Java集合类王者笔记上(含面试重点)

一、数据结构
数据结构就是计算机存储、组织数据的方式。
在计算机科学中,算法的时间复杂度是一个函数,它定性描述了该算法的运行时间,常用O符号来表述。
时间复杂度是同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在于选择合适算法和改进算法
1.1、线性结构
1.1.1、数组
我们对数组的CRUD操作进行性能分析
添加操作
如果保存在数组的最后一个位置,至少需要一次操作
如果保存的位置在数组的第一个位置,那么如果存在N个元素,那么此时后面的元素需要整体后移,此时需要操作N次
那么平均就是(N+1)/2次,如果需要扩容,那么性能会更低
删除操作
如果删除的是最后一个元素,那么需要操作一次
如果操作的是第一个元素,那么其他元素需要整体前移,需要操作N次
平均就是(N+1)/2次
修改操作
给定索引时,仅仅只是操作一次
查询操作
根据索引操作1次,如果根据内存查询的话需要操作N次
总结·
基于数组的数据结构做查询和修改事宜非常快的(性能很高),如果做删除和增加就比较慢了,那如果想保证保存和删除操作的性能,此时就得提链表这种数据结构了
1.1.2、链表
链表(类似火车和火车车厢)是由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
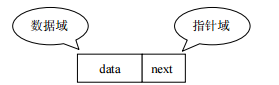
我们常说的链表结构有单向链表与双向链表分为两种:
-
单向链表:只能从头到尾(从尾到头)遍历
-
双向链表:既可以从头到尾又可以从尾到头遍历
对链表操作的性能分析
增加操作
仅仅只是操作1次,断掉链和新增链
删除操作
仅仅只是操作1次
修改操作
如果修改的是第一个元素,那么需要操作1次,如果需要修改的是最后一个元素,那么需要操作N次,所以平均(N+1)/2
查询操作
如果查询的是第一个元素,那么需要操作1次,如果需要查询的是最后一个元素,那么需要操作N次,所以平均(N+1)/2
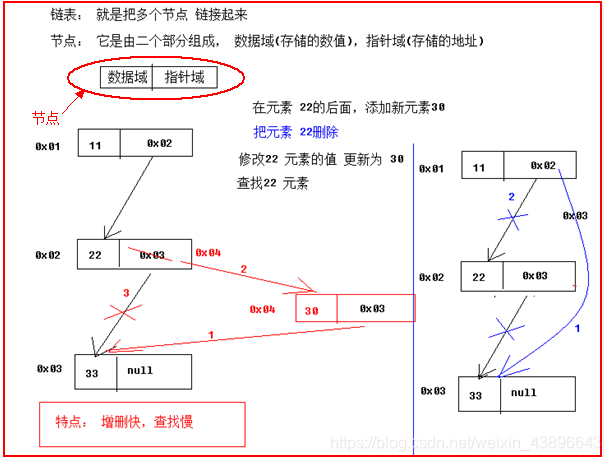
结论
链表的查询和修改性能比较低,而增加和删除性能高
1.1.3、队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,队列是一种操作受限制的线性表。
进行插入操作的端称为队尾,进行删除操作的端称为队头,单向队列是先进先出的,只能从队尾插入元素,从对头删除元素
单项队列

双向队列

1.1.4、栈
栈(stack)又名堆栈,它是一种运算受限的线性表,后进先出(LIFO),和水瓶类似,先装进去的水最后才可以喝到。
