mysql编码问题——charset=utf8你真的弄明白了吗?【绽放吧!数据库】

导读:以前学习mysql的时候,一直不知道“charset=utf8”是什么意思,更不知道“set names gbk”是什么意思,通过这篇文章将会给大家详细介绍客户端字符集、联接器connection、MySQL server字符集的设置。
1、一个建表语句引出的问题
create table student(
sid int primary key aotu_increment,
sname varchar(20) not null,
age int
)charset=utf8;
思考一个问题:
对于刚刚安装好的MySQL,我们随意写了一个建表语句。当建表时指定charset=utf8的时候,此时,插入中文为什么又可以插入中文,并且不乱码呢?当我们建表时,不指定 charset=utf8的时候,此时,插入中文,为什么会报错呢?
2、查看当前电脑使用的字符集
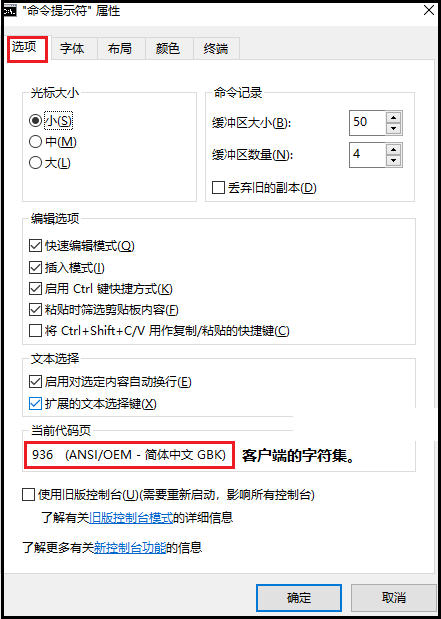
打开电脑黑窗口(CMD),接着点击鼠标右键,然后选择属性,并查看“选项”这一栏。通过上图可以知道:CMD中输入文字使用的字符编码是GBK。
3、你发现这个问题了吗?
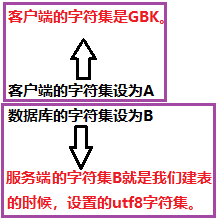
问题如下:
客户端client输入的字符,都是采用GBK编码的。mysql服务器存储的字符又是UTF8编码的。
那么,我们向数据库中插入数据,从数据库中查找数据,返回到界面中,要想保证字符不乱码,肯定是经过了"编码转换过程的"。我要问的是,究竟是什么东西完成了这个编码的转换过程的?
4、你不熟悉的几个命令
-- 查看数据库支持的所有的字符集(这句命令自己下去操作)。
mysql> show character set;
-- 查看系统当前状态,里面可以看到部分字符集设置。
mysql> status;
-- 查看系统字符集设置,包括所有的字符集设置
mysql> show variables like '%char%';
操作结果如下:
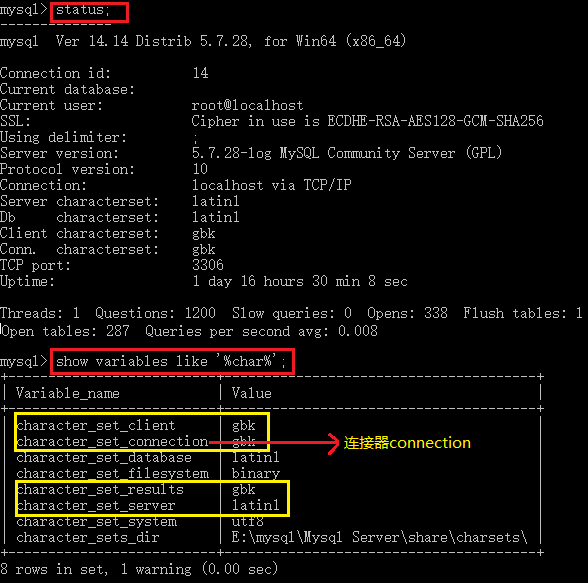
通过上图我们可以看到有一个东西,叫做"connection",中文名叫做"连接器"。"连接器"就是3中那个问题,我们想要知道的答案。也就是说:这个转换过程依赖的就是这个connection。
1)连接器connection的作用与工作流程(文字叙述)
① 连接器的作用
连接客户端与服务端,进行字符集的转换。连接器有这种自动转换的功能。
② 连接器的工作流程
