Python进阶必备:进程模块multiprocessing

1. 再谈线程和进程
在《Python进阶必备:线程模块threading》一文中,我们以经营物业管理公司为例,形象地介绍了线程和进程的概念。有了线程技术,我们就可以在一个进程中创建多个线程,让它们在“同一时刻”分别去做不同的工作了。这些线程共享同一块内存,线程之间可以共享对象、资源,如果有冲突或需要协同,还可以随时沟通以解决冲突或保持同步。
不过,多线程技术不是万金油,它有一个致命的缺点:在一个进程内,不管你创建了多少线程,它们总是被限定在一颗CPU内,或者多核CPU的一个核内。这意味着,多线程编程无法充分发挥多核计算资源的优势。这也是使用多线程做任务并行处理时,线程数量超过一定数值后线程越多速度反倒越慢的原因。
多进程技术正好弥补了多线程编程的不足,我们可以在每一颗CPU上,或者多核CPU的每一个核上启动一个进程,如果有必要,还可以在每个进程内再创建适量的线程,最大限度地使用计算资源解决问题。因为不在同一块内存区域内,和线程相比,进程间的资源共享、通讯、同步等,都要麻烦的多,收到的限制也更多。
multiprocessing 是 Python 内置的标准进程模块,可运行于 Unix 和 Windows 平台台上。依赖于该模块,程序员得以充分利用机器上的多核资源。为便于使用,multiprocessing 模块提供了和 threading 线程模块相似 API。针对进程特点,multiprocessing 模块还引入了在 threading 模块中没有的API,比如进程池(Pool)、共享内存(Array 和 Value)等。
2. 创建、启动和管理进程
Process 类是 multiprocessing 模块的子进程类,用于创建、启动和管理子进程。Process 和线程模块 treading.Thread 的 API 几乎完全相同。Process 类用来描述一个进程对象。创建子进程的时候,只需要传入进程函数和函数的参数即可完成 Process 实例化。
2.1 Process 原型
p = multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
target 是进程函数名,进程函数的函数通过 args 和 kwargs 传入。
2.2 Process的属性和方法
| 方法 | 说明 |
|---|---|
| start() | 启动进程,会自动调用p对象的run()方法 |
| run() | 启动进程时候自动运行的方法,去调用target指向的对象。如果需要自定义进程类,一定要实现run()方法 |
| terminate() | 强制终止一个进程,不会做任何清理工作。如果p还有子进程,执行后子进程成为僵尸进程;如果p有锁,则锁也不会清除,易造成死锁 |
| is_alive() | 判断p是否依然生存,如果是则返回True |
| join([timeout]) | p的主线程等待p终止,timeout为可选的超时时间。主线程处于等待,而p处于执行状态。这个方法只适用于start()开启的进程,不能用于run()开启的进程 |
| daemon | 默认为False。如果设置为True,代表p是后台守护进程,如果p的父进程终止,p也终止。设置为True的时候,p无法创建新进程。这个参数必须在start()之前修改,进程开始运行后无法修改 |
| name | 获取进程名,默认是Process-n |
| pid | 获取进程的PID |
| exitcode | 在运行的时候该值为None,如果进程结束了,表示被某个值的信号结束了进程 |
2.3 应用示例