栈结构仅允许在表的一端进行插入和删除运算,这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈中插入新元素又称作入栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素。从一个栈中删除元素又称作出栈,表示把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
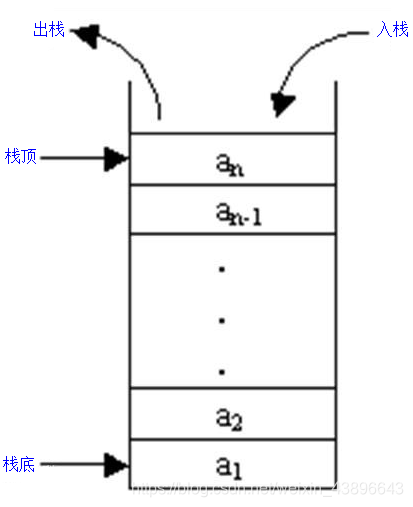
- 压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
- 弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
1.2、非线性结构
1.2.1、哈希表
数组中的元素在数组中的索引位置是随机的,元素的取值和元素的位置之间没有确定的关系,因此在数组中查找特定的值时,需要将特定的值和整个数组元素进行一个个比较。
此时查询的效率依赖于比较的次数,如果比较的次数比较多,那么此时查询的效率还是不高。
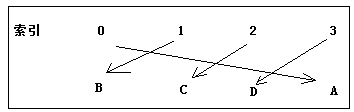
如果此时元素的值(value)和在数组中的索引位置(index)有一个确定的对应关系,我们将这种关系称之为哈希(hash),则元素值和索引之间对应的公式为:index = hash(value),也就是说给定元素值,只要调用了hash(value)方法,就能找到数组中取值value的元素的位置
比方说图中的hash的算法公式为:index = value/10-1,在哈希表中存储对象时,该hash算法就是对象的hashCode方法(真正的hash算法并不是这样,只是打个比方,真实的hash算法我们大可不必去关心)
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用数组处理冲突,同一hash值的链表都存储在一个数组里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间**。简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。**
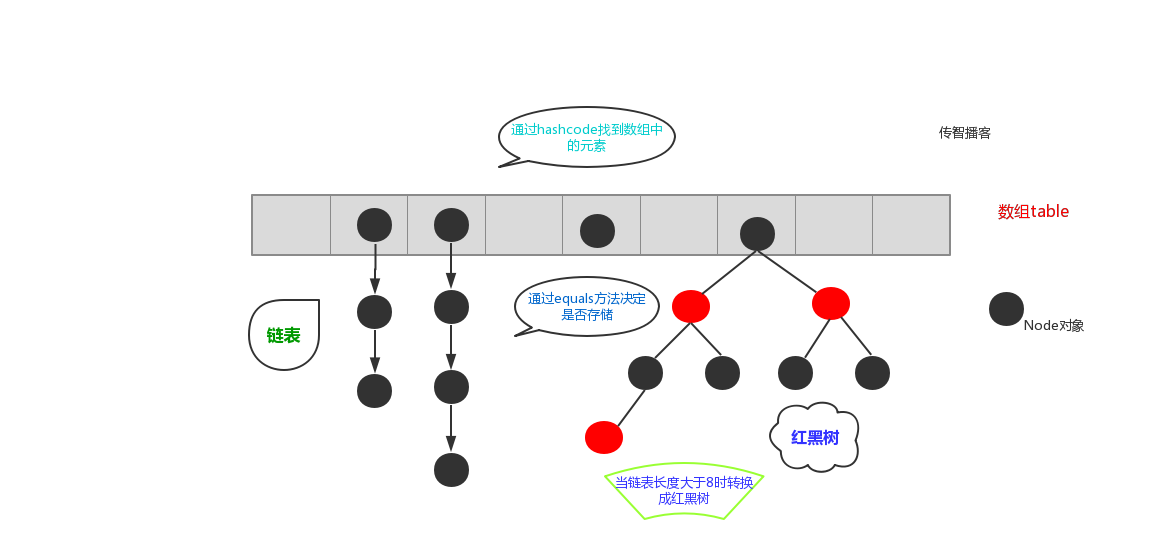
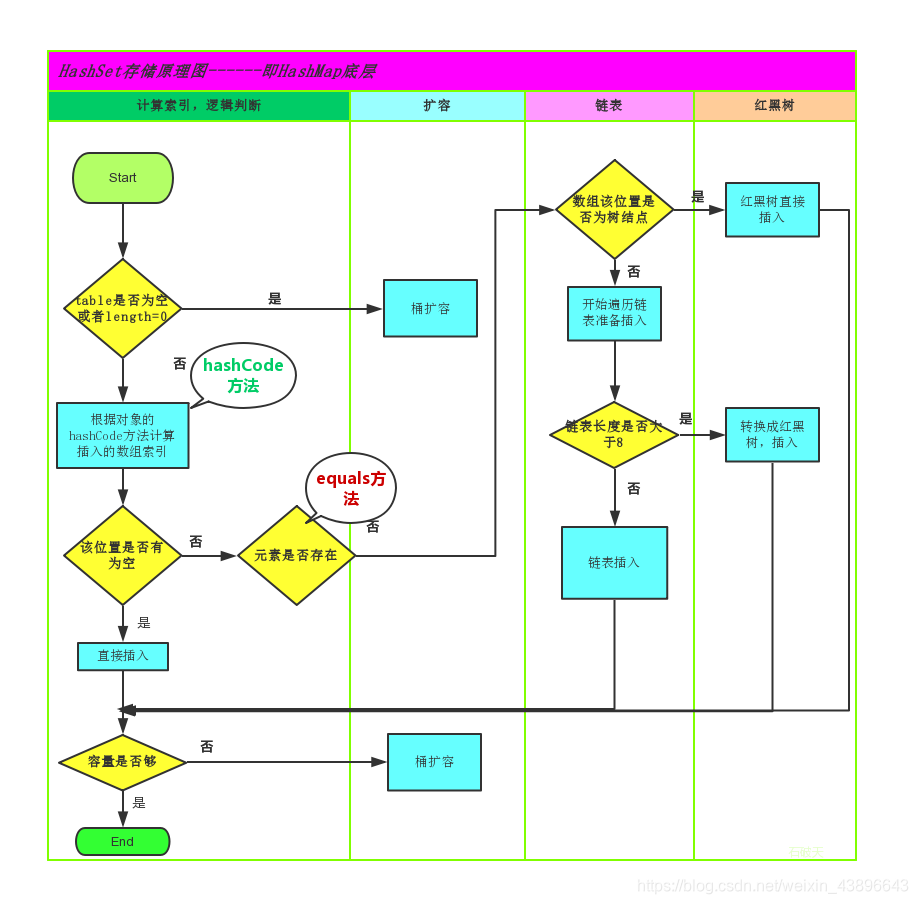
他的存储原理如下图,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