Ⅰ 客户端的字符先发给连接器,连接器选择一种编码将其转换(转换之后的编码,与连接器的编码格式一致),进行临时存储。
Ⅱ 接着,连接器再次转换成服务器需要的编码,并最终存储在服务器中。
Ⅲ 然后,服务器返回的结果,再次先通过连接器,连接器将其转化为与客户端一致的字符集,就可以在客户端正常显示了。
2)图示法讲解connection的作用与工作流程
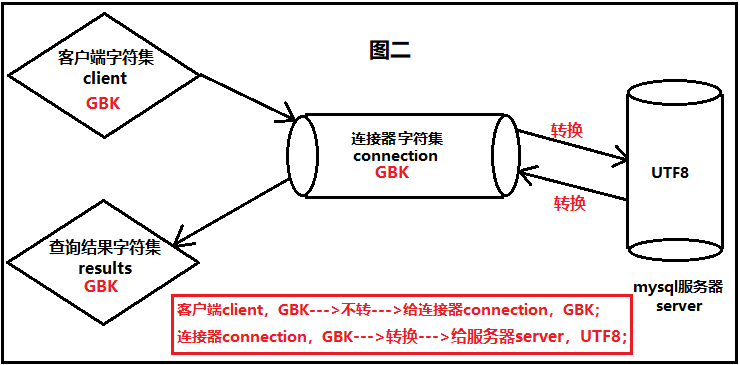
① 第一种方式

图示说明:
我们已经知道:在CMD窗口中输入的字符,采用的字符集是GBK,也就是说客户端(client)的字符集是GBK。而写入到数据库中数据采用什么格式写入,我们在建表的时候已经指明了"charset=utf8",也就是说,mysql服务器(server)的字符集是UTF8。此时,假如说连接器(connection)的字符集是UTF8,这个写入数据库的过程是怎么进行的呢,下面我们进行文字说明。
首先,在客户端输入的字符,使用的字符集是GBK。当经过连接器的时候,连接器会进行"字符集的自动转换",将原来的子符(以GBK进行编码)转换为以UTF8格式的编码字符,临时存储在连接器中。
接着,连接器发现mysql服务器使用的字符集,与自身字符集完全一致,都是UTF8。于是,直接发给mysql服务器,进行最终的存储。
“当我们从mysql服务器查数据的时候,返回过程又是怎么进行的呢?”
首先 ,mysql服务器会将结果以UTF8编码格式进行返回,通过连接器的时候,连接器发现mysql服务器的字符集,与自身字符集一致,于是顺利通过连接器。当连接器准备将结果发送给客户端的时候,发现客户端要求返回的字符集是GBK。因此,连接器会进行"字符集的自动转换",将返回的结果(以UTF8进行编码)转换为以GBK格式的编码,进行显示,并最终发送给客户端,显示在CMD窗口中。
② 第二种方式
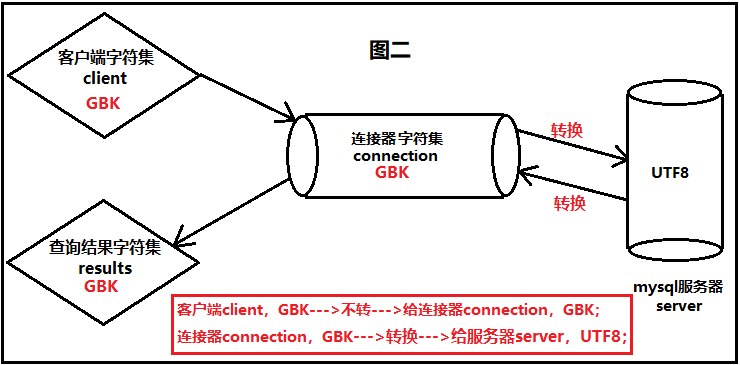
假如说连接器(connection)的字符集是GBk,这个过程又该是怎么进行的呢,下面我们仍然进行文字说明。
首先,在客户端输入的字符,使用的字符集是GBK。当经过连接器的时候,连接器发现客户端发送过来的字符的字符集,与自身字符集相同,因此顺利通过了连接器。
接着,当字符通过连接器发送给mysql服务器进行存储的时候,发现mysql服务器的字符集是UTF8,与自身的字符集GBK并不一致。因此,连接器此时又会进行"字符集的自动转换",将该字符(以GBK进行编码)转换为以UTF8格式的编码,进行显示,转换完成以后,再次发送给mysql服务器,进行最终的存储。
“当我们从mysql服务器查数据的时候,返回过程又是怎么进行的呢?”
