性能场景之稳定性场景方案设计

前言
今天想说说稳定性场景设计。
经常在一些场合被问到性能场景的设计问题,但是大部分都是和容量相关的。
为什么稳定性问的人少呢?稳定性是不是说在容量场景做好了之后就水到渠成了呢?
首先稳定性场景的设计应该说比容量场景设计要简单一点。
毕竟容量如果测试结果非常好的话,稳定性场景只要有一时间变长的动作就可以了。
但是不要小看这个时间变长的动作,它会让你要准备和思考的内容多出不少。
下面来庖丁解牛地细化一下。
数据的增加
数据的增加有两个方面。
- 参数化数据;
- 基础数据。
先说下参数化数据:
拿一个 100 TPS 和稳定性场景来说,假设业务数据不能复用,如果只测试 30 分钟。需要的数据是:
也就是 18 万的参数化数据。
如果要跑 12 个小时呢?就是:
也就是 432 万条数据。
有人说了,我要跑 7*24 。嗯,很好,那就需要 60480000。6 千多万。慢慢准备吧。
如果这些数据是做 insert 的动作呢,可想而知,对表结构的要求就会多出很多,索引的创建的合理性就非常重要了。
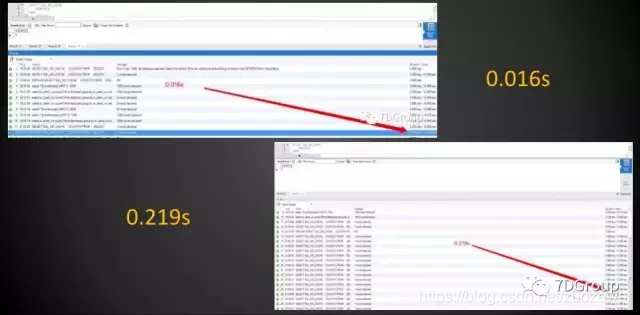
举个例子。同样的一个 SQL,在查找基数为 5537362 的表,都是查一条数据出来。如果是从 9 万多条的索引命中的数据中找的话,需要 0.219 s,而在索引命中 100 多条数据中找的话,只需要 0.016 s。
这是 14 倍的差距。
监控的考验
如果是自己写监控脚本,稳定性场景中数据量的处理那是非常耗时的。所以在稳定性场景中,基本上不会像容量场景中那样设计监控粒度。
粒度的扩大导致的另一个问题是毛刺看不到。
一般容量场景中使用 1~3s 的监控采样粒度,1s 对系统监控还是会消耗些资源。3s 不会有太大的影响。
但是对稳定性来说,3s 都有点短了。可以设置 5~10s 的监控粒度。5-10 的跨度是不是有些大呢?这个取决于系统的稳定程度,对不稳定的 TPS 曲线,可以设置为 5s,对稳定的 TPS 曲线,10s 我觉得是够了的。
监控工具也要选择好,尽量不要用手工生成数据和曲线的工具,费时费力又容易出错。
用自动生成图表的工具比较理智,并且要用可以持续保存数据的。像 Prometheus 类型的工具。
先要设置好监控的计数器。从 OS 层开始,到应用层,到 Jvm 层,到数据库层。
OS 层一定要有 CPU、Memory、IO、Network 这几个是基本的,如果是 C/C++ 的应用,还要有 Process 层的监控。
在场景结束时如果发现还有需要的数据没取到,那就悲催了,还要再来一遍。
对压力工具的选择
一般情况下选择压力工具要注意压力工具本身的稳定性。像 Loadrunner/Jmeter 之类的工具已经被普遍接受了,没有什么问题。
但是 Jmeter ,本地的 jvm 也是需要关注的。
尽量不要用压力工具取监控的数据,这种做法会让结果整理比较费力。
场景的时长确定
这应该是稳定性场景中最关键的一个点了。
我看到有不少设计稳定性的时候没有计算过,只是凭感觉。
那怎么设计这个时长?
我们可以做一个计算,这个计算有一个前提条件。就是系统在运维的过程中需要稳定运行多长时间。
假设在运维中是要三个月做一次正常的维护动作,在这个动作中包括了对一些资源的归档、系统的重启等。
那下一步要计算的就是系统三个月内的业务总量。
我们来做一个假设场景:
一个系统一天业务量是 100 万笔。稳定运行要求 三个月。那总的业务量就是 100万330=9000万。假设系统最大 TPS 是 2000。
这时候要设计的稳定性场景时长就是:
比如说下面两个场景。
下面的图是混合容量场景,看到 TPS 是能加到 5000 左右,但是在 3000 以上的时候就出现了TPS 有下降情况(因为这个文章不是为了分析性能,所以不做下降原因详解)。
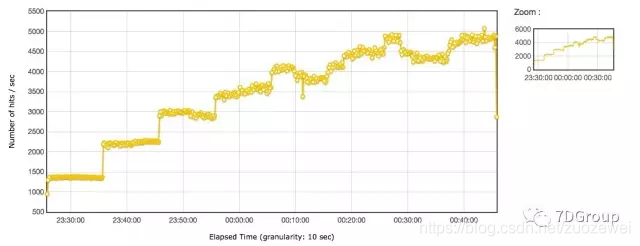
根据这个系统的业务需求,稳定运行时间是三个月。线上均值 TPS 是 329。
那业务量在三个月就是:
稳定性场景用 80%*最大TPS 的压力做的话(这里的稳定性场景的 TPS 可以灵活设置,不一定都是 80%*最大TPS),就是 4000 TPS 左右。
来计算一下:
这样时长就确定下来了。
小结
对于稳定性还有其他的一些区别,都是要一一细化的,这里就不接着写了。毕竟文章太长看得人也累。

- 点赞
- 收藏
- 关注作者
评论(0)