1.2.2、树和二叉树
1.2.2.1、树
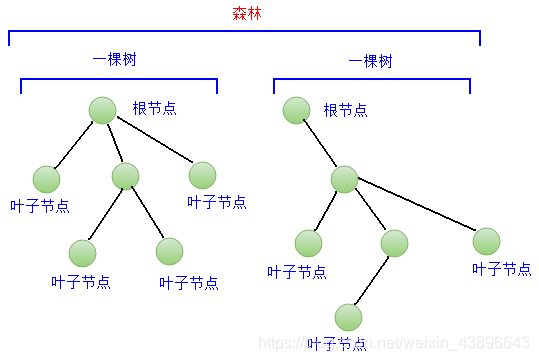
计算机中的树,是根据生活中的树抽象而来的,表示N个有父子关系的节点的集合。
-
N为0的时候,该节点集合为空,这棵树就是空树
-
任何非空树中,有且只有一个根节点(root)
-
N>1时,一颗树由根和若干棵子树组成,每棵子树由更小的若干子树组成
-
树中的节点根据有没有子节点,分成两种:
- 普通节点:拥有子节点的节点。
- 叶子节点:没有字节点的节点。
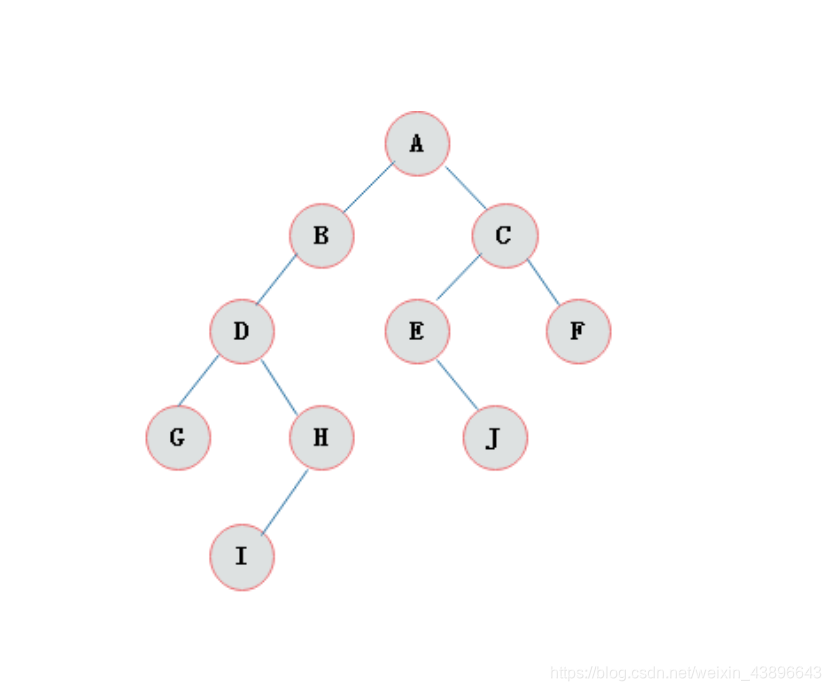
| 名词 | 含义 |
|---|---|
| 节点 | 指树中的一个元素 |
| 节点的度 | 节点拥有的子树的个数,二叉树的度不大于2 |
| 叶子节点 | 度为0的节点,也称之为终端结点 |
| 高度 | 叶子结点的高度为1,叶子结点的父节点高度为2,以此类推,根节点的高度最高 |
| 层 | 根节点在第一层,以此类推 |
| 父节点 | 若一个节点含有子节点,则这个节点称之为其子节点的父节点 |
| 子节点 | 子节点是父节点的下一层节点 |
| 兄弟节点 | 拥有共同父节点的节点互称为兄弟节点 |
1.2.2.2、二叉树
树的结构因为存在多种子节点情况,真的太复杂了,如果我们对普通的树加上一些约束,比如让每一棵树的节点最多只能包含两个子节点,而且严格区分左子节点和右子节点(左右位置不能交换),此时就形成了二叉树。
1.2.2.3、排序二叉树
排序二叉树是一颗有顺序的数,满足以下三个条件:
- 若左子树不为空,则左子树所有节点的值小于根节点的值。
- 若右子树不为空,则右子树所有节点的值大于根节点的值。
- 左右子树也分别是排序二叉树
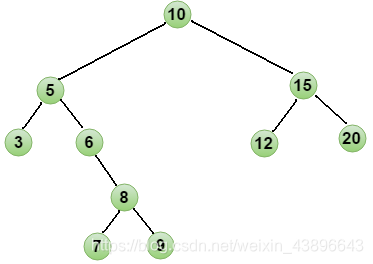
增删改查的性能都很高遍历获取元素的时候可以按照"左中右"的顺序进行遍历;
注意:二叉查找树存在的问题:会出现"瘸子"的现象,影响查询效率。因此此时相当于链表,比如12345678排成一棵树就变成了链表
1.2.2.4、平衡二叉树
为了避免出现"瘸子"的现象,减少树的高度,提高我们的搜素效率,又存在一种树的结构:“平衡二叉树”
规则:它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
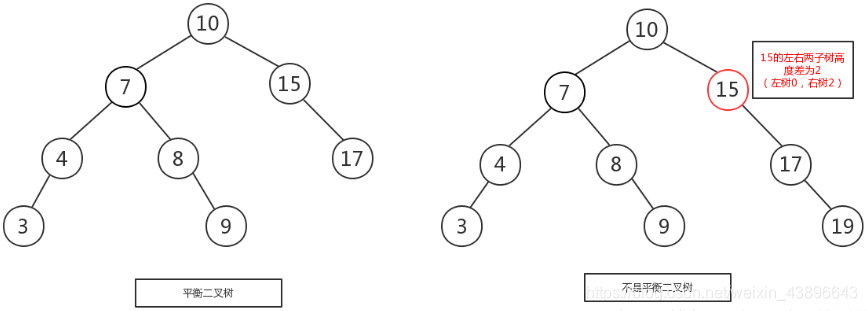
左图是一棵平衡二叉树,根节点10,左右两子树的高度差是1,而右图,虽然根节点左右两子树高度差是0,但是右子树15的左右子树高度差为2,不符合定义,所以右图不是一棵平衡二叉树。