首先 ,mysql服务器会将结果以UTF8编码格式进行返回,通过连接器的时候,连接器发现mysql服务器的字符集,与自身的字符集并不一致,于是连接器会进行"字符集的自动转换",将返回的结果(以UTF8进行编码)转换为以GBK格式的编码,进行显示。接着连接器又将转换后的结果,准备发送给客户端,此时发现客户端的字符集,与自身的字符集一致。因此直接发送给客户端,成功在CMD窗口中显示。
5、上述两种图示法的实际操作演示
1)先了解如下几个代码
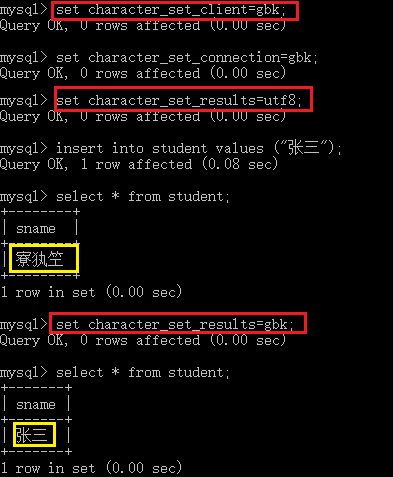
1)设置客户端的字符集
set character_set_client=gbk;
2)设置连接器的字符集
set character_set_connection=utf8;
3)设置返回结果的字符集
set character_set_results=gbk;
2)代码演示过程如下
mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| sid | int(11) | NO | PRI | NULL | auto_increment |
| sname | varchar(20) | NO | | NULL | |
| age | int(11) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> select * from student;
+-----+-------+------+
| sid | sname | age |
+-----+-------+------+
| 1 | 张三 | 23 |
| 2 | 李四 | 25 |
| 3 | 王五 | 43 |
| 4 | 赵六 | 34 |
+-----+-------+------+
4 rows in set (0.00 sec)
mysql> #要想不乱码,需要指定客户端的编码,让连接器不理解错误。
mysql> #这样就不会存入错误数据。
mysql> #往回取数据的时候,还要告诉连接器,如果你从服务器返回,你应该给我转成什么格式。
mysql> #因此,一共需要设置3个参数:
mysql> #1、客户端发送的编码;
mysql> #2、连接器使用的编码;
mysql> #3、返回数据的编码;
mysql>
mysql>
mysql>
mysql> #当前的情况是:客户端是GBK,服务器最终存储的是UTF8。
mysql> #因此,你就要明确告诉服务器,我的客户端是GBK的。
mysql> #命令如下:
mysql> set character_set_client=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> #再告诉连接器,使用UTF8。
mysql> #命令如下:
mysql> set character_set_connection=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> #再告诉,如果你返回值给我看的话,也请返回GBK。
mysql> #命令如下:
mysql> set character_set_results=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into student(sname,age) values ("编码不乱",22);
Query OK, 1 row affected (0.10 sec)
mysql> select * from student;
+-----+----------+------+
| sid | sname | age |
+-----+----------+------+
| 1 | 张三 | 23 |
| 2 | 李四 | 25 |
| 3 | 王五 | 43 |
| 4 | 赵六 | 34 |
| 6 | 编码不乱 | 22 |
+-----+----------+------+
5 rows in set (0.00 sec)
mysql> #我的客户端是GBK,但是我偏要骗对方,是UTF8。
mysql> set character_set_client=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into student(sname,age) values ("编码乱不乱?",22);
ERROR 1366 (HY000): Incorrect string value: '\xB1\xE0\xC2\xEB\xC2\xD2...' for column 'sname' at row 1
mysql> #此时,"编码乱不乱?"对应的GBK的内码,转换成UTF8,压根就出错,不允许插入。
mysql> set character_set_client=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> #我偏要对方返回给我的数据是UTF8。
mysql> set character_set_results=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from student;
+-----+--------------+------+
| sid | sname | age |