下面这段代码,主进程启动了两个子进程,然后等待用户的键盘输入以结束程序。主进程结束后,子进程也随之结束。
# -*- coding: utf-8 -*-
import os, time
import multiprocessing as mp
def sub_process(name, delay):
"""进程函数"""
while True:
time.sleep(delay)
print('我是子进程%s,进程id为%s'%(name, os.getpid()))
if __name__ == '__main__':
print('主进程(%s)开始,按任意键结束本程序'%os.getpid())
p_a = mp.Process(target=sub_process, args=('A', 1))
p_a.daemon = True # 设置子进程为守护进程
p_a.start()
p_b = mp.Process(target=sub_process, args=('B', 2))
p_b.daemon = True # 如果子进程不是守护进程,主进程结束后子进程可能成为僵尸进程
p_b.start()
input() # 利用input函数阻塞主进程。这是常用的调试手段之一。
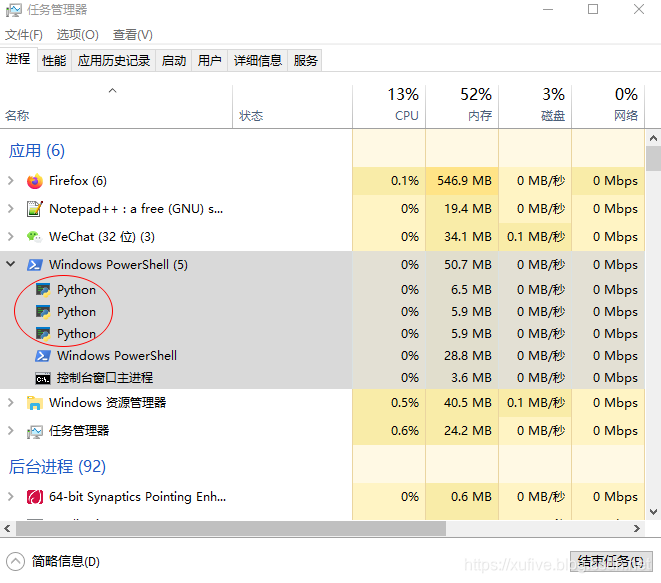
如果上面代码中两个子进程的 daemon 设置为 False,则主进程结束后,两个子进程不会随之结束,从而成为僵尸进程。如下图所示,在任务管理中查看当前进程,可以看到主进程以及两个子进程使用的3个Python解释器(如果你还有其他的 Python 程序,比如 IDLE 等,在运行的话,会看到有更多的 Python 解释器在运行)。我们可以在任务管理中手工关闭僵尸进程。当然,我们也可以在主进程结束前,使用 is_live() 判断进程是否还在运行,使用 terminate() 强制关闭运行中的进程。
3. 进程间通讯
不同的进程,虽然分属于不同的内存区块,但 multiprocessing 模块仍然提供了一些支持进程间通讯的技术,这些技术可分为交换数据和共享状态两类。
3.1 交换数据
3.1.1 队列
队列是进程间交换数据最常用的方式之一,尤其适合生产者——消费者模式。multiprocessing 模块提供了一个和 queue.Queue 近乎一摸一样的 Queue 类,它的 put () 和 get() 两个方法均默认为阻塞式,这意味着一旦队列为空,则 get() 会被阻塞;一旦队列满,则 put() 会被阻塞。如果使用参数 block=False 设置读写 put () 和 get() 为非阻塞,则读空或写满时会抛出异常,因此读写队列之前需要使用 enmpy() 或 full() 判断。Queue 类实例化时可以指定队列长度。
下面的代码,演示了典型的生产者——消费者模式:进程A负责往地上扔钱,进程B负责从地上捡钱。
# -*- coding: utf-8 -*-
import os, time, random
import multiprocessing as mp
def sub_process_A(q):
"""A进程函数:生成数据"""
while True:
time.sleep(5*random.random()) # 在0-5秒之间随机延时
q.put(random.randint(10,100)) # 随机生成[10,100]之间的整数
def sub_process_B(q):
"""B进程函数:使用数据"""
words = ['哈哈,', '天哪!', '卖狗的!', '咦,天上掉馅饼了?']