变成平衡二叉树的办法就是那边高就往他的反方向旋转。
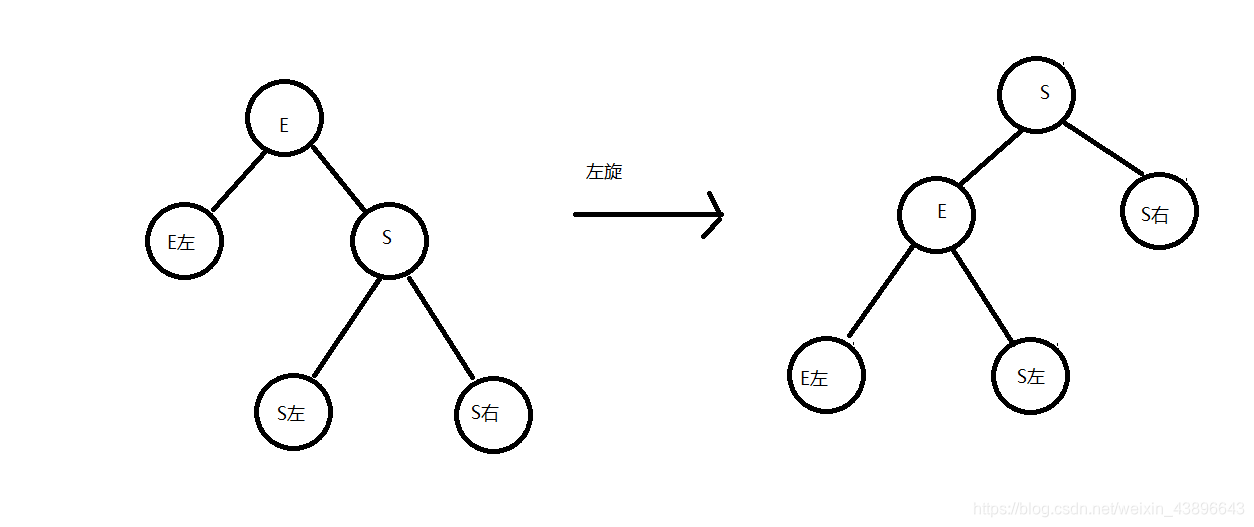
1.2.2.4.1、左旋
左旋就是将节点的右支往左拉,右子节点变成父节点,并把晋升之后多余的左子节点出让给降级节点的右子节点;
1.2.2.4.2、右旋
将节点的左支往右拉,左子节点变成了父节点,并把晋升之后多余的右子节点出让给降级节点的左子节点
举个例子,像上图是否平衡二叉树的图里面,左图在没插入前"19"节点前,该树还是平衡二叉树,但是在插入"19"后,导致了"15"的左右子树失去了"平衡",
所以此时可以将"15"节点进行左旋,让"15"自身把节点出让给"17"作为"17"的左树,使得"17"节点左右子树平衡,而"15"节点没有子树,左右也平衡了。如下图:
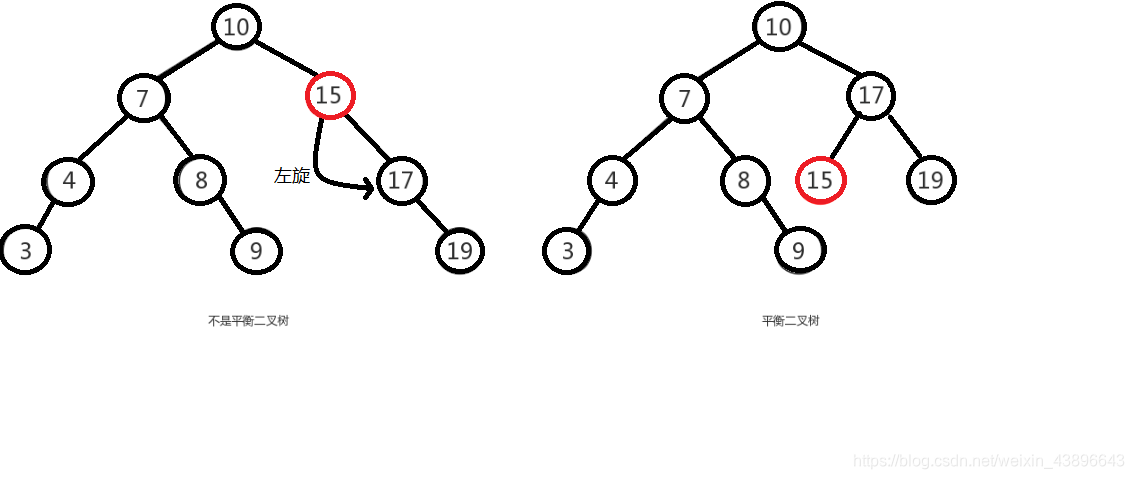
由于在构建平衡二叉树的时候,当有新节点插入时,都会判断插入后时候平衡,这说明了插入新节点前,都是平衡的,也即高度差绝对值不会超过1。
当新节点插入后,有可能会有导致树不平衡,这时候就需要进行调整,而可能出现的情况就有4种,分别称作左左,左右,右左,右右。
1.2.2.4.3、左左
左左即为在原来平衡的二叉树上,在节点的左子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"10"节点的左子树"7",的左子树"4",插入了节点"5"或"3"导致失衡。
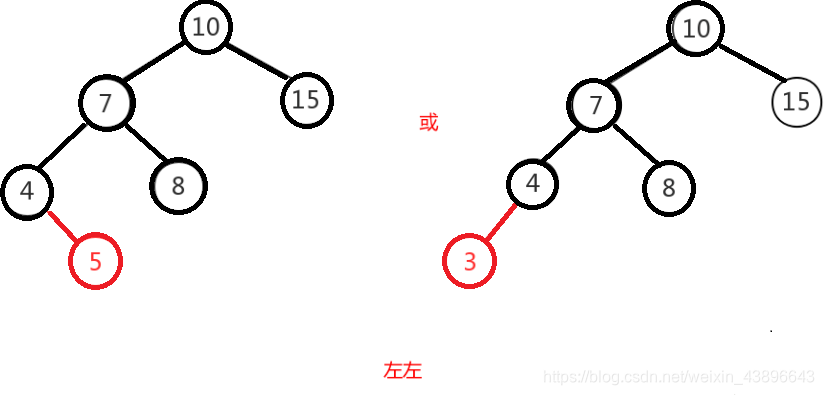
1.2.2.4.4、左右
左右即为在原来平衡的二叉树上,在节点的左子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的左子树"7",的右子树"9",插入了节点"10"或"8"导致失衡。
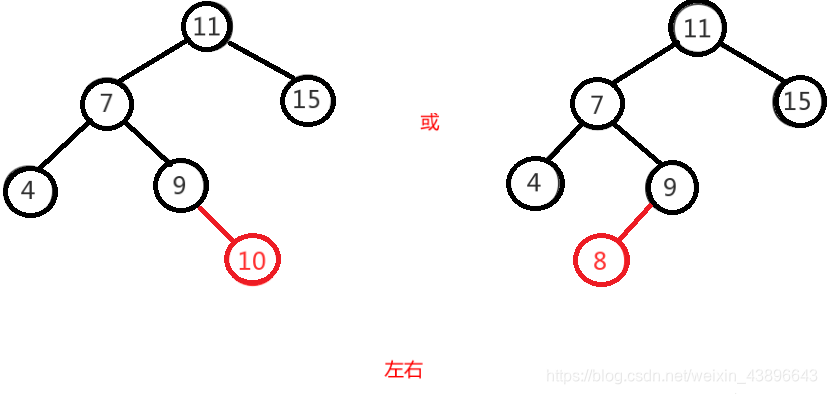
1.2.2.4.5、右左
右左即为在原来平衡的二叉树上,在节点的右子树的左子树下,有新节点插入,导致节点的左右子树的高度差为2,如上即为"11"节点的右子树"15",的左子树"13",插入了节点"12"或"14"导致失衡。
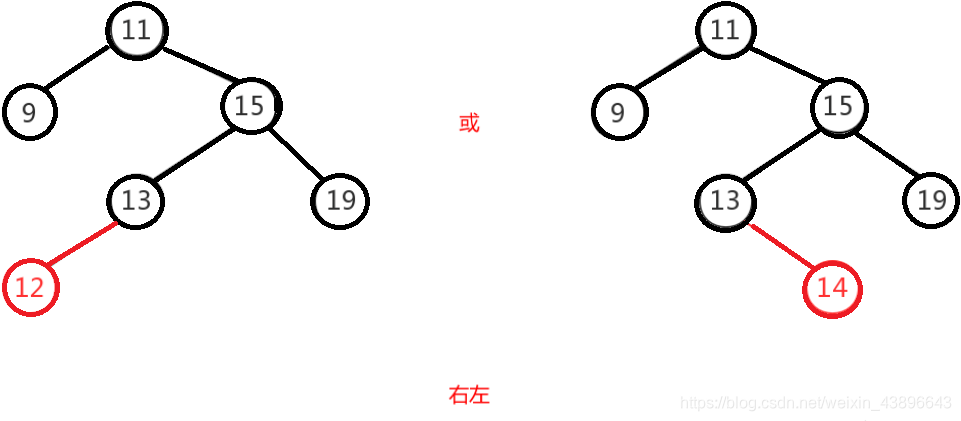
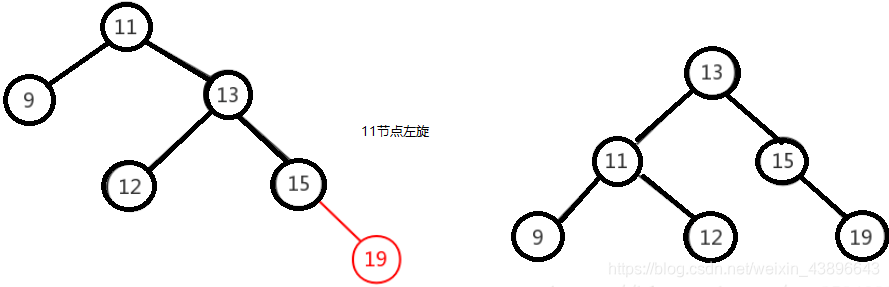
1.2.2.4.6、右右
右右即为在原来平衡的二叉树上,在节点的右子树的右子树下,有新节点插入,导致节点的左右子树的高度差为2,如下即为"11"节点的右子树"13",的左子树"15",插入了节点"14"或"19"导致失衡。
