⭐App爬虫之路⭐:海量食谱数据爬取持久化!!!

【摘要】 ⭐App爬虫之路⭐:海量食谱数据爬取持久化!!!
前言
App数据抓包分析
打开豆果美食APP

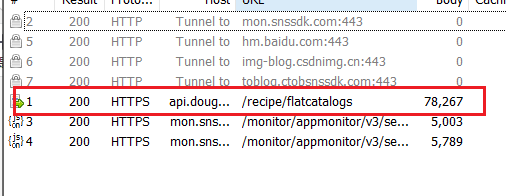
得到对应的JSON数据

对应代码
url = "https://api.douguo.net/recipe/flatcatalogs"
data = {
"client": "4,",
"_vs": "0",
}
count = 0
response = handle_request(url, data)
# 转化为json格式
index_response_dict = json.loads(response.text)
使用在线JSON解析网站进行解析,可以发现我们得到了需要的数据
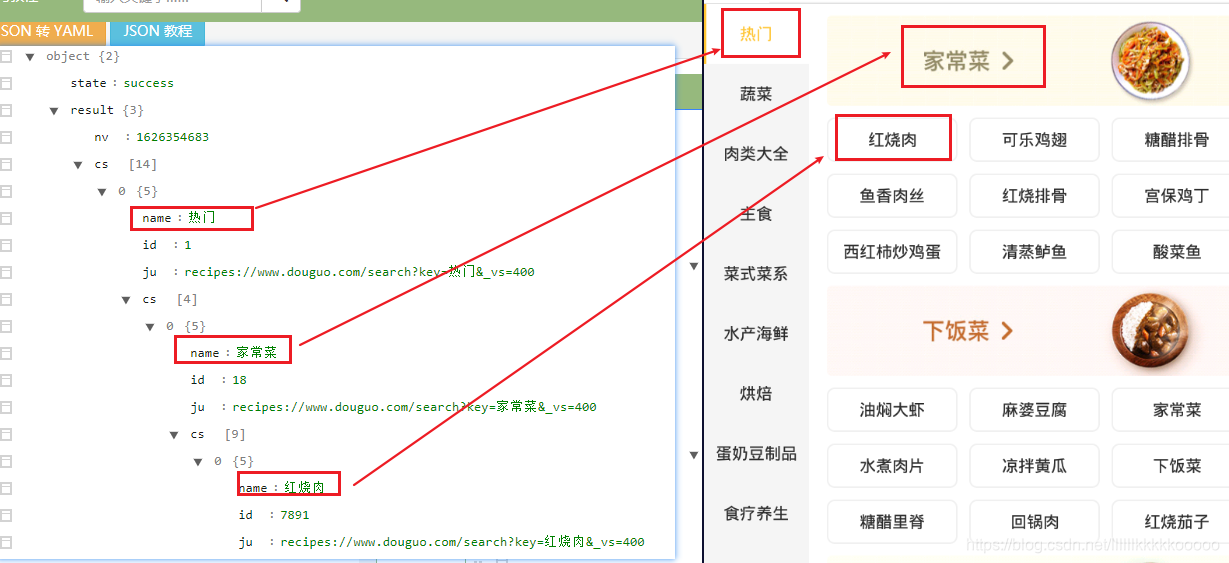
那我们就进入红烧肉吧😁,发现有三种排序的方式
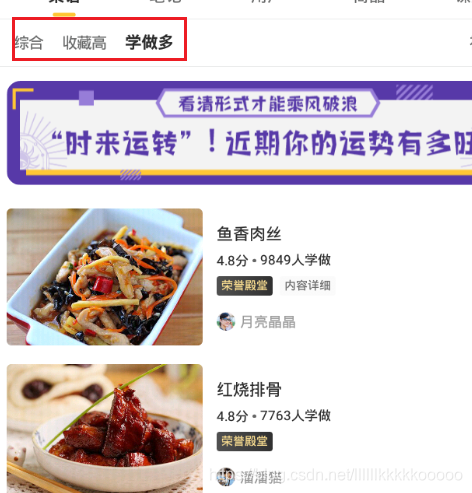
那我们在fiddler中可以发现三个对应的HTTPS请求