while True:
print('%s捡到了%d块钱!'%(words[random.randint(0,3)], q.get()))
if __name__ == '__main__':
print('主进程(%s)开始,按任意键结束本程序'%os.getpid())
q = mp.Queue(10)
p_a = mp.Process(target=sub_process_A, args=(q,))
p_a.daemon = True
p_a.start()
p_b = mp.Process(target=sub_process_B, args=(q,))
p_b.daemon = True
p_b.start()
input()
3.1.2 管道
管道是除队列之外的另一种进程间通讯的主要方式。multiprocessing 模块提供了 Pipe 类用于管道通讯,默认是双工的,管道的两端都可以 send() 和 recv()。需要说明的是,recv() 是阻塞式的,并且没有队列那样的 block 参数可以设置是否阻塞。
下面的代码,演示了两个进程猜数字的游戏:进程A在心中默想了一个 [0, 127] 之间的整数,让进程B来猜。如果B猜对了,游戏结束;如果B猜的数字大于或者小于目标,则A会告诉B大了或者小了,让B继续。
# -*- coding: utf-8 -*-
import time, random
import multiprocessing as mp
def sub_process_A(p_end):
"""A进程函数"""
aim = random.randint(0, 127)
p_end.send('我在闭区间[0,127]之间想好了一个数字,你猜是几?')
print('A: 我在闭区间[0,127]之间想好了一个数字,你猜是几?')
while True:
guess = p_end.recv()
time.sleep(0.5 + 0.5*random.random()) # 假装思考一会儿
if guess == aim:
p_end.send('恭喜你,猜中了!')
print('A: 恭喜你,猜中了!')
break
elif guess < aim:
p_end.send('猜小了')
print('A: 不对,猜小了')
else:
p_end.send('猜大了')
print('A: 不对,猜大了')
def sub_process_B(p_end):
"""B进程函数"""
result = p_end.recv()
n_min, n_max = 0, 127
while True:
time.sleep(0.5 + 2*random.random()) # 假装思考一会儿
guess = n_min + (n_max-n_min)//2
p_end.send(guess)
print('B:我猜是%d'%guess)
result = p_end.recv()
if result == '恭喜你,猜中了!':
print('B:哈哈,被我猜中!')
break
elif result == '猜小了':
n_min, n_max = guess+1, n_max
else:
n_min, n_max = n_min, guess
if __name__ == '__main__':
p_end_a, p_end_b = mp.Pipe() # 创建管道,返回管道的两个端,均可收发信息
p_a = mp.Process(target=sub_process_A, args=(p_end_a,))
p_a.daemon = True
p_a.start()
p_b = mp.Process(target=sub_process_B, args=(p_end_b,))
p_b.daemon = True
p_b.start()
p_a.join()
p_b.join()
3.2 共享状态
3.2.1 共享内存
通过共享内存实现状态共享非常简单,但在多进程编程中,这并不是首选的方法,应当尽量避免使用。multiprocessing 模块提供了 Value 和 Array 两个共享内存对象,一个用于单值共享,一个用于数组共享。实例化 Value 和 Array 时,‘d’ 表示双精度浮点数, ‘i’ 表示有符号整数。这些共享对象将是进程和线程安全的。
下面的例子演示了两个进程如何共享单值内存和数组内存,顺便实现了进程间同步(请注意:进程间同步有更专业的方法)。这个例子里面隐式地涉及到了 ctypes 模块——这是一个用于在Python和C/C++架设沟通桥梁的模块。
# -*- coding: utf-8 -*-
import os, time
import multiprocessing as mp
def sub_process_A(flag, data):
"""A进程函数"""
while True:
if flag.value == 0:
time.sleep(1)
for i in range(len(data)):
data[i] = i * 3.14
flag.value = 1
print([item for item in data])
def sub_process_B(flag, data):
"""B进程函数"""
while True:
if flag.value == 1:
time.sleep(1)
for i in range(len(data)):
data[i] = i * 2.72