+-----+--------------+------+
| 1 | 寮犱笁 | 23 |
| 2 | 鏉庡洓 | 25 |
| 3 | 鐜嬩簲 | 43 |
| 4 | 璧靛叚 | 34 |
| 6 | 缂栫爜涓嶄贡 | 22 |
+-----+--------------+------+
5 rows in set (0.00 sec)
mysql> #此时,请问我再插入数据。
mysql> insert into student(sname,age) values ("编码乱不乱?",22);
Query OK, 1 row affected (0.09 sec)
mysql> select * from student;
+-----+--------------------+------+
| sid | sname | age |
+-----+--------------------+------+
| 1 | 寮犱笁 | 23 |
| 2 | 鏉庡洓 | 25 |
| 3 | 鐜嬩簲 | 43 |
| 4 | 璧靛叚 | 34 |
| 6 | 缂栫爜涓嶄贡 | 22 |
| 7 | 缂栫爜涔变笉涔憋紵 | 22 |
+-----+--------------------+------+
6 rows in set (0.00 sec)
mysql> #虽然插入返回的数据仍然是乱码,但是属于的是,编码和解码不一致导致的乱码,可以修复。
mysql> set character_set_results=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from student;
+-----+--------------+------+
| sid | sname | age |
+-----+--------------+------+
| 1 | 张三 | 23 |
| 2 | 李四 | 25 |
| 3 | 王五 | 43 |
| 4 | 赵六 | 34 |
| 6 | 编码不乱 | 22 |
| 7 | 编码乱不乱? | 22 |
+-----+--------------+------+
6 rows in set (0.00 sec)
mysql> #再看另外一种情况:
mysql> #声明客户端是GBK;
mysql> set character_set_client=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> #声明连接器是GBK;
mysql> set character_set_connection=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> #声明返回值是GBK;
mysql> set character_set_results=gbk;
Query OK, 0 rows affected (0.00 sec)
mysql> #如上操作,插入中文,会不会乱码?
mysql> insert into student(sname,age) values ("真不乱?",666);
Query OK, 1 row affected (0.07 sec)
mysql> select * from student;
+-----+--------------+------+
| sid | sname | age |
+-----+--------------+------+
| 1 | 张三 | 23 |
| 2 | 李四 | 25 |
| 3 | 王五 | 43 |
| 4 | 赵六 | 34 |
| 6 | 编码不乱 | 22 |
| 7 | 编码乱不乱? | 22 |
| 8 | 真不乱? | 666 |
+-----+--------------+------+
7 rows in set (0.00 sec)
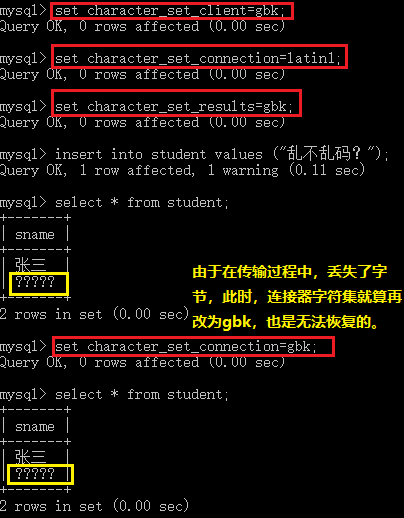
mysql> #现在,我偏偏声明连接器的字符集是latin1。
mysql> set character_set_connection=latin1;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into student(sname,age) values ("还不乱?",888);
Query OK, 1 row affected, 1 warning (0.32 sec)
mysql> select * from student;
+-----+--------------+------+
| sid | sname | age |
+-----+--------------+------+
| 1 | 张三 | 23 |
| 2 | 李四 | 25 |
| 3 | 王五 | 43 |
| 4 | 赵六 | 34 |
| 6 | 编码不乱 | 22 |
| 7 | 编码乱不乱? | 22 |
| 8 | 真不乱? | 666 |
| 9 | ???? | 888 |
+-----+--------------+------+
8 rows in set (0.00 sec)
mysql> #这次乱码,是因为latin1容量小,gbkt容量大。这个转换就像大鱼过小鱼网一样,丢了块肉。
mysql> #也就是说,大容量转换为小容量时,会丢失字节。
mysql> #思考一下:这次乱码能否修复?