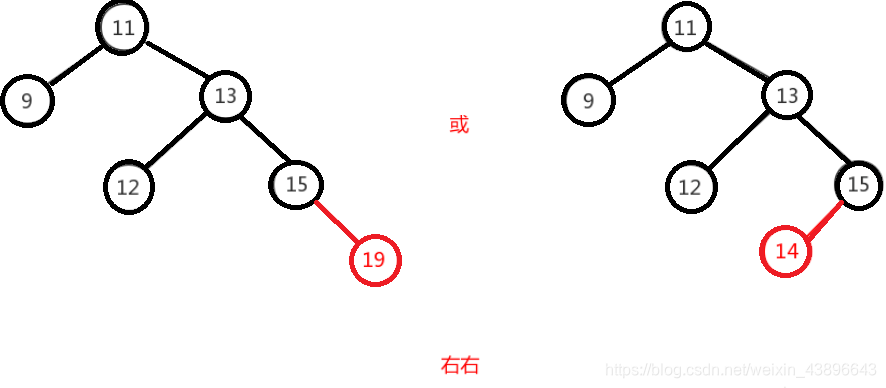
右右只需对节点进行一次左旋即可调整平衡,如下图,对"11"节点进行左旋。
1.2.2.5、红黑树
红黑树本质上是一颗具有更高查询效率的排序二叉树。
排序二叉树可以快速查找,但是如果只有左节点或者左右右节点的时候,此时二叉树就变成了普通
的链表结构,查询效率比较低。为此一种更高效的二叉树出现了——红黑树,满足以下几个条件:
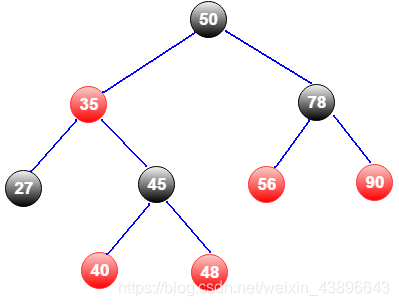
- 每个节点要么是红色的,要么是黑色的。
- 根节点永远是黑色的。
- 所有叶子节点都是空节点(null),是黑色的。
- 每个红色节点的两个子节点都是黑色的。
- 从任何一个节点到其子树每个叶子节点的路径都包含相同数量的黑色节点。
二、Collection集合
集合是Java中提供的一种容器,可以用来存储多个数据
数组相比于集合来说缺点很明显:
- 数组的长度是固定的,而集合的长度是可变的
- 使用Java类封装出一个个容器类,开发者只需要直接调用即可,不必再手动创建容器类
- 数组的API操作难度远远大于集合,集合更加灵活和适合开发
2.1、集合框架概述
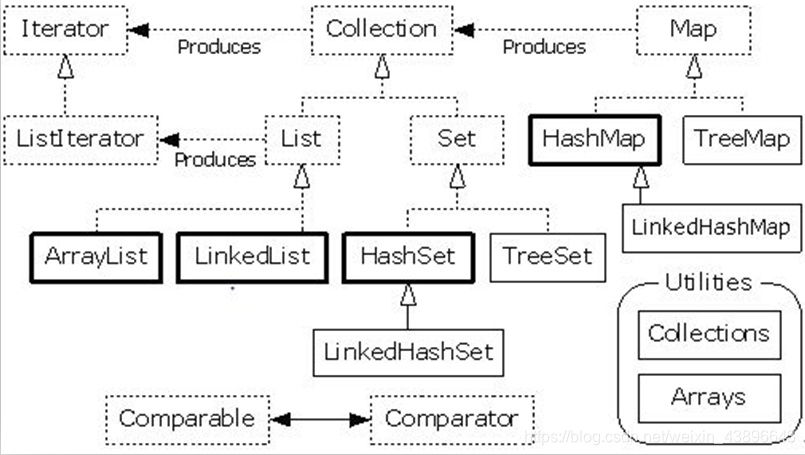
集合是Java中提供的一种容器,可以用来存储多个数据,根据不同存储方式形成的体系结构,就叫做集合框架体系。集合也时常被称为容器,且集合中存储的数据叫做元素,而元素只可以是对象
2.2、集合的分类
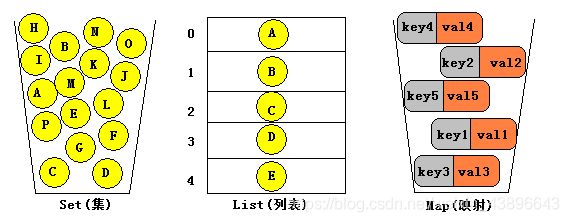
根据容器的存储特点的不同,可以分成三种情况:
| 集合 | 描述 |
|---|---|
| List(列表) | 允许记录添加顺序,允许元素重复(有序可重复) |
| Set(集合) | 不记录元素添加的顺序,不允许元素重复(无序且唯一) |
| Map(映射) | 容器中每一个元素都包含一对key和value,key不允许重复,value可以重复 |
我们查看源码可以看到集合的继承关系:List和Set继承与Collection接口,而Map不继承Collection接口, 容器接口或类都处于java.util包中
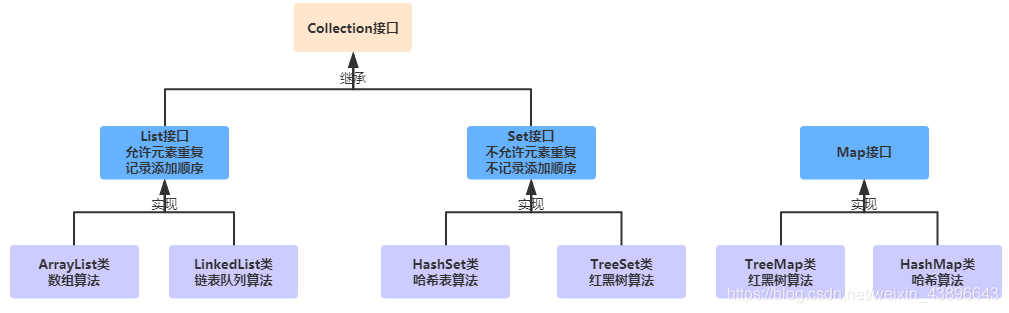
| 接口 | 描述 |
|---|---|
| Collection接口 | 泛指广义上的集合,主要表示List和Set两种存储方式 |
| List接口 | 表示列表,有序可重复 |
| Set接口 | 表示狭义上的集合,无序不可重复 |