表面上看长得一摸一样,但三个都是POST请求,所以参数不同,根据我的实践,发现三种分类对应三个order字段的不同值

再来看看具体的JSON数据,可见是一一对应的
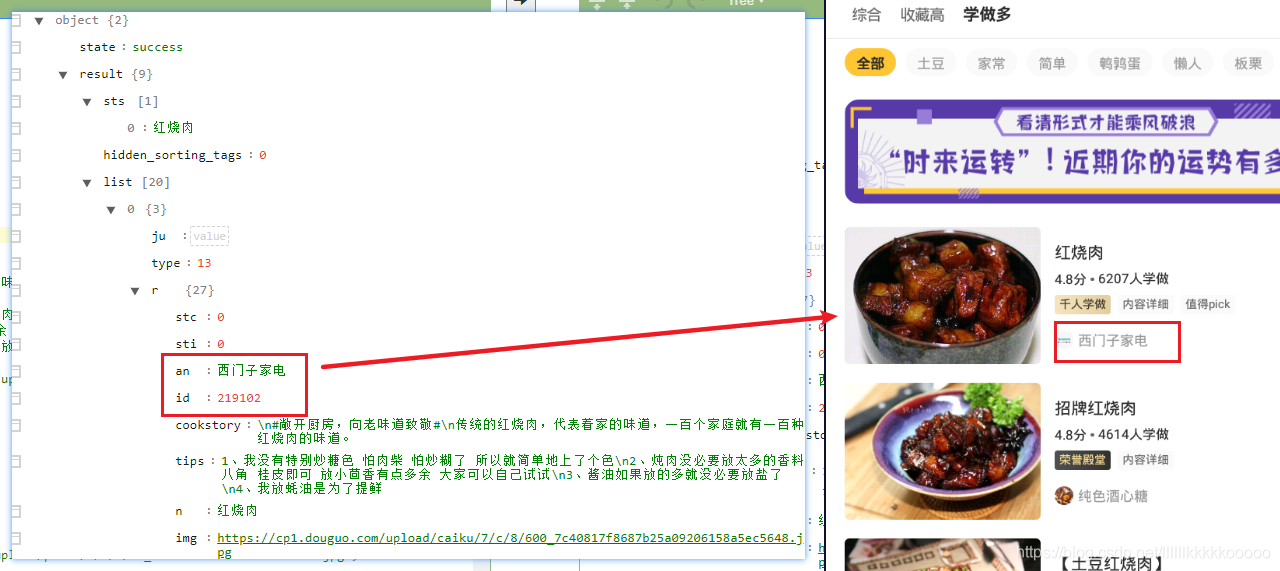
对应部分代码
caipu_list_url = "https://api.douguo.net/recipe/v2/search/0/20"
caipu_list_response = handle_request(url=caipu_list_url, data=data)
caipu_list_response_dict = json.loads(caipu_list_response.text)
然后的话还需要去请求详情页
请求路径中的数字就是上面得到的ID

对应部分代码
detail_url = "https://api.douguo.net/recipe/v2/detail/" + str(shicai_id)
detail_data = {
"client": "4",
"author_id": "0",
"_vs": "11104",
"_ext": '{"query":{"kw":' + str(
shicai) + ',"src":"11104","idx":"3","type":"13","id":' + str(
shicai_id) + '}}',
"is_new_user": "1",
}
detail_response = handle_request(detail_url, detail_data)
#解析为json格式
detail_response_dict = json.loads(detail_response.text)
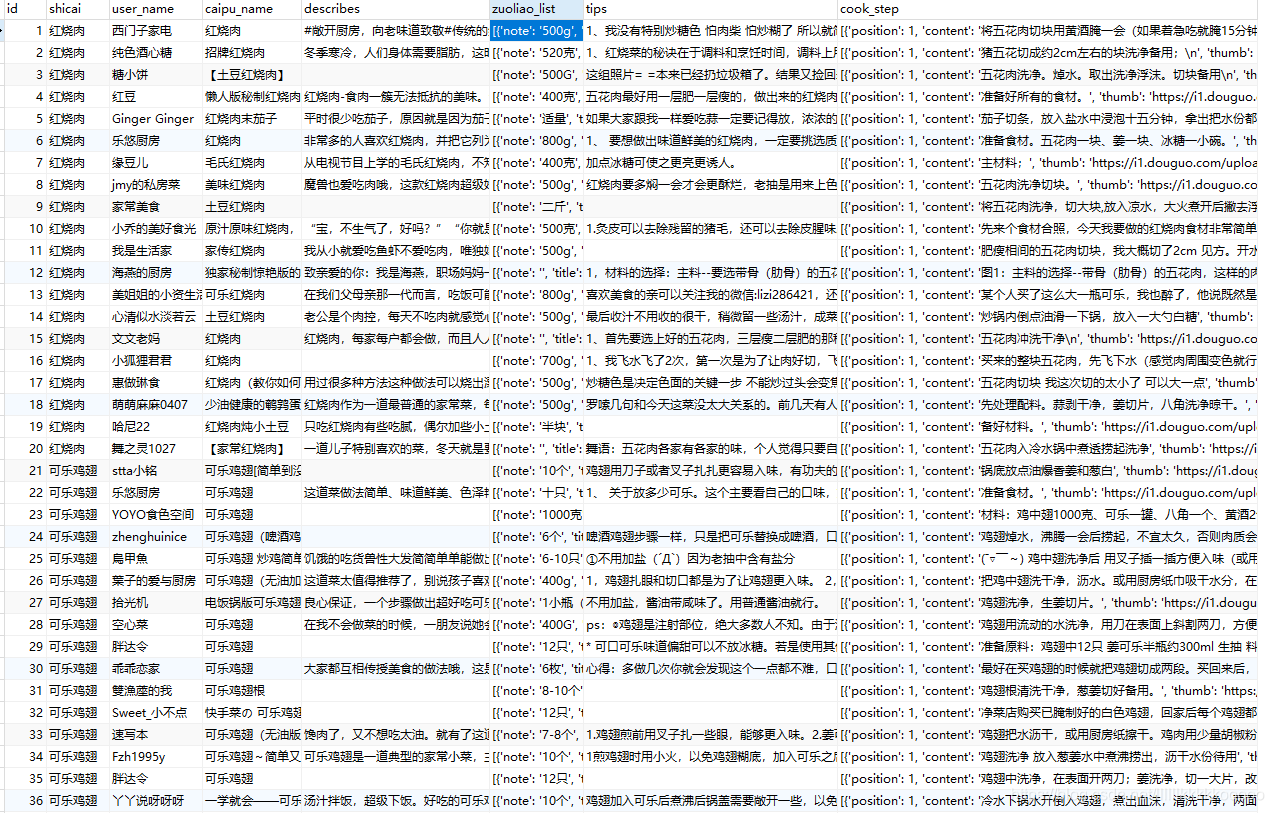
爬取结果
代码测试,只爬取了部分

最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
⭐需要完整代码⭐,麻烦关注公众号:JavaCodes,后台回复:豆果美食,即可领取😁


【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)