的修饰。这表明存在被多个RNA修饰密集修饰的区域,这些区域可能是基因调控的表观转录组层的关键调控成分。这些关键调控区域的序列特征很大程度上在不同的 RNA 修饰之间共享,并被模型成功捕获。值得注意的是,上述分析没有考虑RNA修饰的上下文特异性。
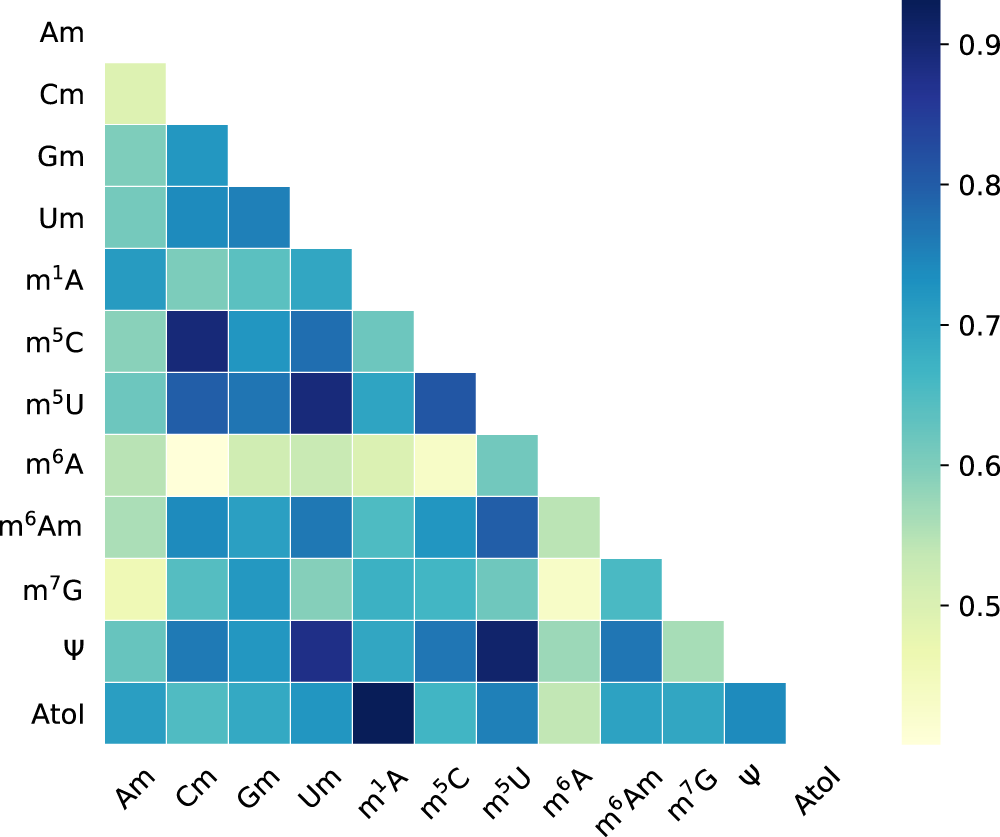
图3. MultiRM揭示了RNA修饰的关联
结论
为了充分利用序列的内在结构,作者试验了三种不同的嵌入式技术,发现Word2vec 大大增强了预测能力。此外,作者还发现输入更长的 RNA 序列可能不一定会导致更高的预测准确性,因此采用了 OHEM 和不确定性权重策略处理不平衡问题。为确保预测的可靠性和稳健性,作者仅使用了从多个正交技术和多项研究生成的高质量表观转录组谱作为训练和测试数据。
MultiRM模型首次揭示了12种RNA修饰之间在序列偏好方面的正相关。作者认为,研究一般 RNA 修饰和表观转录组调控的关键调控区域应该受到重视。同样,它们在不同生物条件下的动态串音也值得关注,这就要求当这些数据更丰富时,对特定条件下的表观转录组谱进行集成预测。由于受限于当前技术,尽管MultiRM 能够预测 12 种不同类型的 RNA 修饰,但目前仅限于人类,而且模型并没有考虑不同 RNA 修饰的不同丰度。
参考资料
Song, Z., Huang, D., Song, B. et al. Attention-based multi-label neural networks for integrated prediction and interpretation of twelve widely occurring RNA modifications. Nat Commun 12, 4011 (2021).
https://doi.org/10.1038/s41467-021-24313-3
文章来源: drugai.blog.csdn.net,作者:DrugAI,版权归原作者所有,如需转载,请联系作者。
原文链接:drugai.blog.csdn.net/article/details/119363394

- 点赞
- 收藏
- 关注作者
评论(0)