| Map接口 | 表示映射关系 |
三、List接口
List接口是Collection接口子接口,List接口定义了一种规范,要求该容器允许记录元素的添加顺序,也允许元素重复。那么List接口的实现类都会遵循这一种规范。
List集合存储的特点:
- 允许元素重复
- 允许记录元素的添加先后顺序
该接口常用的实现类有:
- ArrayList:数组列表,表示数组结构,采用数组实现,用的最多
- LinkedList类:链表,表示双向列表和双向队列结构,采用链表实现
- Stack类:栈,表示栈结构,采用数组实现
- Vector类:向量,其实就是古老的ArrayList,采用数组实现
3.1、List常用API
3.1.1、添加操作
- boolean add(Object e):将元素添加到列表的末尾
- void add(int index, Object element):在列表的指定位置插入指定的元素
- boolean addAll(Collection c):把c列表中的所有元素添加到当前列表中
3.1.2、删除操作
- Object remove(int index):从列表中删除指定索引位置的元素,并返回被删除的元素
- boolean removeAll(Collection c):从此列表中移除c列表中的所有元素
3.1.3、修改操作
Object set(int index, Object ele):修改列表中指定索引位置的元素,返回被替换的旧元素
3.1.4、查询操作
- int size():返回当前列表中元素个数
- boolean isEmpty():判断当前列表中元素个数是否为0
- Object get(int index):查询列表中指定索引位置对应的元素
- Object[] toArray():把列表对象转换为Object数组
- boolean contains(Object o):判断列表是否存在指定对象
四、ArrayList类
ArrayList类,基于数组算法的列表,通过查看源代码会发现底层其实就是一个Object数组
ArrayList是一个List接口的实现类,实现了可变数组,当添加一个元素时,如果容量足够,直接添加,如果容量不够,按照newCapacity = oldCapacity + oldCapacity/2 原则拓容
由于ArrayList底层数据结构是数组,决定了该实现类在查询的场景下比较适用,添加和删除的场景效率稍低
public class ArrayListDemo1 {
/**
ArrayList的常用API
**/
public static void main(String[] args) {