flag.value = 0
print([item for item in data])
if __name__ == '__main__':
print('主进程(%s)开始,按任意键结束本程序'%os.getpid())
flag = mp.Value('i', 0) # flag类型是ctypes.c_long,不是普通的int
data = mp.Array('d', range(5))
p_a = mp.Process(target=sub_process_A, args=(flag, data))
p_a.daemon = True
p_a.start()
p_b = mp.Process(target=sub_process_B, args=(flag, data))
p_b.daemon = True
p_b.start()
input()
3.2.2 服务进程管理器
使用共享内存时,Value 和 Array 只提供了简单的数据结构,服务进程管理器 Manager 则可以支持 list / dict / Lock / RLock / Condition / Event / Queue / Value / Array 等类型。服务进程的管理器比共享内存对象更灵活,比使用共享内存更慢。下面的代码演示了使用服务进程管理器的使用方法。
# -*- coding: utf-8 -*-
import os, time
import multiprocessing as mp
def sub_process_A(m_dict, m_list):
"""A进程函数"""
while True:
time.sleep(1)
for index, value in enumerate(m_list):
m_dict.update({str(index):value})
print(m_dict)
def sub_process_B(m_dict, m_list):
"""B进程函数"""
while True:
time.sleep(1)
for index, value in enumerate(m_list):
if str(index) in m_dict:
m_list[index] += m_dict[str(index)]
else:
m_list[index] = 2 * value
print(m_list)
if __name__ == '__main__':
print('主进程(%s)开始,按任意键结束本程序'%os.getpid())
m = mp.Manager()
m_dict = m.dict()
m_list = m.list(range(5))
p_a = mp.Process(target=sub_process_A, args=(m_dict, m_list))
p_a.daemon = True
p_a.start()
p_b = mp.Process(target=sub_process_B, args=(m_dict, m_list))
p_b.daemon = True
p_b.start()
input()
4. 进程间同步
在《Python进阶必备:线程模块threading》一文中,我用4个例子介绍了4种线程间同步的方法。multiprocessing 模块也提供了与线程间同步一一对应的进程间同步技术。为阅读方便,我借用线程同步的4个例子,用进程代码逐一实现。
4.1 线程锁 Lock
前几天,我想在一个几百人的微信群里统计喜欢吃苹果的人数。有人说,大家从1开始报数吧,并敲了起始数字1,立马有人敲了数字2,3。但是统计很快就进行不下去了,因为大家发现,有好几个人敲4,有更多的人敲5。
这就是典型的资源竞争冲突:统计用的计数器就是唯一的资源,很多人(子线程)都想取得写计数器的资格。怎么办呢?Lock(互斥锁)就是一个很好的解决方案。Lock只能有一个线程获取,获取该锁的线程才能执行,否则阻塞;执行完任务后,必须释放锁。
请看演示代码:
# -*- coding: utf-8 -*-
import time
import multiprocessing as mp
lock = mp.Lock() # 创建互斥锁
counter = mp.Value('i', 0) # 使用共享内存做计数器
def hello(lock, counter):
"""进程函数"""
if lock.acquire(): # 请求互斥锁,如果被占用,则阻塞,直至获取到锁
time.sleep(0.2) # 假装思考、敲键盘需要0.2秒钟
counter.value += 1
print('我是第%d个'%counter.value)
lock.release() # 千万不要忘记释放互斥锁,否则后果很严重
def demo():
p_list= list()
for i in range(30): # 假设群里有30人,都喜欢吃苹果
p_list.append(mp.Process(target=hello, args=(lock, counter)))
p_list[-1].start()
for t in p_list:
t.join()
print('统计完毕,共有%d人'%counter.value)
if __name__ == '__main__':
demo()
除了互斥锁,线程锁还有另一种形式,叫做递归锁(RLock),又称可重入锁。已经获得递归锁的线程可以继续多次获得该锁,而不会被阻塞,释放的次数必须和获取的次数相同才会真正释放该锁。欲了解详情,同学们可以自行检索资料。
