深度学习和目标检测系列教程 13-300:YOLO 物体检测算法

@Author:Runsen
YOLO,是目前速度更快的物体检测算法之一。虽然它不再是最准确的物体检测算法,但当您需要实时检测时,它是一个非常好的选择,而不会损失太多的准确性。
YOLO 框架
在本篇博客中,我将介绍 YOLO 在给定图像中检测对象所经过的步骤。
- YOLO 首先获取输入图像:

然后框架将输入图像划分为网格(比如 3 X 3 网格):
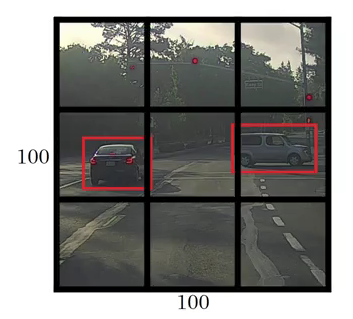
图像分类和定位分别应用于每个网格,然后 YOLO 预测边界框及其对应的对象类别概率。
因此,下一步的方法是将标记数据传递给模型以对其进行训练。假设已将图像划分为大小为 3 X 3 的网格,并且存在有 3 个希望将对象分类的类。
假设这些类分别是 Pedestrian行人、Car 和 Motorcycle摩托车。对于每个网格单元,标签 y 将是一个八维向量:
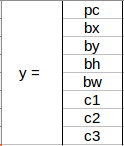
- pc定义对象是否存在于网格中(这是概率)
- bx , by , bh , bw指定边界框,如果有对象
- c1、c2、c3表示类别。因此,如果对象是汽车,则 c2将为 1,c1 和 c3将为 0
从上面的例子中选择了第一个网格:

由于此网格中没有对象,因此 pc 将为零,此网格的 y 标签为
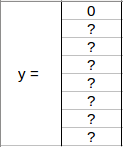
这里, ‘?’ 是没有的意思。
采用另一个网格,其中这里有一辆汽车 (c2 = 1):

在我们为这个网格编写 y 标签之前,首先要知道 YOLO 如何确定网格中是否确实存在对象。在最上面图中,有两个对象(两辆车),因此 YOLO 将取这两个对象的中点,并将这些对象分配到包含这些对象中点的网格。上面的 y 标签将是:
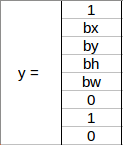
由于此网格中有一个对象,因此 p c 将等于 1。 bx、 by、 bh、 bw将相对于正在处理的特定网格单元。由于汽车是第二类,c2 = 1 且 c1和 c3 = 0。因此,对于9个网格中的每一个,将有一个八维输出向量。此输出的形状为 3 X 3 X 8。
所以现在我们有一个输入图像,它是对应的目标向量。使用上面的例子(输入图像 – 100 X 100 X 3,输出 – 3 X 3 X 8),模型将训练如下:
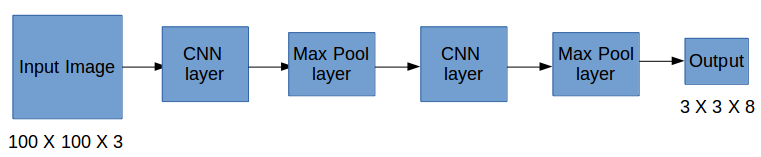
在测试阶段,我们将图像传递给模型并运行前向传播,直到我们得到输出 y。在这里使用 3 X 3 网格进行了解释,但通常在实际场景中采用更大的网格(一般是 19 X 19)。
如何得到编码边界框?
bx、 by、 bh和 bw是相对于正在处理的网格单元计算的。
下面通过一个例子来理解这个概念。考虑包含汽车的中右网格:

bx、 by、 bh和bw将仅相对于该网格进行计算。此网格的 y 标签将是:
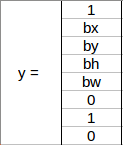
pc = 1 因为在这个网格中有一个物体并且它是一辆汽车,所以 c2 = 1。现在,看看怎么确定 bx、 by、 bh和 bw。在YOLO中,分配给所有网格的坐标是:
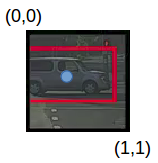
bx , by是对象中点相对于该网格的 x 和 y 坐标。在这种情况下,它将是(大约)bx = 0.4 和 by = 0.3:
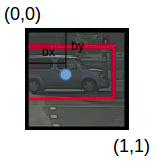
bh 是边界框(上例中的红色框)的高度与相应网格单元的高度之比,在例子中约为 0.9。因此,bh = 0.9。bw是边界框的宽度与网格单元格的宽度之比。因此,大约bw = 0.5。此网格的 y 标签将是:
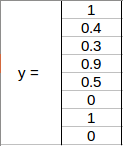
请注意,bx和 by将始终介于 0 和 1 之间,因为中点始终位于网格内。而 bh和 bw可以大于 1,这样边界框的尺寸大于网格的尺寸。
如何确定预测的边界框是否给了我们一个好的结果还是一个坏的结果)?判断的方法就是 Intersection over Union ,计算实际边界框和预测结合框的并集的交集。
Intersection over Union
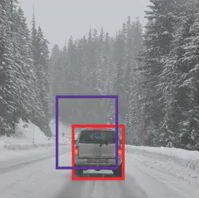
在上图,红色框是实际的边界框,蓝色框是预测的边界框。我们如何确定它是否是一个好的预测?IoU ,全称 Intersection over Union,将计算这两个框的并集上的交集面积。该区域将是:
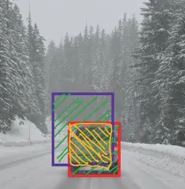
IoU = 交集面积/并集面积,即 IoU = 黄框面积/绿框面积
如果 IoU 大于 0.5,我们可以说预测足够好。0.5 是此处采用的任意阈值。
还有一种技术可以显着提高 YOLO 的输出——Non-Max Suppression。
因为对象检测算法中,有的对象可能会多次检测到一个对象,而不是只检测一次。比如下图:

在这里,汽车被多次识别。Non-Max Suppression 技术对此进行了清理,以便我们对每个对象仅进行一次检测。
Non-Max Suppression首先查看与每个检测相关的概率并取最大的一个。在上图中,0.9 是最高概率,因此将首先选择概率为 0.9 的框:

现在,它查看图像中的所有其他框。与当前框具有高 IoU 的框被抑制。因此,在上面的图片中,概率为 0.6 和 0.7 的框将被抑制:
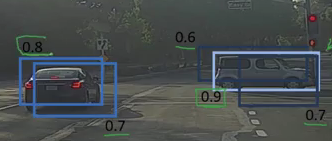
在这些框被抑制后,它从所有具有最高概率的框中选择下一个框,在图片中为 0.8,不断重复这些步骤,直到所有的框都被选中或压缩,得到最终的边界框。
这就是非最大抑制Intersection over Union。以最大概率取框并以非最大概率抑制附近的框。
Anchor Boxes
由于每个网格只能识别一个对象。但是如果一个网格中有多个对象呢?现实中经常是这样。这将我们引向了 Anchor Boxes锚盒的概念。考虑下图,分为 3 X 3 网格:

取对象的中点并根据其位置将对象分配到相应的网格。在上面的例子中,两个对象的中点位于同一个网格中。

我们只会得到两个盒子中的一个,要么是汽车,要么是人。但是如果我们使用锚框,可能可以同时输出两个框!
首先,我们预先定义了两种不同的形状,称为锚盒。对于每个网格,我们将有两个输出,而不是一个输出。我们也可以随时增加锚框的数量。在这里拿了两个来使这个概念易于理解:
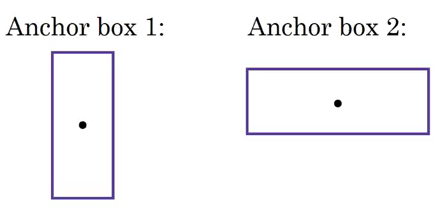
这是没有锚框的 YOLO 的 y 标签的样子:
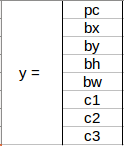
如果有 2 个锚框,你认为 y 标签会是什么?我希望你在进一步阅读之前花点时间思考一下。知道了y 标签将是:
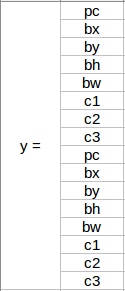
前 8 行属于锚框 1,其余 8 行属于锚框 2。
根据边界框和锚框形状的相似性将对象分配给锚框。
由于anchor box 1的形状类似于person的bounding box,后者将被分配给anchor box 1,car将被分配给anchor box 2。这种情况下的输出,而不是3 X 3 X 8 ,使用 3 X 3 网格和 3 个类将是 3 X 3 X 16(因为使用了 2 个锚点)。
因此,对于每个网格,可以根据锚点的数量检测两个或多个对象。
训练yolo模型的输入显然是图像及其相应的 y 标签。让我们看一个图像如何制作 y 标签:

考虑使用 3 X 3 网格,每个网格有两个锚点,并且有 3 个不同的对象类。所以对应的 y 标签将有 3 X 3 X 16的形状。现在,假设我们每个网格使用 5 个锚框并且类的数量已经增加到 5。所以目标将是3 X 3 X 10 X 5 = 3 X 3 X 50。
在测试中,新图像将被划分为我们在训练期间选择的相同数量的网格。对于每个网格,模型将预测形状为 3 X 3 X 16 的输出,此预测中的 16 个值将采用与训练标签相同的格式。
前 8 个值将对应于锚框 1,其中第一个值将是该网格中对象的概率。值 2-5 将是该对象的边界框坐标,最后三个值将告诉我们该对象属于哪个类。接下来的 8 个值将用于锚框 2 并且格式相同,即首先是概率,然后是边界框坐标,最后是类别。
最后,非最大抑制Intersection over Union技术将应用于预测框以获得每个对象的单个预测。
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/118681888

- 点赞
- 收藏
- 关注作者
评论(0)