//创建一个默认长度的列表对象
List list = new ArrayList();
//打印集合中元素的个数
System.out.println("元素数量:"+list.size());//0
//添加操作:向列表中添加4个元素
list.add("Will");
list.add(100);
list.add(true);
list.add("Lucy");
//查询操作:
System.out.println("列表中所有元素:"+list);//输出:[Will, 100, true, Lucy]
System.out.println("元素数量:"+list.size());//4
System.out.println("第一个元素:"+list.get(0));//Will
//修改操作:把索引为2的元素,替换为wolfcode
list.set(2, "wolfcode");
System.out.println("修改后:"+list);//输出:[Will, 100, wolfcode, Lucy]
//删除操作:删除索引为1的元素
list.remove(1);
System.out.println("删除后:"+list);//输出:[Will, wolfcode, Lucy]
}
}
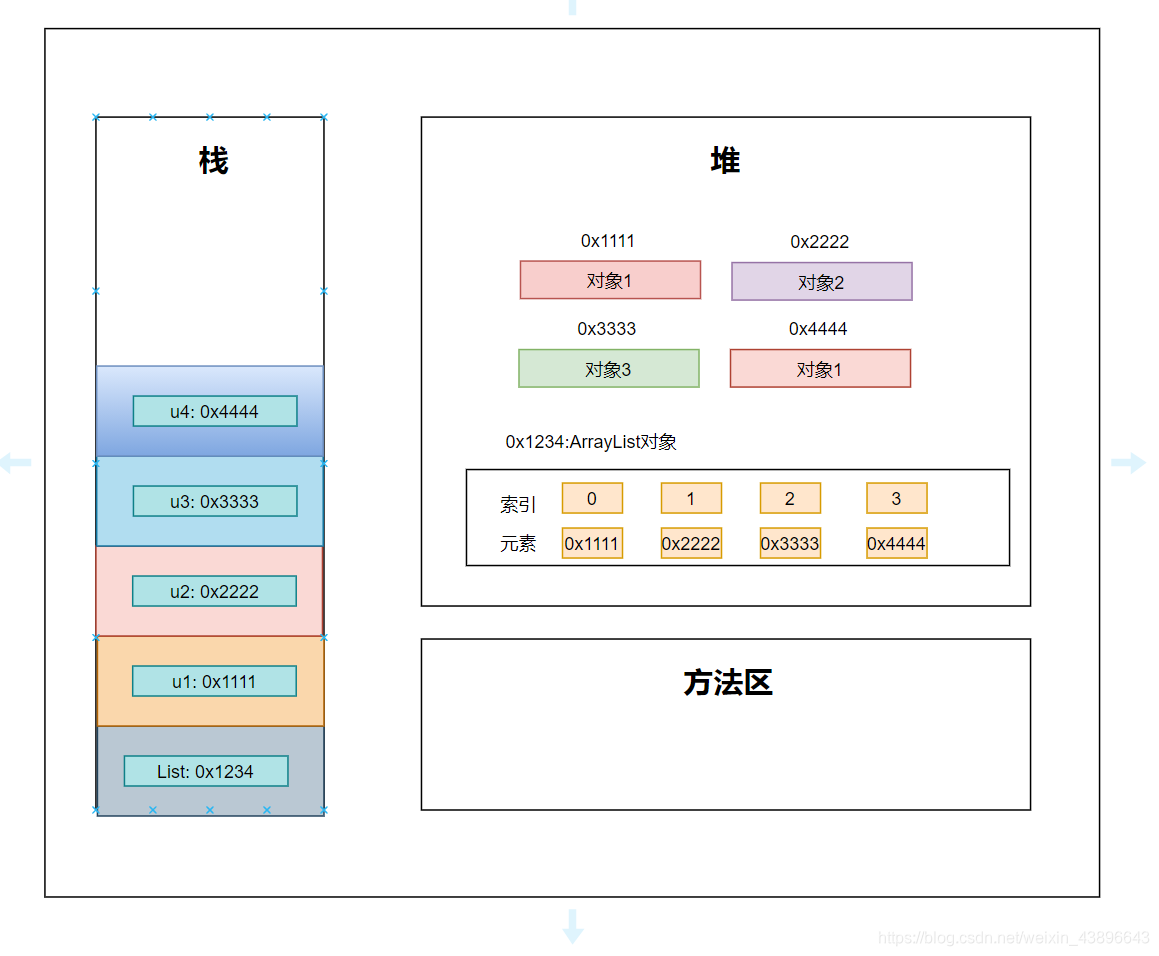
我们画出ArrayList的内存图可以发现集合类中存储的对象,都存储的是对象的引用,而不是对象本身
五、LinkedList类
LinkedList由于底层数据结构是链表,在添加元素和删除元素时效率很高,查询元素效率低。
LinkedList类,底层采用链表算法,实现了链表,队列,栈的数据结构。无论是链表还是队列主要操作的都是头和尾的元素,因此在LinkedList类中除了List接口的方法,还有很多操作头尾的方法。常用的方法如下:
//将指定元素插入此列表的开头。
void addFirst(Object e);
//将指定元素添加到此列表的结尾。
void addLast(Object e);
//返回此列表的第一个元素。
Object getFirst();
//返回此列表的最后一个元素。
Object getLast();
//移除并返回此列表的第一个元素。
Object removeFirst();
//移除并返回此列表的最后一个元素。
Object removeLast();
//在此列表的开头插入指定的元素。
boolean offerFirst(Object e);
//在此列表末尾插入指定的元素。