4.2 信号量 Semaphore
上面的例子中,统计用的计数器是唯一的资源,因此使用了只能被一个线程获取的互斥锁。假如共享的资源有多个,多线程竞争时一般使用信号量(Semaphore)同步。信号量有一个初始值,表示当前可用的资源数,多线程执行过程中会通过 acquire() 和 release() 操作,动态的加减信号量。比如,有30个工人都需要电锤,但是电锤总共只有5把。使用信号量(Semaphore)解决竞争的代码如下:
# -*- coding: utf-8 -*-
import time
import multiprocessing as mp
S = mp.Semaphore(5) # 有5把电锤可供使用
def us_hammer(id, S):
"""进程函数"""
S.acquire() # P操作,阻塞式请求电锤,
time.sleep(0.2)
print('%d号刚刚用完电锤'%id)
S.release() # V操作,释放资源(信号量加1)
def demo():
p_list = list()
for i in range(30): # 有30名工人要求使用电锤
p_list.append(mp.Process(target=us_hammer, args=(i, S)))
p_list[-1].start()
for t in p_list:
t.join()
print('所有进程工作结束')
if __name__ == '__main__':
demo()
4.3 事件Event
想象我们每天早上上班的场景:为了不迟到,总得提前几分钟(我一般都会提前30分钟)到办公室,打卡之后,一看表,还不到工作时间,大家就看看新闻、聊聊天啥的;工作时间一到,立马开工。如果有人迟到了呢,自然就不能看新闻聊天了,得立即投入工作中。
这个场景中,每个人代表一个线程,工作时间到,表示事件(Event)发生。事件发生前,线程会调用 wait() 方法阻塞自己(对应看新闻聊天),一旦事件发生,会唤醒所有调用 wait() 而进入阻塞状态的线程。
# -*- coding: utf-8 -*-
import time
import multiprocessing as mp
E = mp.Event() # 创建事件
def work(id, E):
"""进程函数"""
print('<%d号员工>上班打卡'%id)
if E.is_set(): # 已经到点了
print('<%d号员工>迟到了'%id)
else: # 还不到点
print('<%d号员工>浏览新闻中...'%id)
E.wait() # 等上班铃声
print('<%d号员工>开始工作了...'%id)
time.sleep(10) # 工作10秒后下班
print('<%d号员工>下班了'%id)
def demo():
E.clear() # 设置为“未到上班时间”
threads = list()
for i in range(3): # 3人提前来到公司打卡
threads.append(mp.Process(target=work, args=(i, E)))
threads[-1].start()
time.sleep(5) # 5秒钟后上班时间到
E.set()
time.sleep(5) # 5秒钟后,大佬(9号)到
threads.append(mp.Process(target=work, args=(9, E)))
threads[-1].start()
for t in threads:
t.join()
print('都下班了,关灯关门走人')
if __name__ == '__main__':
demo()
4.4 条件 Condition
两位小朋友,Hider 和 Seeker,打算玩一个捉迷藏的游戏,规则是这样的:Seeker 先找个眼罩把眼蒙住,喊一声“我已经蒙上眼了”;听到消息后,Hider 就找地方藏起来,藏好以后,也要喊一声“我藏好了,你来找我吧”;Seeker 听到后,也要回应一声“我来了”,捉迷藏正式开始。各自随机等了一段时间后,两位小朋友都憋住了跑了出来。谁先跑出来,就算谁输。
# -*- coding: utf-8 -*-
import time
import multiprocessing as mp
import random
cond = mp.Condition() # 创建条件对象
draw = mp.Array('i', [0,0]) # [Seeker小朋友认输, Hider小朋友认输]
def seeker(cond, draw):
"""Seeker小朋友的进程函数"""
global draw_Seeker, draw_Hidwer
time.sleep(1) # 确保Hider小朋友已经进入消息等待状态
cond.acquire() # 阻塞时请求资源
time.sleep(random.random()) # 假装蒙眼需要花费时间
print('Seeker: 我已经蒙上眼了')
cond.notify() # 把消息通知到Hider小朋友
cond.wait() # 释放资源并等待Hider小朋友已经藏好的消息
print('Seeker: 我来了') # 收到Hider小朋友已经藏好的消息后
cond.notify() # 把消息通知到Hider小朋友
cond.release() # 不要再听消息了,彻底释放资源