mysql> #不能。。。
mysql> #因此,记住这个原则:
mysql> #字符集,服务器>=连接器>=客户端。
mysql> #也即:进行字符集的转换的时候,必须是小容量转换为大容量(小鱼过大鱼网)d,才不会丢失字节。
mysql> #########################################
mysql> #再回头看:一个比较巧的地方。
mysql> #client、connection、server字符集设置的都是GBK,不会导致乱码。
mysql> #如果三者都是GBK,可以简写成如下形式:
mysql> #set names gbk;
mysql> #这一句话,其实表示了3句话的含义。
mysql> Terminal close -- exit!
6、产生乱码的两个原因
- 解码与实际编码,不一致导致的乱码,可修复。
- 在传输过程中,由于编码不一致,导致部分字节丢失,造成的乱码,不可修复。
1)编码和解码不一致导致的乱码
2)传输过程中,丢失字节导致的乱码。
7、对实际情况的分析(什么都不设置,系统默认是如何呢?)
1)MySQL系统参数如下
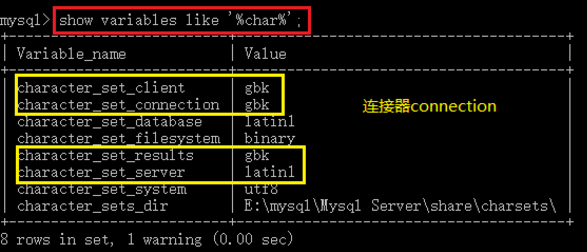
根据上图可以知道:
我们使用图中的这个命令,可以查看系统所有的字符集的设置。从图中可以清楚的看到,客户端的字符集默认是gbk,连接器的字符集默认是gbk,返回值的字符集是gbk,mysql服务器的字符集默认是latin1。
上述设置,是不是和图2(如下所示)中的情况,非常相似。唯一不同的就是系统默认mysql服务器的字符集是latin1,而图二中mysql服务器的字符集是utf8。
“系统为什么将mysql服务器默认使用latin1字符集?你可以自行百度。”
为什么要这么设置呢?因为latin1不支持中文,当我们插入中文的时候,当客户端发送过去的字符,通过连接器,最后发送给mysql服务器的时候,连接器发现mysql服务器采用的字符级是latin1,字符集由gbk转化为latin1,就相当于大鱼过小渔网一样,一定会掉肉,而对于字符集来说就会丢失字节。丢失字节后存入的值,肯定也就是错误的,不正确的。
由于mysql的检测是很严格的,既然你存入的时候都会丢失字节,那么存入的值肯定也是错误的,因此,我索性就不让你插入。“这就是我们不设置mysql服务器字符集,想要插图中文,提示1366错误的原因。”"ERROR 1366 (HY000): Incorrect string value: ‘\xD5\xC5\xC8\xFD’ ““for column ‘sname’ at row 1”
当我们使用"charset=utf8"命令,将mysql服务器的字符集设置为utf8后,由于utf8是支持中文的,utf8是变长字符集,它能够支持全世界所有国家的语言。因此,当你输入一个以gbk格式编码的中文,在utf8中肯定是也有自己的一套编码格式,显示同样的文字(只不过此时是以utf8编码的)。
“最后用一个不那么恰当的比喻,来说明字符集编码。”
拿一本新华字典(汉语字典),再拿一本牛津字典(英语字典)。此时,我们要查找一个同一个词"中国”,在汉语字典中,"中国"采用的编码是zhongguo,但是在牛津字典中,“中国"采用的编码是china,你非要拿着zhongguo去牛津字典中查"中国”,你觉得你得到的结果是正常显示,还是乱码呢?
2)set names gbk的含义
当客户端、连接器、返回值的字符集相同,并且都是gbk的时候,我们可以采取如下的简写方式:
set names gbk;
这就话其实包含了三层意思:
set character_set_client=gbk;
set character_set_connection=gbk;
set character_set_results=gbk;

- 点赞
- 收藏
- 关注作者
评论(0)