boolean offerLast(Object e);
////获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
Object peekFirst();
////获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
Object peekLast();
////获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
Object pollFirst();
//获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
Object pollLast();
//将元素推入此列表所表示的栈。
void push(Object e);
//从此列表所表示的栈处弹出一个元素。
Object pop();
//获取但不移除此列表的头(第一个元素)。
Object peek()
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList list = new LinkedList();
//添加元素
list.addFirst("A");
list.addFirst("B");
System.out.println(list);
list.addFirst("C");
System.out.println(list);
list.addLast("D");
System.out.println(list);
//获取元素
System.out.println("获取第一个元素:" + list.getFirst());//C
System.out.println("获取最后一个元素:" + list.getLast());//D
//删除元素
list.removeFirst();
System.out.println("删除第一个元素后:" + list);//[B, A, D]
list.removeLast();
System.out.println("删除最后一个元素后:" + list);//[B, A]
}
}
六、Stack和Vector类
Vector类:基于数组算法实现的列表,其实就是ArrayList类的前身。和ArrayList的区别在于方法使用synchronized修饰,所以相对于ArrayList来说,线程安全,但是效率就低了点。
Stack类:表示栈,是Vector类的子类,具有后进先出(LIFO)的特点,拥有push(入栈),pop(出栈)方法

- 点赞
- 收藏
- 关注作者
评论(0)