sklearn的简单使用

【摘要】 导入数据集
鸢尾花数据集: load_iris() 可用于分类 和 聚类
乳腺癌数据集: load_breast_cancer() 可用于分类
手写数字数据集: load_digits()
可用于分类 糖尿病数据集: load_diabetes()
可用于分类 波士顿房价数据集: load_boston() 可用于回归
体能训练数据集: load_lin...
导入数据集
- 鸢尾花数据集: load_iris() 可用于分类 和 聚类
- 乳腺癌数据集: load_breast_cancer() 可用于分类
- 手写数字数据集: load_digits()
- 可用于分类 糖尿病数据集: load_diabetes()
- 可用于分类 波士顿房价数据集: load_boston() 可用于回归
- 体能训练数据集: load_linnerud() 可用于回归
- 图像数据集: load_sample_image(name)
from sklearn import datasets
wine =datasets.load_wine()
print(wine)
- 1
- 2
- 3
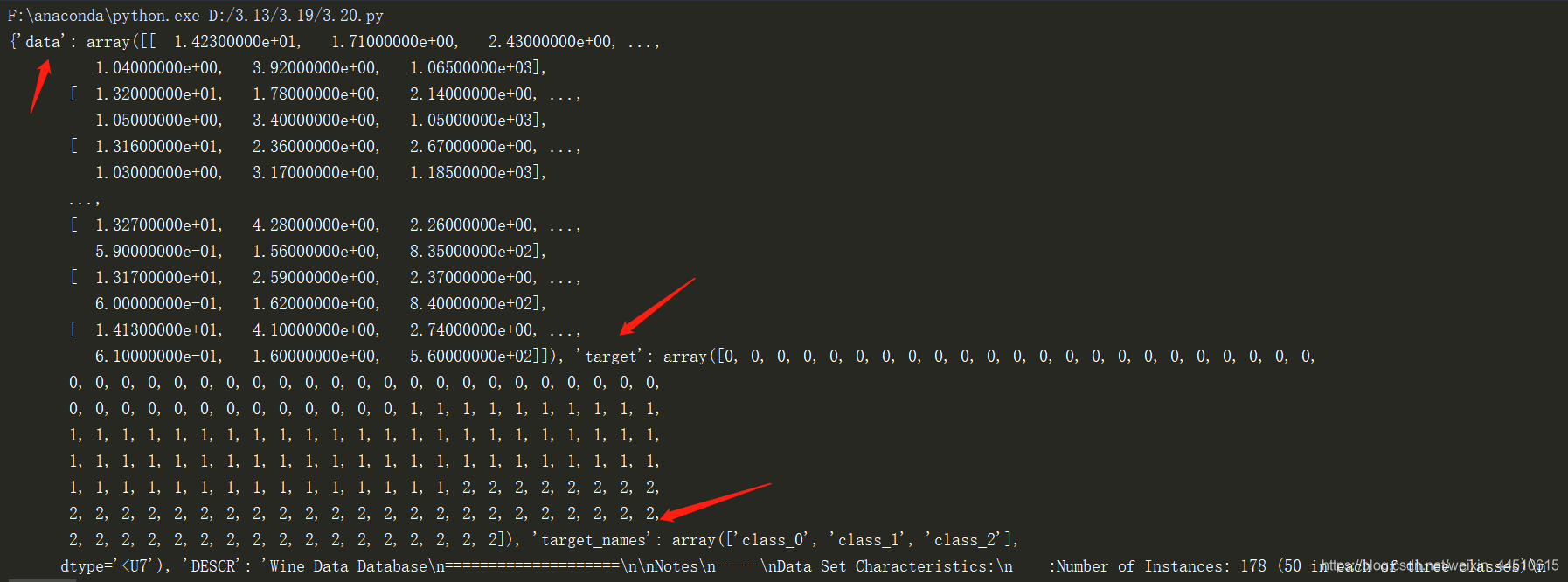
我们可以看到自带的数据集中又data 和target 以及target_names 三个属性
通过字典取值得到data和target
x = wine.data
y = wine.target
- 1
- 2
如何查看特征向量
通过numpy的方
文章来源: maoli.blog.csdn.net,作者:刘润森!,版权归原作者所有,如需转载,请联系作者。
原文链接:maoli.blog.csdn.net/article/details/88746552

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)