time.sleep(random.randint(3,10)) # Seeker小朋友的耐心只有3-10秒钟
if draw[1]:
print('Seeker: 哈哈,我找到你了,我赢了')
else:
draw[0] = True
print('Seeker: 算了,我找不到你,我认输啦')
def hider(cond, draw):
"""Hider小朋友的进程函数"""
global draw_Seeker, draw_Hidwer
cond.acquire() # 阻塞时请求资源
cond.wait() # 如果先于Seeker小朋友请求到资源,则立刻释放并等待
time.sleep(random.random()) # 假装找地方躲藏需要花费时间
print('Hider: 我藏好了,你来找我吧')
cond.notify() # 把消息通知到Seeker小朋友
cond.wait() # 释放资源并等待Seeker小朋友开始找人的消息
cond.release() # 不要再听消息了,彻底释放资源
time.sleep(random.randint(3,10)) # Hider小朋友的耐心只有3-10秒钟
if draw[0]:
print('Hider: 哈哈,你没找到我,我赢了')
else:
draw[1] = True
print('Hider: 算了,这里太闷了,我认输,自己出来吧')
def demo():
p_seeker = mp.Process(target=seeker, args=(cond, draw))
p_hider = mp.Process(target=hider, args=(cond, draw))
p_seeker.start()
p_hider.start()
p_seeker.join()
p_hider.join()
if __name__ == '__main__':
demo()
5. 进程池
和线程一样,处理并行任务时,处理效率和进程数量并不总是成正比——当进程数量超过一定限度后,完成任务所需时间反倒会延长。进程池提供了一个保持合理进程数量的方案,但合理进程数量则需要根据硬件状况及运行状况来确定。
multiprocessing.Pool(n) 用于创建n个进程的进程池供用户调用。如果进程池任务不满,则新的进程请求会被立即执行;如果进程池任务已满,则新的请求将等待至有可用进程才被执行。向进程池提交任务有两种方式:
- apply_async(func[, args[, kwds[, callback]]])
非阻塞式提交。即使进程池已满,也会接受新的任务,不会阻塞主进程。新任务将处于等待状态。 - apply(func[, args[, kwds]])
阻塞式提交。若进程池已满,则主进程阻塞,直至有空闲进成可用
5.1 典型应用
下面的代码,演示了进程池的典型用法。读者可自行尝试阻塞式提交和非阻塞式提交两种方法的差异。
# -*- coding: utf-8 -*-
import time
import multiprocessing as mp
def power(x, a=2):
"""进程函数:幂函数"""
time.sleep(1)
print('%d的%d次方等于%d'%(x, a, pow(x, a)))
def demo():
mpp = mp.Pool(processes=4)
for item in [2,3,4,5,6,7,8,9]:
mpp.apply_async(power, (item, )) # 非阻塞提交新任务
#mpp.apply(power, (item, )) # 阻塞提交新任务
mpp.close() # 关闭进程池,意味着不再接受新的任务
print('主进程走到这里,正在等待子进程结束')
mpp.join() # 等待所有子进程结束
print('程序结束')
if __name__ == '__main__':
demo()
5.2 Map & Reduce
MapReduce 是一种用于大规模数据集的并行运算编程模型,分为 Map(映射)和 Reduce(归约)两个步骤。Py2时代,map() 和 reduce() 都是标准函数。不知为何,Py3 把 reduce() 藏到了标准模块 functools 中,只保留了 map() 在标准函数库中。
进程池对象 Pool 自带 map() 方法,遗憾的是没有提供 reduce() 方法。没关系,我们可以借用 Python 标准库 functools 模块中的 reduce(),实现完整的 Map & Reduce 的数据处理。下面以计算整数列表各元素的平方和为例,演示了 Map 和 Reduce 的用法。
# -*- coding: utf-8 -*-
import time
from functools import reduce
import multiprocessing as mp
def power(x, a=2):
"""进程函数:幂函数"""
time.sleep(0.5)
return pow(x, a)
if __name__ == '__main__':
#mp.freeze_support() # 如果乱弹窗口,请放开注释
with mp.Pool(processes=8) as mpp:
print(reduce(lambda result,x:result+x, mpp.map(power, range(100)), 0))

- 点赞
- 收藏
- 关注作者
评论(0)